XLSTAT によるクラスカル・ウォリス検定:正規分布に従わない3つ以上のグループを比較する
- クラスカル・ウォリス検定とは?
- 分散分析に正規分布が必要な理由
- クラスカル・ウォリス検定の計算過程(理論説明)
- クラスカル・ウォリス検定を実行するためのデータセット
- クラスカル・ウォリス検定を実行する手順
- クラスカル・ウォリス検定の結果の解釈
- まとめ
- 参考文献
- XLSTAT の無料トライアル
クラスカル・ウォリス検定とは?
クラスカル・ウォリス検定は、3つ以上の独立したグループの間に、統計的に意味のある差があるかどうかを調べるための手法です。例えば「A薬(新薬)、B薬(既存薬)、C薬(プラセボ)」の3つのグループで、検査値に違いがあるかを調べたい場合などに用いられます。

通常、3群以上の平均値を比較する場合は、分散分析(ANOVA)を使いますが、分散分析を使うには「データが正規分布している」という条件が必要です。データ数が少なかったり、分布が偏っていたりして条件を満たさない場合に、このクラスカル・ウォリス検定が採用されます。このようにデータの正規分布を前提としない手法は「ノンパラメトリック検定」と呼ばれ、クラスカル・ウォリス検定はその代表格です。
分散分析に正規分布が必要な理由
分散分析とクラスカル・ウォリス検定の使い分けにおいて、データの形(正規分布かどうか)が重要な理由は、分散分析をはじめとするパラメトリック検定が平均値を比較する手法であるためです。
データがきれいな山型(正規分布)であれば、平均値は集団の実態をよく表す優れた指標になります。しかし、極端に大きな値(外れ値)が混じっていると、平均値はその値に引っ張られてしまいます。
例えば、学校のクラスごとの平均体重を比較する場面を想像してみましょう。もし1つのクラスに1人だけ力士が含まれていると、そのクラスの平均体重は跳ね上がりますが、それはほかのメンバーとの実態とはかけ離れた数値になってしまいます。

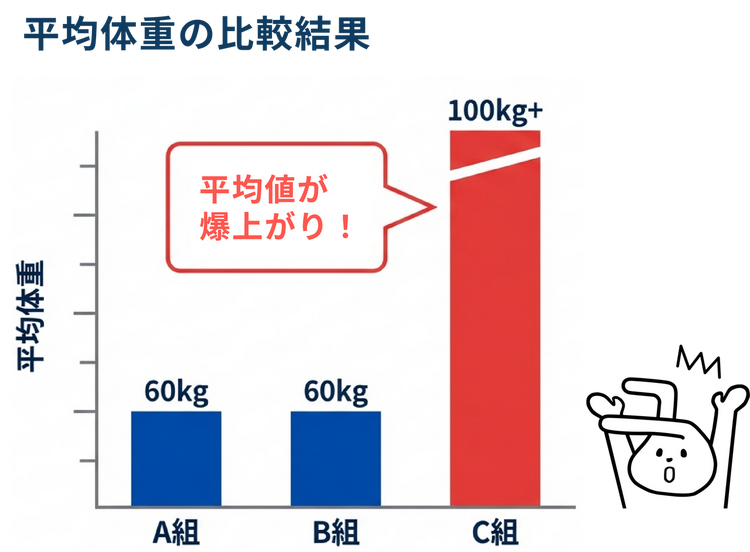
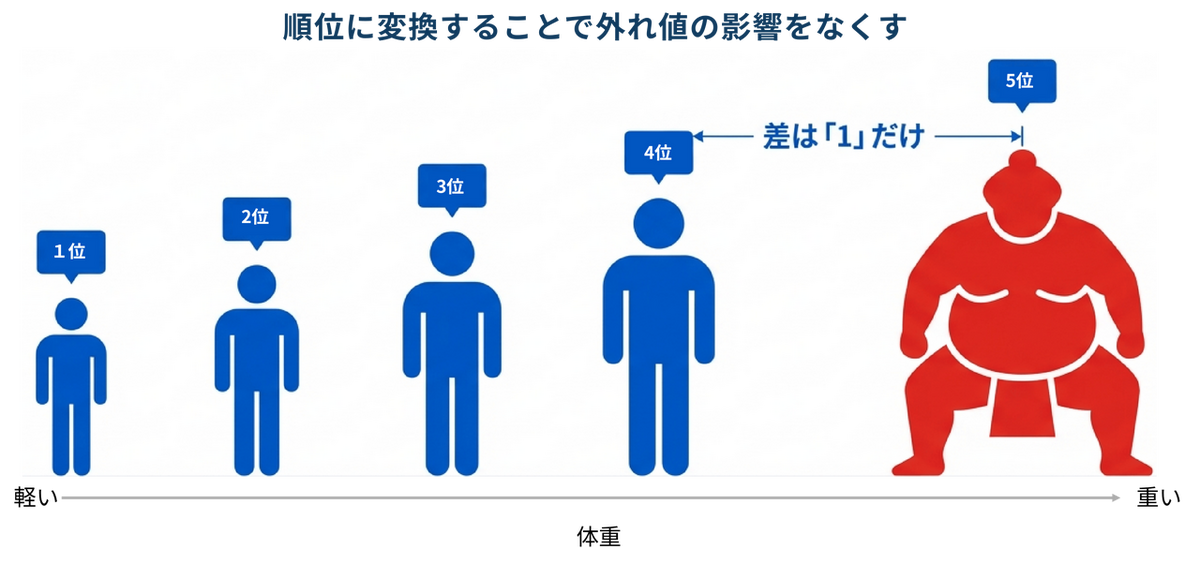
これに対して、クラスカル・ウォリス検定は具体的な数値ではなく、データを小さい順に並べた際の「順位」を用いて検定を行います。先ほどの力士の例で言えば、体重が150kg だろうと200kg だろうと、数値の大きさそのものは使いません。単に一番重い(5人のデータであれば5位)という順位として扱います。このように数値を順位に置き換えることで、極端な値が計算結果を歪めることを防げるため、データが正規分布していなくてもグループ間の差を適切に比較することができます。
クラスカル・ウォリス検定の計算過程(理論説明)
クラスカル・ウォリス検定がどのような仕組みで判定しているのか、「3種類の肥料の効果比較」という事例を使って、実際の計算プロセスを追ってみましょう。
事例:3種類の肥料によるトマトの収穫量の比較
ある農家が、3種類の肥料(A、B、C)を使ってトマトを育て、収穫量に差があるかを調べたいと考え、各肥料ごとに3つの苗を育てました。各苗で収穫できたトマトの個数は以下の通りです。
データ(収穫量)
肥料A: 10個, 12個, 15個
肥料B:13個, 20個, 22個
肥料C:25個, 28個, 30個

この結果だけみると、肥料C が一番収穫量が多く、肥料A や肥料B と比べると差がありそうですが、今回の調査ではたまたまこのような結果が出ただけという可能性も考えられます。そこでクラスカル・ウォリス検定を使って、「肥料によりトマトの収穫量に差があると言えるか?」を検定します。
ステップ1:すべてのデータを混ぜて順位をつける
まず、グループに関係なく、全データを小さい順に並べて順位をつけます。 今回はA(赤)とB(黄) の収穫量が近いため、順位が少し入り混じります。

ステップ2:グループごとに「順位の合計」を出す
それぞれのグループの「順位」だけを足し算します。これを「順位和」と呼びます。

肥料A の順位和:1 + 2 + 4 = 7
肥料B の順位和:3 + 5 + 6 = 14
肥料C の順位和:7 + 8 + 9 = 24
ステップ3:検定統計量H を計算する
公式に値を代入して統計量H を求めます。
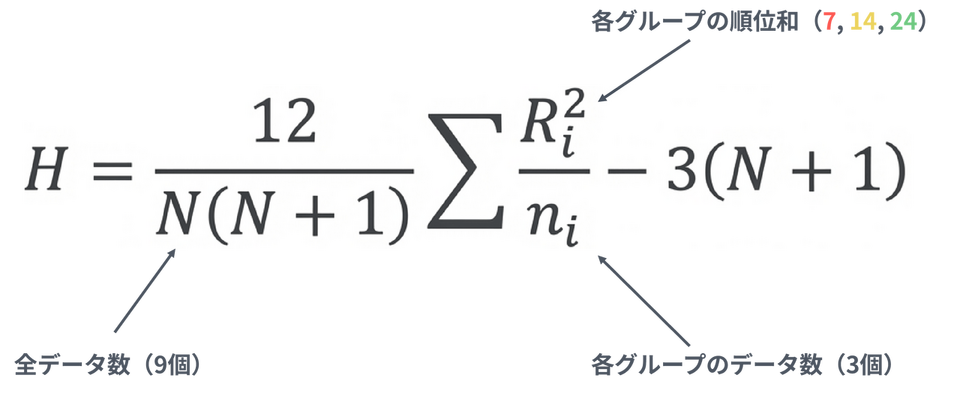
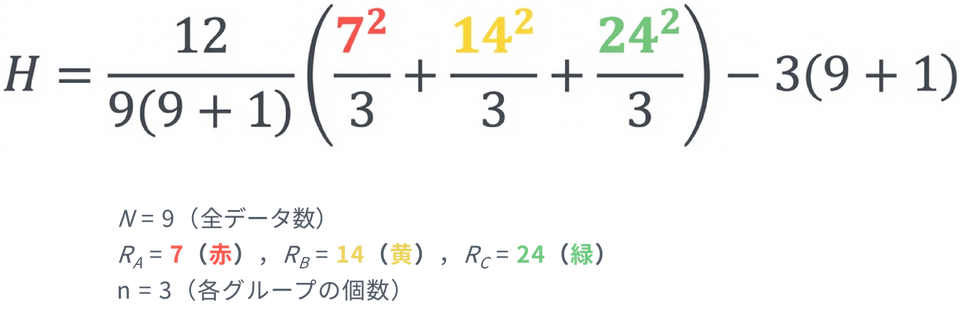

上記の計算で検定統計量H は 6.49 となりました。
ステップ4:カイ二乗分布と検定統計量を比較して判定する
クラスカル・ウォリス検定の統計量は、近似的にカイ二乗分布に従います。カイ二乗分布表で有意水準が5% のときのカイ二乗値を確認し、検定統計量H と比較します。もし計算した検定統計量の方が大きければ、「有意差あり」と判断します。自由度は「(グループの数)-1」で求められます。
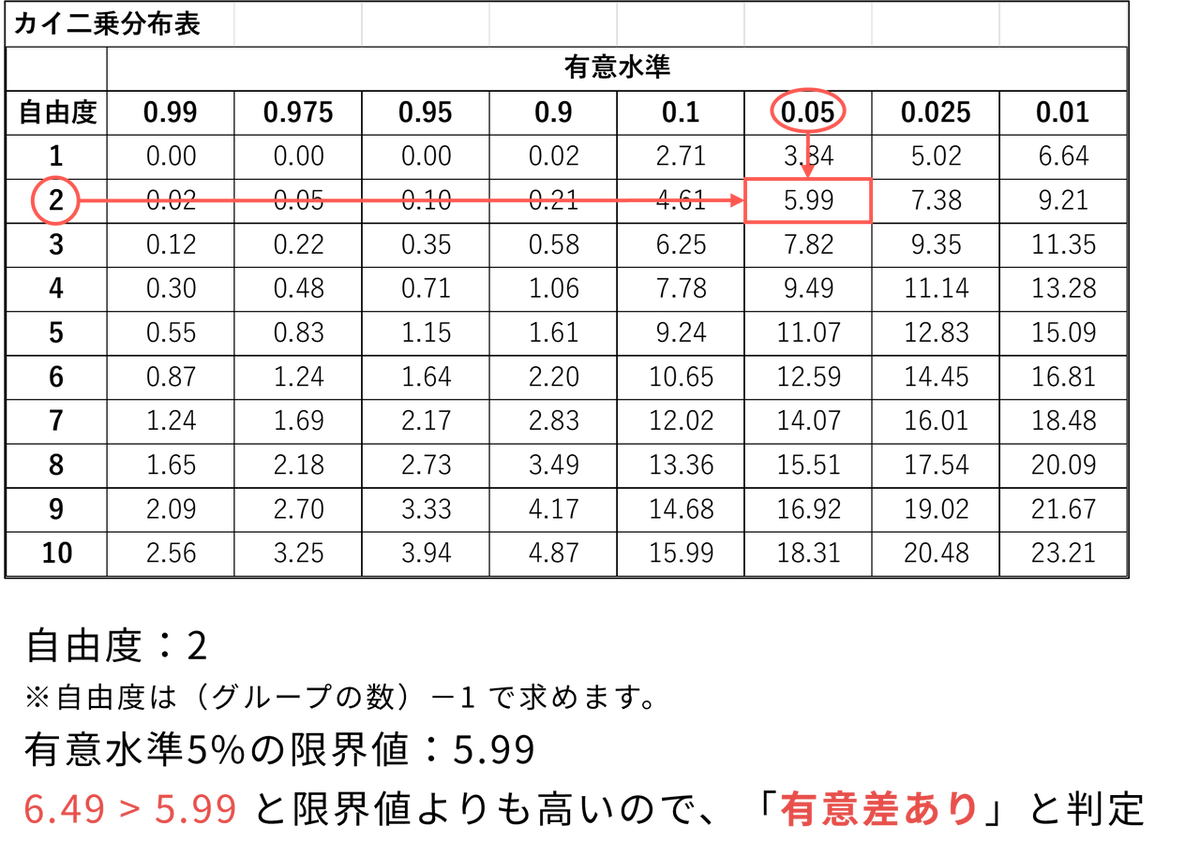
今回の場合、分布表で自由度「2」、有意水準「0.05」の項目を確認すると、「5.99」となっています。それに対して検定統計量は「6.49」であり、分布表の値よりも大きいため、「有意水準5%で、3種類の肥料によるトマトの収穫量には有意な差がある」と言えます。
【注意】
クラスカル・ウォリス検定でわかるのは、「少なくとも1つのグループが他と異なる(全体のどこかに差がある)」ということまでです。「AとB が違うのか」「A とC が違うのか」を知るためには、さらに事後検定(スティール・ドゥワス検定など)を行う必要があります。
なお、本チュートリアルでは、クラスカル・ウォリス検定による全体差の確認に加え、どのグループ間に差があるのかを確認する多重比較(スティール・ドゥワス検定)までを、XLSTAT を用いて説明します。
クラスカル・ウォリス検定を実行するためのデータセット
計算のイメージがつかめたところで、次は実際のデータとXLSTAT を使って、もっと大量のデータを分析してみましょう。
事例:4種類の研修プログラムによるテストスコアの比較
ある企業で、4つの異なる研修プログラム(研修A、研修B、研修C、研修D)を実施しました。 各研修を受けた10名の社員(計40名)のテストスコアを比較し、プログラムによる効果の違いを検証します。

各列が1つのグループ(研修プログラム)に対応する形式でデータを作成しています。
A列~D列:それぞれの研修プログラムを受けた社員のテストスコア
今回はこのデータに対してXLSTAT でクラスカル・ウォリス検定を行い、受講した研修によりテストスコアに差があるのかどうかを確認します。
サンプルデータのダウンロードはこちらから
dataset-for-Kruskal-Wallis-test.xlsmなお、XLSTAT では標本ごとに一列ではなく、以下のような積み重ねのリスト形式でもクラスカル・ウォリス検定を実行することが可能です。

クラスカル・ウォリス検定を実行する手順
-
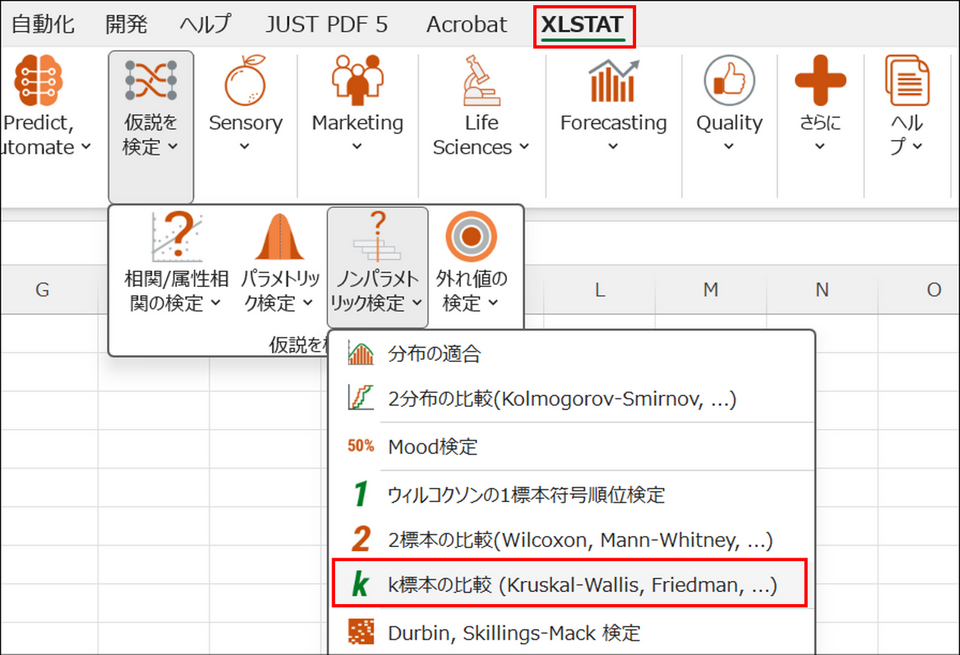
XLSTAT を起動し、[仮説を検定] > [ノンパラメトリック検定] > [k標本の比較 (Kruskal-Wallis, Friedman, ...)] を選択します。
-
ダイアログボックスが表示されたら「一般」タブで以下の設定をします。
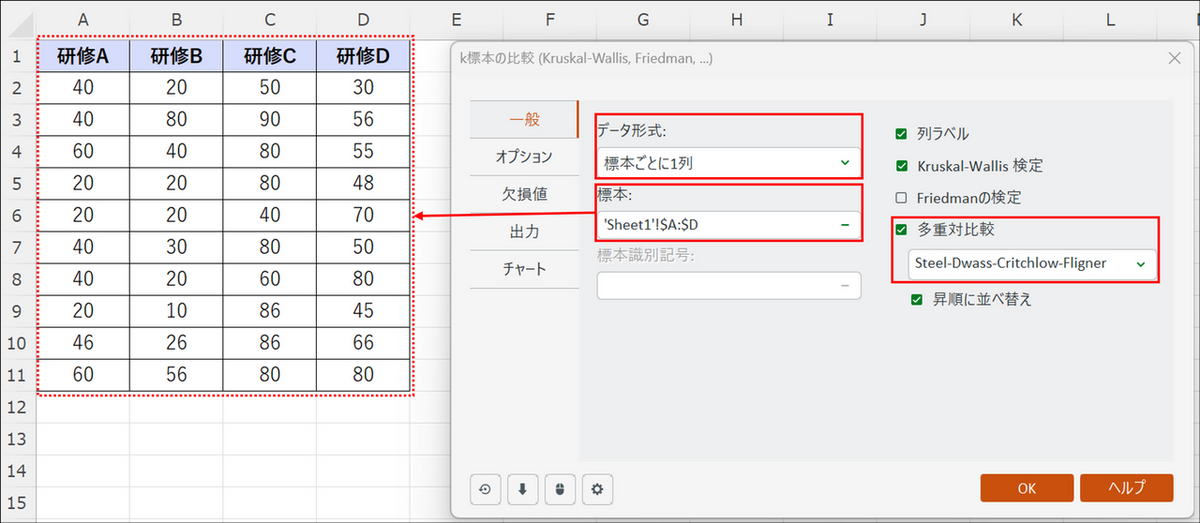
- データ形式:[標本ごとに1列] を選択
- 標本:Excel シート上のA 列からD 列のデータ範囲をすべて選択
- 多重対比較:チェックを入れ、[Steel-Dwass-Critchlow-Fligner(スティール・ドゥワス)] を選択
※Steel-Dwass検定は、ノンパラメトリックな多群比較において、より厳密な方法として用いられる事後検定の一つです。
※このオプションを有効にすることで、クラスカル・ウォリス検定で全体の有意差が確認できた場合に、検定後の多重比較(ペア間の有意差確認)ができます。
【補足】
リスト形式のデータの場合は、以下のようにデータを選択します。
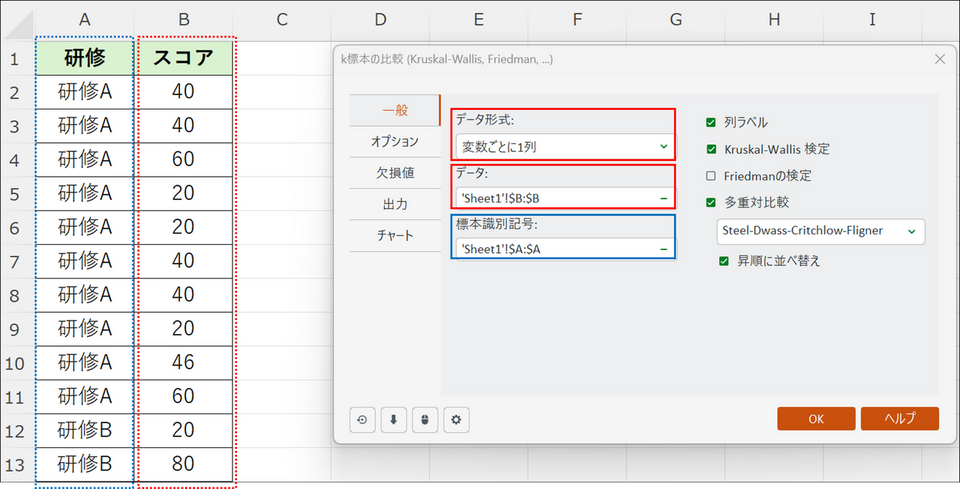
- データ形式:[変数ごとに1列] を選択
- データ:スコアが入力されているデータ列を選択
- 標本識別記号:研修A, B, C, D が入力されている列を選択
-
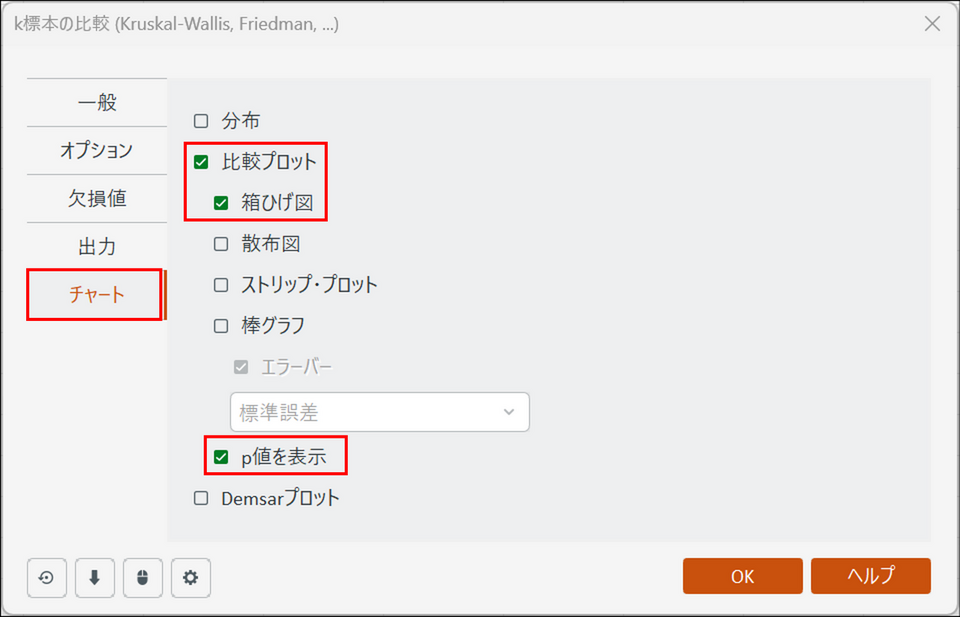
[チャート] タブに切り替え、[箱ひげ図] と [p値を表示] の項目にチェックを入れます。
-
[OK] ボタンをクリックすると計算が始まり、結果が別シート(Kruskal-Wallis)に出力されます。
クラスカル・ウォリス検定の結果の解釈
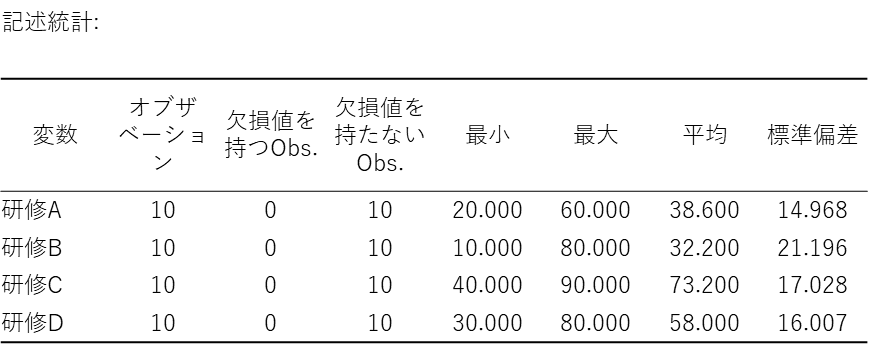
記述統計
結果の最初には「記述統計」の表が出力されます。クラスカル・ウォリス検定の結果を確認する前に、「分析対象のデータに間違いがないか」「どのような特徴があるか」をざっと把握するために使います。
クラスカル・ウォリス検定の結果
Kruskal-Wallis 検定結果でp値を確認します。今回の結果ではp値は「0.000」と限りなく0 に近く、有意水準0.05 より小さいため、「4つの研修プログラムのスコア分布には、統計的に有意な差がある」 と判断します。

多重比較検定(スティール・ドゥワス検定)の結果
クラスカル・ウォリス検定の結果から全体の有意差は確認できたため、次にどのグループ間で差があるのかを多重比較検定の結果(p値の表や有意差の表)で確認します。赤くハイライトされている箇所が「有意差あり(p < 0.05)」の組み合わせです。
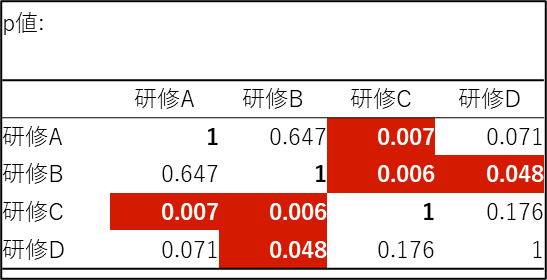
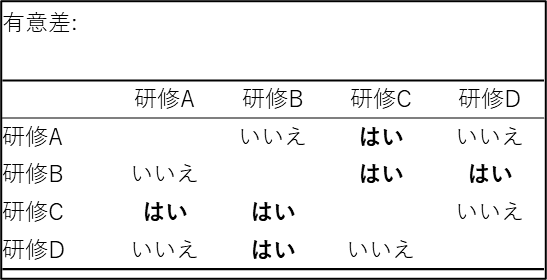
今回の分析結果は以下のようになりました。
【有意差あり(違いがある)】
- 研修A vs 研修C: p = 0.007
- 研修B vs 研修C: p = 0.006
- 研修B vs 研修D: p = 0.048
【有意差なし(違いがあるとは言えない)】
- 研修A vs 研修B: p = 0.647
- 研修A vs 研修D:p = 0.071
- 研修C vs 研修D: p = 0.176
このように、事後検定を行うことで「なんとなく全部違う気がする」ではなく、「統計的に確実に違うと言えるのはこのペアだけ」という厳密な結論を導き出すことができます。
箱ひげ図
オプションで箱ひげ図にチェックを入れて実行した場合は、検定結果だけでなく、各グループの分布を示す箱ひげ図も出力されます。
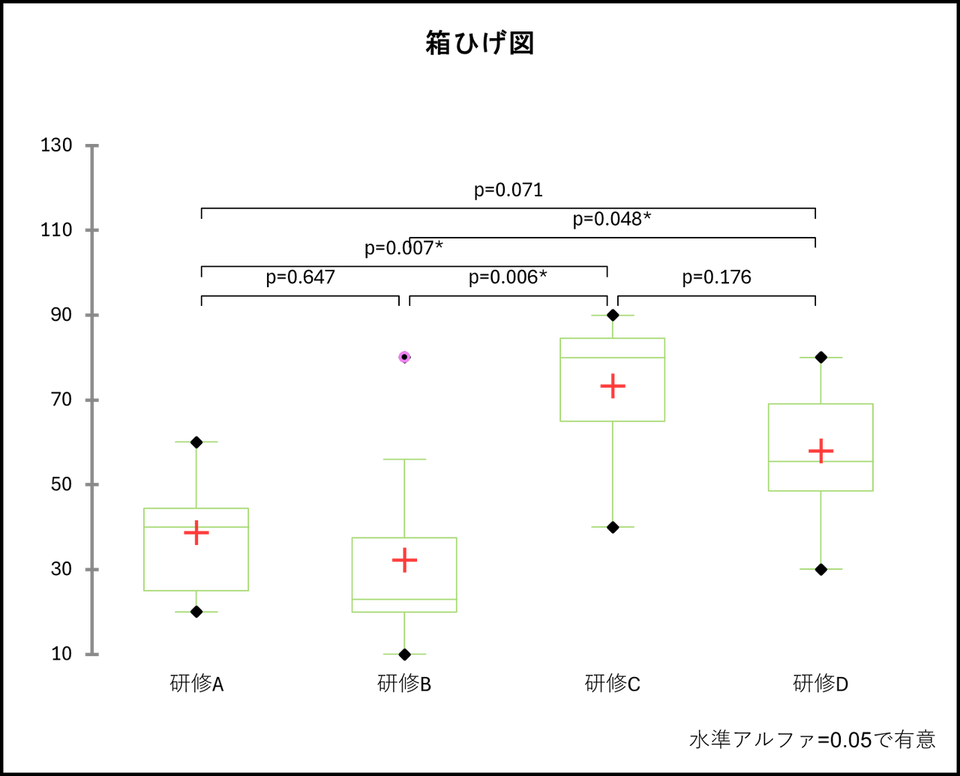
この図から研修C のスコアが最も高く、研修B のスコアが最も低いということが視覚的にも確認できます。また箱ひげ図にはグループ間をつなぐ線と共にp値が表示されています。p=0.007* や p=0.048* のように、アスタリスクが付いているペアは「統計的に有意な差がある」ことを示しています。
まとめ
クラスカル・ウォリス検定は、データの分布形状を問わずに3つ以上のグループを比較できる、非常に汎用性の高い手法です。「データが正規分布していない」「サンプル数が少ない」「順位データしかない」といった、現場でよくある悩みに対して有効な解決策となります。XLSTAT では使い慣れたExcel 上で多重比較(どのペアに差があるかの特定)や結果の可視化(箱ひげ図)まで自動で出力することが可能です。
参考文献
- XLSTAT: Kruskal-Wallis test in Excel
- 統計Web. クラスカル=ウォリス検定.
https://bellcurve.jp/statistics/glossary/1252.html
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したクラスカル・ウォリス検定はすべてのライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。

