XLSTAT によるフリードマン検定:同じ対象から繰り返し測定したデータを比較する
- フリードマン検定とは?
- 反復測定分散分析との違い
- フリードマン検定の計算過程(理論説明)
- フリードマン検定を実行するためのデータセット
- XLSTAT でフリードマン検定を実行する手順
- フリードマン検定の結果の解釈
- まとめ
- 参考文献
- XLSTAT の無料トライアル
フリードマン検定とは?
フリードマン検定は、同じ人や物に対して3つ以上の条件で繰り返し測定したデータ(対応のあるデータ)に、条件間で統計的に意味のある差があるかどうかを調べる手法です。例えば、「10人の審査員が4種類のチーズの硬さをそれぞれ評価した」「複数の患者それぞれに3種類の鎮痛剤を投与し、各鎮痛剤使用時の痛みの程度を比較した」といった場面で用いられます。
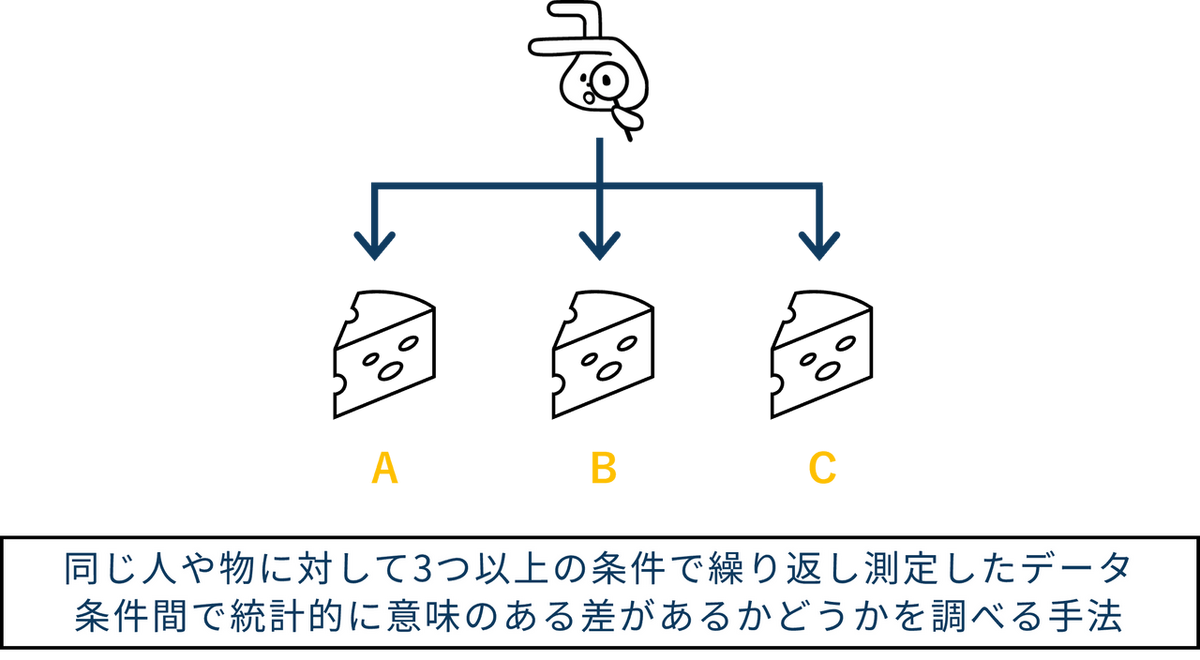
このように、同じ対象(人・物)から繰り返し得たデータを比較したい場合に使える手法として、反復測定分散分析 がありますが、反復測定分散分析を使うには「データが正規分布に従う」「等分散である」といった条件を満たす必要があります。フリードマン検定は、これらの条件を満たさないときに代わりに使えるノンパラメトリック検定です。
ノンパラメトリック検定とは、データの分布の形(正規分布かどうか)を問わない検定のことです。フリードマン検定は、具体的な測定値ではなく「順位」に変換して分析を行うため、外れ値に影響されにくく、順序尺度(リッカート尺度など)のデータにも使えるという特徴があります。
反復測定分散分析との違い
フリードマン検定と反復測定分散分析は、どちらも「同じ対象を3つ以上の条件で繰り返し測定したデータ」に使う検定ですが、重要な違いがあります。
反復測定分散分析は実際の測定値(平均値)をもとに計算を行うパラメトリック検定です。データが正規分布していれば、平均値の違いを高い精度で検出できるため検出力が優れています。しかし、極端に大きな値や小さな値(外れ値)がデータに含まれていると、平均値が引っ張られてしまい、正しい結論を導けなくなる恐れがあります。
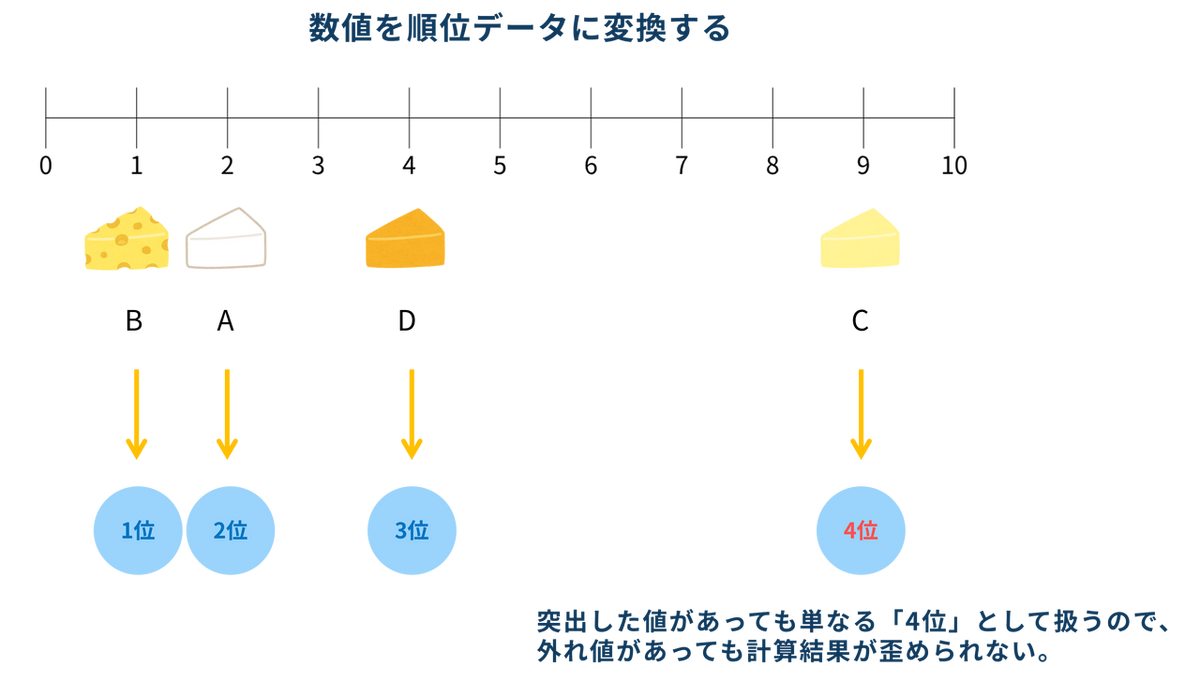
一方、フリードマン検定は測定値を「順位」に変換してから分析します。例えば、ある審査員が4種類のチーズを評価した際に、スコアが「2, 1, 9, 3」だったとします。フリードマン検定ではこのスコアの大小だけに着目し、小さい順に1位、2位、3位、4位と順位をつけます。「9」という突出した値があっても、順位としては「4位(一番大きい)」として扱われるだけなので、計算結果を歪めることがありません。
以下に両者の違いをまとめます。
| 比較項目 | 反復測定分散分析 | フリードマン検定 |
| 種類 | パラメトリック検定 | ノンパラメトリック検定 |
| 比較対象 | 平均値 | 順位(順位和) |
| 正規分布 | 必要 | 不要 |
| 外れ値への耐性 | 弱い(影響を受けやすい) | 強い(順位に変換するため影響を受けにくい) |
| 検出力 | 前提を満たせば高い |
反復測定分散分析よりやや低い |
| 対応するデータの尺度 | 間隔尺度・比率尺度 | 順序尺度でも使える |
使い分けの目安として、データが正規分布に従い、等分散性も満たしているなら反復測定分散分析を使い、正規分布に従わない場合や、サンプルサイズが小さい場合、順序尺度のデータを扱う場合にはフリードマン検定を使います。
フリードマン検定の計算過程(理論説明)
フリードマン検定がどのような仕組みで判定を行っているのか、簡単な事例を使って計算の流れを追ってみましょう。
事例:3種類の学習法の効果を比較する
ある大学で、4人の学生が3種類の学習法(A:講義、B:動画、C:実習)をそれぞれ体験し、各学習法でテストを受けました。学習法によってテストの得点に差があるかを検証します。
データ(テスト得点)

同じ学生が全ての学習法を体験しているため「対応のあるデータ」です。得点の傾向をみると学習法C が高そうですが、たまたまこの結果が出ただけかもしれません。フリードマン検定を使って統計的に確かめてみましょう。
ステップ1:各学生(行)の中で順位をつける
フリードマン検定では、各学生の中で得点を小さい順に並べ、1, 2, 3 と順位をつけます。ここがクラスカル・ウォリス検定 との最大の違いです。クラスカル・ウォリス検定は、フリードマン検定と同様に3つ以上のグループを比較するノンパラメトリック検定ですが、各グループ間に対応がない場合に用いられます。 クラスカル・ウォリス検定では全データを混ぜて順位をつけますが、フリードマン検定では各行(各被験者)の中だけで順位をつけます。
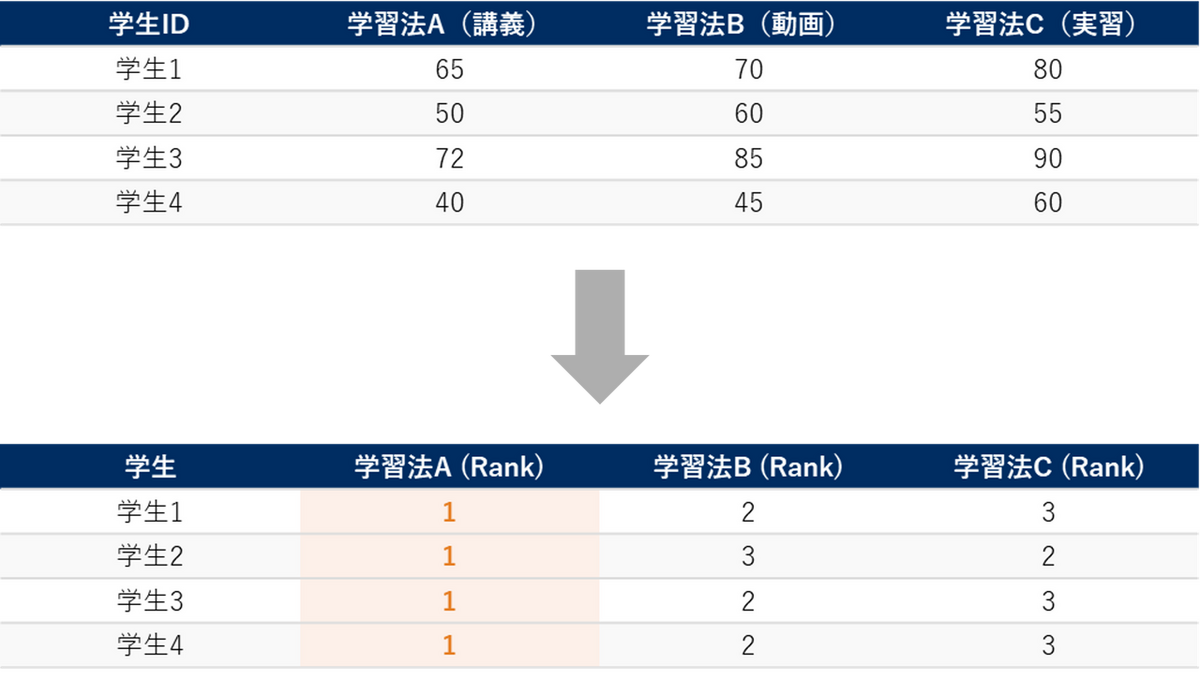
ステップ2:各条件(列)ごとに順位和を求める
各列(条件)の順位を縦方向に足し合わせます。これを「順位和(Ri)」と呼びます。
- 学習法A の順位和:RA = 1 + 1 + 1 + 1 = 4
- 学習法B の順位和:RB = 2 + 3 + 2 + 2 = 9
- 学習法C の順位和:RC = 3 + 2 + 3 + 3 = 11
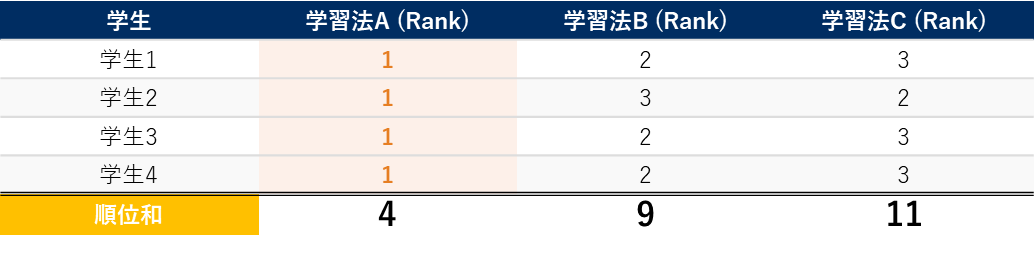
もし3つの学習法に全く差がなければ、順位はランダムに割り当てられるため、各条件の順位和はほぼ同じ値になるはずです。しかし、今回は学習法A の順位和が4と非常に小さく、学習法C は11 と大きくなっています。この「順位和のばらつき」が偶然では説明できないほど大きいかどうかを、次のステップで統計的に検定します。
ステップ3:検定統計量 Q を計算する
フリードマン検定の公式にそれぞれの値を代入して、検定統計量 Q を求めます。
公式:
Q = 12 / [n × k × (k + 1)] × Σ(Ri²) − 3n(k + 1)
※n = 4(学生の数 = ブロック数)、k = 3(学習法の数 = 条件の数)です。
代入と計算:
Σ(Ri²) = 4² + 9² + 11² = 16 + 81 + 121 = 218
Q = 12 / (4 × 3 × 4) × 218 − 3 × 4 × 4
Q = 12 / 48 × 218 − 48
Q = 0.25 × 218 − 48
Q = 54.5 − 48
Q = 6.5
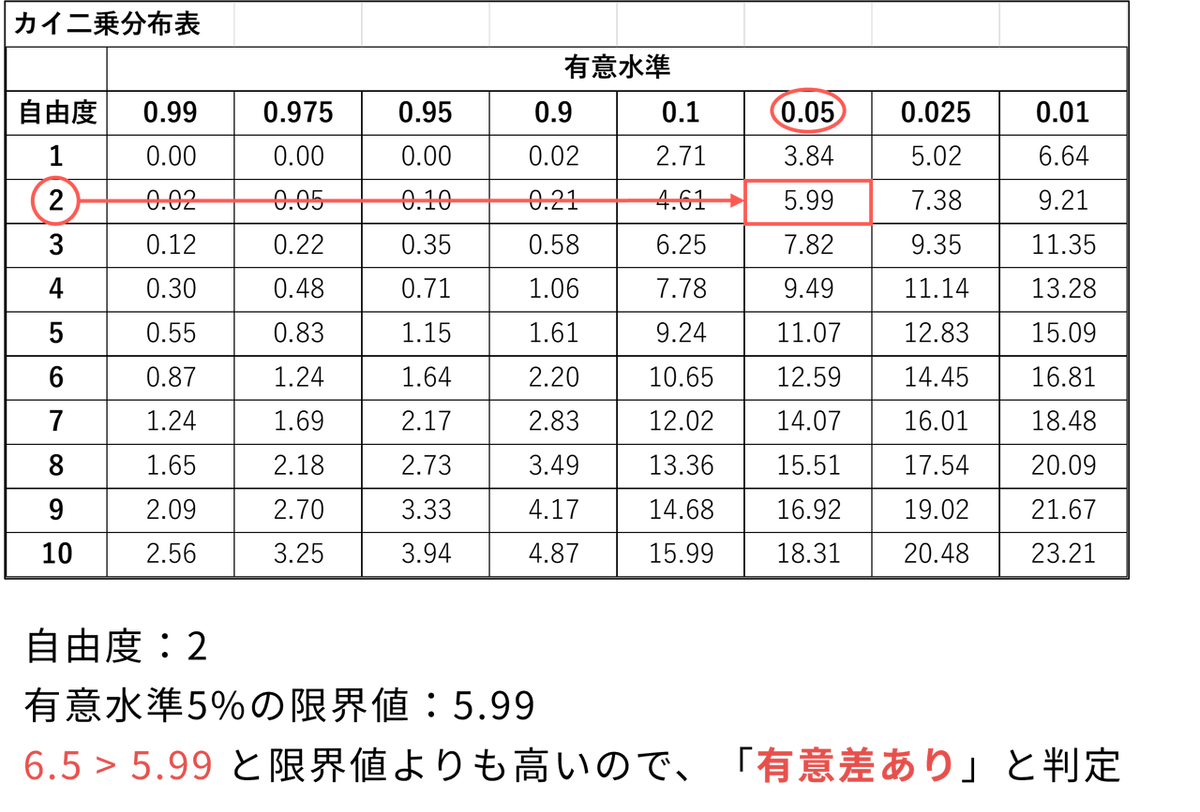
ステップ4:カイ二乗分布と比較して判定する
フリードマン検定の統計量 Q は、近似的に自由度 k − 1 のカイ二乗分布に従います。今回は自由度 = 3 − 1 = 2 です。カイ二乗分布表で自由度「2」、有意水準「0.05」の臨界値を確認すると「5.99」です。計算した Q = 6.5 はこの臨界値を超えているため、「有意水準5%で、3つの学習法の間にテスト得点の有意な差がある」 と結論づけることができます。
【注意】
フリードマン検定で分かるのは、「少なくとも1つの条件が他と異なる(全体のどこかに差がある)」ということまでです。「学習法A と学習法C が違うのか」「学習法B と学習法C が違うのか」を特定するためには、さらに事後検定(多重比較)を行う必要があります。XLSTAT では Nemenyi 法などによる多重比較を自動で実行できます。
フリードマン検定を実行するためのデータセット
計算の仕組みがわかったところで、今度は実際のデータとXLSTAT を使って分析してみましょう。
事例:10人の審査員による4種類のチーズの硬さの評価
ある食品メーカーで、4種類のチーズ(Cheese1〜Cheese4)の硬さを官能検査で評価しました。10人の審査員(Expert1〜Expert10)がそれぞれ4種類すべてのチーズを評価し、硬さのスコアを記録しています。スコアは数値が大きいほど「硬い」と評価されたことを表します。チーズの種類によって硬さのスコアに差があるかを検定します。

各列が1つのチーズの種類に対応し、各行が1人の審査員に対応しています。同じ審査員が4種類すべてのチーズを評価しているため「対応のあるデータ」です。
サンプルデータのダウンロードはこちらから
dataset-for-Friedman-test.xlsmXLSTAT でフリードマン検定を実行する手順
-
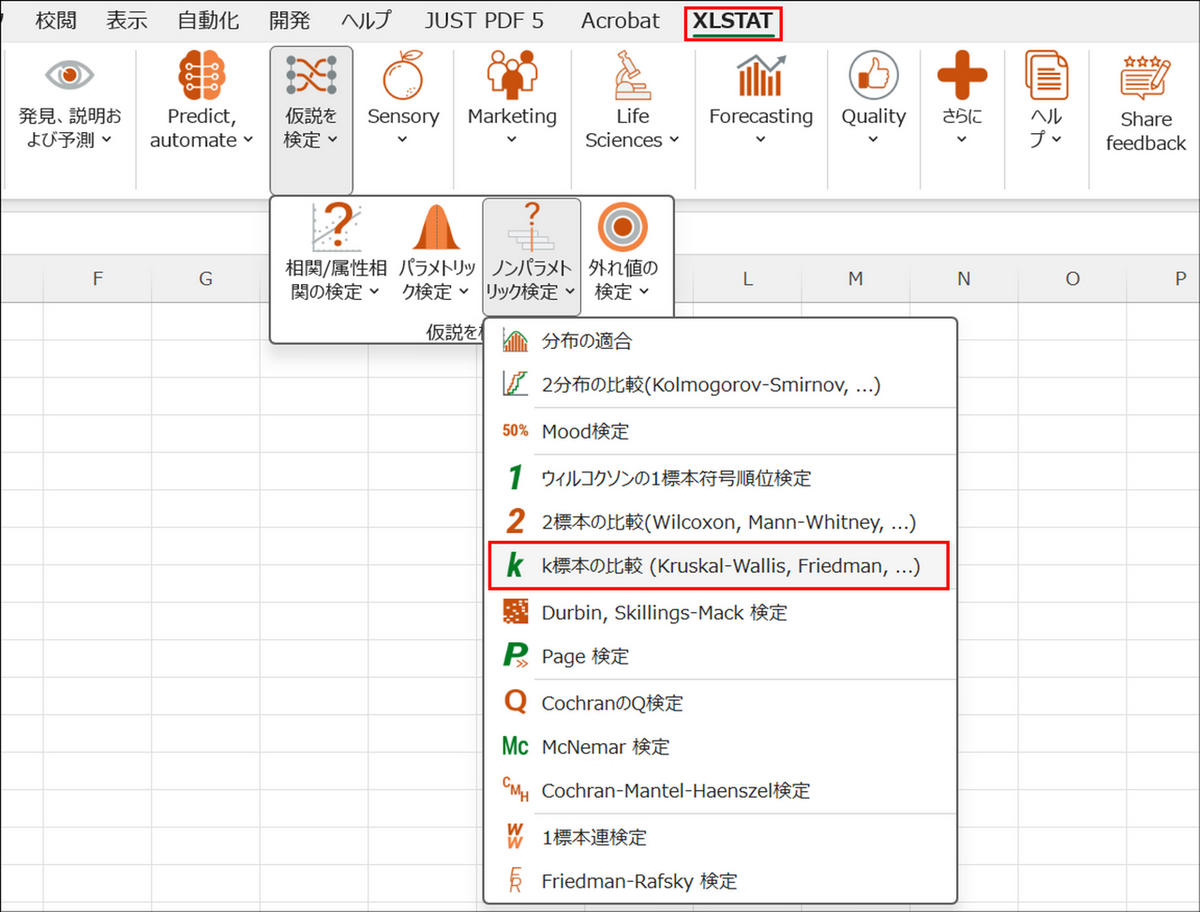
XLSTAT を起動し、[仮説を検定] > [ノンパラメトリック検定] > [k標本の比較 (Kruskal-Wallis, Friedman, ...)] を選択します。
-
ダイアログボックスが表示された[一般] タブで以下の設定をします。
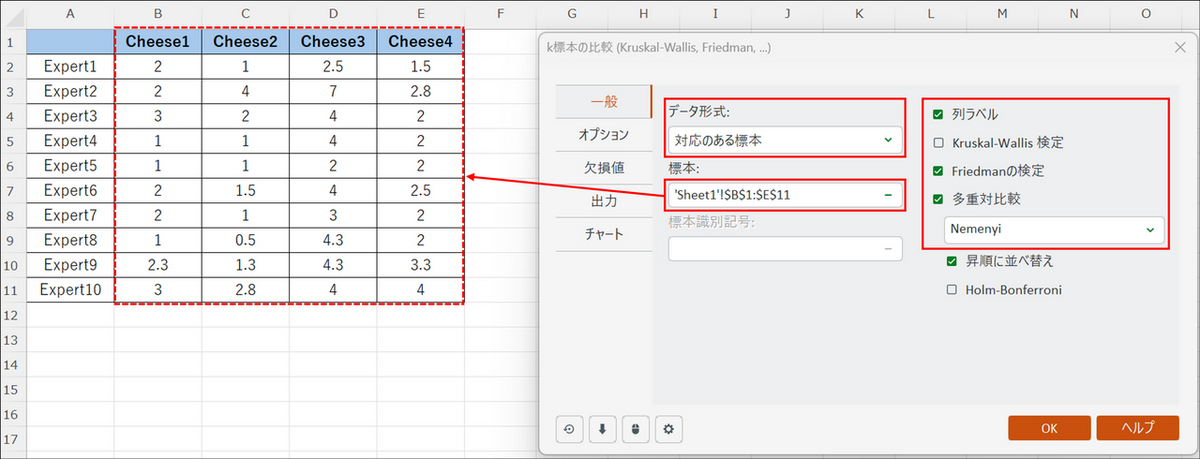
- データ形式:[対応のある標本] を選択
- 標本:シート上のCheese1〜Cheese4 のデータ範囲(4列分)をすべて選択
- 列ラベル:列名を含めてデータを選択した場合は、チェックを入れる
- 多重対比較:チェックを入れ、[Nemenyi] を選択
-
[チャート] タブに切り替え、以下のように設定します。
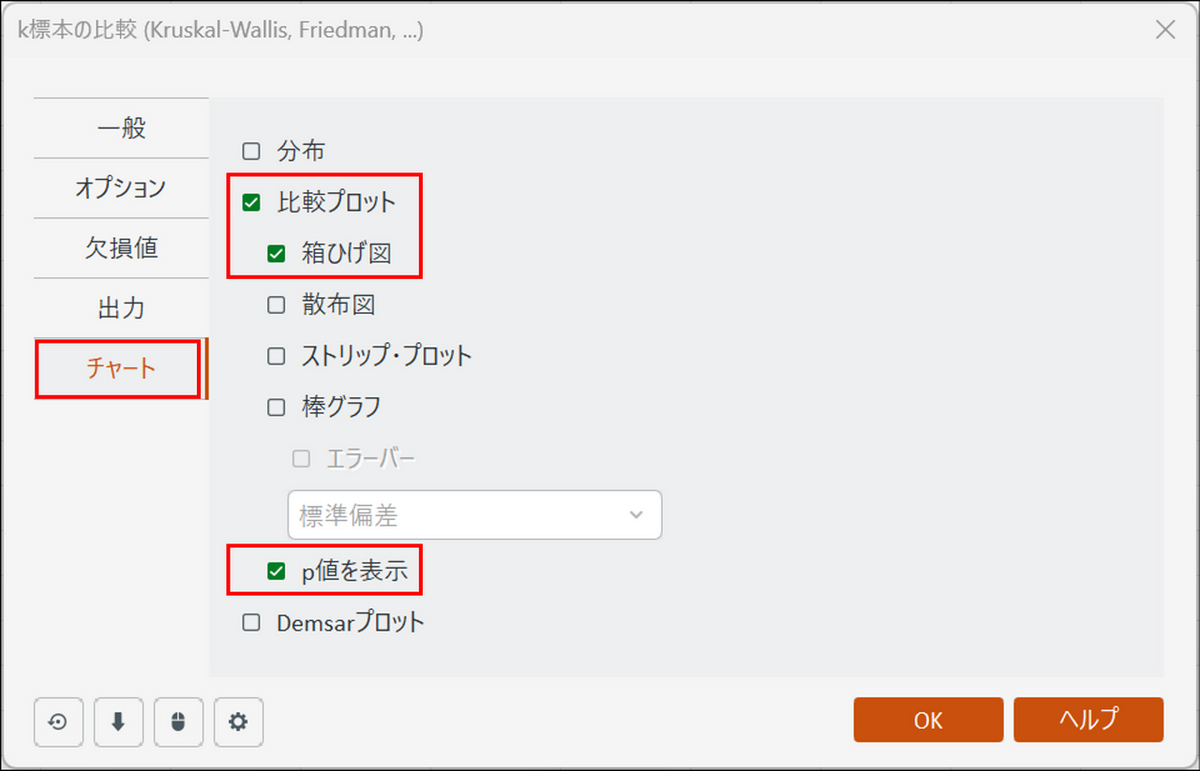
-
[OK] ボタンをクリックすると計算が始まり、結果が別シート(Friedman)に出力されます。
フリードマン検定の結果の解釈
記述統計
結果の最初には「記述統計」の表が出力されます。分析対象のデータの概要を確認するために使います。
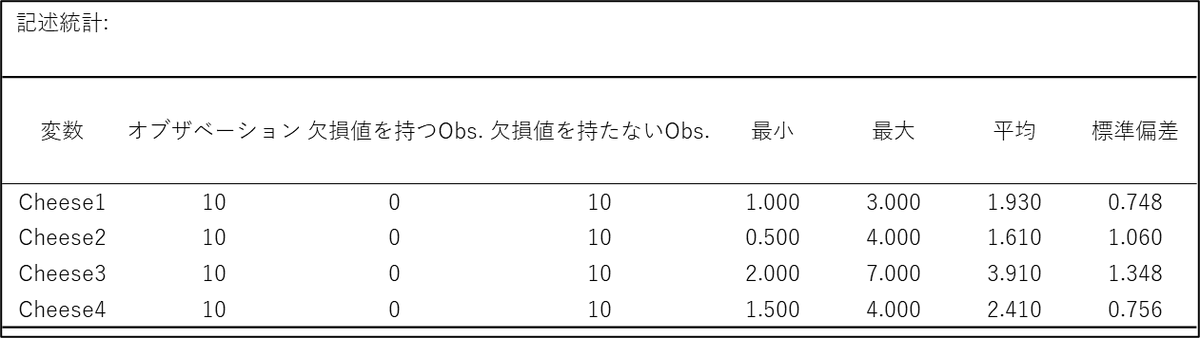
この結果から、4種類のチーズの中で Cheese3 の平均スコアが3.91 と最も高く(最も硬い)、Cheese2 が1.61 と最も低い(最も柔らかい)ことがわかります。ただし、この段階ではまだ「統計的に有意な差かどうか」は判断できません。
フリードマン検定
次に、フリードマン検定の結果を確認します。

今回の結果ではp値が0.0001 未満であり、有意水準0.05 よりも十分に小さいため、「4種類のチーズの硬さのスコアには、統計的に有意な差がある」と判断します。つまり、少なくとも1つのチーズの硬さが、ほかのチーズと異なるということです。
多重比較検定(Nemenyi 法)
フリードマン検定で全体に有意差があることが確認できたため、次に「どのチーズ間で差があるのか」を多重比較の結果で確認します。まず、順位和と平均順位の表を見ます。
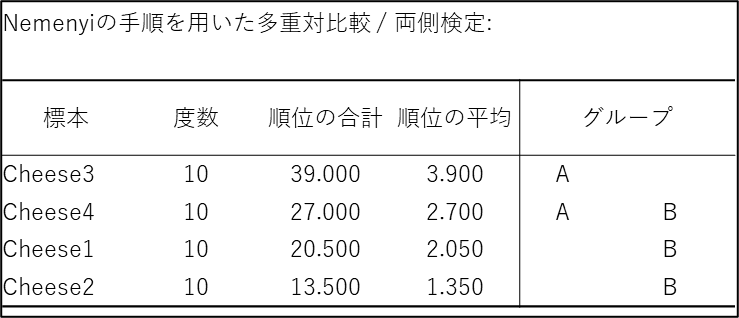
「グループ」の列に注目してください。同じアルファベットが含まれるチーズ同士は「統計的に有意な差がない」ことを示しています。Cheese4、Cheese1、Cheese2 はいずれもグループ「B」に属しており、互いに有意差がありません。一方、Cheese3 はグループ「A」のみに属しており、グループ「B」のみに属するチーズ(Cheese1 と Cheese2)とは有意に異なることがわかります。
次に、一対比較のp値の表を見ると、具体的にどのペアで有意差が出ているかを確認できます。

赤くハイライトされているセルが有意差あり(p < 0.05)の組み合わせです。
【有意差あり(違いがある)】
- Cheese1 vs Cheese3:p = 0.008
- Cheese2 vs Cheese3:p < 0.001
【有意差なし(違いがあるとは言えない)】
- Cheese1 vs Cheese2:p = 0.620
- Cheese1 vs Cheese4:p = 0.674
- Cheese2 vs Cheese4:p = 0.092
- Cheese3 vs Cheese4:p = 0.163
この結果から、Cheese3(平均スコア3.91 で最も硬いチーズ)が、Cheese1 および Cheese2 と有意に異なることが確認できました。一方、Cheese4 はいずれのチーズとも有意差が認められず、中間的な位置にあります。このように、事後検定を行うことで「なんとなく全部違う気がする」ではなく、「統計的に確実に違うと言えるのはこのペアだけ」という厳密な結論を導き出すことができます。
まとめ
フリードマン検定は、同じ対象から繰り返し測定した3つ以上の条件のデータに対して、条件間に差があるかを調べるためのノンパラメトリック検定です。データの分布の形を問わないため、「データが正規分布していない」「サンプルサイズが小さい」「順序尺度のデータしかない」といった、反復測定分散分析の前提条件を満たせない場面で有力な選択肢になります。XLSTAT を使えば、使い慣れた Excel 上でフリードマン検定の実行から多重比較(Nemenyi法によるペア間の有意差確認)までを簡単に行うことができます。
参考文献
- XLSTAT: Friedman nonparametric test in Excel. https://community.lumivero.com/s/article/6737-friedman-non-parametric-test-excel-tutorial?language=en_US
-
Friedman test https://www.xlstat.com/solutions/features/friedman-test
-
統計Web. フリードマン検定. https://bellcurve.jp/statistics/glossary/1046.html
- numiqo. Friedman Test Tutorial. https://numiqo.com/tutorial/friedman-test
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したフリードマン検定はすべてのライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。
