XLSTAT によるマン・ホイットニーのU検定:正規分布に従わない2つのグループを比較する
- マン・ホイットニーのU検定とは?
- ノンパラメトリック検定とは?
- マン・ホイットニーのU検定の計算過程(理論説明)
- マン・ホイットニーのU検定を実行するためのデータセット
- マン・ホイットニーのU検定を実行する手順
- マン・ホイットニーのU検定の結果の解釈
- まとめ
- 参考文献
- XLSTAT の無料トライアル
マン・ホイットニーのU検定とは?
マン・ホイットニーのU検定とは、2つの独立したグループ(標本)の間に、統計的に意味のある差があるかどうかを判定する分析手法です。例えば「A 支店とB 支店の顧客満足度(5段階評価)を比較したい」、「数人ずつの小さなデータで、どちらの施策が効果的か確かめたい」といった場面で用いられます。2群の比較ではt検定が一般的ですが、データ数が少なかったり、極端な値(外れ値)があったり、あるいはアンケートの「満足〜不満」のような順序データの場合、一般的な「平均値の比較(t検定)」は統計的に不適切なことがあります。そこで役立つのがこのページでご紹介するマン・ホイットニーのU検定です。
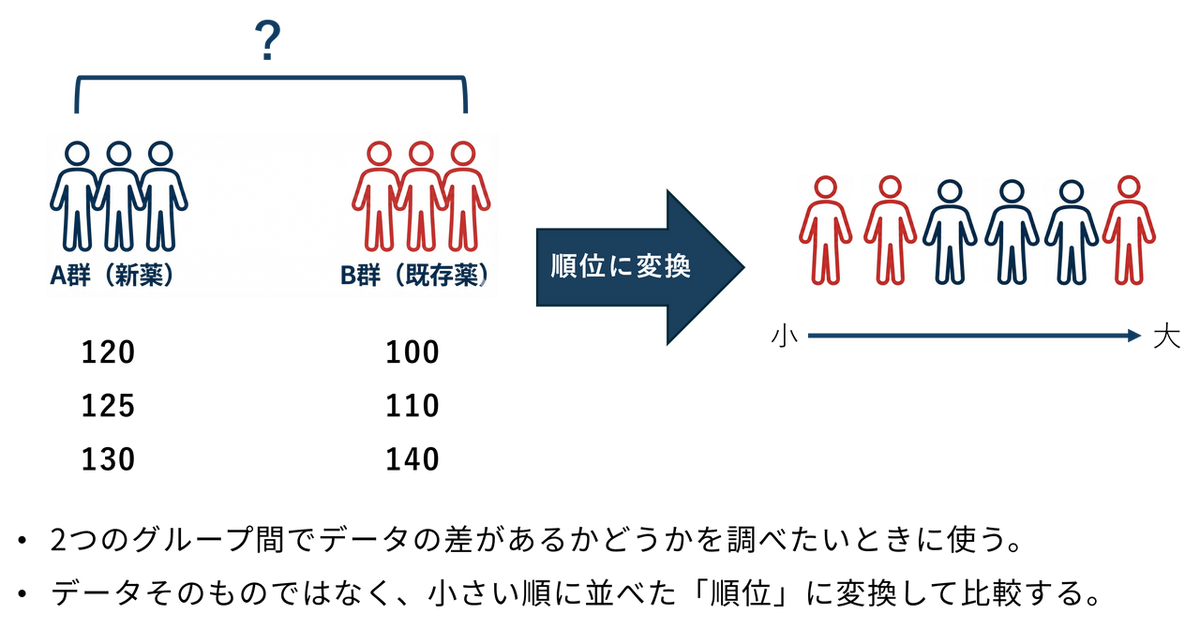
マン・ホイットニーのU検定では、データの値そのものではなく、データを並べ替えたときの順位(ランク)を使って、2つのグループ間に統計的な差があるかを判定します。平均値に頼らず、「どちらのグループが全体的に上位(または下位)に位置しているか」を評価するため、データの偏りや外れ値の影響を受けにくいという強みがあります。
ノンパラメトリック検定とは?
統計的仮説検定には大きく分けて「パラメトリック」と「ノンパラメトリック」の2種類があります。マン・ホイットニーのU検定はノンパラメトリック検定に分類される手法です。
パラメトリック検定(例:t検定)
母集団が特定の分布(主に「正規分布」=きれいな山型)に従っていることを前提条件とします。前提条件が満たされている場合は高い検出力を持ちますが、データが歪んでいたり、外れ値が含まれていたりすると、誤った結論を導くリスクがあります。

ノンパラメトリック検定(例:マン・ホイットニーのU検定)
母集団が特定の分布に従っていることを仮定しません(分布によらない)。データの「値」そのものではなく、「順位」や「大小関係」に着目して分析を行います。データ数が少ない場合や、極端な外れ値がある場合、あるいはアンケートの評価段階のようなデータに対しても、ロバスト(頑健)な結果を得ることができます。
「データの分布形状に不安がある場合」や「サンプルサイズが小さい場合」は、より安全な選択肢としてノンパラメトリック検定を採用するのが定石です。
2群・多群比較で用いる検定法の使い分け
| 分析の目的 | パラメトリック | ノンパラメトリック |
| 独立した2群の比較 (A 支店 vs B 支店、男性 vs 女性) |
t検定 (スチューデントのt検定 / ウェルチのt検定) |
マン・ホイットニーのU検定 |
| 対応のある2群の比較 (同一対象の「施策前 vs 施策後」など) |
対応のあるt検定 | ウィルコクソンの符号付順位検定 |
| 3群以上の比較 (A製品 vs B製品 vs C製品) |
分散分析(ANOVA) | クラスカル・ウォリス検定 |
マン・ホイットニーのU検定の計算過程(理論説明)
XLSTAT を使えば簡単に検定を実行できますが、裏側でどのような計算が行われているかを知っておくと、結果の理解が深まります。ここでは簡単な事例で計算の流れを見てみましょう。
事例:猫のおやつ比較
ある猫カフェで、2種類のおやつ(おやつA、おやつB)のどちらが人気かを調べることにしました。数匹の猫にそれぞれおやつを与えて、「何個食べたか」を記録しました。以下はその結果です。
- グループA(おやつA):3匹の猫が食べた個数 → 3個、 5個、 8個(n=3)
- グループB(おやつB):4匹の猫が食べた個数 → 4個、7個、10個、12個(n=4)
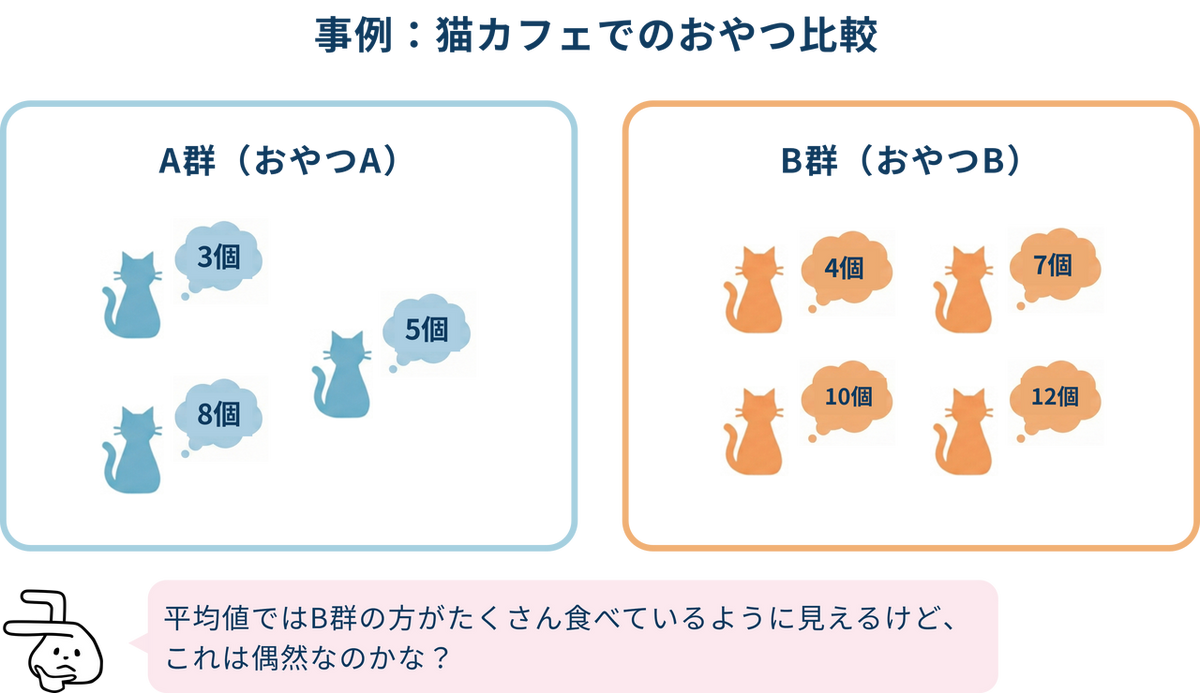
単純に平均値を比較すると、A群が5.3個に対し、B群が8.25個なので、おやつB の方が人気がありそうですが、今回の調査ではたまたまこのような結果が出ただけという可能性も考えられます。そこでマン・ホイットニーのU検定を使って、「おやつB の方がよく食べられている(差がある)と言えるか?」を検定します。
ステップ1:すべてのデータを混ぜて順位をつける
まず、グループAとB を区別せず、すべてのデータを小さい順に並べ替え、順位をつけます。
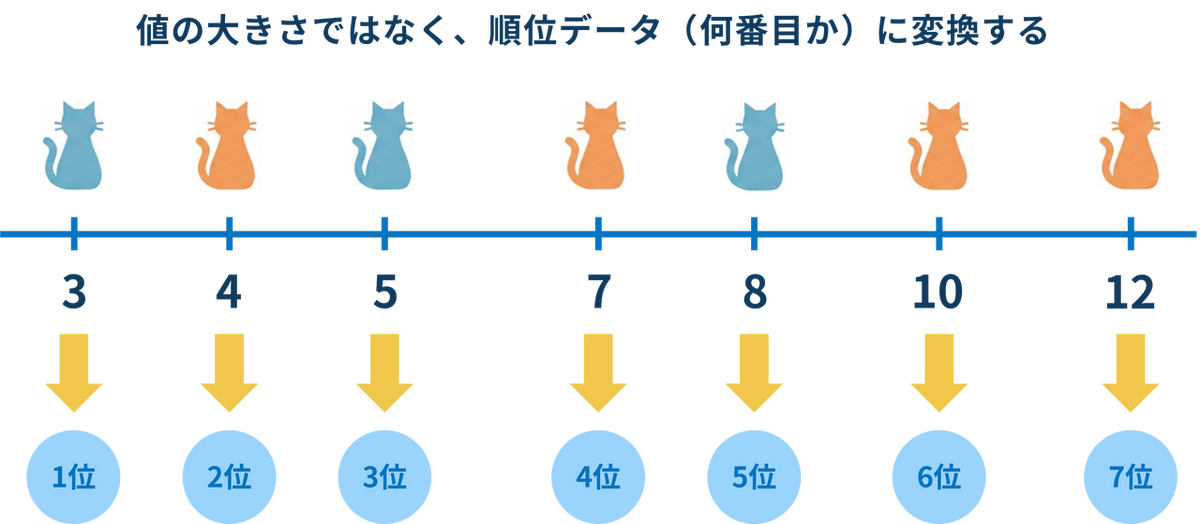
もし同じ値(同順位)があった場合は、順位の平均をとります(例:3位と4位が同じ値なら、両方3.5位にする)。今回はすべてバラバラなのでそのままです。
ステップ2:グループごとに「順位の合計」を出す
それぞれのグループの「順位」だけを足し算します。これを「順位和」と呼びます。
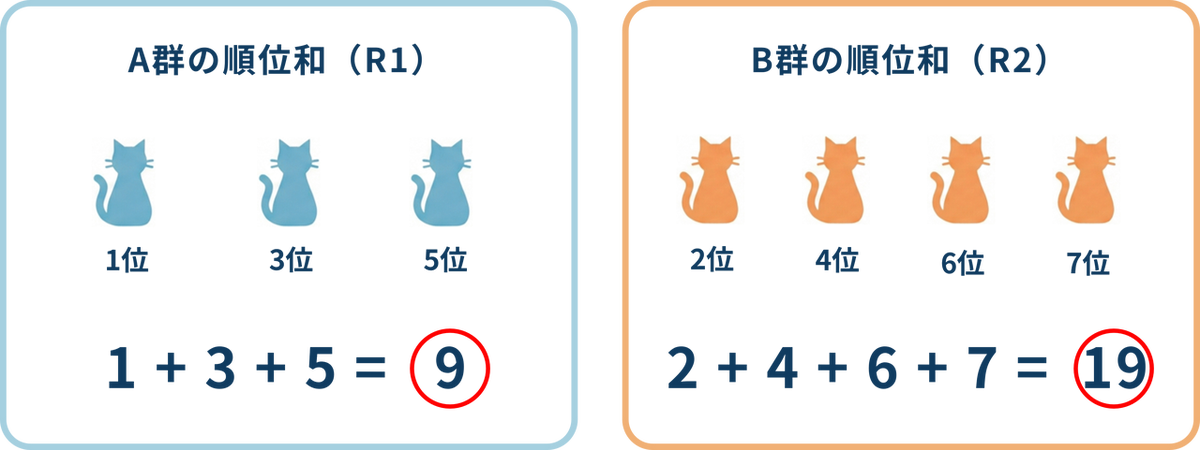
- グループA の順位和(R1):1 + 3 + 5 = 9
- グループB の順位和(R2):2 + 4 + 6 + 7 = 19
ここまでの直感的な理解として、「もしグループ間に差がなければ、順位の合計は大体同じくらいになるはず(データ数の違いは考慮が必要)」と考えます。今回はB 群の方が合計が大きいです。
ステップ3:U値を計算する
公式に当てはめて検定統計量Uを計算します。少し複雑に見えますが、四則演算で求められます。
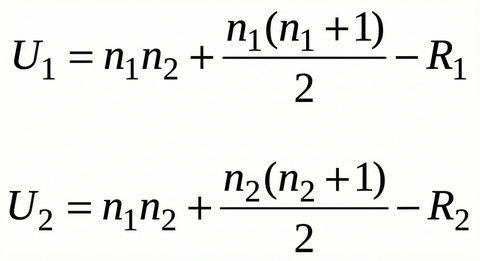
n1 = グループA のデータ数(3)
n2 = グループB のデータ数(4)
R1, R2 = ステップ2で計算した順位和(9, 19)
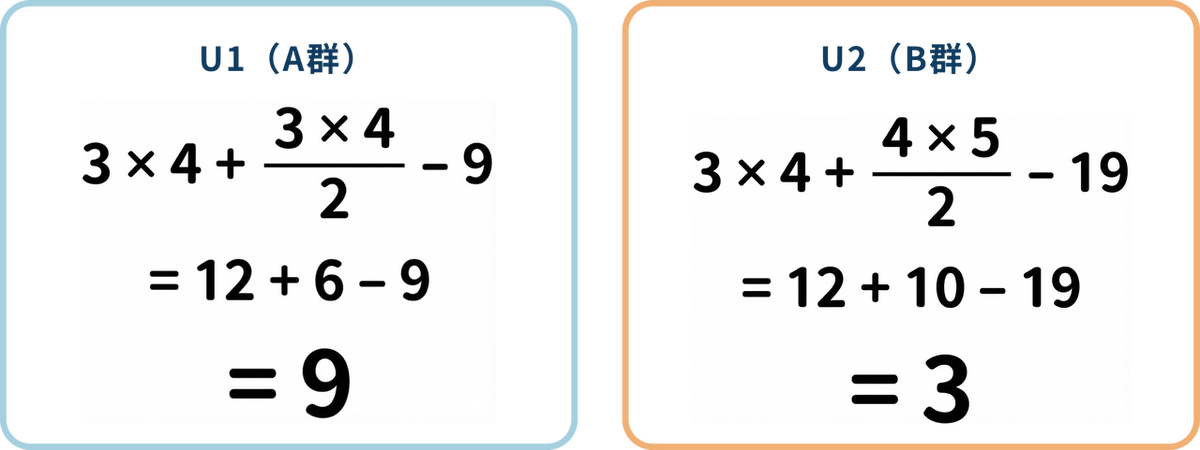
グループA の U1
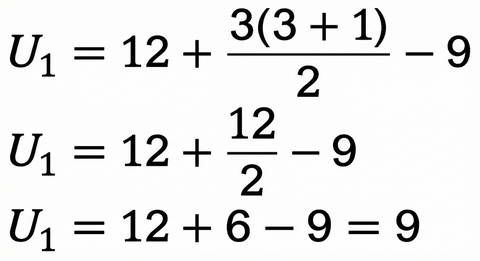
グループB の U2
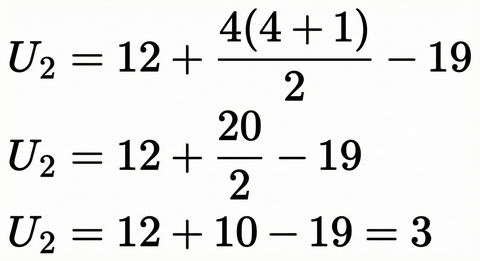
ステップ4:小さい方の値を「U値」として、検定表と比較する
計算して出た2つのU値(9 と 3)のうち、小さい方を採用します。今回の検定統計量は U = 3 となります。このU=3 という数字を使って、「偶然こうなったのか、それとも意味がある差なのか」を判定します。
-
U検定表(臨界値表)を見る
U検定表にて「n1=3, n2=4」で「有意水準5%(両側検定)」の基準値を探します。検定表で縦の「3」と横の「4」が交わるところを確認します。
※ 「-」の記号: サンプルサイズが小さすぎるため、U値が「0」であっても統計的に有意な差(5%未満)が出ないことを意味します。
-
U値と検定表の値を比較し、判断する
マン・ホイットニーのU検定では「計算した値が、表の値より小さい」ときに「有意差あり」となります。検定表で「3」と横の「4」が交わるところは「-」 です。これはサンプルサイズが小さすぎるため、U値が「0」であっても統計的に有意な差(5%未満)が出ないことを意味します。仮に0 であってもU=3 は基準値(0)よりも大きいため、「今回のデータだけでは、おやつB の方が人気があるとは断定できない(有意差なし)」という結果になります。このように、データ数が少ないときは、かなり極端な順位差(U値が0や1になるような状態)がないと、統計的に「差がある」とは認められにくいことがわかります。
マン・ホイットニーのU検定を実行するためのデータセット
計算のイメージがつかめたところで、次は実際のデータとXLSTAT を使って、もっと大量のデータを分析してみましょう。今回は、統計学で有名な「アヤメ(Iris)のデータセット」(Fisher, 1936)を使用します。

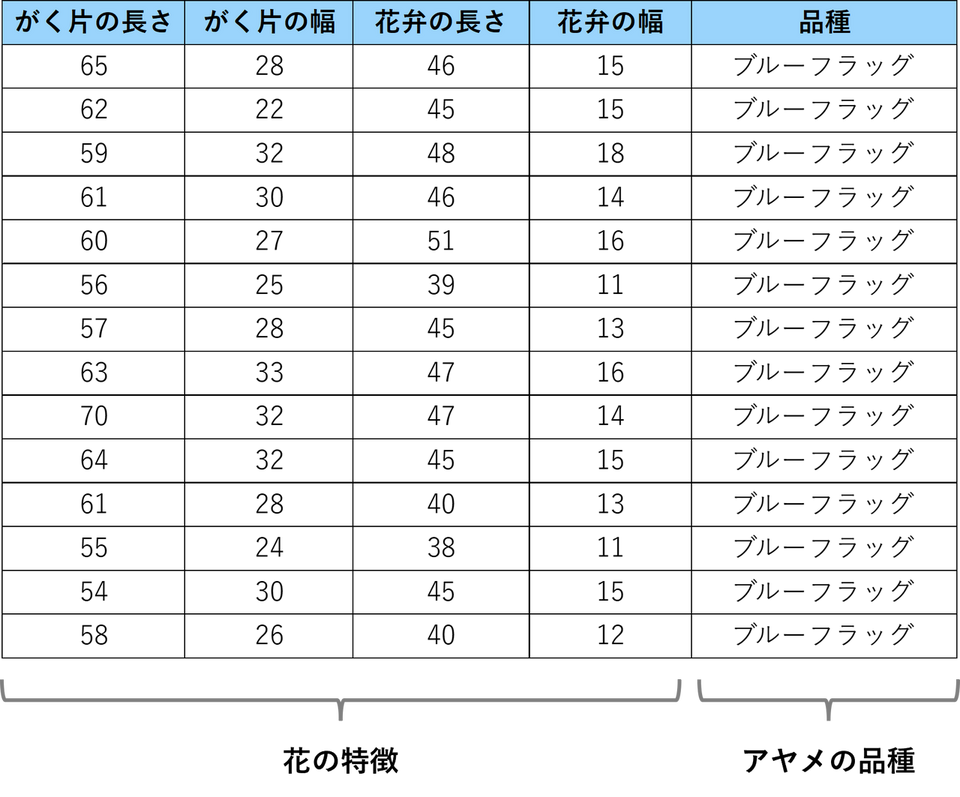
このデータセットには100本のアヤメの花について、以下のデータが記述されています。
- 花の特徴:
- がく片の長さ
- がく片の幅
- 花弁の長さ
- 花弁の幅
- アヤメの品種:
"ブルーフラッグ"、"バージニアアイリス" の2種類
オリジナルのデータセットには150本の花と3つの品種が含まれていますが、このチュートリアルではブルーフラッグとバージニアアイリスという2つの品種のみを抽出して使用します。
4つの変数(がく片の長さ、がく片の幅、花弁の長さ、花弁の幅)それぞれについて、ブルーフラッグとバージニアアイリスの間に明確な違いがあるかどうかを検証することが目的です。各変数について独立して2つの品種を比較します。
サンプルデータのダウンロードはこちらから
dataset-for-mann-whitney-u-test.xlsmマン・ホイットニーのU検定を実行する手順
-
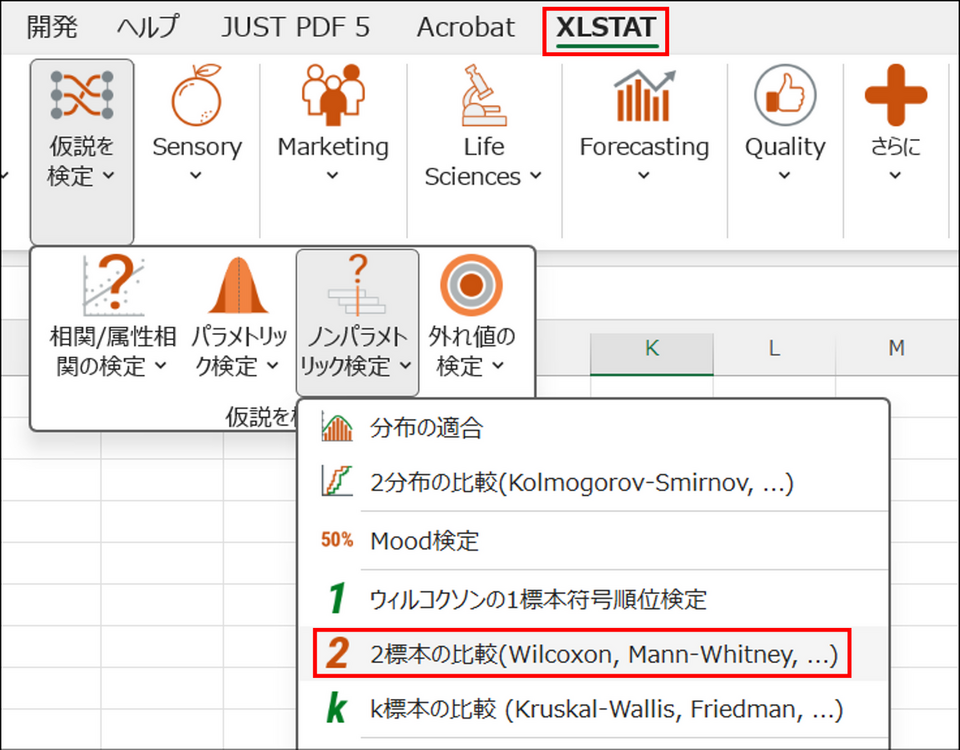
XLSTAT を起動し、[仮説を検定] > [ノンパラメトリック検定] > [2標本の比較 (Wilcoxon, Mann-Whitney, ...)] を選択します。
-
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
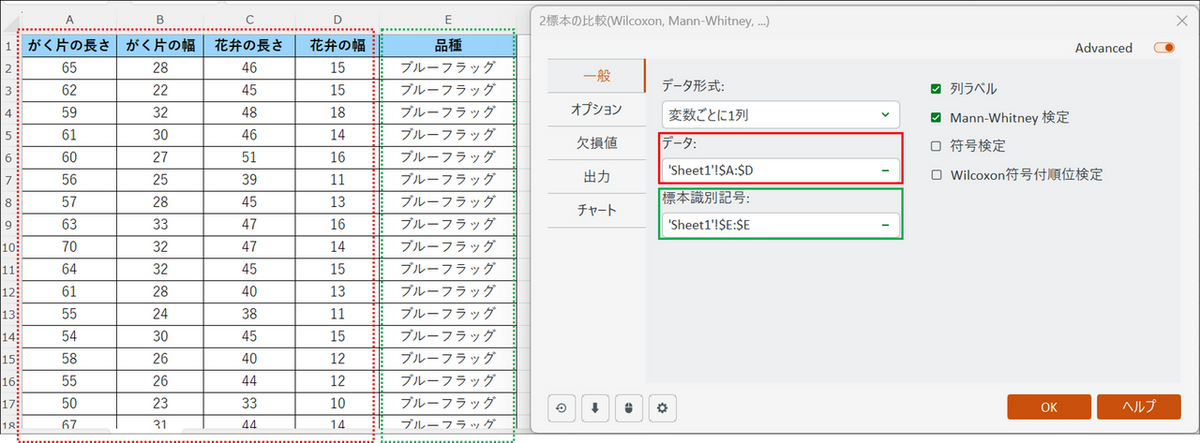
- データ形式:[変数ごとに1列] を選択
- データの選択:花の特徴が記載された列(4つのデータ列)をまとめて選択
- 標本識別記号:品種列を選択
-
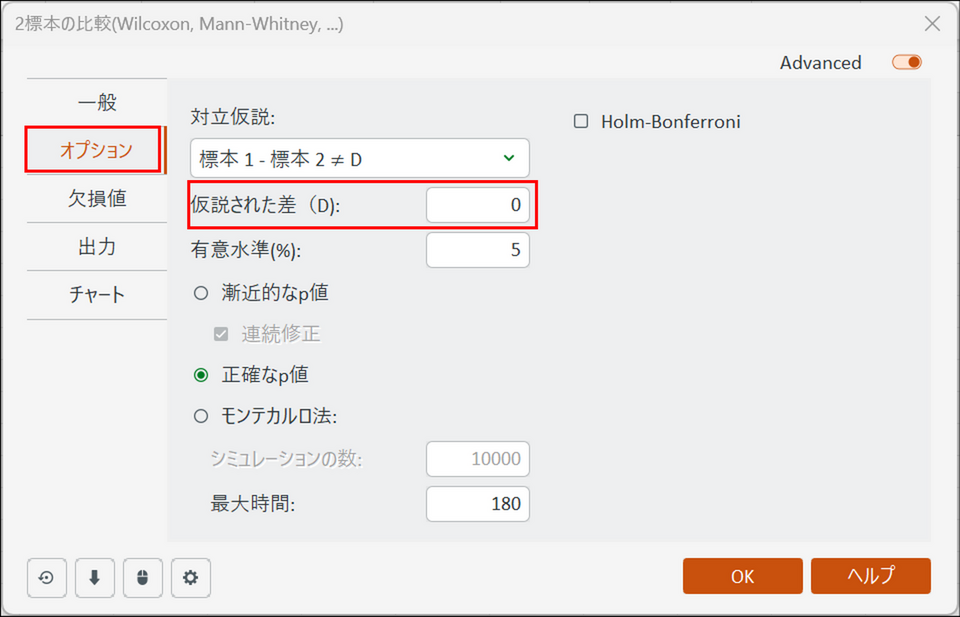
[オプション] タブに切り替え、[仮説された差 (D):] を「0」とします(「2つのグループに差はない」という前提で検定を始めます)。
-
[チャート] タブに切り替え、[比較プロット] と[箱ひげ図] にチェックを入れます。
-
[OK] ボタンをクリックすると、計算が始まり、結果が別シート(Mann-Whitney)に出力されます。
マン・ホイットニーのU検定の結果の解釈
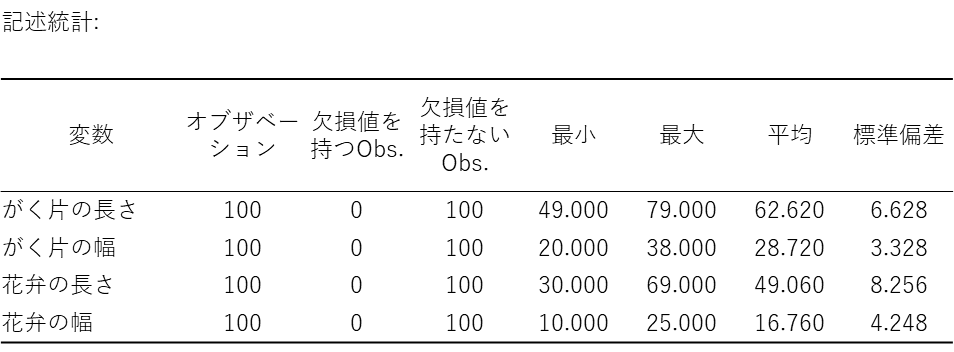
記述統計
結果の最初には「記述統計」の表が出力されます。マン・ホイットニーのU検定の前に、「分析対象のデータに間違いがないか」「どのような特徴があるか」をざっと把握するために使います。
マン・ホイットニーのU検定の結果
各変数ごとに検定結果が表示されます。ここで見るべきポイントは、表の中にある「p値(両側)」です。

「がく片の長さ」の検定結果では、「p値(両側)」は < 0.0001 となっています。これは、「2つの品種の間に差がない(偶然このようなデータになった)」確率が、0.01% 未満であることを示しています。統計的仮説検定では、一般的に「有意水準 = 0.05(5%)」を基準にし、p値が 0.05 より小さい場合、「統計的に有意な差がある」と判断します。今回の結果は、0.05 よりもはるかに小さい値なので、「2つの品種の間で、がく片の長さに統計的に有意な差がある」ことを意味します。
箱ひげ図
オプションで箱ひげ図にチェックを入れて実行した場合は、検定結果だけでなく、各グループの分布を示す箱ひげ図も出力されます。
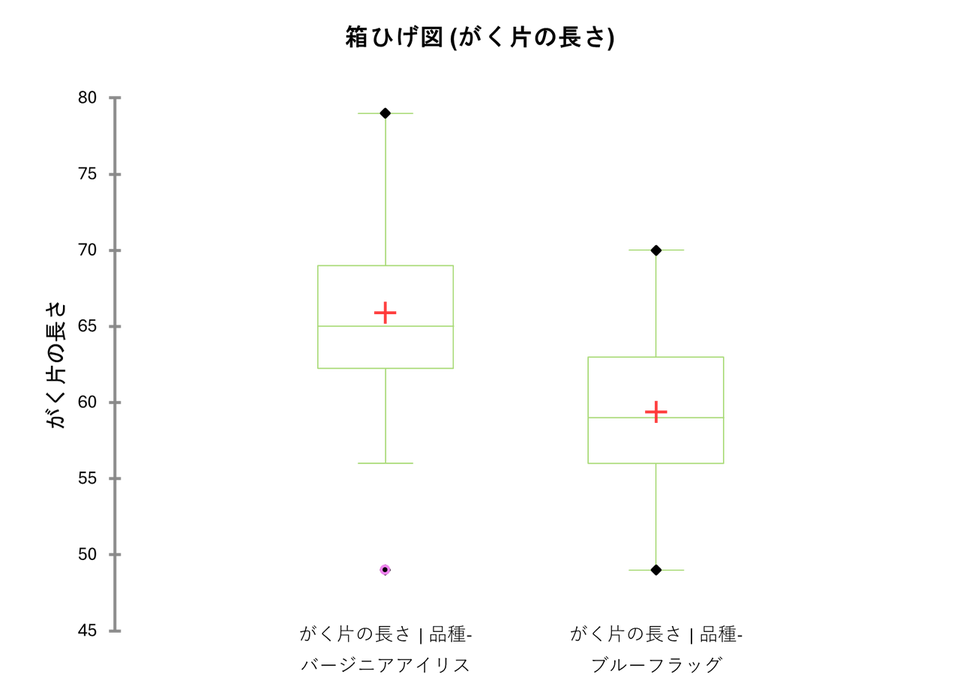
検定結果で「差がある」と出た場合、箱ひげ図を見ることで「どちらの品種の方が値が大きいのか」「データのばらつきはどうなっているか」を視覚的に確認できます。今回の例では、検定結果の通り、2つの品種の分布の位置がズレている(差がある)ことがグラフからも読み取れます。
まとめ
マン・ホイットニーのU検定は、2つのグループの「順位」に基づいて差を比較する手法です。データが正規分布していない場合や、サンプル数が少ない場合に、t検定の代わりとして使用することができます。XLSTAT を使用すれば、複雑な計算を意識することなく、簡単な操作でマン・ホイットニーのU検定を実行できます。統計的な有意差の有無を判断するだけでなく、箱ひげ図で視覚的に違いを確認することで、データの特性をより深く理解することができます。
参考文献
- Real Statistics Using Excel. Mann-Whitney Table.
https://real-statistics.com/statistics-tables/mann-whitney-table/
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したマン・ホイットニーのU検定はすべてのライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。


