質的研究に適しているのはQDAソフトか?テキストマイニングソフトか?
質的データ分析支援(QDA)ソフトとテキストマイニングソフトの間には頻出語の抽出・視覚化などの共通機能が多くあります。質的研究を行う方で、自身の研究にどちらが向いているか悩んで迷われる方も少なくありません。本稿ではQDAソフトであるNVivoとテキストマイニングソフトの共通機能、違いを通して、質的研究にはどのソフトが適しているか、説明していきます。
QDAソフトとテキストマイニングソフトの違い
質的研究は文字などの質的データを扱い、質的分析の手法を用いて、質的データを質的に分析します。一方、テキストマイニングでは文字などの質的データを定量化し、統計などの量的分析の手法を使用して量的に分析します。
どちらも質的データを扱いますが、分析の手法が質的なのか、量的なのかが異なっています。
QDAソフトは質的データを質的に分析するのをサポートします。それは、語られた言葉を文脈を含めて深く解釈することを助けます。
一方、テキストマイニングソフトは質的データを量的に分析するのをサポートします。それは、語られた言葉から傾向や特徴を発見することを助けます。
それぞれのソフトウェアの特徴を詳しく見ていきましょう。
質的データを定量化し、客観的に有用な情報を引き出すテキストマイニングソフト
一般的なテキストマイニングでは、最初に、テキストに含まれる品詞を識別する形態素解析(分かち書き)や、語句の間の修飾関係を分析する構文解析(係り受け解析)などの言語処理が行われる。その後、多変量解析による可視化や、辞書に基づくパタンマッチングによって、テキストデータの中から、何らかの意味のある情報を取り出す過程が支援される。(稲葉光行 and 抱井尚子 2011)
テキストマイニングソフトは使用されている言葉の頻度や前後の繋がりを解析し、質的データであるテキストを定量化することで、客観的な気付きを得やすくします。
テキストマイニングソフトは「定量化」と「可視化」が特長です。定量化することで、統計分析が可能になります。そのため、大量のデータの扱いに向いています。大量のデータを定量化することで、傾向や特徴を発見することを可能にします。
例えば、「頻度分析をすると『価格』『サポート』が多く出現した」「共起ネットワークを見ると『価格』と『不満』が強く結びついていた」 などの傾向や特徴を発見することができます。
一方、テキストマイニングは文字データのデータマイニングのため、文字に現れないものは分析することができません。いとうたけひこ氏が「『水平社宣言』テキストのパラドックス」と呼ぶものがあります。(いとう 2011)
「水平社宣言」は部落差別批判の声明ですが、「差別」「偏見」などのテキストは含まれていません。しかしテキストがないから本質が存在しないということはありません。読み解いてゆけば「差別」「偏見」に対する内容が含まれていることがわかるでしょう。
しかし、テキストマイニングではテキストに無いものは現れないため、見落としてしまう可能性があります。現れていても、出現頻度が少ない場合はデータのノイズとして切り捨てられることもあります。
また、テキストマイニングのテキストは文脈から切り離されたテキストであるため、単語の出現頻度や単語間の関係は分析できますが、文脈を読む、解釈するということが難しい面があります。
例えば「不満」というキーワードがあった場合、頻度を見るだけでは「不満がある」のか、「不満がない」のかはわかりません。頻出する単語が同じことを言及しているわけではないこともあります。
テキストマイニングの開発の現段階では「行間を読む」事ができない。文と文のつながり方を含む、いわゆる談話文法的な分析が不得意なのである。さらには語用論的限界がある。当てこすり、反語、皮肉、など状況的な意味や言外の意味を解析するのも不得意である。(いとう 2011)
データ量の問題もあります。テキストマイニングは量的に分析するため、分析対象のデータが少ない場合はパターンを得たりするのが難しいという面もあります。
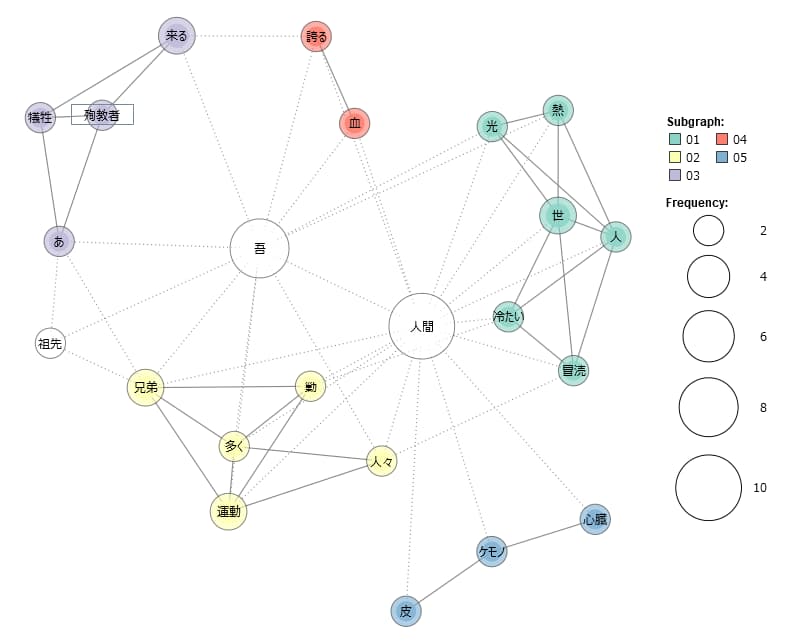
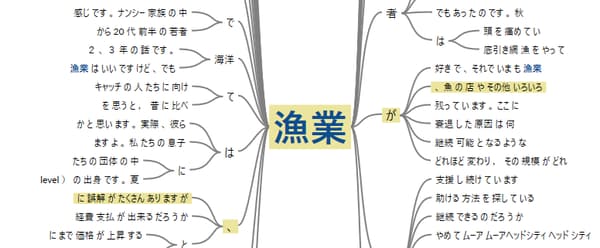
上記画像は水平社宣言をテキストマイニングし、共起ネットワーク(単語と単語が一緒に使われる関係性を線で結んで図示したもの)で表示した例です。元々のテキスト量が少ないこともあり、パターンを得たり、差別について読み取るのは難しい結果になっています。

テキストマイニングと実証主義パラダイム
大谷尚氏は質的データの扱いを簡略化したモデルで「実証主義パラダイム」、「ポスト実証主義パラダイム」、「社会的構成主義や相互行為論や解釈学のパラダイム」の3つに区別しており、この分類を氷山に例えています。(大谷 2019)
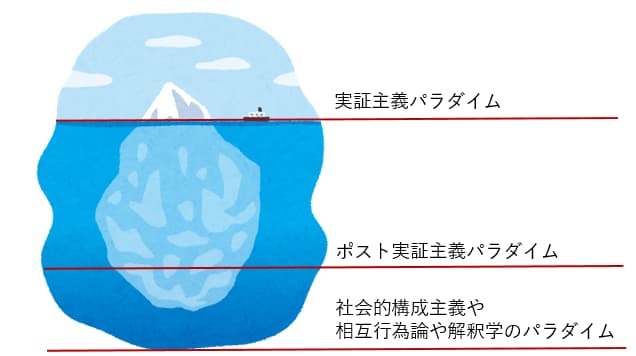
氷山の海面上に見える部分は「研究参加者が語った内容」、海面下の比較的浅い部分は「研究参加者が言いたかったが、うまくいえなかった内容」、海面下の深い部分は「研究参加者が思ってもいないが研究者が語りを分析して得られる内容」であるとし、「研究参加者が語った内容」だけを扱うのは「実証主義パラダイム」、「研究参加者が言いたかったが、うまくいえなかった内容」まで含めるのは「ポスト実証主義パラダイム」、「研究参加者が思ってもいないが研究者が語りを分析して得られる内容」まで含めるのは「社会的構成主義や相互行為論や解釈学のパラダイム」と説明します。
テキストマイニングはこの「研究参加者が語った内容」だけを扱う「実証主義パラダイム」に適しています。
テキストマイニングは、この氷山の海面に表れている「研究参加者が語った内容」を「数量化」と「可視化」することで、客観的な気付きを得やすくします。文脈を見る機能がある場合は、それを使うことで更に深く掘ることも可能です。
言葉と深く向き合い、自身の洞察や結論を導き出すことを支援するQDAソフト

QDAソフトは研究者がテキストを読み込み、コード化、カテゴリー化など洞察や結論を導き出すことを支援します。
「効率的な質的分析」と「可視化」が特長であり、質的データの分析の際に不可避であった事務的な作業を無くすことで、研究者がテキストを読み込み、思考することに集中できるようにします。質的データの可視化や比較も容易にします。
しかし、QDAソフトは質的分析そのものは行いません。
QDAソフトは質的分析そのものを遂行しない。つまり、それに任せておけば自動的に質的分析をしてくれるものではない。これと対照的にSPSSのようなソフトは統計的操作や因子分析を自動的に行ない得るものである。QDAソフトはむしろワープロに似ている。ワープロの使用のために執筆のあり方がいかに変化したかということが長らく論じられているが、ワープロがテクストを書くわけではない。ワープロはその作業を幾分か楽にしてくれるものである。これと同様に、QDAは質的研究を助けるものではあれ、それを自動化するものではない。(Flick, 2011)
QDAソフトは質的分析そのものは行いませんが、コーディングを容易にしたり、原文とコードの行き来をワンクリックにしたり、全てのデータを集約して管理したりと、手間のかかる質的分析の諸作業を無くし、データを整理して効率的な質的分析を可能にします。
QDAソフトはテキスト、語られた言葉と深く向き合い、語られた言葉を丹念に読み取っていく「ポスト実証主義的パラダイム」のアプローチや、語られていないことも含めて解釈する「解釈学的パラダイム」のアプローチで研究を進める場合に適しています。
また、テキストマイニングソフトと同様に頻出語や共起関係を特定する機能、視覚化や集計の機能を備えており、「実証主義パラダイム」のアプローチにも対応します。質と量の両面から探索することにより、より深い洞察を可能にします。
質的データ分析支援(QDA)ソフトとテキストマイニングソフトで共通している機能は
■頻出語の集計・視覚表現

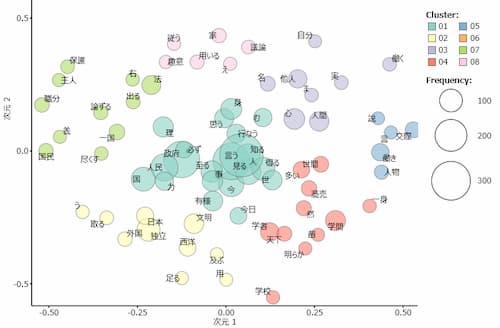
文章を語に切り分け、テキストデータを分析。それぞれの語の出現頻度を数え、視覚化することができます。これはテキストマイニングソフトでもQDAソフトでも同じようにできます。 各語の出現頻度や全体に占める割合などを数値で確認するとともに、視覚的な表現が可能です。
この視覚表現もソフトウェアによって異なりますが、NVivoでは単語クラウドを使用します。視覚化して俯瞰することで、新たな概念の発見や、見落としていた概念の発見などをサポートします。
■語の共起関係を見るための機能
それぞれの語の共起関係(ある文字列とある文字列が一緒に出現した際の関係性)を見るための視覚化機能もソフトによって異なります。
テキストマイニングソフトの多くは、語と語を線で結ぶ共起ネットワーク形式が多いですが、NVivoの場合はワードツリー(テキスト検索クエリ)という、キーワードの前後の文脈をひとつながりにする方法をとっています。
そのため、より文脈上の意味合いなどを考慮して、新たな発見や考察に役立てることができます。
■発言や文章、感情を自動で分類

発言や文章を自動的に分類できるソフトも数多くあります。例えば、自動的に感情を特定し、肯定的な発言・否定的な発言に分類する機能は多くのテキストマイニングソフトが備えていますし、NVivoでも可能です。また、テキストを読み取り、テーマなどを特定し自動でコーディングすることも可能です(NVivo Windowsのみ)。
質的研究、混合研究法(ミックスメソッド)に適しているのはQDAソフト? テキストマイニングソフト?

質的データを定量化したものが重要なのか、文脈が重要なのか、様々な考慮すべき点があります。研究内容、対象、手法などに合わせて、その都度、最も適当なものを選択する必要があるでしょう。
テキストマイニングはデータマイニングの一種であり、統計的処理による量的分析が基本となっています。質的データを対象に統計的処理を行ない、そこからなんらかの傾向や法則性を見出します。
語られた言葉、文字データのデータマイニングから確度が高いと思われる傾向や法則性を見つけ、比較、検定することで信頼性の高い結論を導くことが可能です。
テキストマイニングは質的研究の中でも、大量の質的データを解析する必要がある場合や、質的データを量的な内容分析をすることがメインの場合に適しているでしょう。
一方で、重要な概念が言葉そのものとして語られていなかったり、言葉の使用頻度が少なかったりした場合、その概念は他の言葉に埋もれてしまう可能性があります。現れていないものは見ることができません。
大谷尚氏は著書で、経験上、他の概念との間で強い関連を持ち、他のコードやできごとを説明できるような重要なコードはたった一度しか出てこないと述べています。(大谷 2019)
テキストマイニングはこのようなケースは不得意です。言葉の使用頻度が少ない場合、表示させる頻度の設定によってはそもそも分析の俎上に上がらないことも考えられます。また、使用頻度が高い言葉が本当に重要なのかどうかも検討が必要です。
一方、語られた言葉を丹念に読み取っていく質的分析は先述のような言葉として語られていない概念や使用頻度の少ない概念を発見するのに適していますが、分析の結論の確かさを第三者に納得させるには「濃密な記述」やプロセスの透明性が必要になります。この「濃密な記述」やプロセスの透明性はQDAソフトがサポートするところです。
ソフトウェアの使用によって、理論的コード化のような分析手法がより明示的で透明に実施されることになる。研究者が進んだテクストからカテゴリーへの道のりが、他者に検証可能になるのである。研究チームのメンバー間に共有できる形で、また論文の読者にも伝わる形で分析の途中経過を記録できるようになる。こうして形の分析の透明性を、多くの研究者は分析の妥当性の向上につながるものとみなしている。(Flick, 2011)
また、QDAソフトを使用した研究は使用していない研究よりも透明性が高いだけでなく、ケレとローリーはQDAソフトの使用と質的研究の妥当性の向上は関連性があると述べています。(Kelle and Laurie 1995)
質的分析の場合、QDAソフトを使用することで解析のプロセスが明らかになり、分析の透明性や妥当性が向上する可能性があります。
また、QDAソフトにおいても、上述のテキストマイニング的機能を使用することで質的分析の結果を量的な分析で補完、あるいは量的な分析の結果を質的分析で補完することも可能です。
質的分析がメイン、または混合研究法などで質的分析をおこなう場合はQDAソフトが適しているでしょう。
研究内容、対象、手法、データ量などに合わせて、最も適当なものを選択してください。
![]()
参考文献
- Flick, U., 小田博志, 山本則子, 春日常, & 宮地尚子. (2011). 質的研究入門 : 「人間の科学」のための方法論 (新版 ed.): 春秋社.
- Kelle, U., & Laurie, H. (1995). Computer use in qualitative research and issues of validity.
- 稲葉光行, & 抱井尚子. (2011). 質的データ分析におけるグラウンデッドなテキストマイニング・アプローチの提案. 政策科学, 18(3), 255-276.
- いとうたけひこ. (2011). 批判心理学の方法としてのテキストマイニング : 変数心理学に対するオルタナティブ(<特集>批判心理学の可能性). 心理科学, 32(2), 31-41
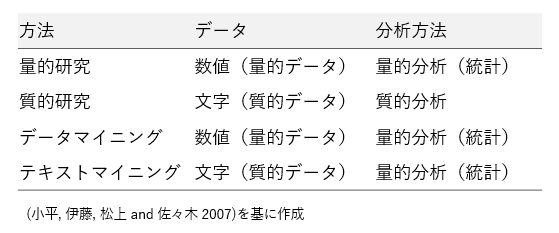
- 小平朋江, 伊藤武彦, 松上伸丈, & 佐々木彩. (2007). テキストマイニングによるビデオ教材の分析:精神障害者への偏見低減教育のアカウンタビリティ向上をめざして マクロ・カウンセリング研究, 6, 16-31. マクロ・カウンセリング研究, 6, 16-31.
- 大谷尚. (2019). 質的研究の考え方 : 研究方法論からSCATによる分析まで: 名古屋大学出版会

