XLSTAT による反復測定分散分析:時間の経過に伴う新薬の治療効果を評価する
- 反復測定分散分析とは?
- 反復測定分散分析を使うための条件
- 反復測定分散分析に必要なデータ形式(縦型と横型)
- 反復測定分散分析を実行するためのデータセット
- XLSTAT で反復測定分散分析を実行する手順
- 反復測定分散分析の結果の解釈
- 平行座標プロットで平均の推移を可視化する
- 補足:母数効果(固定効果)とは?
- まとめ
- 参考文献
- XLSTAT の無料トライアル
反復測定分散分析とは?
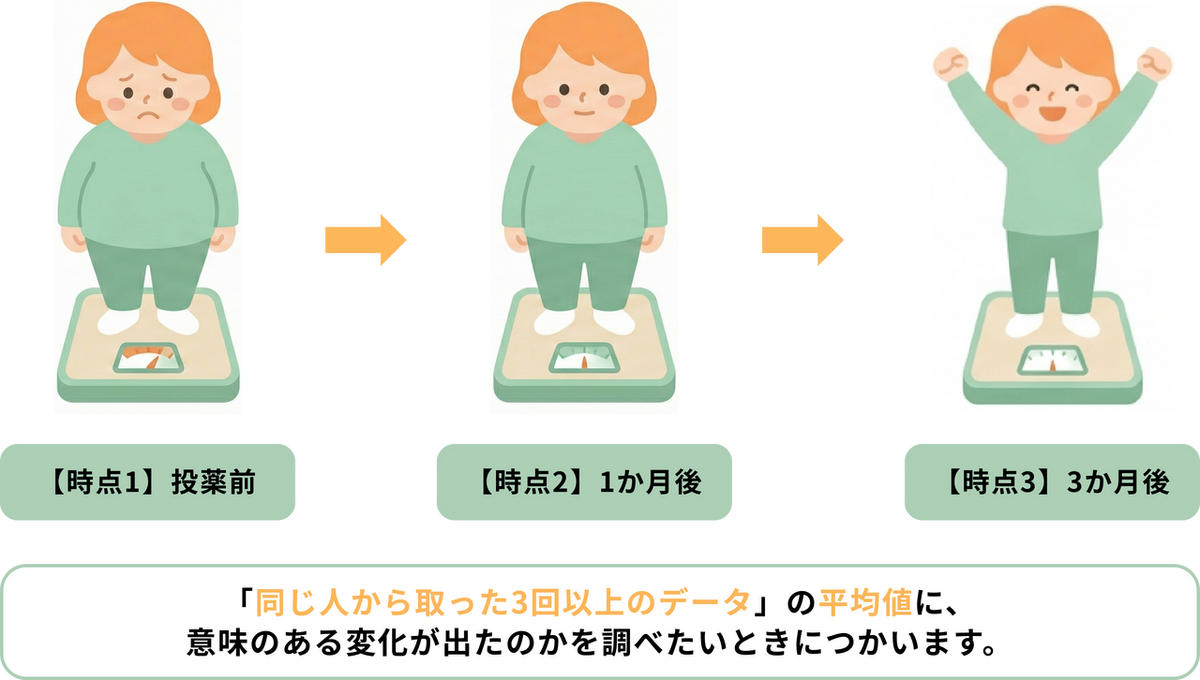
反復測定分散分析とは同じ人や物から3回以上繰り返し測定したデータに、変化(平均値の差)があったかどうかを調べる分析手法です。例えば、新しいダイエット薬の効果を調べるために、同じ患者10人の体重を「投薬前」「1か月後」「3か月後」の3回(3つの時点)測ったとします。この同じ人から取った3回以上のデータの平均値に、意味のある違いが出たかを比較したい時に使います。
反復測定分散分析を使うための条件
反復測定分散分析を行うには、対象のデータが以下の条件を満たしている必要があります。
- 対応があること:
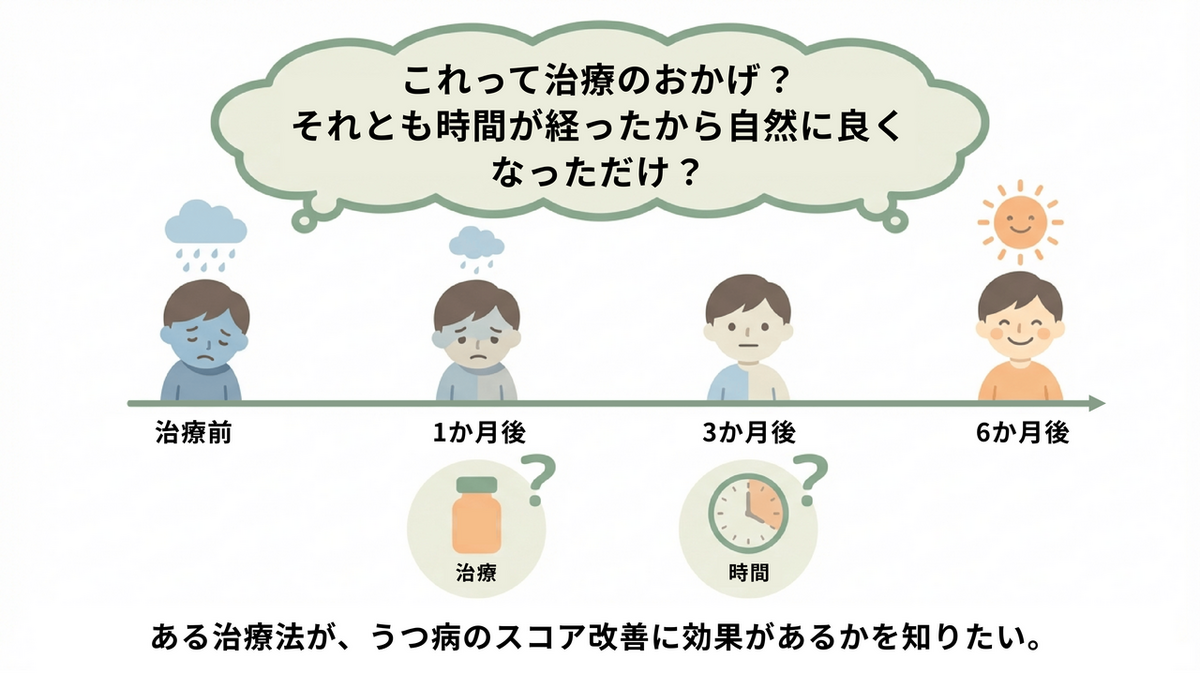
「対応がある」とは前述の通り、「同じ人(または物)から繰り返し測ったデータ」であることを指します(全く別の人を集めて比較する場合は「対応がない」データとなります)。「わざわざ同じ人を何度も測らなくても、毎回別の人を集めて測ればいいのでは?」と思うかもしれませんが、同じ人を反復して測定することには個人差というノイズを取り除けるメリットがあります。人間の体重には、元から大きな個人差があります(最初から50kgの人もいれば、100kgの人もいます)。もし毎回違う人を集めてしまうと、「体重が減ったのは、薬の効果なのか、それとも元々体重が軽い人を集めてしまっただけなのか」が区別しにくくなります。しかし、同じ人を追いかければ「Aさんはマイナス2kg」「Bさんはマイナス3kg」という純粋な変化量だけにフォーカスできるため、少ないデータ数でもより正確に効果(差)を検出しやすくなります。 - 3つ以上のグループ(時点)であること:
反復測定分散分析の最大の強みは、3回以上のタイミングや条件を一度に比較できる点にあります。もし「投薬前」と「投薬後」の2回だけの比較であれば、別のよりシンプルな手法を使います(詳しくは「対応のあるt検定」の解説ページをご覧ください)。 「3回の比較なら、t検定を3回繰り返せばよいのでは?」と思うかもしれません。しかし、1つのデータに対して検定を何度も繰り返すと、本当は差がないのに、偶然差があると間違えて判定するリスク(αエラー、第一種の過誤)が増加してしまうという統計上の重大な問題が発生します。この問題を回避し、「全体としてどこかに有意な差があるか」を一度に正しく評価するため、この分散分析が必要になります。 - データが数値(連続変数)であること:
分析対象となるデータが、「体重」「血圧」「テストの点数」のように、連続した数値(連続変数)で表されている必要があります。これらのデータは、足し算や割り算ができ、平均値や分散(ばらつき)を計算することに意味があるため、分散分析に適しています。反対に、「治った / 治っていない」の2択データや、「血液型(A・B・O・AB)」のような単なる分類データ(名義変数)、あるいは「1位、2位、3位」といった順位のみを表すデータ(順序変数)には、原則としてこの分析は使えません。
※ただし、アンケートの「5段階評価」のようなデータは、実務上は連続変数とみなしてこの分析にかけることもあります。 - 正規分布に従う(パラメトリック):
正規分布とは、平均値のあたりにデータが一番多く集まり、両端にいくほど数が減っていく左右対称のきれいな釣り鐘型の分布のことです。反復測定分散分析は、データの平均値やばらつきをベースに計算を行う手法(パラメトリック検定)です。そのため、一部の人だけが極端に高いスコアを出しているような偏ったデータを使ってしまうと、平均値が大きく引っ張られてしまい、正しい結論が導けなくなってしまう可能性があります。もし正規分布から大きく外れている場合は、平均値の代わりに「順位」を使って比較する「フリードマン検定」という別の手法に切り替えることを検討します。 - 球面性の仮定を満たす:
球面性とは「どの測定タイミング(条件)の間の『差のばらつき(分散)』も、だいたい同じである」というルールです。例えば、患者の血圧を「投薬前(A)」「1か月後(B)」「3か月後(C)」の3回測ったとし、A-B 間、B-C 間、A-C 間それぞれの差を考えます。球面性の仮定が満たされている状態とは、これら3つのパターンの「差のばらつき」がすべて等しい状態を指します。 この前提が崩れたまま分析を行うと、p値が実際よりも甘く計算されてしまい、誤って「有意差あり」と判定してしまうリスク(αエラー)が高まります。そのためXLSTAT では、分析時に自動で「Mauchly(モークリー)の球面性検定」を行い、この仮定をチェックします。もし球面性が満たされていないと判定された場合でも、「Greenhouse-Geisser(グリーンハウス・ガイザー)」等の補正方法を用いて、甘く出すぎたp値を適切な厳しい値に自動修正してくれる仕組みになっています。
※これらの検定や補正の方法は少し専門的で難しいため、具体的な表の見方や判断基準については、後述の「出力結果の解釈」セクションであらためて解説します。ここでは「XLSTAT 側に自動でばらつきのズレをチェック・補正してくれる仕組みがある」とだけご理解ください。
反復測定分散分析に必要なデータ形式(縦型と横型)
反復測定分散分析では、主に2つのデータ形式があります。XLSTAT ではどちらのデータ形式にも対応していますが、実行時のデータ選択方法が若干異なります。
横型(繰り返しごとに1列 / Wide Format):
1行が「1人の被験者」の情報を表し、測定タイミング(1か月後、3か月後...)ごとに列が横に増えていく形式です。直感的に分かりやすく、XLSTAT ではこちらの形式を使うと自動で要因を判別してくれるためおすすめです。
例)3人の患者(A、B、C)に、ある薬を投与し、血圧を3日間(1日目、2日目、3日目)測定した場合のデータ形式

縦型(すべての繰り返しで1列 / Long Format):
測定したデータ(従属変数)がすべて1つの列に縦に長く入力されている形式です 。この場合、「どの列が時間の情報か」「どの列が個人のIDか」を分析実行時に別途指定する必要があります。
例)上記と全く同じ患者の血圧データを、縦型で入力した場合の事例

反復測定分散分析を実行するためのデータセット
今回は、うつ病治療の研究データ(横型フォーマット)を使用します。このデータでは患者(24名)に対し、4つの時点(dv0:治療前、dv1:1か月後、dv3:3か月後、dv6:6か月後)でうつ病スコアを測定しています。また、患者は「1:対照群」と「2:新薬群」の2つのグループに分かれています。

このデータに対して反復測定分散分析を実行し、時間の経過がうつ病スコアに与える影響と、治療グループによってスコアの変化のパターンに違いがあるかを確認します。
サンプルデータのダウンロードはこちらから
dataset-for-repeated-measures-ANOVA.xlsmXLSTAT で反復測定分散分析を実行する手順
-
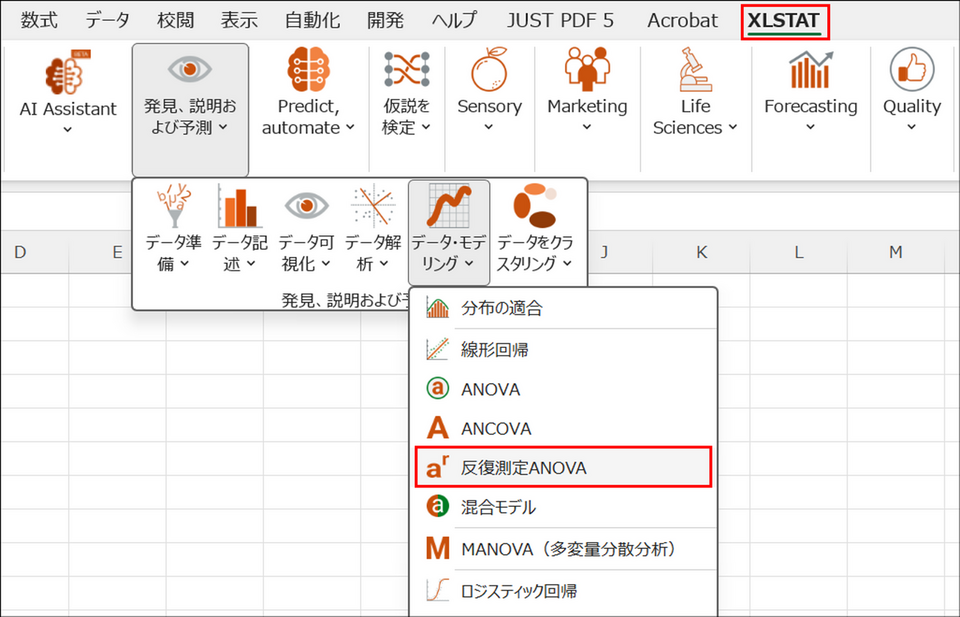
XLSTAT を起動し、[発見、説明、および予測] > [データ・モデリング] > [反復測定ANOVA] を選択します。
-
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
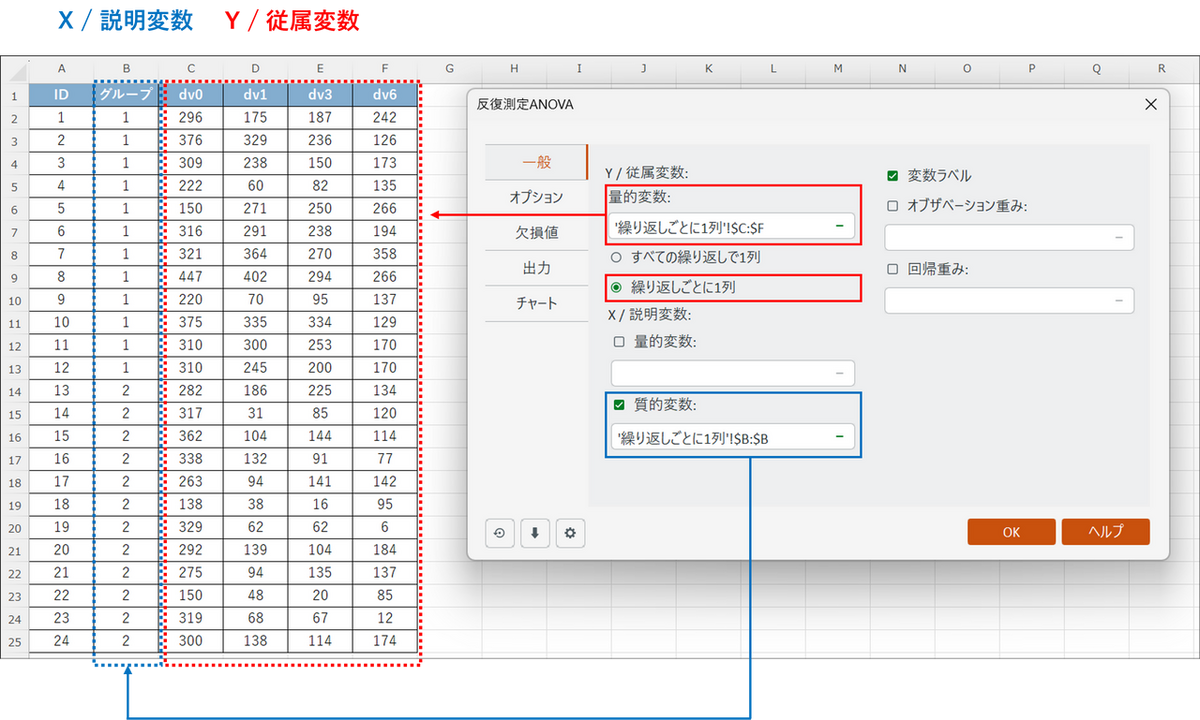
- 横型フォーマットのため、データ形式は [繰り返しごとに一列] を選択します。
- Y / 従属変数:
各測定タイミングのスコアが入った列(dv0〜dv6)をすべて選択します。 - X / 説明変数:
[質的変数] にチェックを入れ、患者のグループ分けを示す列(グループ)を選択します。
【補足】縦型フォーマットのデータで実行する場合
測定したデータ(従属変数)がすべて1つの列に縦に長く入力されている形式の場合は、データ形式は [すべての繰り返しで一列] を選択し、従属変数と説明変数は以下のように入力します。
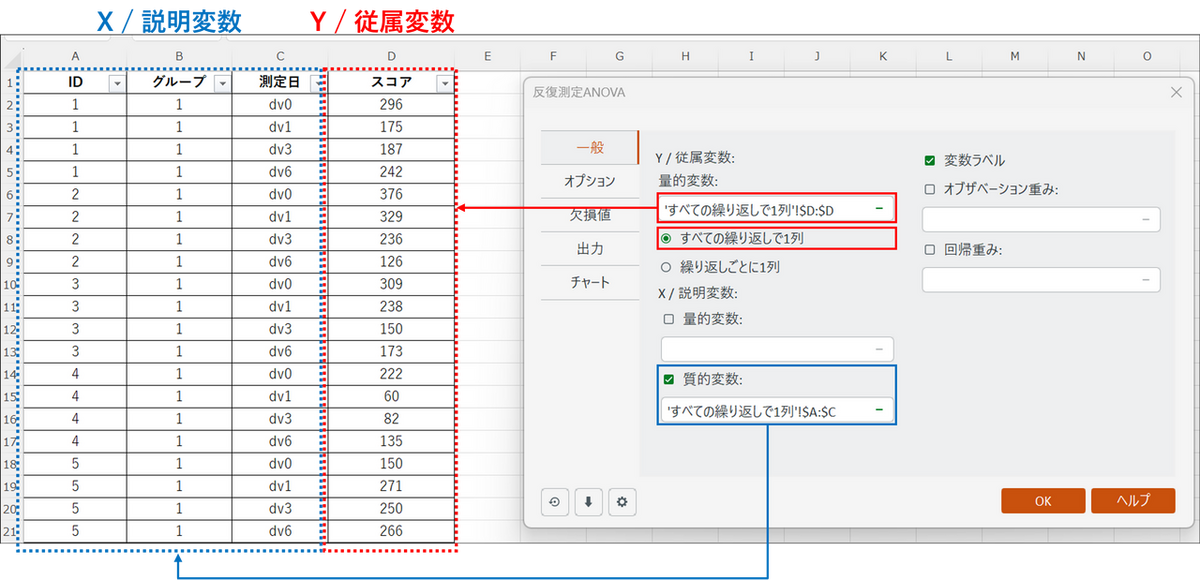
- Y / 従属変数:
うつ病スコアの値が入った列を選択します。 - X / 説明変数:
[質的変数] にチェックを入れ、「ID」「グループ」「測定日」の列を選択します。
- 横型フォーマットのため、データ形式は [繰り返しごとに一列] を選択します。
-
[出力] タブに切り替え、以下の画面のように設定します。
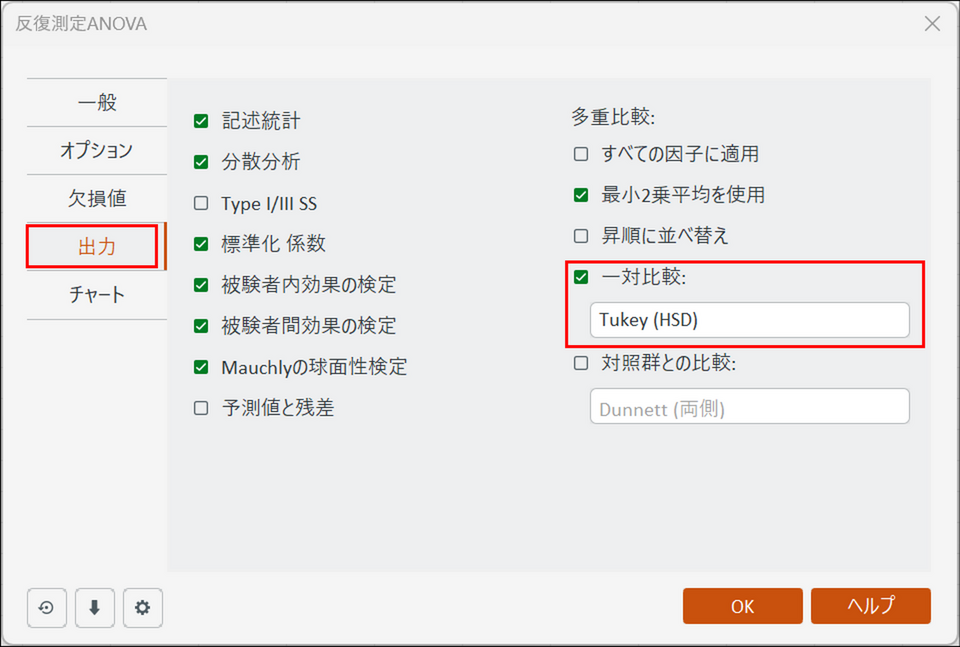
多重比較の設定:
[一対比較] にチェックを入れることで、分散分析で「有意差あり」となった後、「具体的にどのグループ間に差があるのか」を検証することができます。今回は最も一般的に使われる「Tukey (HSD)」を選択しておきます。 -
[OK] ボタンをクリックします。
-
因子と交互作用のダイアログボックスが表示されます。画面内にある3つのボックスに因子を以下のように割り当てます。
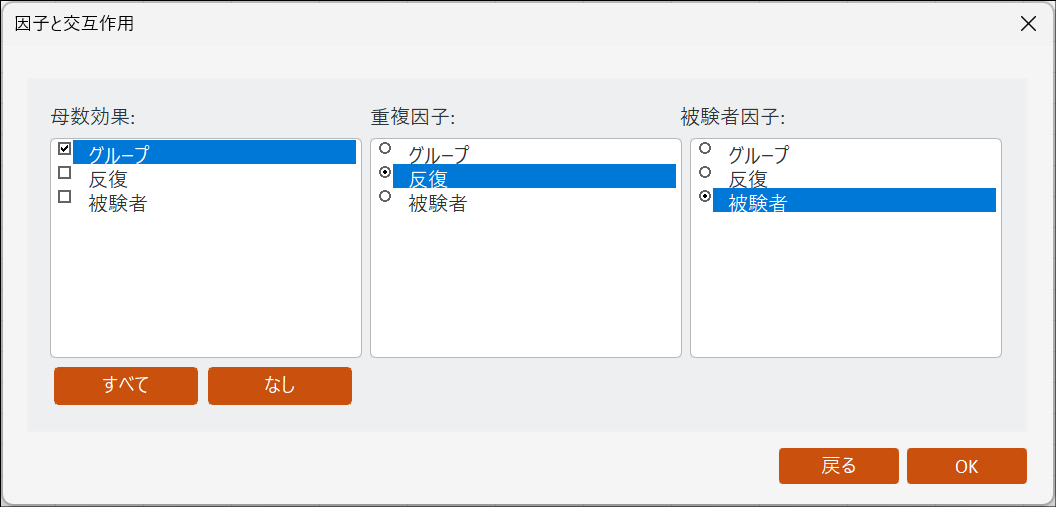
- 母数効果:
「グループ間の違い(新薬群か対照群か)」を検証するための要因を入れる場所です。今回は「グループ」のみにチェックを入れます。母数効果については「補足:母数効果(固定効果)とは?」の項目をご参照ください。 - 重複因子 :
「時間の経過(反復)」を表す要因を入れる場所です。自動生成された「反復」 を選択します。 - 被験者因子:
「誰のデータか(個人ID)」を表す要因を入れる場所です。自動生成された「被験者」を選択します。
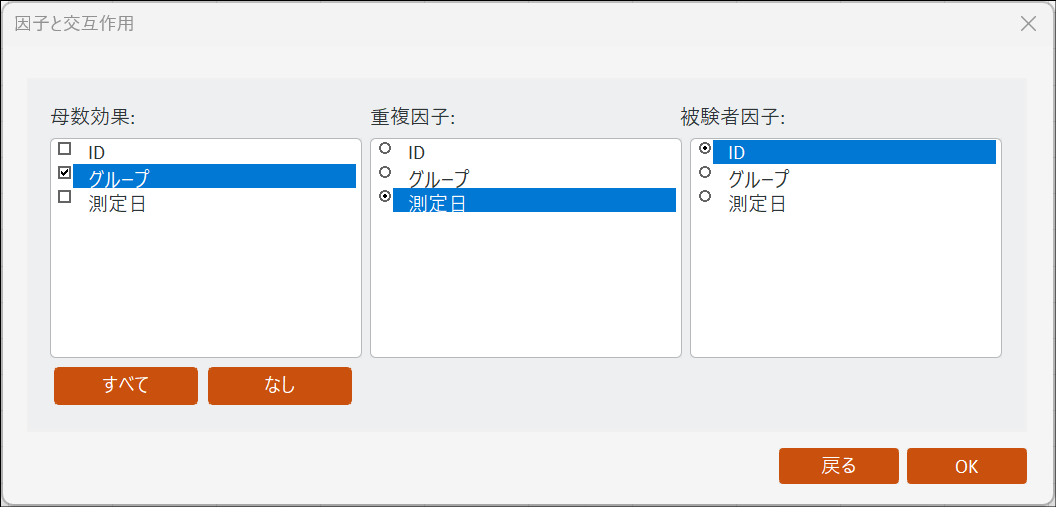
【補足】縦型フォーマットのデータで実行する場合
縦型フォーマットのデータで実行する場合は、「母数効果」にグループ、「重複因子」に測定日、「被験者因子」にID の列を選択する必要があります。
- 母数効果:
-
[OK] をクリックします。
-
多重比較のオプションを有効にした場合、各変数ごとに多重比較検定の結果を表示するかどうか確認されますので、画面内の項目にチェックを入れて、[OK] をクリックします(各測定時点ごとにダイアログが表示されるため、複数回選択します)。
反復測定分散分析の結果の解釈
計算が完了すると新しいシートに結果が出力されます。出力される表を上から順番に確認していきましょう。
記述統計
ここでは参考として、グループ(対照群・新薬群)の違いを考慮せず、各時点ごとの単純な変化を確認できます。
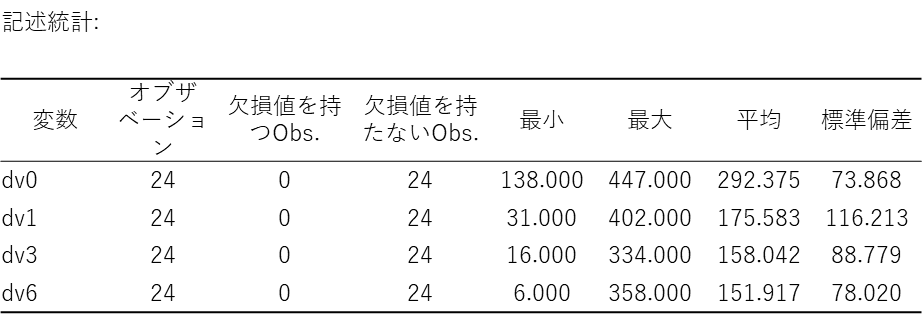
「平均」の列を見ると、dv0(治療前)の292.375 から始まり、dv1(1か月後)で175.583、最終的なdv6(6か月後)では151.917 へと数値が下がっていることが分かります。つまり、全体として、時間が経つにつれてうつ病スコアの平均が下がって(改善して)いるという大まかな傾向を捉えることができます。
各変数(dv0~dv6)の分散分析結果
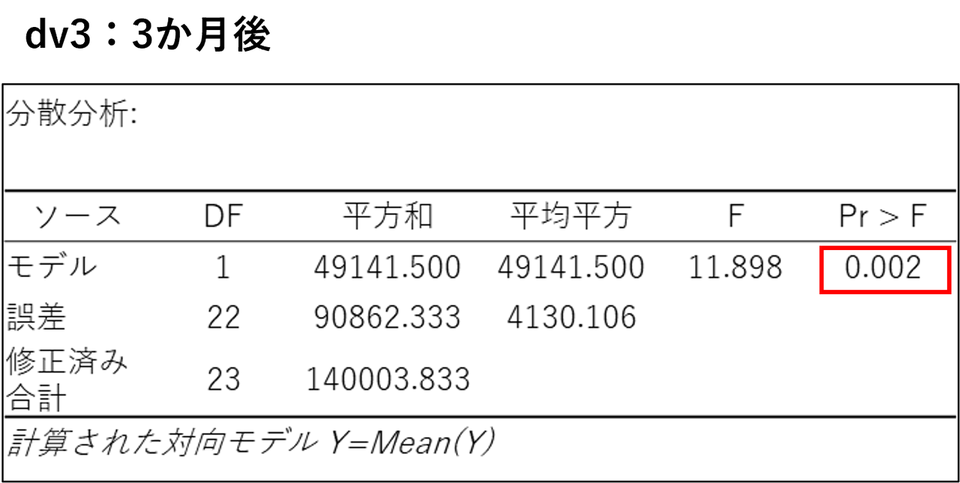
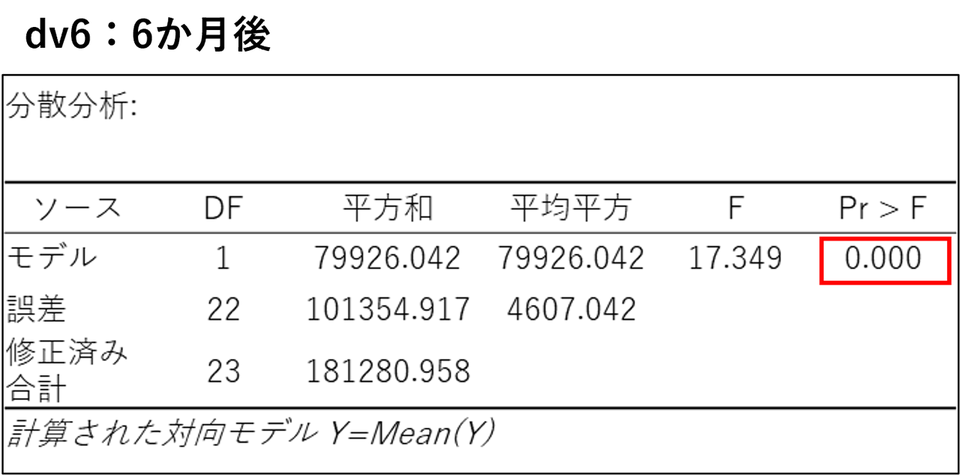
時間の経過(反復)はいったん置いておき、それぞれの測定タイミング単体で対照群と新薬群の間に差があったかを確認します。各表の「モデル」行にある「Pr > F(p値)」の項目に注目します。
dv0(治療前)の分散分析表:
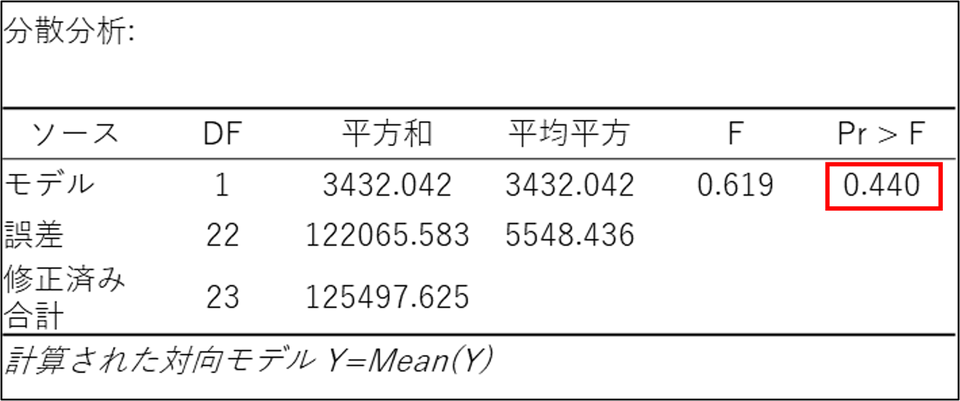
dv0(治療前)の分散分析表ではp値が「0.440」となっており、0.05(有意水準)より大きくなっています。これは、「実験を始める前の段階では、2つのグループのうつ病スコアに統計的な差はなかった(=公平なスタートラインに立っていた)」という前提を証明しています。
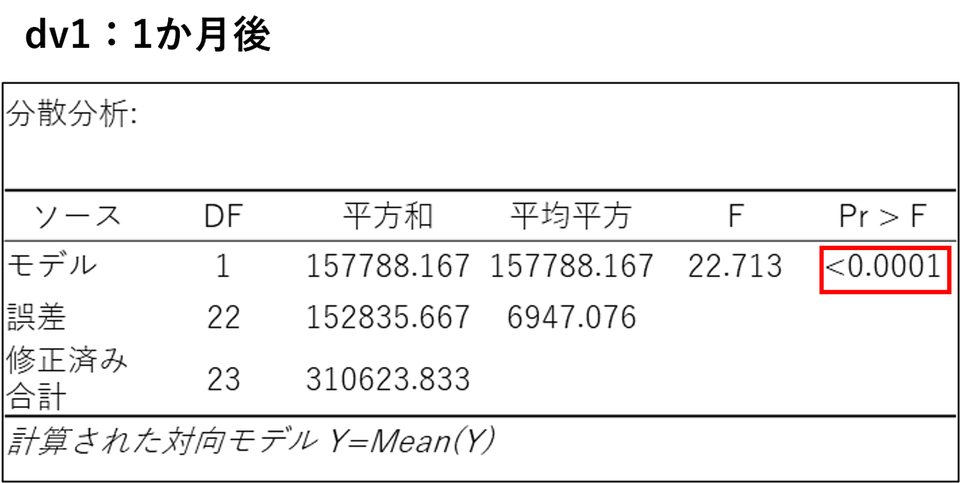
dv1(1か月後)~ dv6(6か月後)の分散分析表:
すべての表でp値が0.05 を下回っています。これは、治療開始から1か月経った時点ですでにグループ間に明確な差(新薬の効果)が現れ、その差が3か月後、6か月後も継続していることを示しています。
グループ要約対比較(Tukey (HSD))
「グループ要約対比較」は、前のステップで「全体として差があった」と分かった後、「では具体的にどちらのグループがどう違ったのか?」を視覚的に教えてくれる便利な表です。これは多重比較(post-hoc検定)の結果であり、ここではTukey(HSD)法を用いてグループ間の差を検定しています。
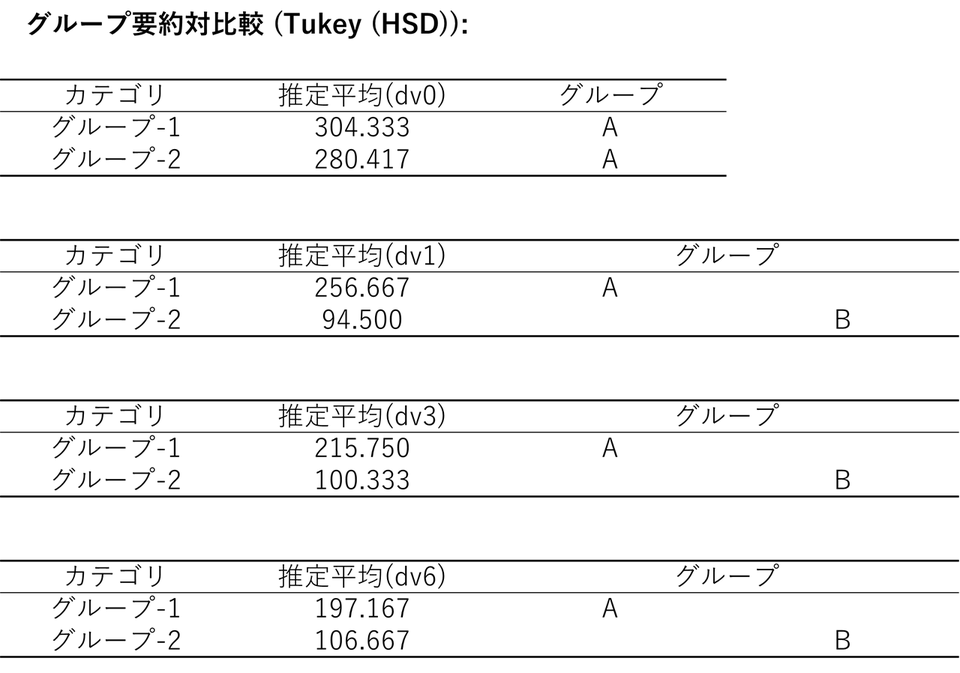
一番右にある「グループ」列のアルファベット(A、B )に注目します。同じアルファベットの組み合わせ(AとAなど)であれば、統計的に有意な差はありません。それに対して違うアルファベットの組み合わせ(AとBなど)であれば、 統計的に有意な差があると解釈します。
- dv0(治療前):
グループ1もグループ2 も同じ「A」がついています。つまり、実験前の段階では両グループに差はなかったことがわかります。 - dv1(1か月後)~ dv6(6か月後):
グループ1(対照群)が「A」、グループ2(新薬群)が「B」と明確にアルファベットが分かれました。隣の「推定平均」の数値を見ると、グループ2の方がスコアが低くなっています。
これにより、スタートラインは同じだったが、治療開始から1か月後以降は、新薬グループ(グループ2)の方が明確にうつ病スコアが改善していると解釈できます。
Mauchly の球面性検定
反復測定分散分析を正しく行うための前提である、「測定タイミング間の差のばらつきが等しいか(球面性)」をテストした結果です。Pr > Chi2(p値)に注目します。ただし、この検定は検出力が低いため、サンプルサイズが小さい場合には結果を過信すべきではない点に注意が必要です。

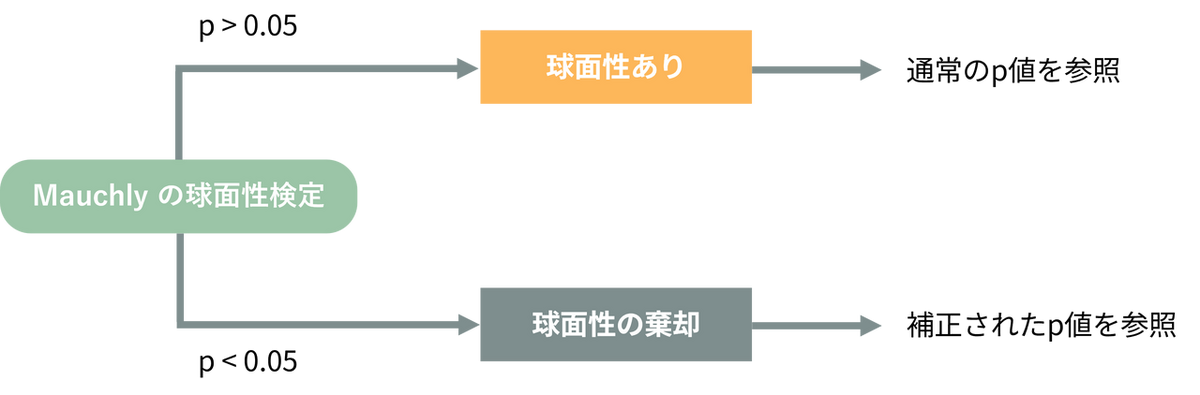
以下のようにp値が0.05 より大きいか小さいかで、この後に見るべき項目が変わります。
- p > 0.05 の場合(球面性あり):
前提条件を満たしているため、そのまま通常の解析を実行し、後の検定では通常のp値を参照します。 - p < 0.05 の場合(球面性の棄却):
「球面性の仮定は満たされていない」と判断され、球面性が棄却されます。この場合、この後の「被験者内効果の検定」で見るべきp値の項目が変わり、自動補正されたp値を参照する必要があります。
今回のp値は「0.000」となっており、基準となる0.05 を下回っています。これは「球面性の仮定は満たされていない」ことを意味します。表の右側にある「Greenhouse-Geisser(グリーンハウス・カイザー) イプシロン(0.730)」と「Huynt-Feldt(ホイン・フェルト)イプシロン(0.851)」は前提が崩れて甘くなってしまったp値を、どれくらい厳しく補正すれば良いかを示す値です(1に近いほど共分散行列が球形に近いことを意味します)。この結果を受けて、「被験者内効果の検定」では通常のp値ではなく、これらのイプシロン値で補正されたp値を確認します。
被験者間効果の検定
時間の経過(dv0〜dv6 の違い)とは関係なく、純粋にグループ間(対照群と新薬群)で全体的なうつ病スコアに差があったかを示す表です。グループの行にあるPr > F(p値)に注目します。
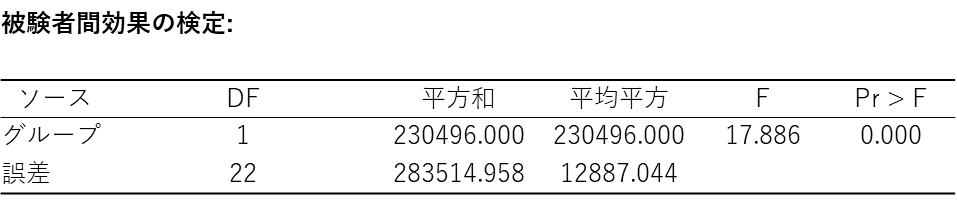
今回の結果では、グループ のp値が「0.000」となっており、0.05 を大きく下回っています。これは、4回の測定タイミングすべてを含めた全体的な平均スコアにおいて、対照群と新薬群の間には、統計的に明確な違い(有意差)があるということを意味しています。
被験者内効果の検定
反復測定分散分析において、最も重要な検定結果です。「反復(時間の経過)」と「グループ*反復(グループによる変化パターンの違い=交互作用)」の効果を確認します。ここで、球面性検定の結果が非常に重要になります。今回は球面性の検定で球面性が棄却されている(p < 0.05)ことが判明しているため、通常の Pr > F の列ではなく、表の右側にある補正されたp値「Adj. Pr>F G-G(Greenhouse-Geisser 補正)」 または「Adj. Pr>F H-F(Huynt-Feldt 補正)」の数値を確認します。
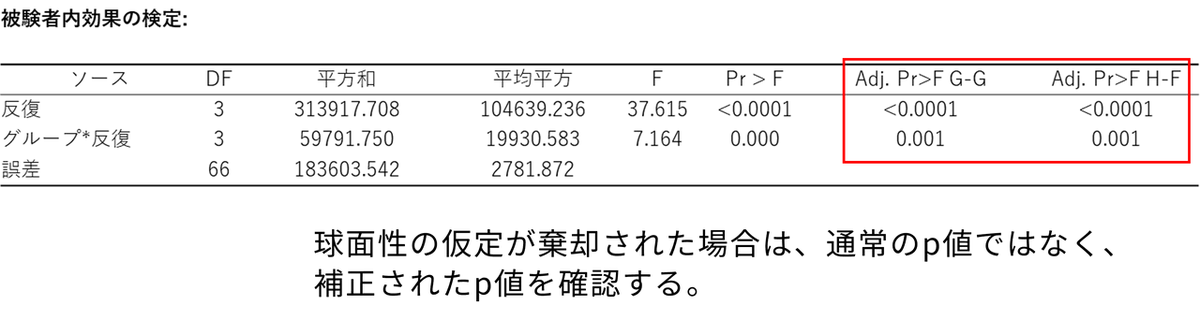
「反復(時間の効果)」については、「Adj. Pr>F G-G」の値が 「<0.0001」 となっており、有意水準である0.05 を下回っています。これはグループに関係なく、時間が経つにつれてうつ病スコア全体が統計的に有意に変化したことを示しています。
「グループ*反復(交互作用)」においても、「Adj. Pr>F G-G」の値が 「0.001」 となっており、こちらも0.05 未満です。これは、対照群と新薬群で、時間の経過に伴うスコアの変化のパターン(グラフの折れ線の形)が明確に異なるということを統計的に裏付けています。
これまでのすべての検定結果を総合すると、本事例のデータからは以下の結論が導き出されます。
- 時間の主効果:
全体として見ると、時間が経つにつれてうつ病スコアは有意に減少(改善)しています。
- 交互作用(グループによる変化パターンの違い):
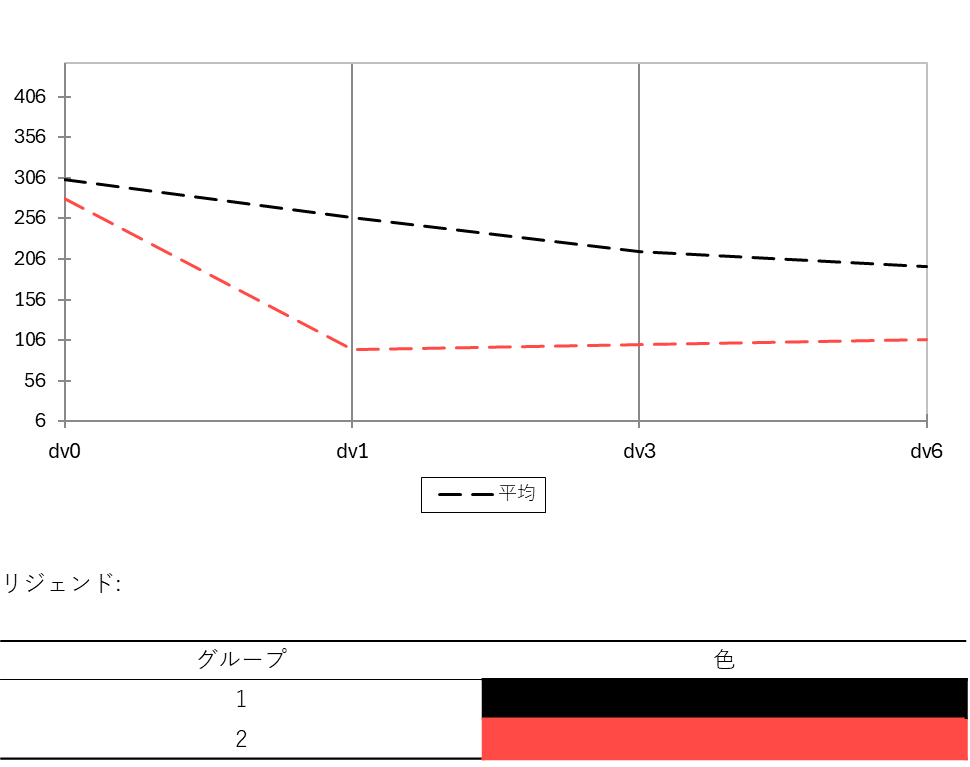
実験前はどちらのグループも同じうつ病レベル(差がない状態)でしたが、新薬を投与したグループは、対照群と比べて1か月後から明らかに早く、スコアが改善する推移をたどっています。
平行座標プロットで平均の推移を可視化する
数値の表やアルファベットだけでなく、結果をグラフにすることで「時間の経過とともに2つのグループがどう変化したのか」が一目瞭然になります。XLSTAT の「平行座標プロット」ツールを使うと、グループごとのスコア平均の推移を簡単に可視化できます。
-
XLSTAT のメニューから[発見、説明および予測] > [データ可視化] > [平行座標プロット] を選択して起動します。
-
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
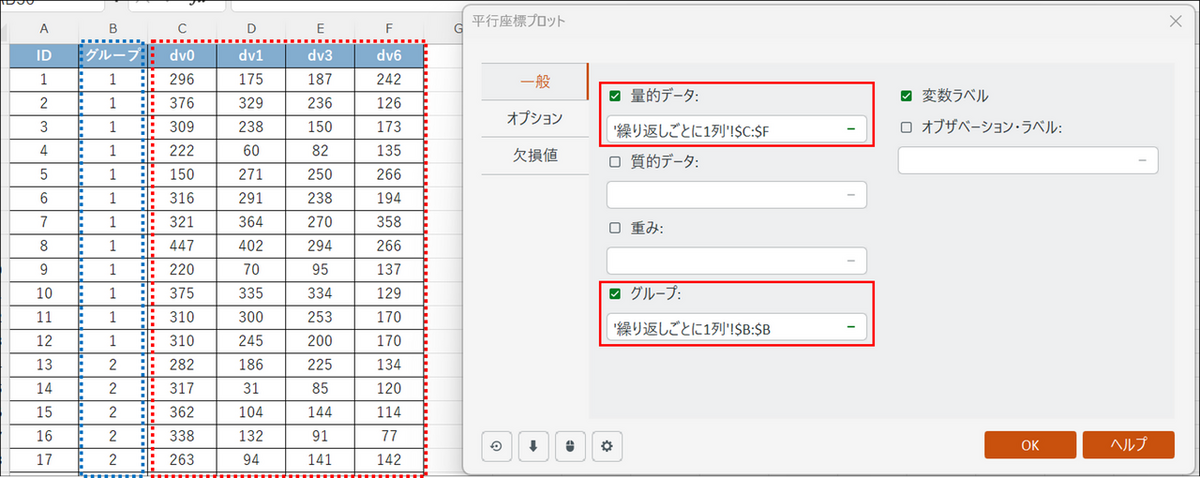
- 量的データ:時間経過のスコアが入った列(dv0〜dv6)を選択します。
- 変数ラベル:列の見出しを含めて選択した場合は、チェックを入れます。
- グループ:患者のグループ分けを示す列(グループ)を選択します。
- 量的データ:時間経過のスコアが入った列(dv0〜dv6)を選択します。
-
[オプション] タブに切り替え、[平均] にチェックを入れます。
-
「OK」をクリックすると、別シートにグループごと(対照群と新薬群など)に色分けされた折れ線の軌跡が描画されます。多重比較検定の表と照らし合わせながら見ることで、どこで差が開き始めたのかを直感的に理解することができます。
補足:母数効果(固定効果)とは?
母数効果とは、分散分析などの統計モデルにおいて、研究者が意図的に設定・制御した特定の条件(水準)が結果に与える効果のことを指します。一般的には「固定効果」とも呼ばれます。もう少し簡単に言えば、「すべての人(対象)に共通して現れる、ベースとなる効果」のことです。これと対になる概念として、個体によって生じるランダムなばらつきを表す「変量効果(ランダム効果)」があります。
ワクチンの副反応(発熱)を例に、両者の違いを見てみましょう。
- 固定効果(母数効果):
ワクチンを打った人全員に共通して現れる効果です。例えば「ワクチンを打つと、平均して熱が2度上がる」という場合、このすべての人に共通する「+2度」という固定された数値が固定効果にあたります。 - 変量効果(ランダム効果):
とはいえ、全く熱が出ない人もいれば、40度の高熱が出る人もいます。このような、人それぞれの体質によるランダムなばらつきのことを変量効果(ランダム効果)と呼びます。
今回のうつ病の治療データにおいても、「治療グループ」と「対照グループ」という条件の違いによって、グループ全体に共通して現れるベースラインの変化(=治療の本当の効き目)を見つけ出すことが目的です。そのため、要因である 「グループ」は「固定効果(母数効果)」として扱われます。
まとめ
反復測定分散分析は、「時間の効果」と「グループによる変化の違い(交互作用)」を同時に評価できる手法です。XLSTAT を使用すれば、前提条件である球面性の検定から、変化の場所を特定する多重比較(事後検定)、さらには結果のグラフ化まで、必要なステップをすべてスムーズに実行できます。正しいデータ形式と(グループ・時間・被験者)の設定さえ押さえておくことで、説得力のある分析結果を導き出すことが可能です。
参考文献
-
固定効果と変量効果の直感的理解. https://tomsekiguchi.hatenablog.com/entry/2022/04/16/125708
-
平井 明代: 教育・心理系研究のためのデータ分析入門~理論と実践から学ぶSPSS活用法~ 第2版, 東京図書, 2017.
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介した反復測定分散分析はStandard と Advanced のライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。
