XLSTAT によるランダムフォレスト:アクセスログやユーザー属性からサービスの登録有無を予測しよう
- ランダムフォレストとは?
- ランダムフォレストの仕組み
- アンサンブル学習とは?
- ランダムフォレストのメリットと注意点
- ランダムフォレストを実行するためのデータセット
- XLSTAT でランダムフォレストを実行する手順
- ランダムフォレストの結果の解釈
- 作成したモデルを用いて予測する
- 結果からROC 曲線を作成する
- まとめ
- 参考文献
- XLSTAT の無料トライアル
ランダムフォレストとは?
ランダムフォレストは、機械学習においてデータから予測を立てるために使われる分析手法の一つです。データを使って「分類」や「回帰」を行う際、たくさんの決定木(条件分岐によって予測するモデル)を作り、それらの結果を総合して最終的な答えを出します。
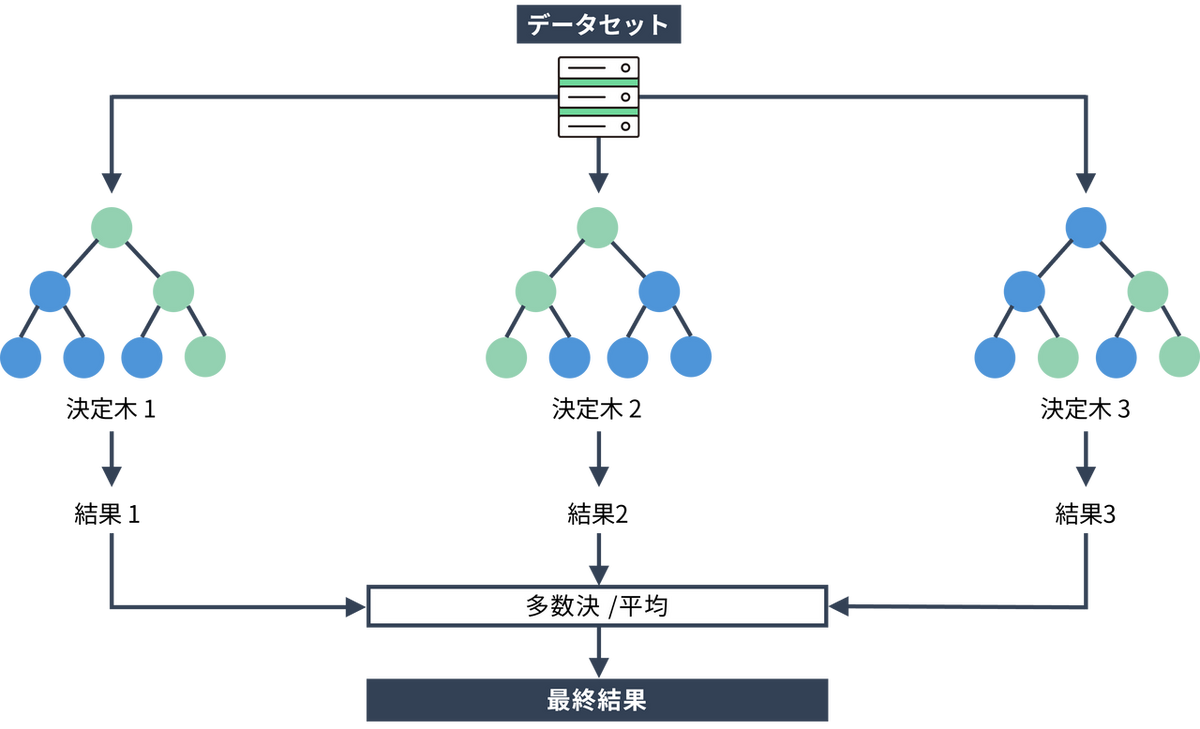
イメージとしては、少しずつ違う特徴を持ったたくさんの木(決定木)を集めて森を作り、多数決(または平均)で正しい答えを導き出す仕組みです。1人の専門家(1本の木)の意見だけを聞くと、その人の思い込みや手元のデータに偏りすぎて、未知のデータに対して間違った判断をしてしまう(過学習)リスクがあります。ランダムフォレストは、たくさんの木の意見をまとめることでこの弱点をカバーし、よりブレの少ない安定した予測を可能にしています。
ランダムフォレストの仕組み
ランダムフォレストが具体的にどのような仕組みなのか、3つのステップと例え話で解説します。
1. ベースとなるのは「決定木」
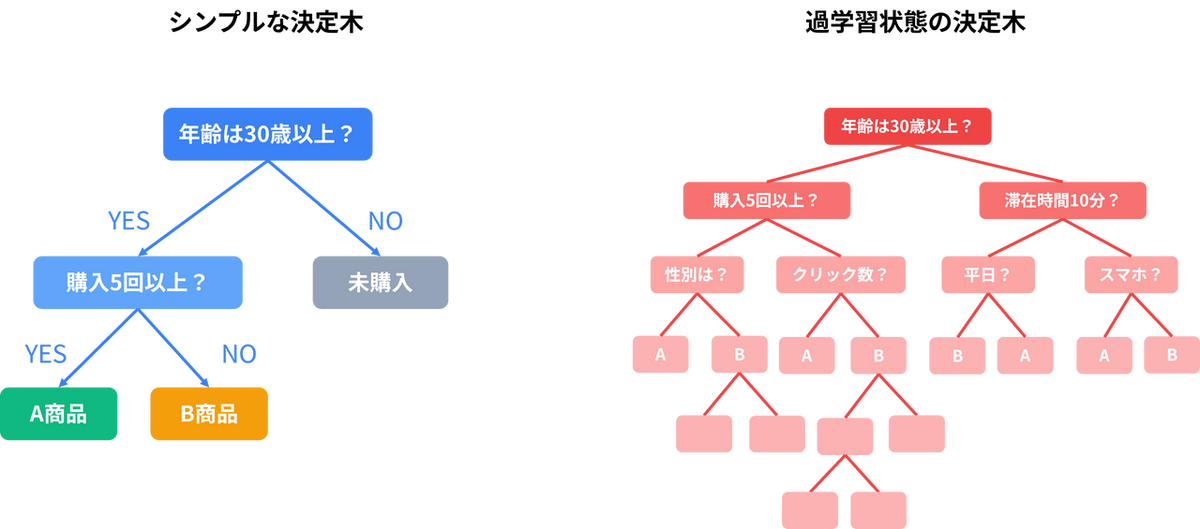
まず、ランダムフォレストを構成する1本1本の木は「決定木」と呼ばれる機械学習のモデルです。これは「年齢は30歳以上か?」「過去の購入履歴は5回以上か?」といったYES/NO の条件分岐(質問)を繰り返してデータを分類し、「その顧客が新商品を購入するかどうか」といった結果を予測するシンプルな仕組みです。 しかし、決定木を1本だけ深く成長させると、学習データに含まれる細かな条件(例:「滞在時間10分以上か?」など)まで使って複雑に分岐してしまいます。こうした分岐は、そのデータに特有の偶然のパターンを反映していることも多く、新しいデータには当てはまりません。その結果、未知のデータに対して予測を間違えやすくなるという弱点があります。
決定木については下記ページもあわせてご参照ください。
XLSTAT による決定木分析:分類木で個体情報をもとにアヤメの花を分類しよう
2. 2つの「ランダム」で多様な木を作る
そこで、たくさんの決定木を集めて「森」を作るのですが、全く同じ木をいくつ集めても多数決の意味がありません。そのため、意図的に木に「個性(多様性)」を持たせるために、以下の2つのランダムな要素を取り入れます。
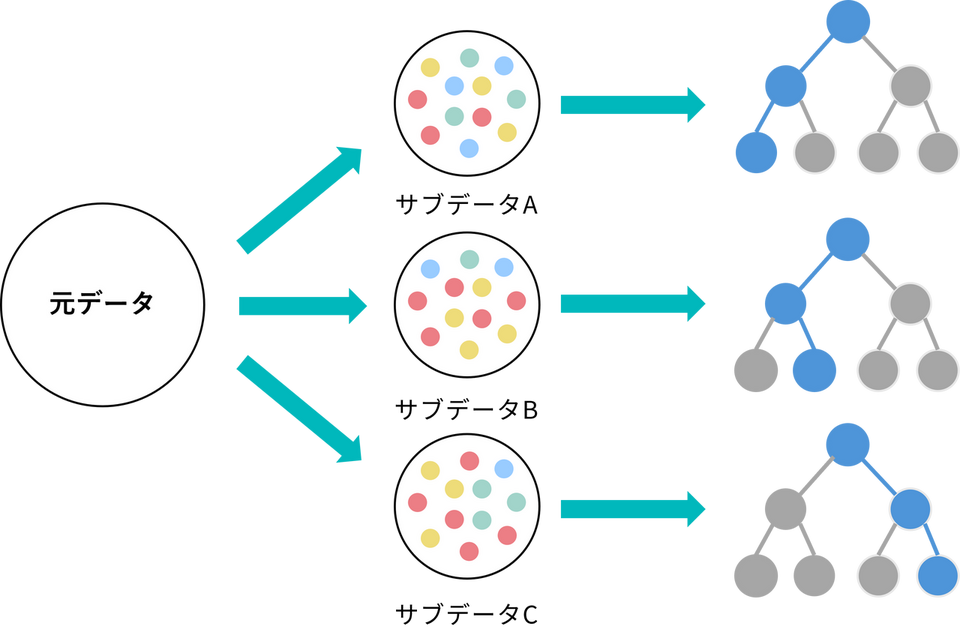
データのランダム(ブートストラップサンプリング):
元のデータから、あえて重複を許してランダムにデータを抽出して、少しずつ中身の違うデータセットをたくさん作ります。そして、そのデータセットごとに別々の決定木を学習させます。
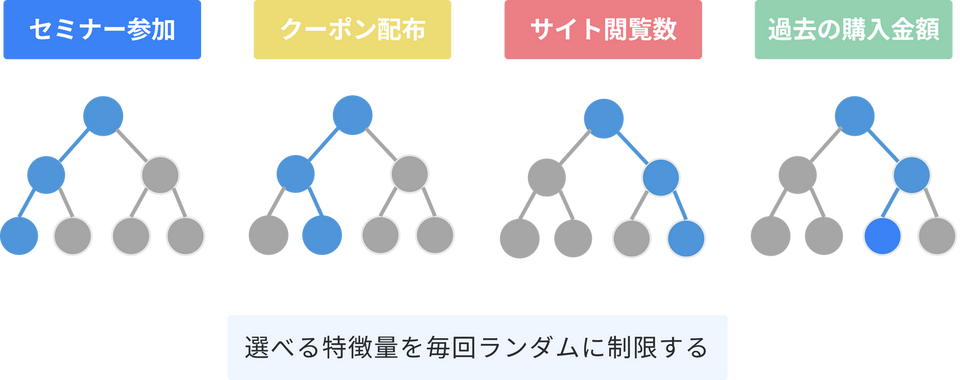
特徴量(判断材料)のランダム:
決定木が枝分かれ(条件分岐)を作る際、すべての判断材料(特徴量)を見るのではなく、ランダムに選ばれた一部の判断材料だけを使って分岐を考えさせます。
この2つのランダム性により、それぞれが異なる視点や偏りを持った多様な決定木(個性豊かな専門家たち)が多数出来上がります。
3. 多数決または平均で結果を統合
それぞれの木が個別に予測を出した後、最後はすべての木の結果を統合します。
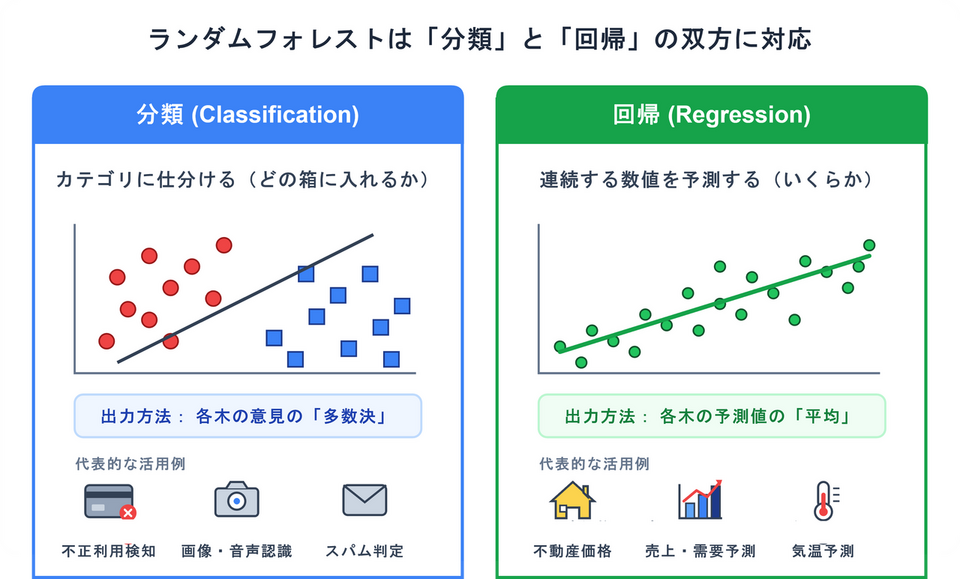
- 分類問題(カテゴリを予測する場合):
全ての木の意見をまとめ、最も多かった答えを採用する「多数決」で決めます。 - 回帰問題(数値を予測する場合):
全ての木の予測値の「平均」をとって最終的な答えにします。
例え話で理解する(クラスでクイズを解くイメージ)
この仕組みを「クラスのみんなで難しいクイズの答えを出す」場面に例えてみましょう。
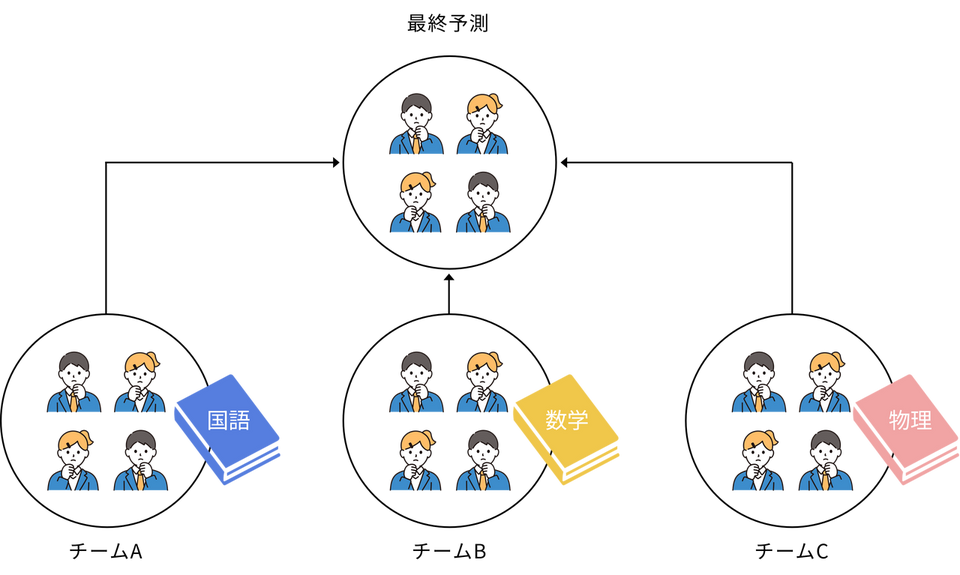
-
クラス全員で一斉に1つの答えを考えるのではなく、毎回ランダムに少人数の小さなチームをたくさん作ります(データのランダム)。
-
それぞれのチームには、別々の参考書やヒント(国語の知識だけ、数学の知識だけなど)をランダムに渡して、チームごとに独自の答えを出させます(特徴量のランダム)。
-
最後に、すべてのチームが出した答えを集めて、「多数決」で最終的なクラスの答えを決めます。
1つのチーム(1本の決定木)だけでは、知識に偏りがあって予測を間違えるかもしれません。しかし、違う知識を持ったたくさんのチームの意見を多数決や平均でまとめることで、個々の弱点を打ち消し合い、単独で考えるよりも非常に正確で安定した答えを導き出すことができます。これがランダムフォレストの仕組みです。
アンサンブル学習とは?
上記のように、複数の機械学習モデル(弱学習器)を組み合わせて、1つの強力なモデル(強学習器)を作り上げるアプローチを「アンサンブル学習」と呼びます。 アンサンブル学習には、ランダムフォレストが該当する「バギング」(並列で多数決をとる手法)のほか、間違いを修正しながら直列で学習する「ブースティング」、異なる種類のモデルを統合する「スタッキング」などの手法があります。
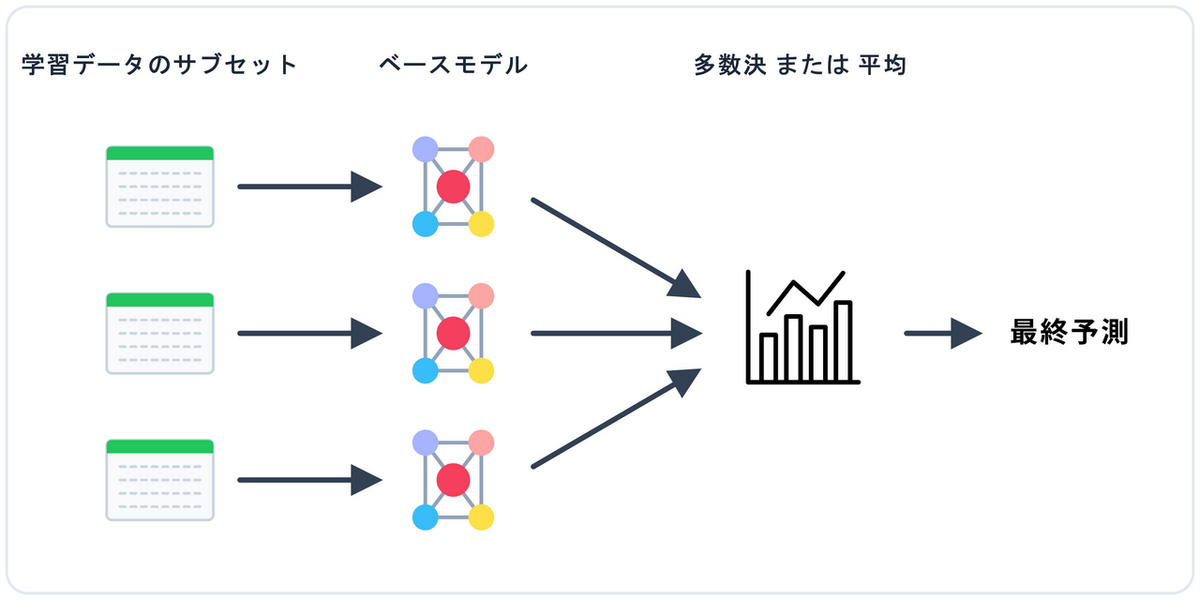
バギング
データをランダムに抽出して並列に学習し、結果を平等に多数決(平均)する手法です。モデルの極端な意見(過学習)を抑え、全体として安定した予測を実現します。本ページでご紹介するランダムフォレストはバギングの代表格です。
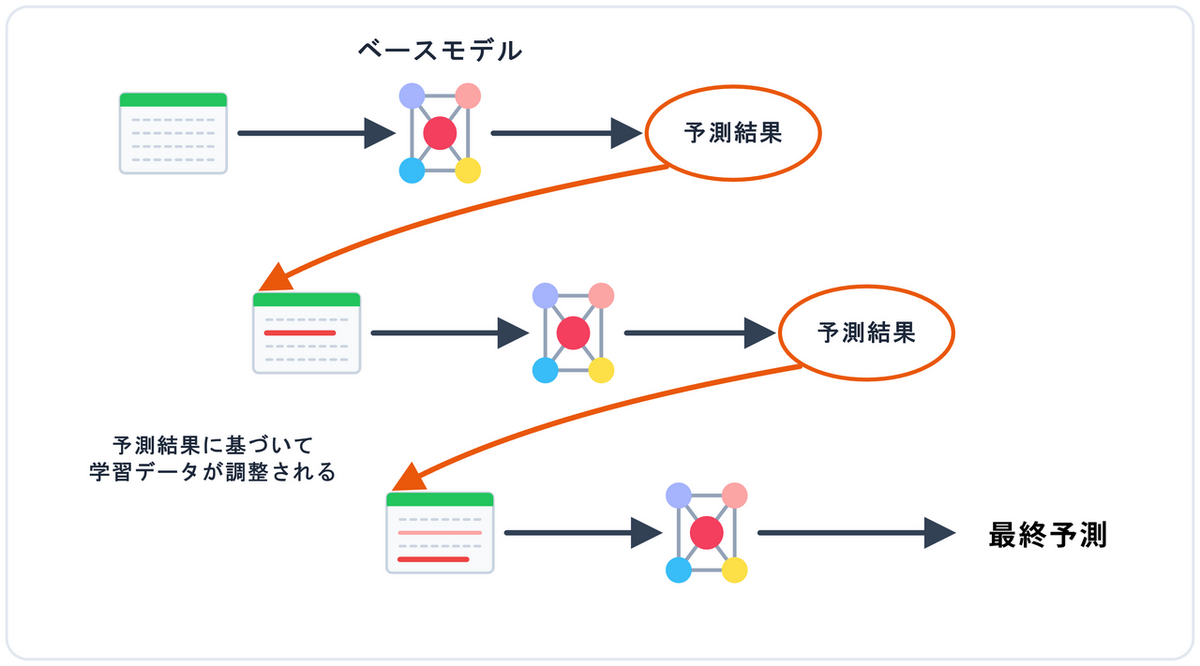
ブースティング
前のモデルが間違えたデータに注目し、直列に弱点を補強しながら学習する手法です。代表的なアルゴリズムとしてXGBoost や LightGBM などがあります。
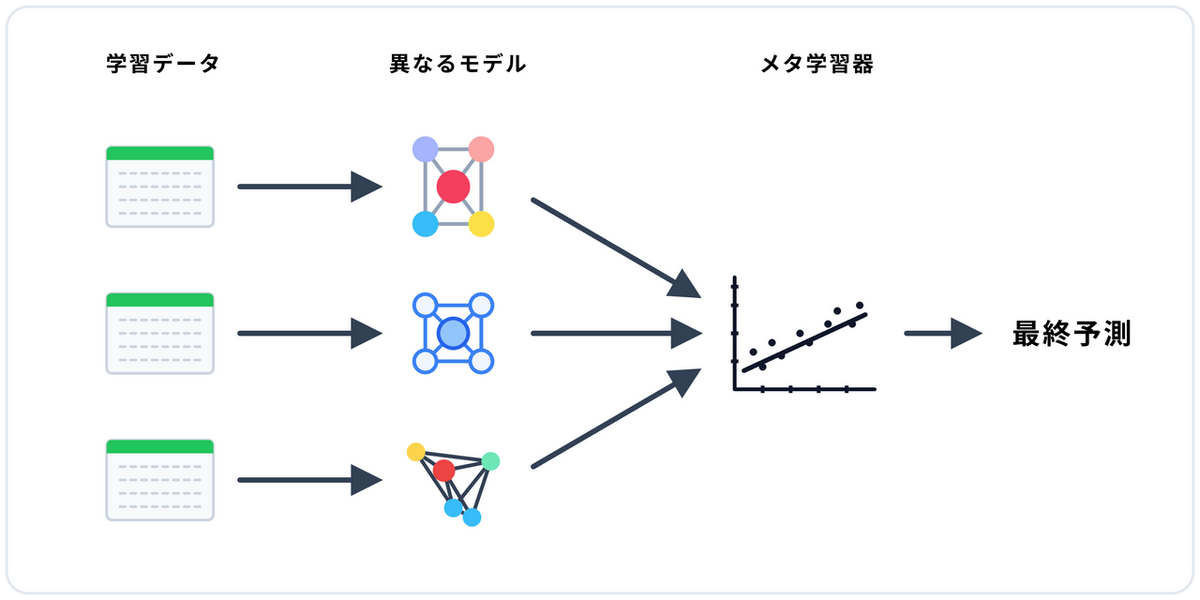
スタッキング
異なる種類のアルゴリズムを並列に走らせ、それらの予測結果をさらにメタモデルが再学習する手法です。それぞれのモデルの強みを引き出し、柔軟に統合することで高度な予測を目指します。
ランダムフォレストのメリットと注意点
ランダムフォレストには主に以下のようなメリットと注意点があります。
メリット
過学習(オーバーフィッティング)を防ぎやすい:
データと特徴量にランダム性を持たせて多数の木を作り平均化するため、データのノイズやばらつきを抑え、未知のデータに対して安定した予測が可能になります。
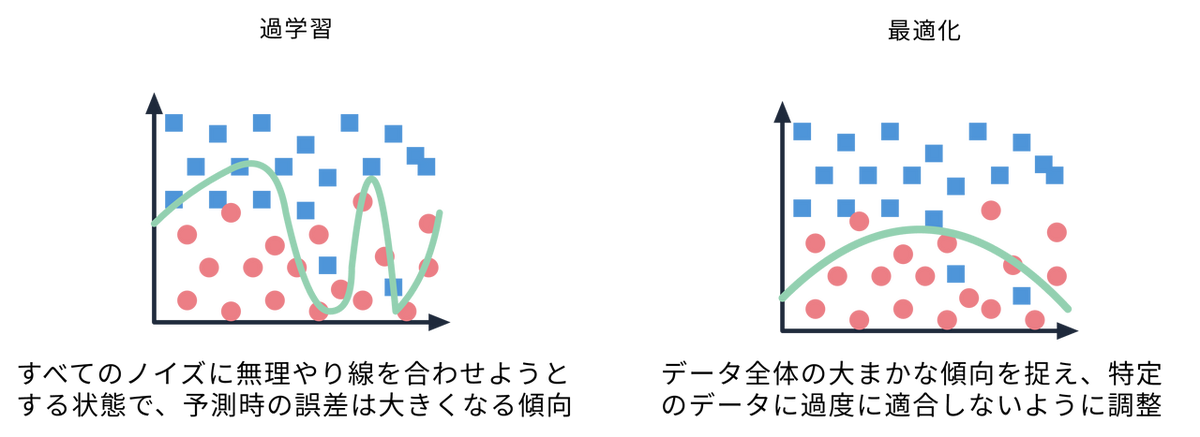
高い予測精度と汎用性:
分類問題と回帰問題の双方に対応しており、多様なデータに対して高い予測精度を発揮します。
特徴量の重要度が測定できる:
「どのデータ(変数)がどれくらい重要だったか」を数値化できるため、「なぜその予測になったのか」という要因分析や、不要な変数を削る特徴量選択に役立ちます。
注意点
外挿が苦手:
外挿とは、手元にあるデータの「範囲外」にある未知の数値を、これまでの傾向から予測することです。ランダムフォレストは、過去のデータをグループ分けして「このグループの平均値は〇〇」と予測する仕組みです。そのため、学習した範囲を超える未知のデータが入力されても、自ら新しい傾向の線を伸ばして計算することができません。結果として、「自分の知っている範囲の中で一番近い答え」を上限(または下限)としてそのまま返してしまうという弱点があります。
ブラックボックス化:
ブラックボックス化とは、モデルが「なぜその予測結果を出したのか」という内部の思考プロセスを、人間が追えなくなってしまう状態のことです。 1本の決定木であれば「築10年以下で、駅徒歩5分以内だから家賃は○○円」といった具体的な条件の分岐(ルート)を人間が目で見て解釈できます。しかし、ランダムフォレストは内部で複数の異なる木を作り、その多数決で最終的な予測を行います。 そのため、「結局、どういう条件の組み合わせでその結論に至ったのか」という詳細なプロセスが人間には解読できなくなるという注意点があります。
ランダムフォレストを実行するためのデータセット
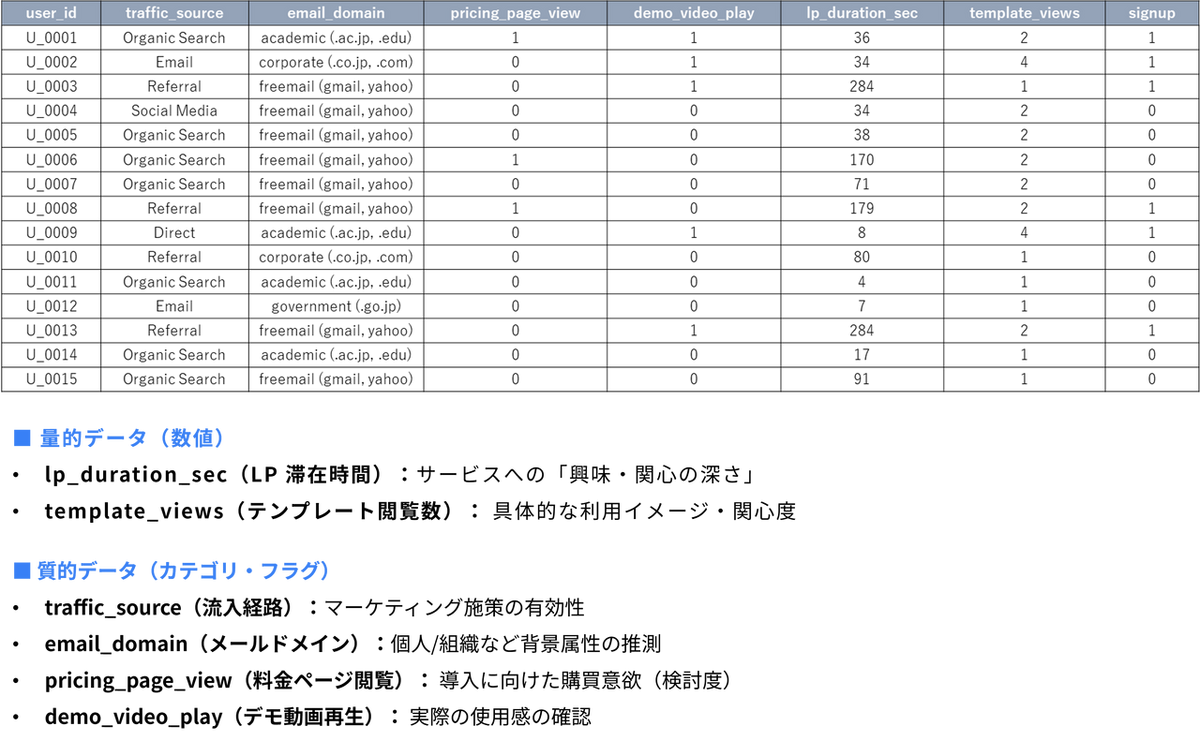
今回はある架空のSaaS 型オンラインデザインツールの過去のアクセスログおよびユーザー属性データ(1,000名分)を使用します。
サンプルデータのダウンロードはこちらから
dataset-for-random-forest-classification.xlsmこの分析の目的は、Web サイトを訪れたユーザーの行動や属性から、最終的に有料プランの検討や本登録(サインアップ)に至る確率を予測し、優先的にアプローチすべき有望な見込み客を見つけ出すことです。データセットに含まれる各変数の詳細は以下の通りです。
■ 目的変数
-
signup(サインアップ):
ユーザーが最終的にサービスに本登録したかどうかを表します。(0 = 未登録、1 = 登録済)。
■ 説明変数(量的データ)
-
lp_duration_sec(LP 滞在時間):
ランディングページ(最初の案内ページ)に滞在した秒数です。ユーザーのサービスに対する「興味・関心の深さ」を測る基本的な指標となります。 -
template_views(テンプレート閲覧数):
ツール内で提供されているデザインテンプレートを閲覧した回数です。具体的な利用イメージをどれくらい持っているか(機能への関心度)を示します。
■ 説明変数(質的データ)
-
traffic_source(流入経路):
ユーザーがどこからWeb サイトを訪れたかを表します。(例:Organic Search = 検索エンジン、Social Media = SNS、Direct = 直接訪問など)。マーケティング施策の有効性を測る指標です。 -
email_domain(メールドメイン):
ユーザーが問い合わせや一部機能の利用時に入力したメールアドレスのドメイン(@以降の部分)の種類です。(例:フリーメール、企業ドメイン、学術機関ドメインなど)。ユーザーが「個人」か「法人・組織」かなど、背後にある属性を推測する手がかりになります。 -
pricing_page_view(料金ページ閲覧):
料金プランのページを見たかどうかのフラグです。(0 = 見ていない、1 = 見た)。サービス導入に向けた「購買意欲(検討フェーズ)」の高さを示します。 -
demo_video_play(デモ動画再生):
ツールの使い方を解説する動画を再生したかどうかのフラグです。(0 = 再生していない、1 = 再生した)。実際の使用感を真剣に確認しようとしているかの指標となります。
XLSTAT でランダムフォレストを実行する手順
-
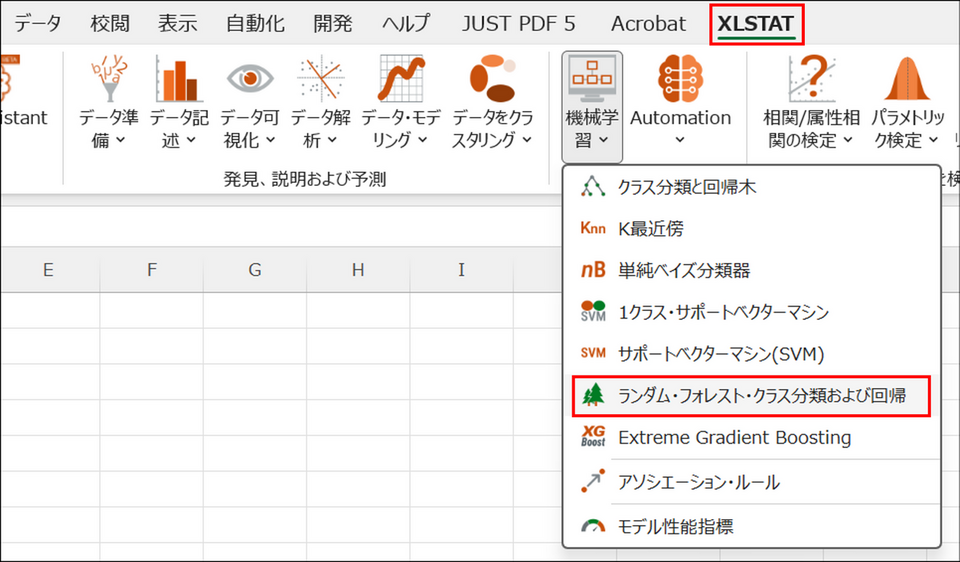
XLSTAT を起動し、[機械学習] > [ランダム・フォレスト・クラス分類および回帰] を選択します。
-
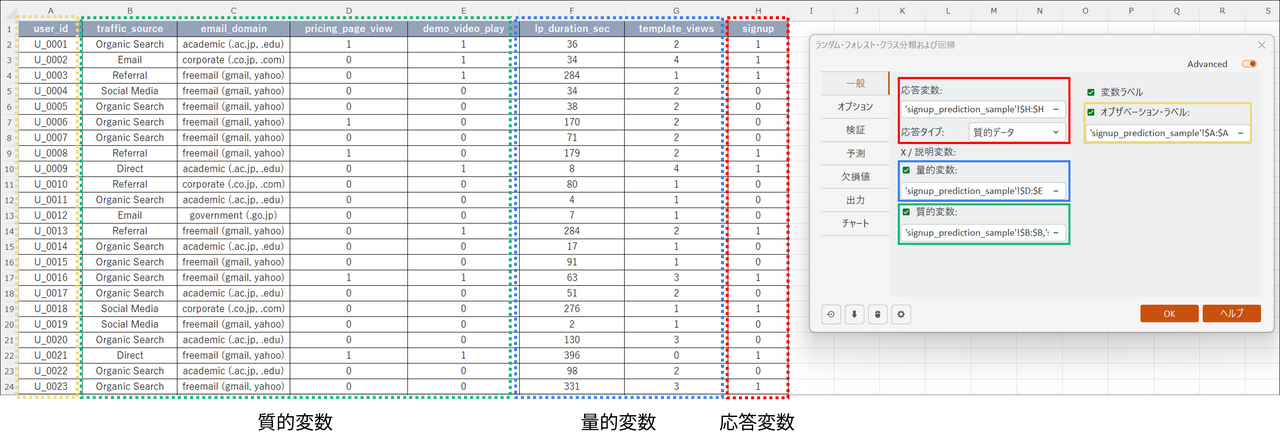
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
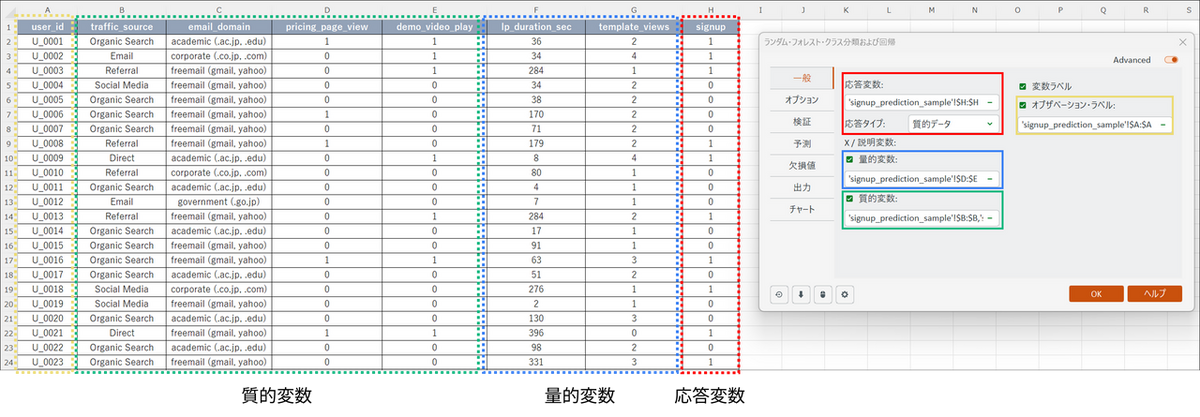
- 応答変数:「signup」の列を選択
- 応答タイプ:
「質的データ」を選択(※今回は0と1の数値データですが、分類問題として扱うために質的データを選択します)。 - 説明変数(量的変数):
チェックを入れ、「lp_duration_sec」 と「template_views」の列を選択 - 説明変数(質的変数):
チェックを入れ、「traffic_source」、「email_domain」、「pricing_page_view」、「demo_video_play」の列を選択 - 変数ラベル:見出し行を含めて選択した場合は、チェックを入れる
- オブザベーションラベル:チェックを入れ、「user_id」列を選択
- 応答変数:「signup」の列を選択
-
[オプション] タブに切り替え、各パラメータを設定します。
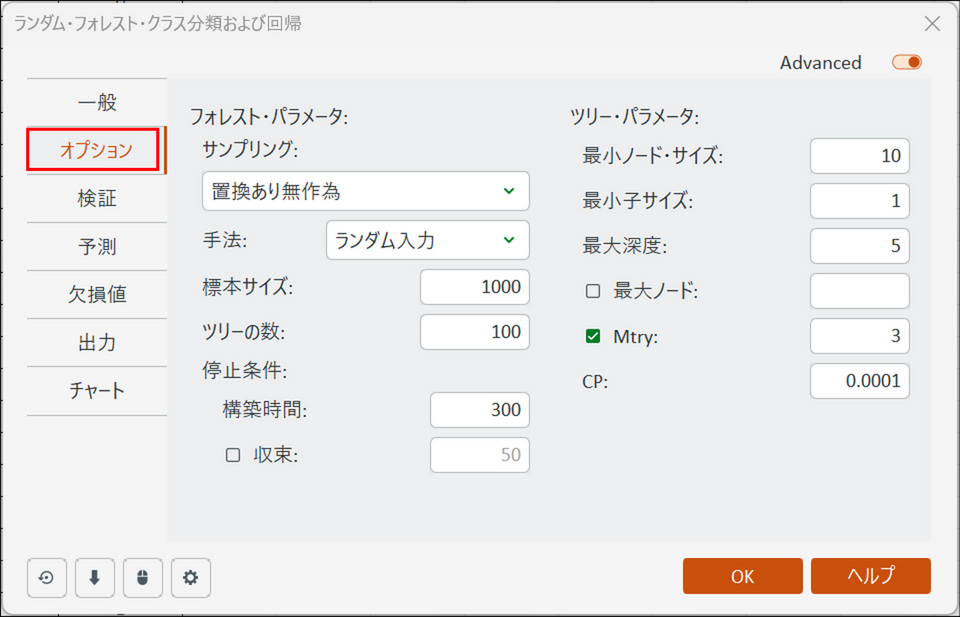
-
サンプリング:
ツリーを作るためのデータの抽出方法です。基本は「置換あり無作為(ブートストラップサンプリング)」を使用します。 -
手法:
「ランダム入力(ランダムフォレスト)」を選択します。 -
ツリーの数:
構築する決定木の総数です。多ければ安定しますが計算時間がかかります。まずは「100」から始めるのがおすすめです。 -
最小ノード・サイズ:
枝分かれ(データの分割)を実行するために、そのグループに最低何人のデータが必要かを指定します。少なすぎると少数の例外に振り回されるため、「10」などに設定して過学習を防ぎます。 -
最小子サイズ:
分割されたあとの新しいグループ(葉)に、最低何人のデータが残っていなければならないかを指定します。 -
最大深度:
木の深さ(条件分岐の階層)の上限です。これを「5」など適度に浅く制限することで、過学習を防ぎます。 -
Mtry:
各枝分かれでランダムに選ぶ変数の数です。空白でも自動計算されますが、目安として全変数の数の平方根(今回なら説明変数が6個なので「2」または「3」程度)を指定します。
-
-
[出力] タブに切り替え、以下の画面のように設定します。
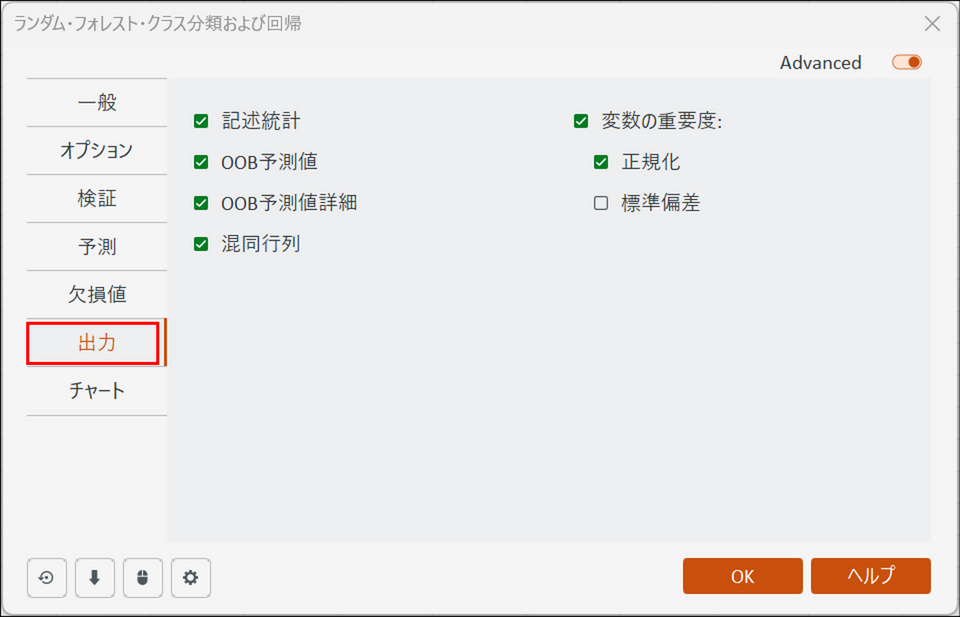
-
[チャート] タブに切り替え、以下の画面のように設定します。
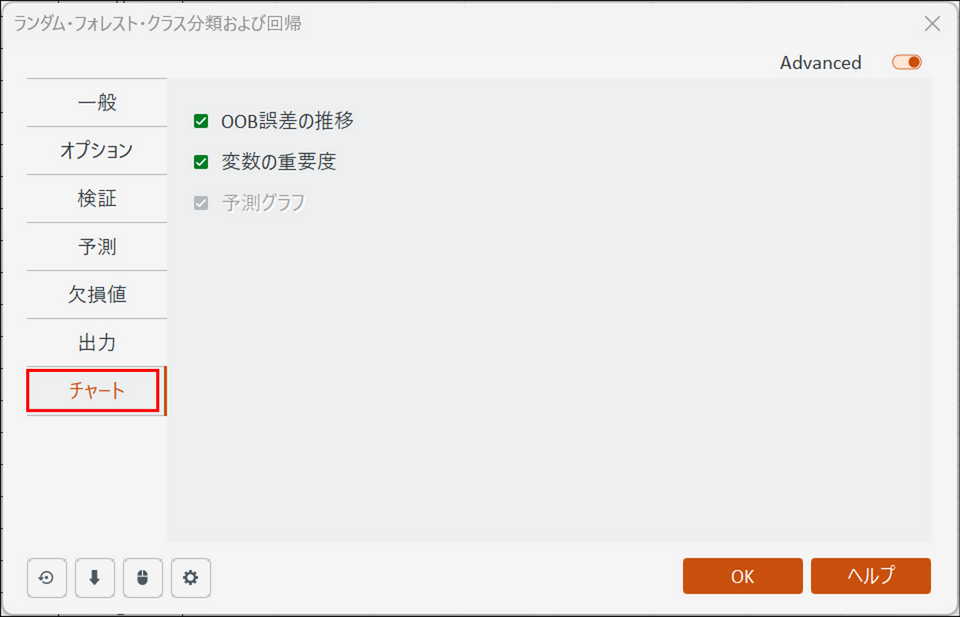
-
[OK] をクリックすると、計算が始まり、結果が別シート(RDF)に出力されます。
ランダムフォレストの結果の解釈
記述統計:
記述統計では読み込んだデータセットの各変数の平均や件数などの分布を確認し、データに偏りや異常値がないかチェックします。

今回のサンプルデータでは目的変数である「signup」が未登録(49.6%)と登録済(50.4%)でほぼ半分に分かれており、正解データのバランスが良い理想的な状態です。また、欠損値もなく、健全な分析を始められる状態であることがわかります。
誤分類率(OOB)とOOB 誤差推移のグラフ:
OOB(Out-Of-Bag)とは、ランダムフォレストなどのバギングを用いた手法において、ブートストラップサンプリングを行った際に、「一度も選ばれずに余ったデータ」のことを指します。機械学習では通常、モデルの性能を評価するためにデータを「学習用」と「テスト用」に分ける交差検証(クロスバリデーション)を行いますが、ランダムフォレストではこのOOB データをそのままテストデータとして再利用することができます。
今回の実行結果では、誤分類率が「0.262」と出力されました。これは予測を外した確率が26.2%であり、裏を返せば「約73.8%の確率でサインアップを見抜けるモデル」であることを示しています。

その下に表示される「OOB 誤差の推移」の折れ線グラフは、横軸に決定木の数、縦軸に誤分類率をとり、木を増やすにつれてモデルの精度がどう変化するかを可視化したものです。
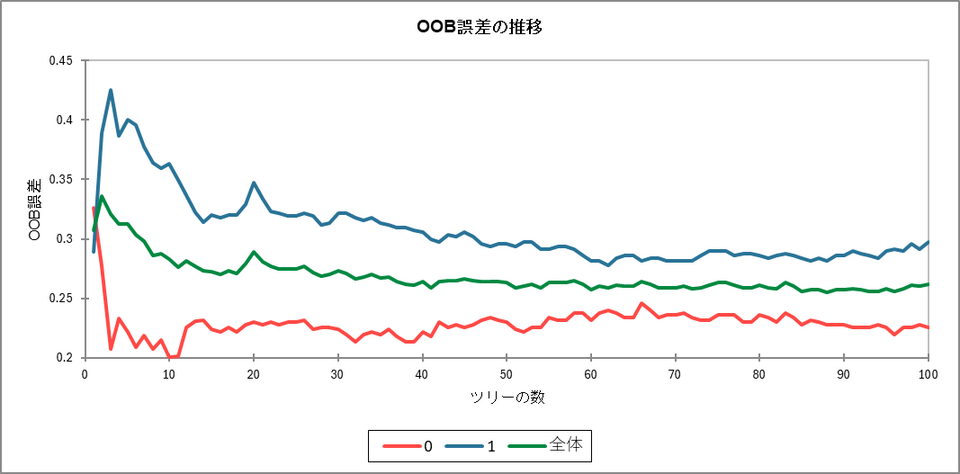
最初は木を増やすごとにOOB 誤差(誤分類率)が急激に下がっていきますが、ある程度の木の数に達すると、グラフは横ばいになります。誤差が横ばいになった後は、それ以上木を増やしても計算コストがかかるだけで、モデルの性能はほとんど向上しません。そのため、このグラフを見ることで、「どのくらいの木の数に設定すれば、効率よく最大の精度を引き出せるか」を見極めることができます。今回は横軸のツリーの数が40本を超えたあたりから、緑色の線(全体のエラー率)が0.26 付近で完全に横ばいになっています。これは「これ以上木を増やしてもモデルの予測精度は向上しない(100本で十分に学習が完了している)」ということを示しています。
混同行列 (OOB標本):
混同行列は予測と実際の答え合わせの表です。行が「実際のサインアップの有無」、列が「モデルが予測したサインアップの有無」を示します。対角線上にある数字が、正しく分類できた数です。
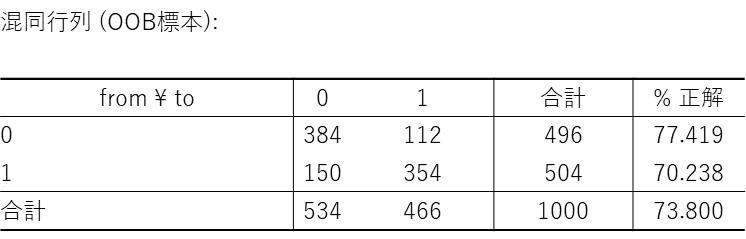
- 全体の正解率:738 / 1,000 = 73.8%
- 「未登録」を正しく予測できた割合:384 / 496 = 約77.4%
- 「登録」を正しく予測できた割合:354 / 504 = 約70.2%
この結果から今回作成されたモデルは、登録者層(予測精度70.2%)よりも未登録者層(予測精度77.4%)の特徴をより正確に見抜く傾向がありそうです。
新規サインアップの促進に向けた今後のプロモーション施策においては、モデルが「未登録」と予測したにもかかわらず、実際には登録に至った150名の層に注目することが重要であると考えられます。なぜなら、この層には、現在のモデルが捉えきれていない特有の動機や、サービスに対する隠れたニーズが存在している可能性があるためです。今後、これらの要因を深掘りして新たな指標として捉えることで、アプローチの改善およびサービス登録者数のさらなる増加が期待できるかもしれません。
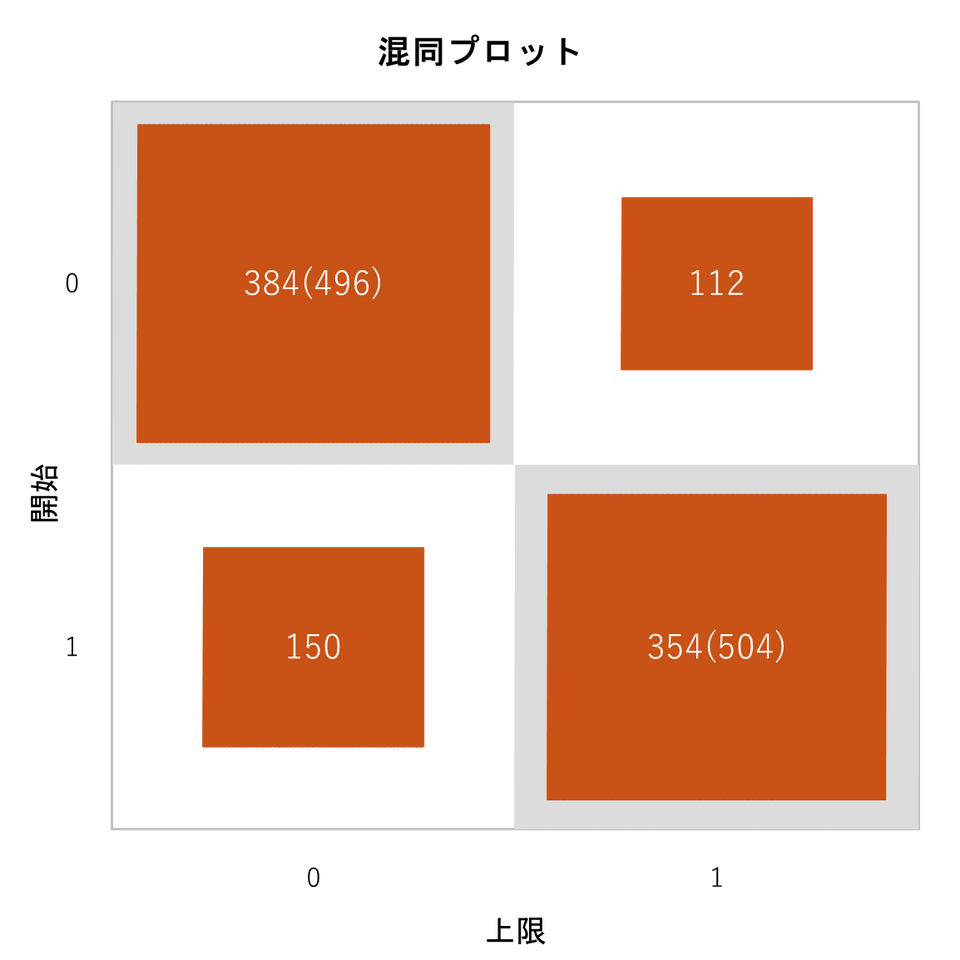
混同プロット:
混同プロットは一つ前の「混同行列 (OOB標本)」をグラフで可視化したものです。モデルの予測精度を、数字の表だけでなく直感的に把握するために使われます。
OOB 予測値:
学習データに含まれる各ユーザーに対して、モデルが最終的にどう予測したかの一覧表です。

出力された表を見ると、「U_0001」のように実際の signup と予測値が一致しているユーザーが並ぶなか、「U_0008」のように実際は登録(1)したのに、モデルは未登録(0)と予測してしまったケースも個別に確認することができます。このように予測を外したユーザーの元データをさかのぼって確認することで、イレギュラーな優良顧客のパターンを発見するなど、マーケティングの新たなヒントを得るのにも役立ちます。
変数の重要度 (平均減少正確度):
平均減少正確度(または平均正解率減少量、MDA:Mean Decrease Accuracy)とは、ランダムフォレストなどの機械学習モデルにおいて、各特徴量(変数)が予測結果に対してどれくらい重要であったか(変数重要度)を測るための指標の一つです。数値が大きいほど、モデルの予測において重要な変数であると解釈します。
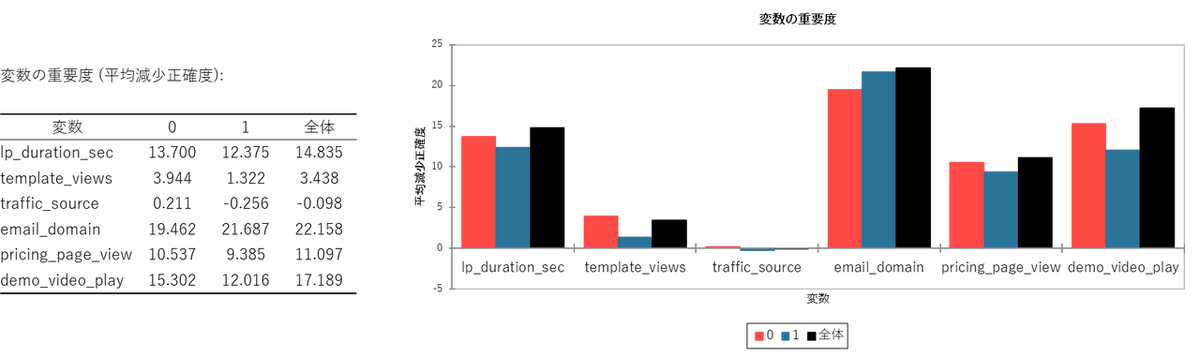
出力結果を「全体」のスコアに基づいて読み解くと、email_domain(メールドメイン)が一番高く、次いで demo_video_play(デモ動画再生)、lp_duration_sec(LP 滞在時間)、pricing_page_view(料金ページ閲覧)が続いています。一方で、traffic_source(流入経路)はマイナスになっており、ノイズとしてモデルの精度を下げている可能性があります。
この結果から、どこからサイトにアクセスしてきたか(SNS 経由か検索経由か)はサインアップの決め手にはならず、ユーザーの背後にある所属属性(学術機関か企業か等)と、デモ動画の視聴や十分な滞在時間といったサイト内での具体的な検討行動の方が重要であると考えられます。今後は流入経路の最適化よりも、デモ動画を見てもらうためのUI 改善等に取り組むことで登録者数を増やせるかもしれません。
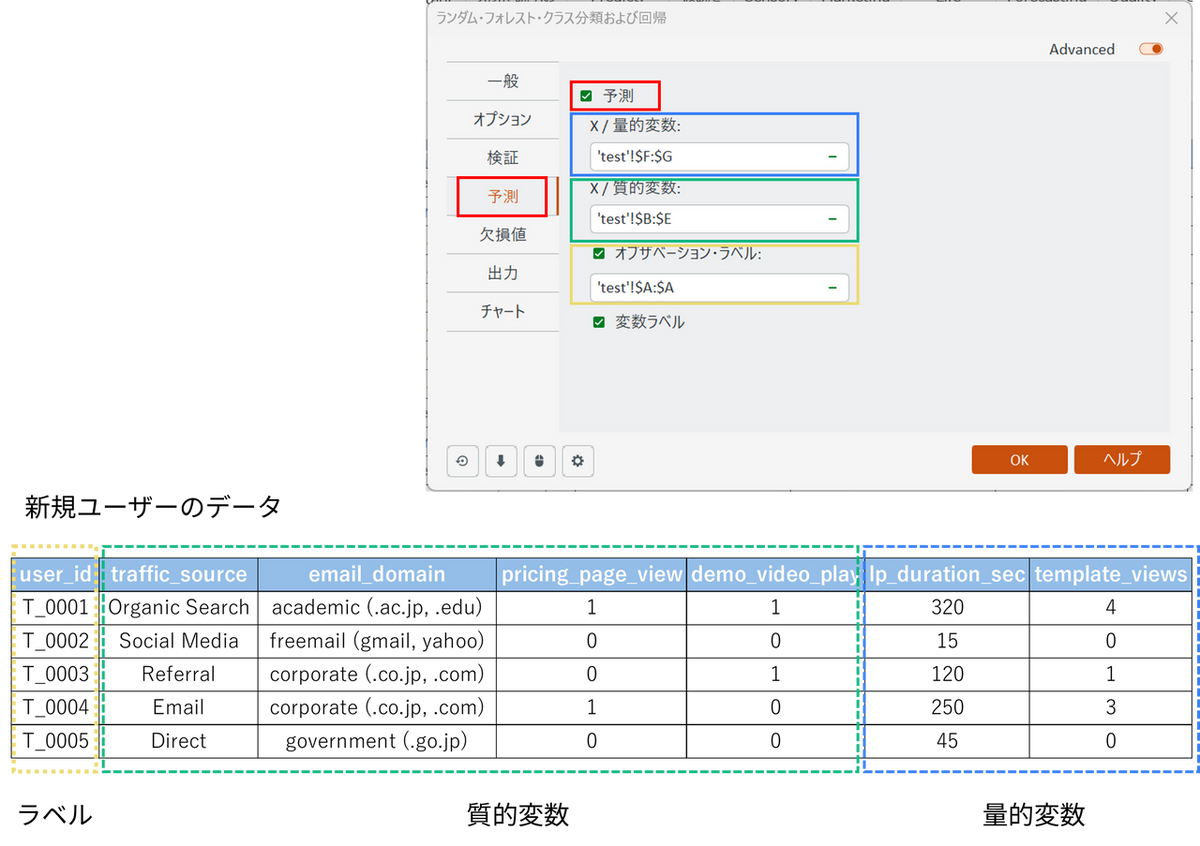
作成したモデルを用いて予測する
モデルが完成したら、まだ結果が分かっていない新規ユーザーのデータに対して予測を行ってみましょう。 今回は別シートに用意した下記5名のデータを使って、サインアップの予測を実行します。

【注意】
予測対象となるデータセットは、モデルの学習時に使用した元のデータセットと同じ変数項目(目的変数である「signup」列を除く)を同じ並び順で用意する必要があります。変数に過不足があったり、列の順番が異なっていたりする場合、実行時にエラーになるためご注意ください。
-
出力結果シートの上部の「▶」アイコンをクリックし、ランダムフォレストのダイアログ画面を開きます。

-
[予測] タブに切り替え、[予測] にチェックを入れ、以下のように新規ユーザーのデータ範囲を指定します。
-
[OK] をクリックすると、再度別シートにて結果が出力されます。
予測結果
予測結果は出力シートの一番下に表示されます。

結果には各ユーザーに対する「予測値(0/1)」が表示されます。 これを活用することで、例えば日々のWeb アクセスから得られた見込み客リストの中から、優先的に営業アプローチをかけるべき有望なユーザー(リード)を自動でリストアップできるようになります。
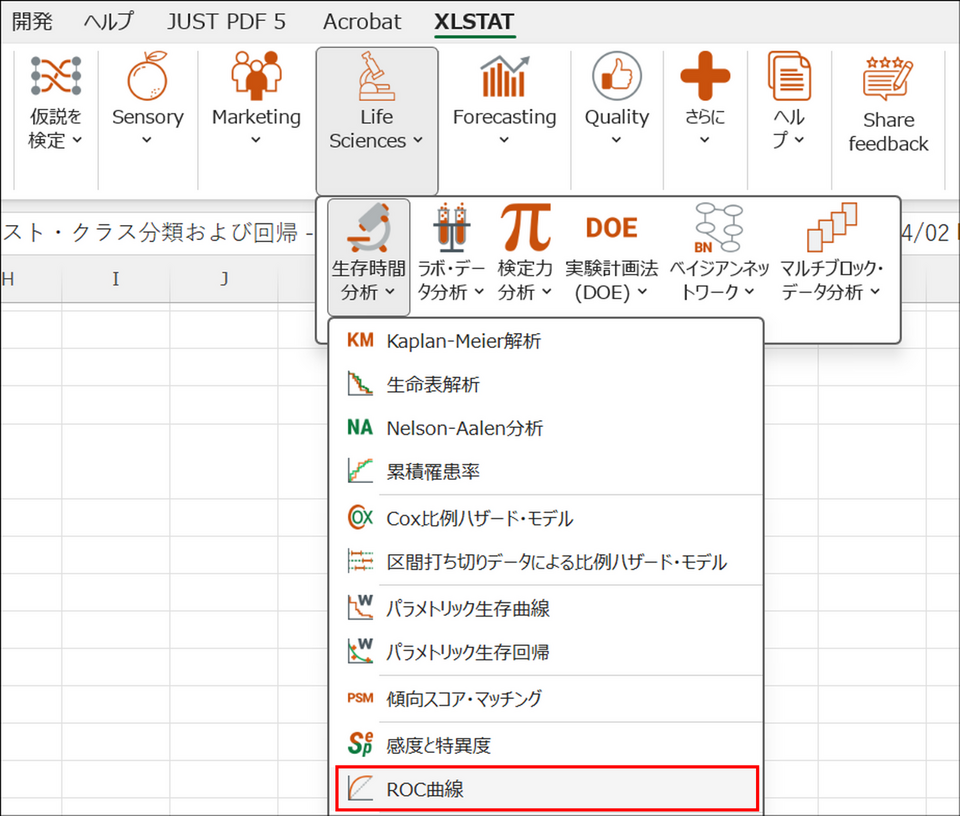
結果からROC 曲線を作成する
ランダムフォレストの総合的な評価指標であるROC 曲線(AUC)を描画したい場合、出力された「OOB 予測値」の表を利用することで簡単に作成できます。
※「ROC 曲線」はAdvanced のライセンスでご利用いただけます。
-
XLSTAT メニューの [Life Sciences] > [生存時間分析] > [ROC曲線] を選択します。
-
表示されたダイアログ画面で以下のようにデータを選択します。
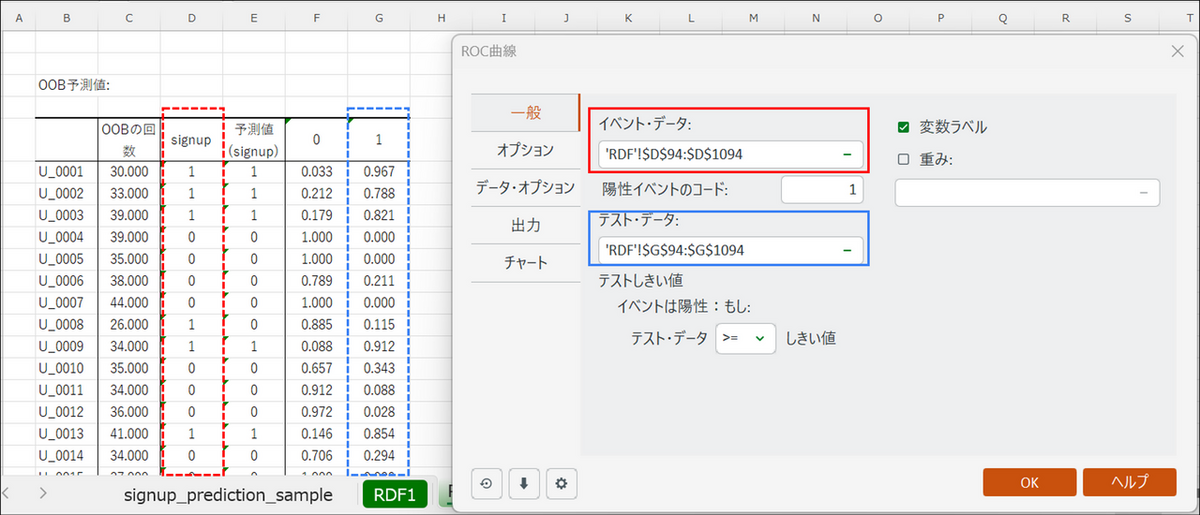
- イベント・データ:実際の正解データ(signup)の列を選択
- 陽性イベントのコード:「1」と入力
- テスト・データ:予測された「1」の確率の列を選択
-
[OK] をクリックすると結果が別シート(ROC曲線)に出力されます。
ROC 曲線
ROC 曲線では曲線がグラフの左上に向かって大きく膨らんでいるほど、予測性能が高いことを示しています。AUC の値は最大1 で、1 に近いほど高性能です。今回のデータではAUC が「0.804」なので、予測性能が優れていると判断できます。
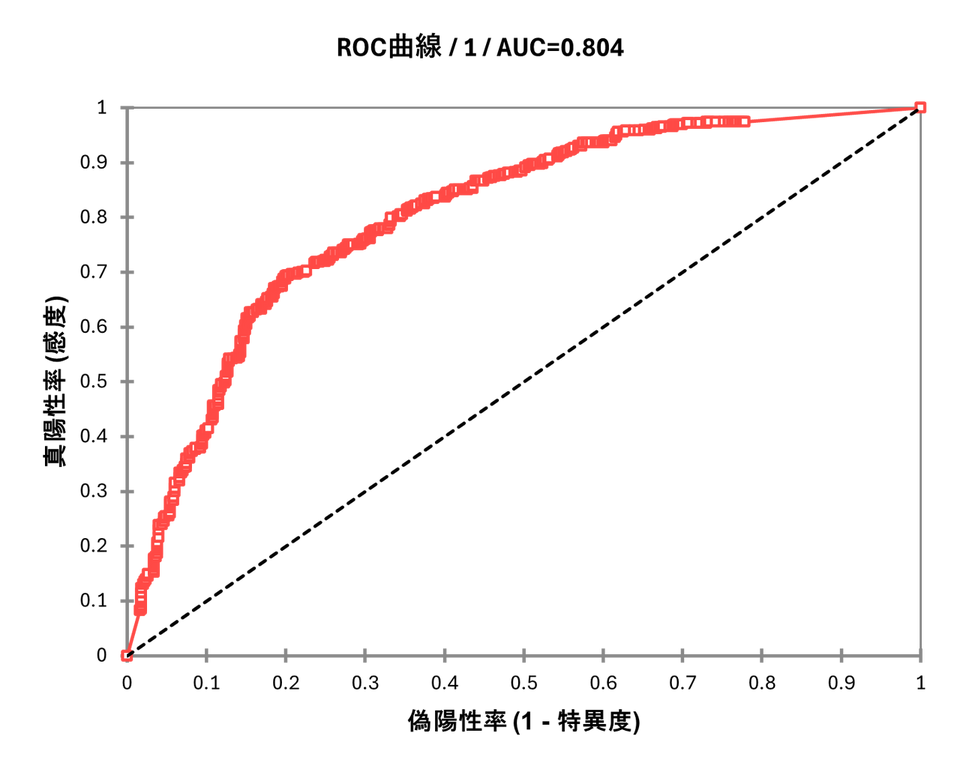
ROC 曲線の詳細については下記ページもあわせてご参照ください。
まとめ
ランダムフォレストは、データの背景にある複雑な法則を自動で見つけ出し、高精度な予測と変数の重要度による根拠を提示してくれる、ビジネスにおいて極めて実用性の高い手法です。XLSTAT を活用すれば、Python などのプログラミング知識がなくても、普段使い慣れたエクセルの画面上から直感的なマウス操作だけで、本格的な機械学習モデルの構築、パラメータの設定、そして予測までをシームレスに完結させることができます。ぜひ、お手元のマーケティングデータや顧客データを使って、予測分析をスタートしてみましょう。
参考文献
- XLSTAT: Random Forest Classification in Excel. https://community.lumivero.com/s/article/6602-random-forest-classification-excel-tutorial?language=en_US
- 青の統計学. 【アンサンブル学習】ランダムフォレストをわかりやすく解説|ブートストラップ法を決定木に応用. https://statisticsschool.com/%E3%80%90%E3%83%A9%E3%83%B3%E3%83%80%E3%83%A0%E3%83%95%E3%82%A9%E3%83%AC%E3%82%B9%E3%83%88%E3%80%91%E3%83%96%E3%83%BC%E3%83%88%E3%82%B9%E3%83%88%E3%83%A9%E3%83%83%E3%83%97%E6%B3%95%E3%82%92%E6%B1%BA/
- ランダム・フォレストとは. https://www.ibm.com/jp-ja/think/topics/random-forest
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したランダムフォレストはStandard と Advanced のライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。


