XLSTAT による決定木分析:分類木で個体情報をもとにアヤメの花を分類しよう
- 決定木分析とは?
- 分類木を実行するためのデータセット
- XLSTAT で分類木を実行する手順
- 出力結果の解釈
- 【補足】ノードのグラフを円グラフに変更する
- まとめ
- 参考文献
- XLSTAT の無料トライアル
決定木分析とは?
決定木分析は、機械学習の手法の一つで、データが持つルールやパターンを見つけ出すために使われます。木の枝が分岐していくような図(樹形図)を使って結果を表現するのが最大の特徴です。上から順に、データを最も上手く分類・予測できる「質問(ルール)」を見つけてデータを分割していきます。例えば、顧客がサービスを契約するかどうかを予測するケースを考えてみましょう。
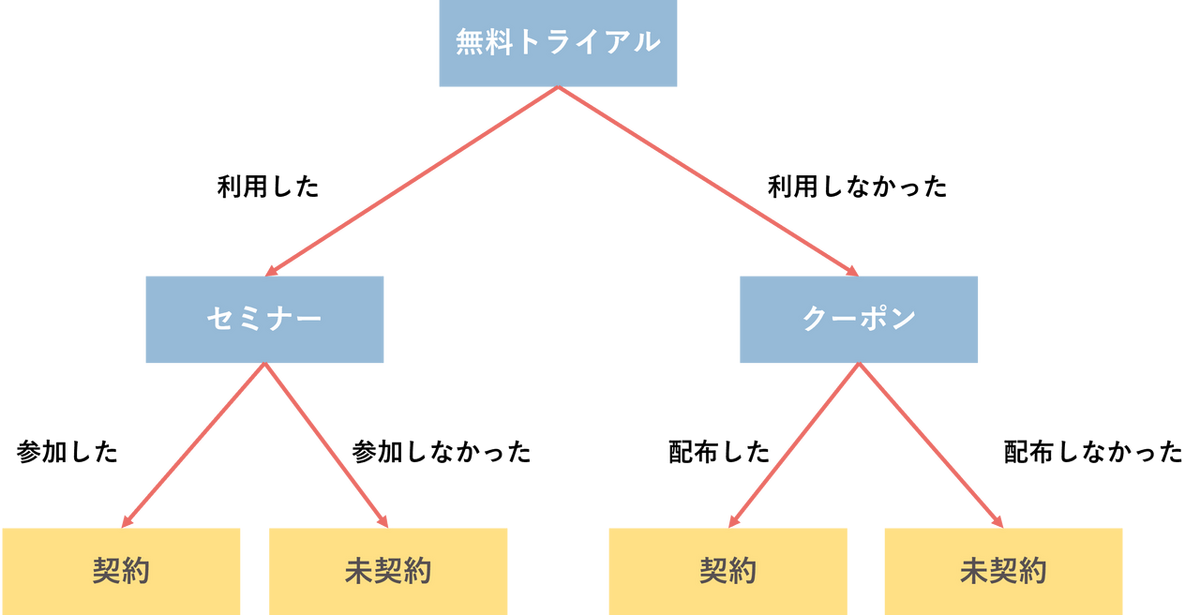
上図のように、まず「無料トライアルを利用したか?」という質問で顧客を二分します。「利用した」顧客は次に「セミナーに参加したか?」でさらに分岐し、最終的に「契約」か「未契約」かの予測に至ります。「利用しなかった」顧客は「クーポンを配布したか?」で分岐し、同様に予測します。このように、質問を繰り返してデータを分割していくことで、最終的な予測結果を導き出します。
この手法は、結果が視覚的にわかりやすく、どのような基準で判断が行われたのかというルールが明確になるという利点があります。決定木分析は、予測したい対象(目的変数)の種類によって、主に2つのタイプに分けられます。
- 分類木:
「品種はどれか?」「合格か不合格か?」といった、データが属するカテゴリ(クラス)を予測する場合に使います。 - 回帰木:
「売上はいくらか?」「価格はいくらか?」といった、数値を予測する場合に使います。
分類木を実行するためのデータセット
今回の分析では、統計学で有名な「アヤメ(Iris)のデータセット」(Fisher, 1936)を使用します。

画像引用:https://www.kaggle.com/code/sunaysawant/iris-eda
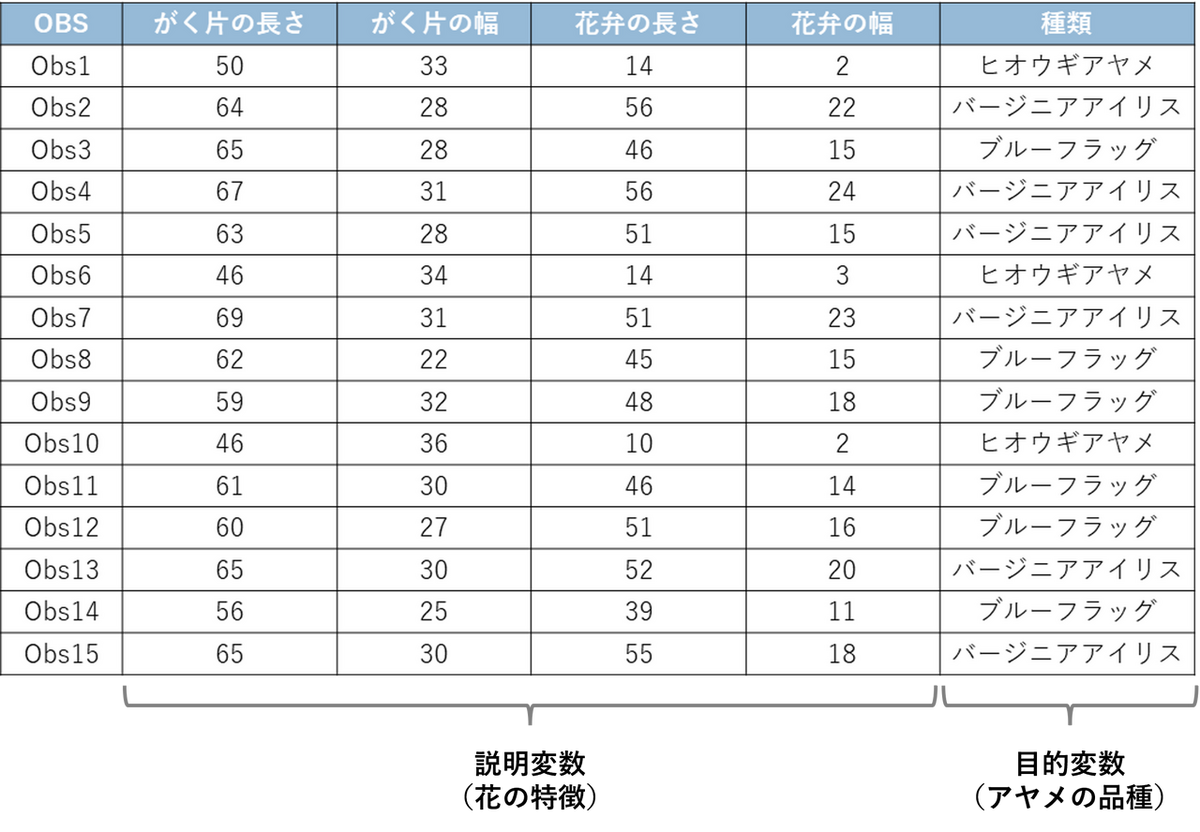
このデータには、150のアヤメの花について、以下の情報が含まれています。
- 説明変数(花の特徴):
- がくの長さ
- がくの幅
- 花弁の長さ
- 花弁の幅
- 目的変数(アヤメの品種):
"ヒオウギアヤメ"、"ブルーフラッグ"、"バージニアアイリス" の3種類
このデータセットを用いて、花の特徴(説明変数)から、その花がどの品種(目的変数)なのかを予測する分類木を作成します。
サンプルデータのダウンロードはこちらから
Dataset-for-CHAID-Classification-Tree.zipXLSTAT で分類木を実行する手順
-
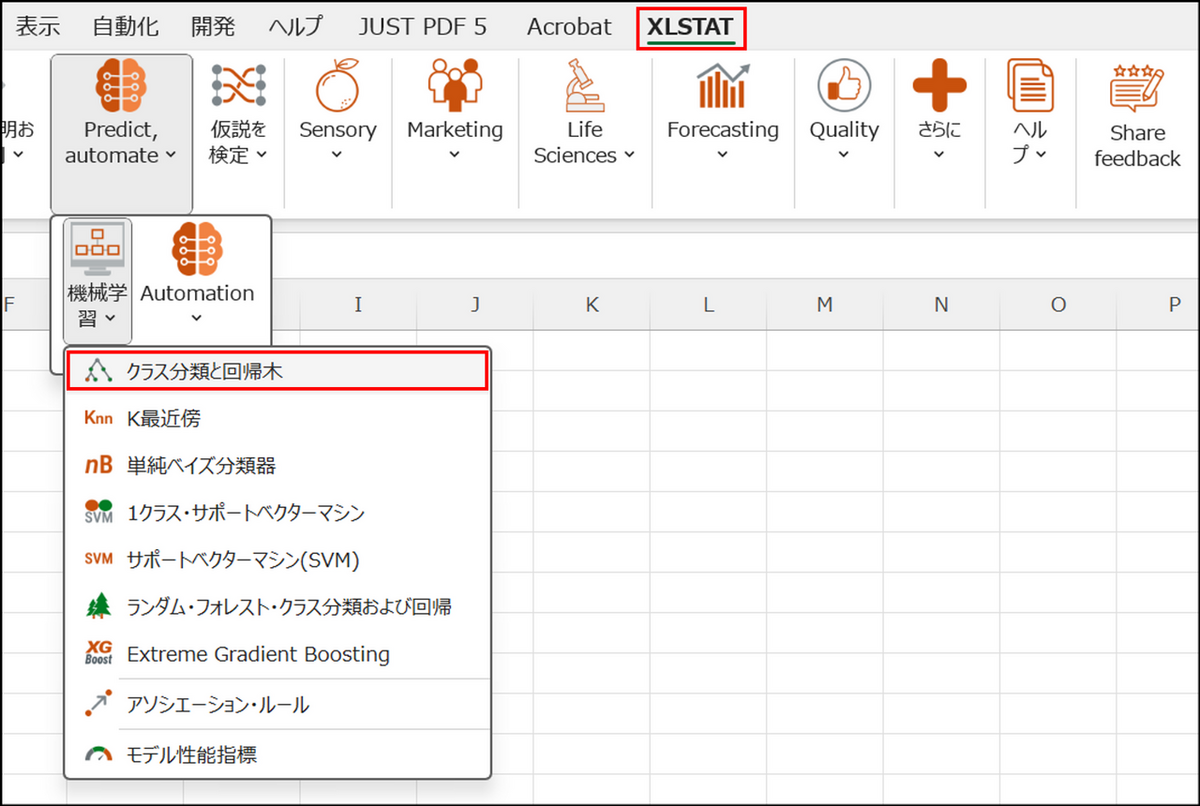
XLSTAT を起動し、[Predict, automate] > [機械学習] > [クラス分類と回帰木] を選択します。
-
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
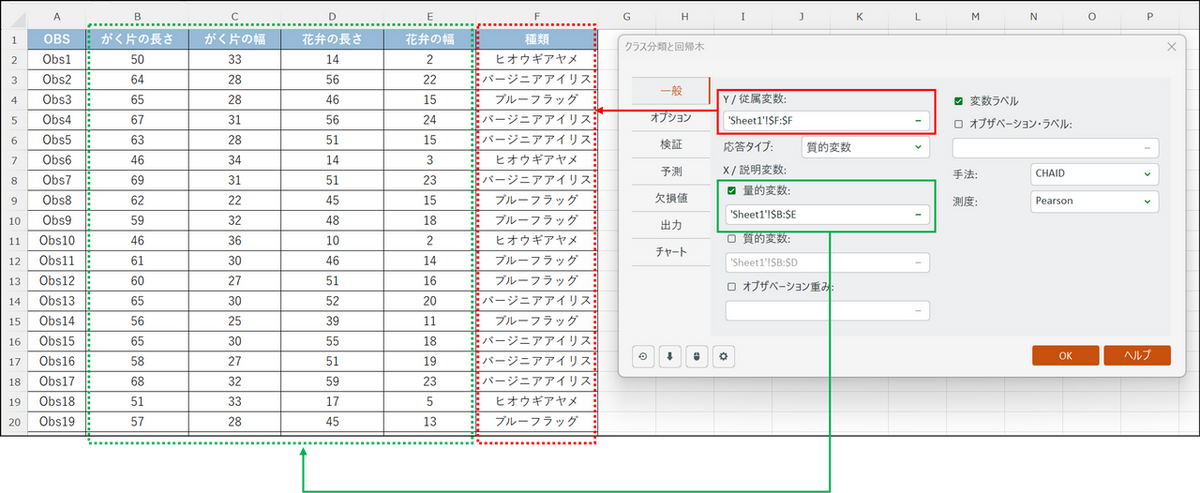
- Y / 従属変数:「種類」の列を選択
- 応答タイプ:「質的変数」を選択
- X / 説明変数:
[量的変数] にチェックを入れ、「がく片の長さ」「がく片の幅」「花弁の長さ」「花弁の幅」の4つのデータ列をまとめて選択します。 - 手法:[CHAID] を選択
- 変数ラベル:
見出しの行も含めて選択しているため、チェックを入れる。
-
[オプション] タブに切り替え、[一般] と [CHAID] の画面を以下のように設定します。
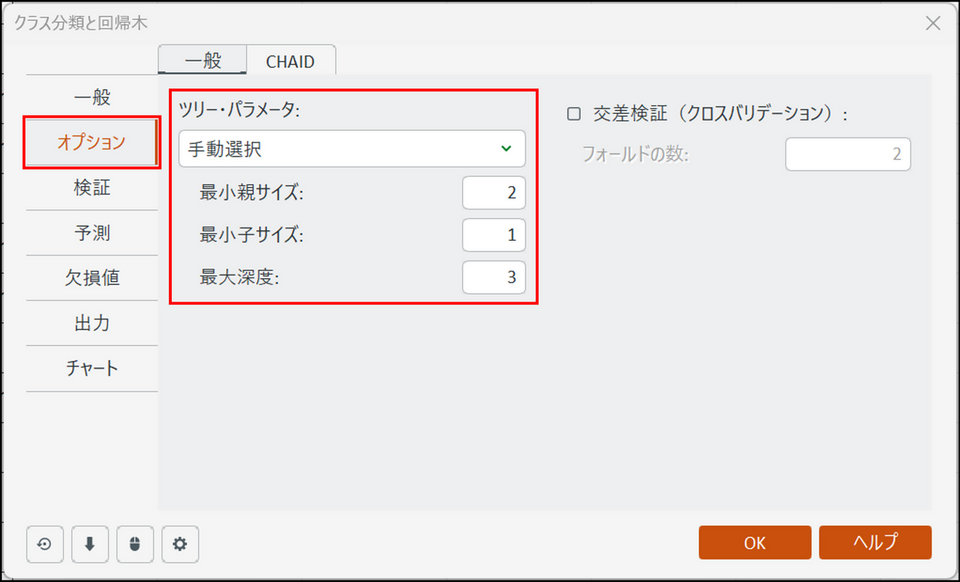
- 最大深度: ここでは「3」に設定します。
※この設定は、木が複雑になりすぎる(過学習)のを防ぐために行います。木の分岐の深さを最大3段階までに制限します。
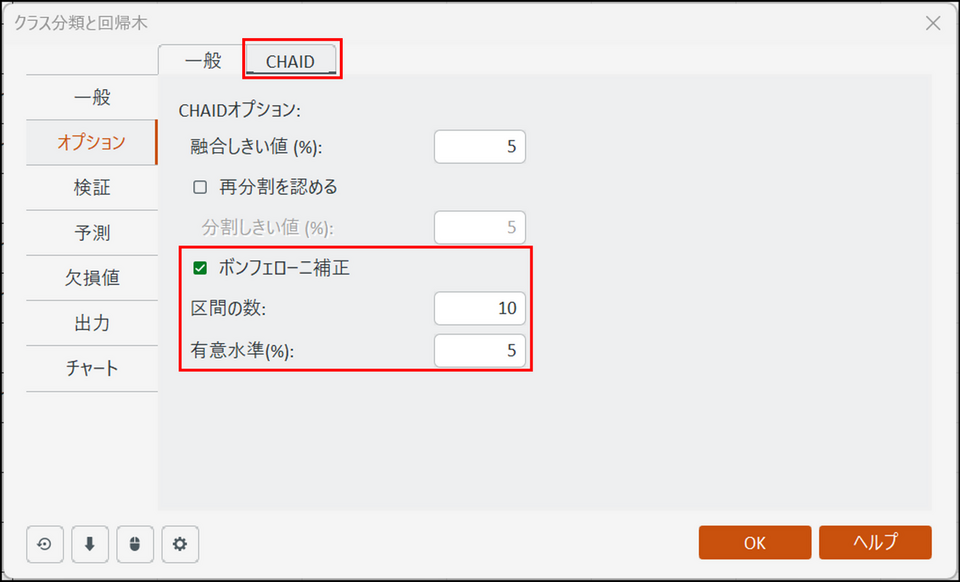
- 最大深度: ここでは「3」に設定します。
-
[出力] タブに切り替え、以下のように設定します。
-
[チャート] タブに切り替え、以下の設定を行います。
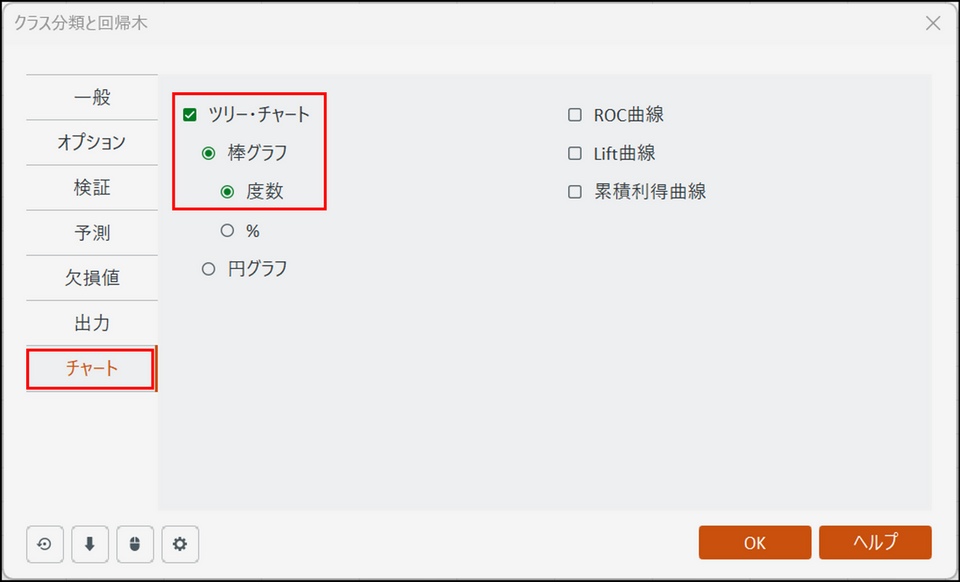
- ツリー・チャート :チェックを入れ、[棒グラフ] を選択
これにより、各分岐点(ノード)で、品種がどのように分布しているかが棒グラフで可視化されます。
- ツリー・チャート :チェックを入れ、[棒グラフ] を選択
-
すべての設定が終わったら、[OK] ボタンをクリックすると、計算が始まり、結果が別シート(ツリー)に出力されます。

出力結果の解釈
結果シートには多くの情報が出力されますが、特に重要なポイントを解説します。
1. 混同行列
混同行列は、モデルがどれだけ正確に分類できたかを示す「成績表」のようなものです。
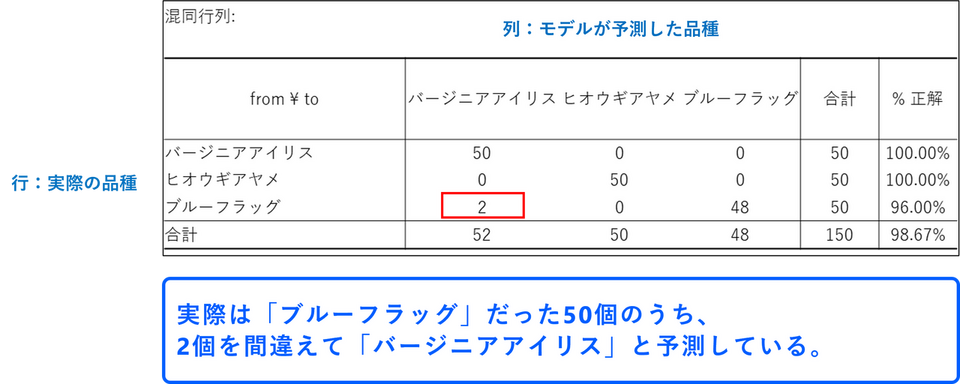
- 行が「実際の品種」、列が「モデルが予測した品種」を示します。
- 対角線上にある数字(例:「ヒオウギアヤメ」と予測され、実際「ヒオウギアヤメ」だったのが50)が、正しく分類できた数です。

今回の例では、実際には「ブルーフラッグ」だった 50 個のうち、モデルは 48 個を「ブルーフラッグ」と正しく予測しましたが、2 個を誤って「バージニアアイリス」と予測してしまいました。このため、このカテゴリの正解率は 96.00% となっています。全体としては、150個のデータのうち148個が正しく分類され、誤分類はわずか2個でした。そのため、正解率は98.67%となり、精度の高いモデルが構築できたことがわかります。
表の下には混同行列の内容を視覚的に表現したグラフが表示されます。このグラフを確認することで、モデルの予測結果がどれだけ正しかったか、また、どのように間違えたかを一目で把握することができます。
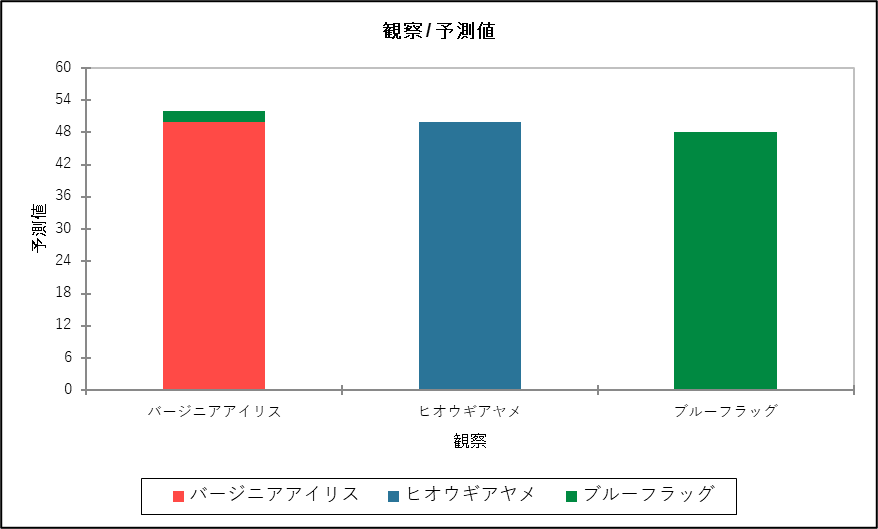
グラフの読み方は以下の通りです。
- 横軸(観察):モデルが予測した品種のグループを示しています。
- 縦軸(予測値):モデルが予測した各品種の個数を示しています。
- 棒グラフの色:「実際の品種(正解)」を色で示しています。
- 赤:バージニアアイリス
- 青:ヒオウギアヤメ
- 緑:ブルーフラッグ
グラフを見ると、「バージニアアイリス」と予測された棒グラフ(左)は、大部分が赤色(正解)ですが、わずかに緑色(実際はブルーフラッグ)が混じっています。
一方、「ヒオウギアヤメ」と予測された棒グラフ(中央)は青色のみ、「ブルーフラッグ」と予測された棒グラフ(右)は緑色のみの単一色になっています。これは、モデルが「ヒオウギアヤメ」または「ブルーフラッグ」と予測したケースには、間違いがなかったことを示しています。
2. ツリー構造
ツリー構造は、モデルがアヤメの品種を分類するために作成した「ルールの設計図」です。樹形図の各分岐点(ノード)がどのようなルールで分割され、どのような特徴を持っているかを詳細に記述しています。
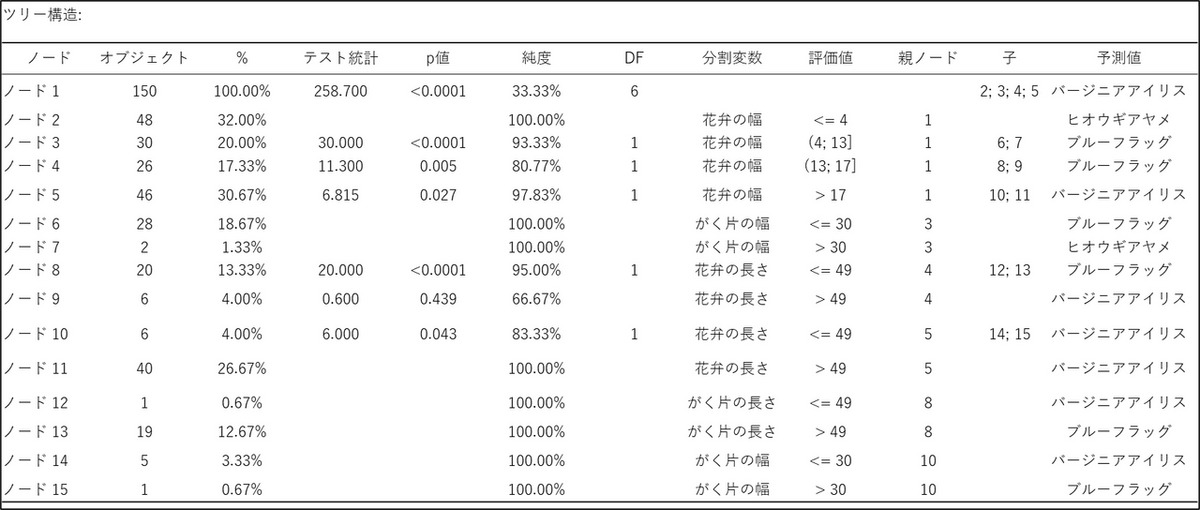
各列の主な意味
- ノード:
木の各分岐点や終点の番号です。「ノード 1」が一番上の出発点(根ノード)です。 - オブジェクト:
そのノードに含まれる花の数です。 - p値:
このノードをさらに分割するルールが、統計的に意味があるかどうかを示す指標です。p値が小さいほど(例: <0.0001)、その分割が有効であることを意味します。 - 純度:
そのノード内で最も多い品種が占める割合です。例えば、ノード3 では30個中、最も多い品種(ブルーフラッグ)は28個です。そのため、28÷30 = 93.33%となります。純度が100% になると、そのノードは1種類の品種だけで構成されており、完全に分類が完了したことを示します(これを終端ノードまたは葉ノードと呼びます)。 - 分割変数:
データを分割するために使われた花の特徴(例:「花弁の幅」)。 - 評価値:
分割するための具体的な条件(例:「<= 4」)。 - 予測値:
このノードに分類されたデータが、どの品種であるとモデルが予測したかを示します。
具体的な読み方の例
この表を文章で読み解くと、以下のようになります。
1. スタート地点(ノード 1)
- 全150個のデータから開始します。
- 最初の分割は「花弁の幅」で行われます (p値 < 0.0001 なので非常に有効な分割です)。
- この分割によって、データはノード2, 3, 4, 5の4つのグループに分かれます。
2. 最初の分岐(ノード 1 からの分岐)
- もし「花弁の幅 <= 4」なら → ノード 2 に進みます。
- ここには48個の花が分類され、純度は100%。すべて「ヒオウギアヤメ」と予測され、ここで分類は完了です。
- もし「花弁の幅が (4, 13]」(4より大きく13以下)なら → ノード 3 に進みます。
- ここには30個の花が分類されます。さらに「がく片の幅」でノード6と7に分割されます。
- 以下、同様に分岐が続きます
3. ルール
これは、上記「ツリー構造」で示された複雑な分岐ルールを、人間が読みやすい自然な文章で要約したものです。

例えば、ノード2 のルールは「もし花弁の幅 <= 4であれば、ケースの32%で種類 = ヒオウギアヤメである。」と記述されています。これは「(全データのうち)32%(48個)の花が『花弁の幅が4以下』という条件に該当し、そのグループ(ノード2)に分類されました。そして、そのグループの花は100%の純度で(つまり、すべてが)ヒオウギアヤメであると正しく予測されました。」という意味になります。
4. 分類木(樹形図)
これが分類木の本体です。ここまでみてきた「ツリー構造」の表や「ルール」のテキストを視覚的な図にしたもので、アルゴリズムがどのようにデータを分割していったかを直感的に示します。
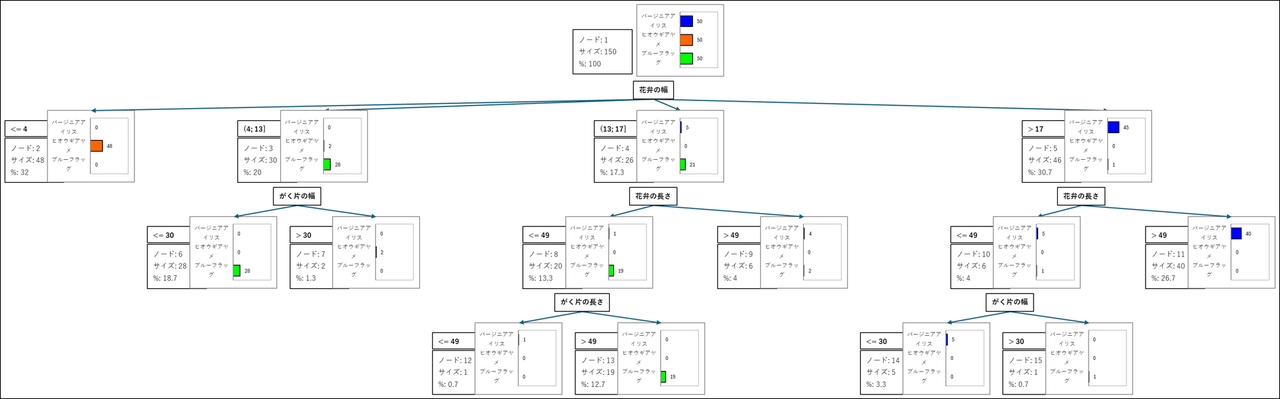
ノードの読み方
樹形図の各ノードは、以下の情報で構成されています。この読み方を理解することで、モデルがどのように判断しているかを詳細に追うことができます。

- 分割の変数:
ノードを分割するために使用された変数(例:花弁の幅)。親ノードから分岐する矢印の上、またはボックス内に表示されます。 - 分割の値:
親ノードからこのノードへ分岐するための具体的な条件(例:4;13)。 - ノード識別子:
ノードの番号(例:ノード: 3)。「ツリー構造」の表と対応しています。 - ノードのオブジェクト数:
このノードに分類された花の合計数(例:サイズ: 48)。 - 割合 (%):
データ全体(150個)のうち、このノードに属するデータの割合(例: 「%: 20」は 30個 / 150個 を意味します)。 - 純度:
このノード内で、最も多い品種(優勢カテゴリ)が占める割合(例: 「93.3」は28個 / 30個 を意味します)。
※デフォルトのボックスサイズでは、この行が隠れて表示されていない場合があります。その場合は、Excel 上で樹形図のオブジェクトを選択し、該当するノードのテキストボックスの枠線をドラッグして、ボックスの高さを広げることで表示できます。 - カテゴリごとのオブジェクト数 (棒グラフ):
そのノードに含まれるデータの内訳です。棒グラフと数字で、各品種が何個含まれているかを示します。
分岐プロセスの具体例(ノード3):
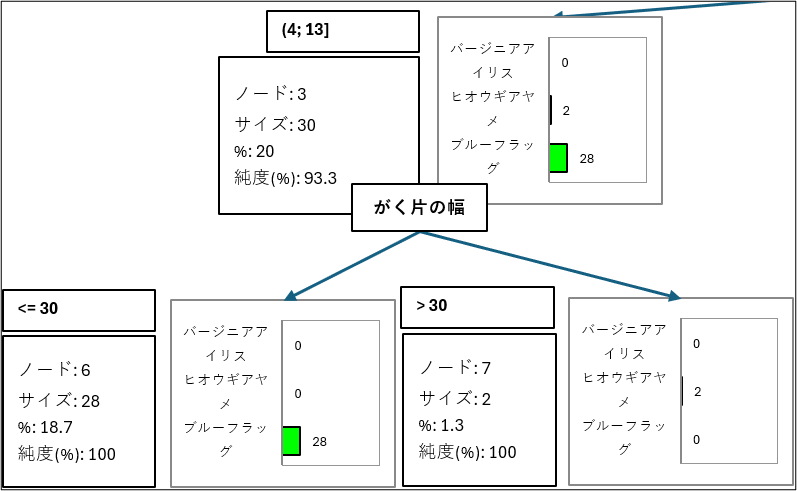
-
「花弁の幅が (4, 13]」というルールで、30個の花が ノード3 に分類されます。
-
この時点のノード3 の内訳は、ブルーフラッグ28個とヒオウギアヤメ2個が混在している状態です(純度(%)は93.3%です)。
-
純度が100%ではないため、モデルは「この30個をさらにうまく分類できないか?」と試み、「がく片の幅」という新しい分割変数を使って、ノード3 をさらに2つ(ノード6、ノード7)に分割します。
-
ノード6(分割の値: <= 30)にブルーフラッグ28個に分離されました(純度100%)。
-
ノード7(分割の値: > 30)にヒオウギアヤメ2個が分離されました(純度100%)。
純度が100%になった場合や、ダイアログ画面で設定した制限(例:木の深さ3)に達すると、アルゴリズムが停止し、ノードがそれ以上分岐しなくなります。
【補足】ノードのグラフを円グラフに変更する
分析実行時のダイアログボックスで「チャート」タブを開き、「円グラフ」オプションを選択することで、樹形図の各ノードのグラフを棒グラフから円グラフに変更することもできます。
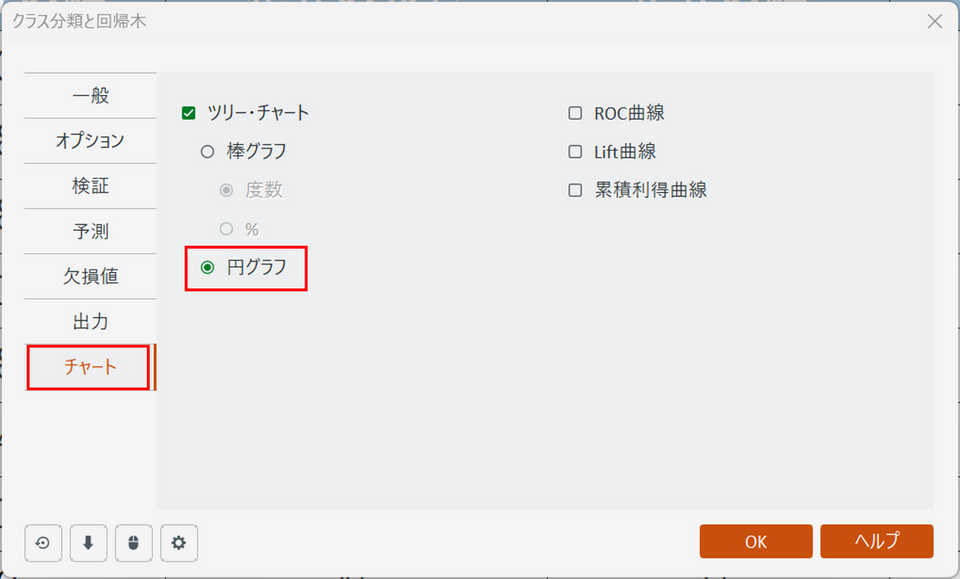
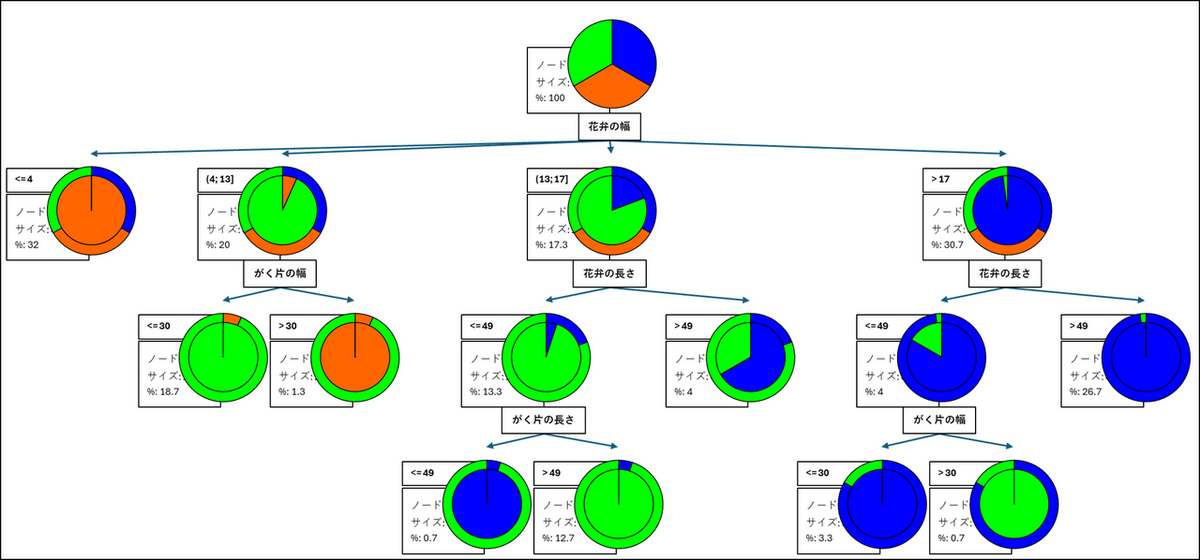
円グラフで表示すると、各ノードにおけるカテゴリの構成比率をより直感的に把握しやすくなります。特にカテゴリ数が多い場合に有効な場合があります。
まとめ
決定木分析(分類木)は、データを木のように分岐させながら、予測に至るまでの「ルール」を自動的に見つけ出す分析手法です。結果が視覚的にわかりやすく、「なぜその予測になるのか」という判断基準が明確になる点が大きな強みです。今回のアヤメのデータ分析では、「花弁の幅」が品種を分類する上で非常に重要な変数であることがわかりました。構築されたモデルは98.67%という高い精度で、特に「ヒオウギアヤメ」は花弁の幅だけで100%正確に分類できることが視覚的に示されました。
このような分析は、ビジネスの場面で幅広く活用できます。例えば、「どのような顧客が商品を購入しやすいか(ターゲットマーケティング)」、「どの顧客がサービスを解約するリスクが高いか(顧客維持)」、「どのような条件で不具合が発生しやすいか(品質管理)」といった課題の要因を特定し、具体的な戦略を立てるのに役立ちます。通常、こうした機械学習の手法は専門的なプログラミング知識が必要になることも少なくありません。しかし、XLSTAT を使えば、使い慣れた Excel 上でクリック操作をするだけで、誰でも手軽に分類木分析を実行することができます。データに隠された「ルール」を見つけ出し、次のアクションにつなげるために、ぜひ XLSTAT をご活用ください。
参考文献
- Fisher RA. (1936). The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2), 179-188. https://doi.org/10.1111/j.1469-1809.1936.tb02137.x
- XLSTAT: CHAID classification tree in Excel
https://community.lumivero.com/s/article/6565-chaid-classification-tree-excel-tutorial?language=en_US
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介した分類木はStandard と Advanced のライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。
