XLSTAT によるマクネマー検定:アンケートの2値データを用いた前後比較で研修の効果を検証しよう
- マクネマー検定とは?
- カイ二乗検定との違い
- マクネマー検定の仕組み(計算過程)
- マクネマー検定を実行するためのデータセット
- XLSTAT によるマクネマー検定の実行手順
- マクネマー検定の結果の解釈
- まとめ
- 参考文献
- XLSTAT の無料トライアル
マクネマー検定とは?
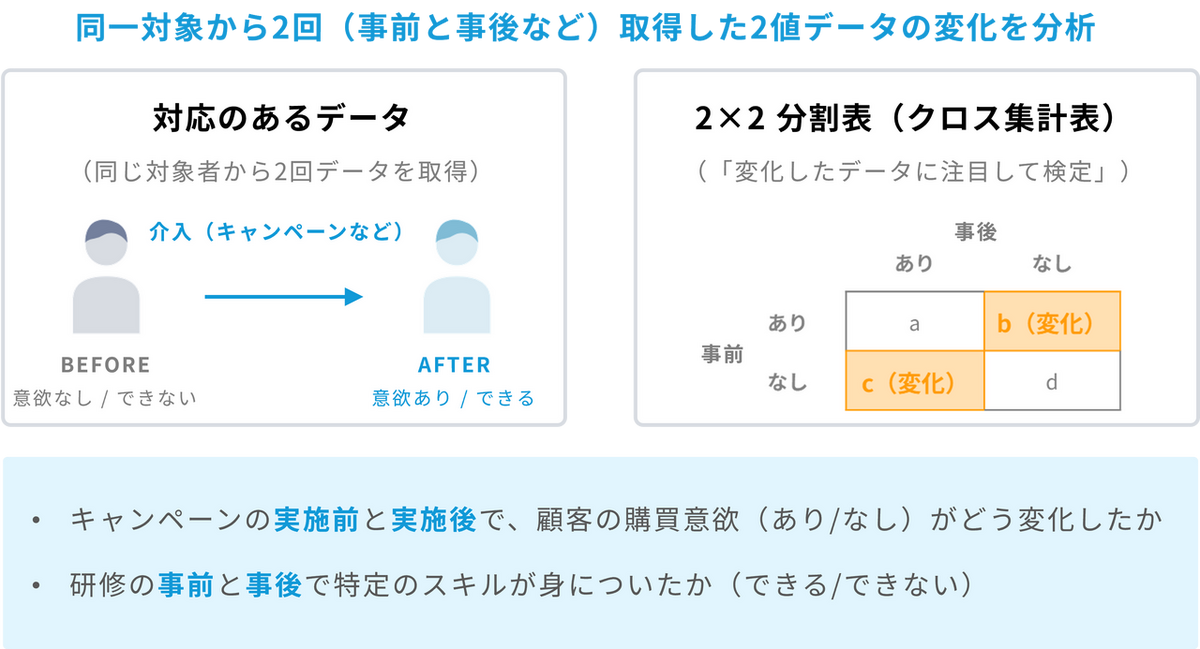
マクネマー検定は、「対応のあるデータ」に対する2×2分割表(クロス集計表)の検定手法です。 ここで言う「対応のあるデータ」とは、同じ対象者から2回(例:事前と事後)データを取得している状態を指します。例えば「キャンペーンの実施前と実施後で、顧客の購買意欲(あり/なし)がどう変化したのか」や「研修前と研修後で特定のスキルが身についたか(できる/できない)」といった、2値データの「変化」が統計的に有意であるかどうかを分析するのに最適な手法です。
カイ二乗検定との違い
分割表(クロス集計表)の検定手法としてよく知られるものに「カイ二乗検定(独立性の検定)」がありますが、使い分けのポイントは「データ対応の有無」です。

- カイ二乗検定:
「対応のない」データに使用します。独立した別々の集団間(例:「男性グループ」と「女性グループ」など)に偏りがないかを比較します。
- マクネマー検定:
「対応のある」データに使用します。同一の対象者から得られた「前」と「後」のデータを比較し、個人の変化に着目します。
マクネマー検定の仕組み(計算過程)
マクネマー検定の特徴は、前後で変化がなかった対象者は考慮せず、「変化があった対象者」のみに着目して計算する点です。具体的な事例で計算の仕組みを見てみましょう。
例)PR 動画の視聴前後での購買意欲の変化
ある企業が新サービスのユーザー登録者数を増やすため、サービスの魅力を伝える新しいPR 動画を作成しました。この動画を見てもらうことで、ターゲット層の「サービスを使いたい」という気持ちに変化があったのかを客観的に評価したいと考えています。そこで、PR 動画を見た100人を対象に、「サービスを使いたいか」を前後でアンケートしました。
上記アンケートの結果、100人の回答を「2×2のクロス集計表」に整理したものが以下の表です。
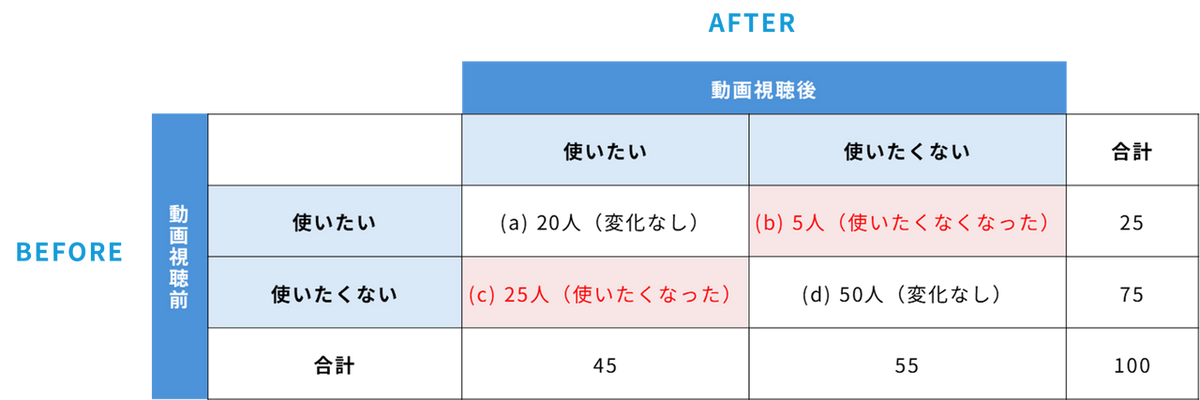
4つのセルを整理すると、以下のように解釈できます。
- (a) 使いたい → 使いたい(変化なし):20人
- (b) 使いたい → 使いたくない(使いたくなくなった):5人
- (c) 使いたくない → 使いたい(使いたくなった):25人
- (d) 使いたくない → 使いたくない(変化なし):50人
ステップ1. 帰無仮説と対立仮説を設定する
マクネマー検定では、クロス集計表で状態が変化したペア(b と c)に注目して以下のように仮説を設定します。
- 帰無仮説:
動画視聴の前後で、意欲の変化に偏りはない(bとc の割合に差はない=動画の効果はない)。 - 対立仮説:
動画視聴の前後で、意欲の変化に偏りがある(bとc の割合に差がある=動画の効果がある)。
ステップ2. 検定の対象となる「状態が変化したペア」を抽出する
独立性のカイ二乗検定ではすべてのセルの「期待度数」を計算しますが、マクネマー検定が着目するのは「状態が変化した人(b と c)」だけです。変化しなかった人(a と d)は計算から除外します。もしPR 動画に全く効果がなかった(帰無仮説が正しい)としたら、「使いたくなった人(b)」と「使いたくなくなった人(c)」の数は、理論上同じ(半々)になるはずです。
- 変化した人の合計:5人(b) + 25人(c) = 30人
- 差がない場合の理論値(期待値):15人ずつ
実際のデータ(25人と5人)が、この理論上の状態からどれくらいズレているかを計算していきます。
ステップ3. カイ二乗値を計算する
抽出した「状態が変化したペア」の実測値をもとに、カイ二乗値(検定統計量)を計算します。サンプルサイズが小さい場合にも対応できるよう、「イェーツの連続性補正」を含んだ以下の公式を使用するのが一般的です。
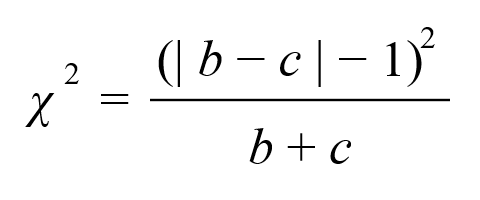
上記公式に値を代入してカイ二乗値を求めます。
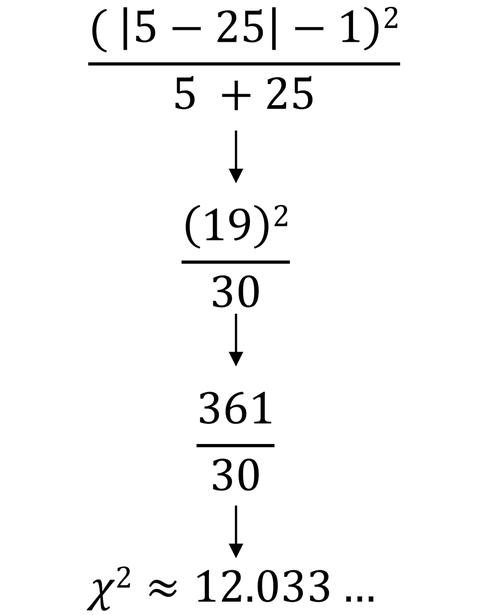
結果として、今回のデータから得られたカイ二乗値は約「12.03」となります。
ステップ4. カイ二乗分布とカイ二乗値を比較して判定する
カイ二乗分布表で有意水準が5%のときのカイ二乗値を確認し、計算で得られたカイ二乗値と比較します。もし計算したカイ二乗値の方が大きければ、「帰無仮説を棄却し、前後の変化に偏り(有意差)がある」と判断します。マクネマー検定の対象となる2×2のクロス集計表における自由度は、常に「1」になります。なお、3カテゴリ以上の場合は別の検定(例:Bowker検定)を用います。
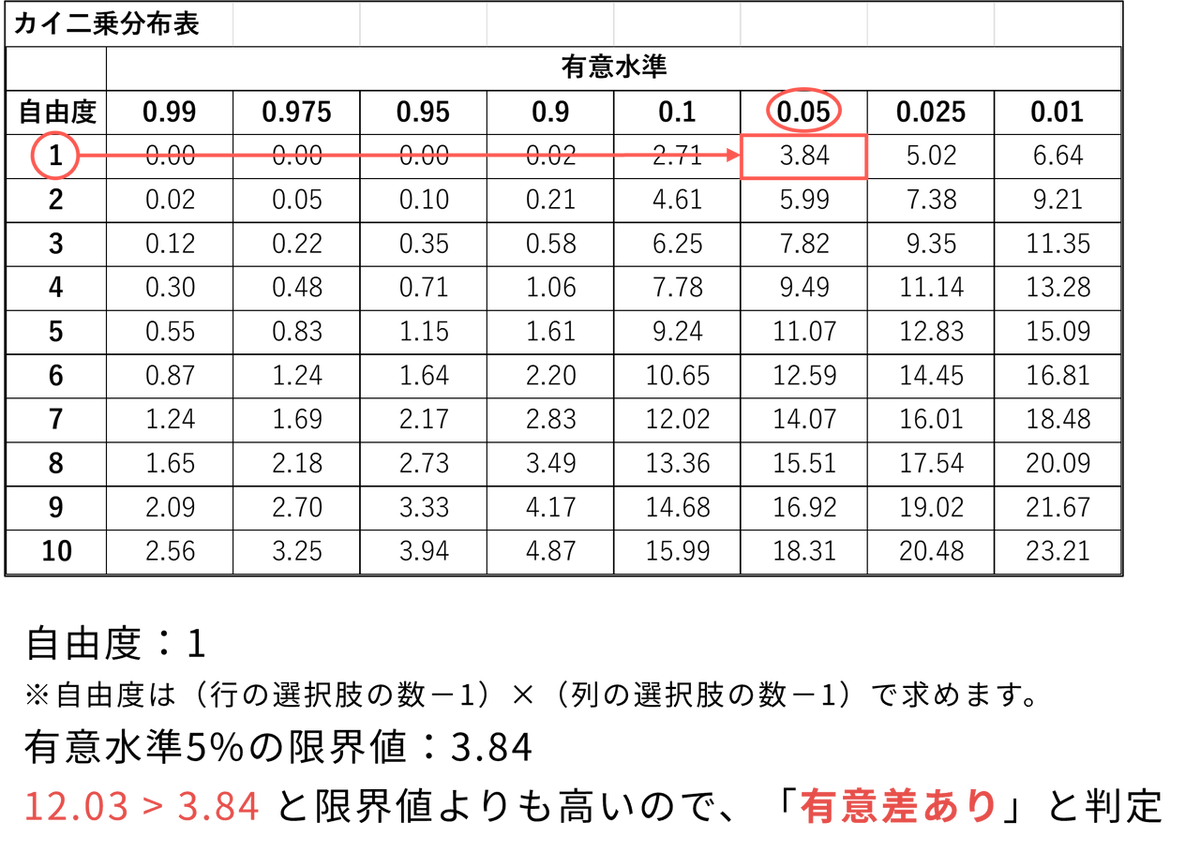
今回の場合、分布表で自由度「1」、有意水準「0.05(5%)」の項目を確認すると、基準となる値(臨界値)は「3.84」となっています。それに対して今回のデータで得られたカイ二乗値は「12.03」であり、分布表の基準値よりも大きくなっています。したがって、「偶然このような偏りが生じる確率は5%未満である」と判断でき、PR 動画の視聴前後でユーザーの意欲には有意な変化があった(効果があった)と結論づけることができます。
マクネマー検定を実行するためのデータセット
マクネマー検定の計算イメージがつかめたところで、次はXLSTAT を使って、別分野のデータを分析してみましょう。
事例:看護学生を対象にした研修の効果検証
今回は、看護学生100名を対象とした「急変時対応のシミュレーション研修」のアンケート結果(ローデータ)を使用し、「患者の異変に気づき、ためらわずに医師へ報告できるか」という項目の達成度を研修前後で比較・分析します。

事前準備:2値データへの変換
4段階のデータのままではマクネマー検定を実行できないため、事前に「できる群(3〜4点)= 1」と「できない群(1〜2点)= 0」という2値データに変換しておきます。
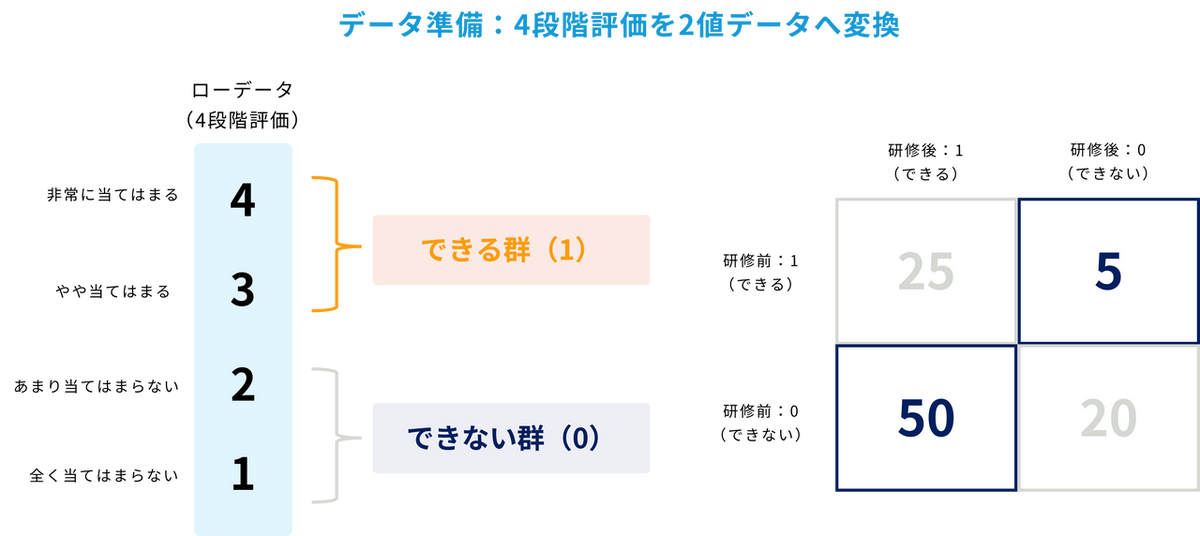
この100名分のデータをクロス集計したところ、以下のようになりました。

- 研修前も後も「できる(1,1)」:25名
- 研修前も後も「できない(0,0)」:20名
- 研修前「できる」→ 研修後「できない(1,0)」:5名
- 研修前「できない」→ 研修後「できる(0,1)」:50名
マクネマー検定では、この変化があった「5名」と「50名」の偏りに着目して計算を行います。
サンプルデータのダウンロードはこちらから
dataset-for-mcnemars-test.xlsmなお、XLSTAT ではクロス集計表とリスト形式どちらの形式でもマクネマー検定を実行することが可能です。
XLSTAT によるマクネマー検定の実行手順
-
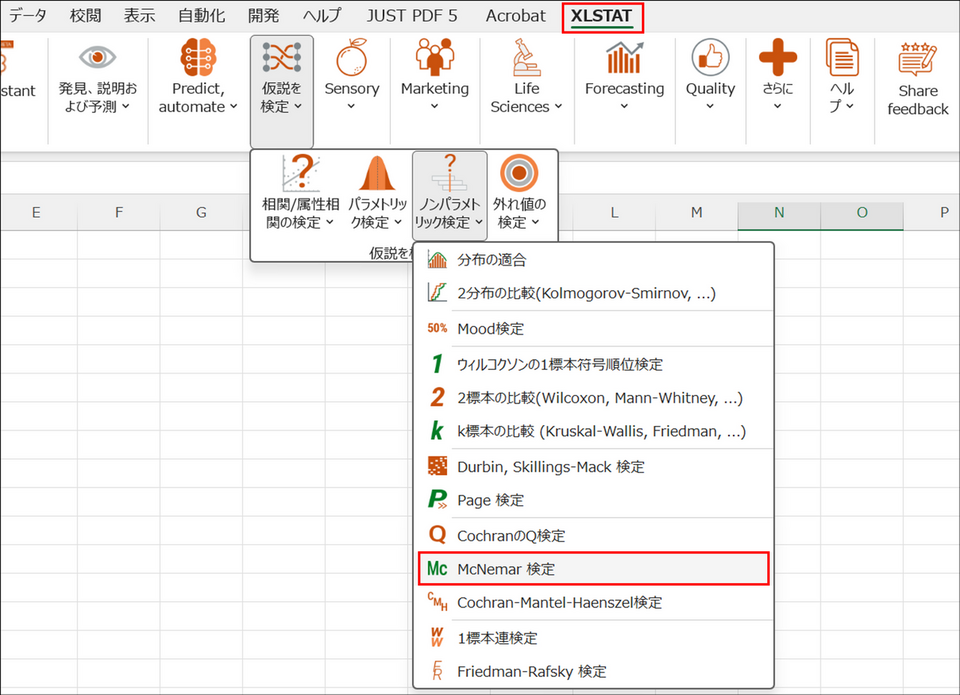
XLSTAT を起動し、[仮説を検定] > [ノンパラメトリック検定] > [McNemar 検定] を選択します。
-
ダイアログボックスが表示されたら「一般」タブで以下の設定をします。
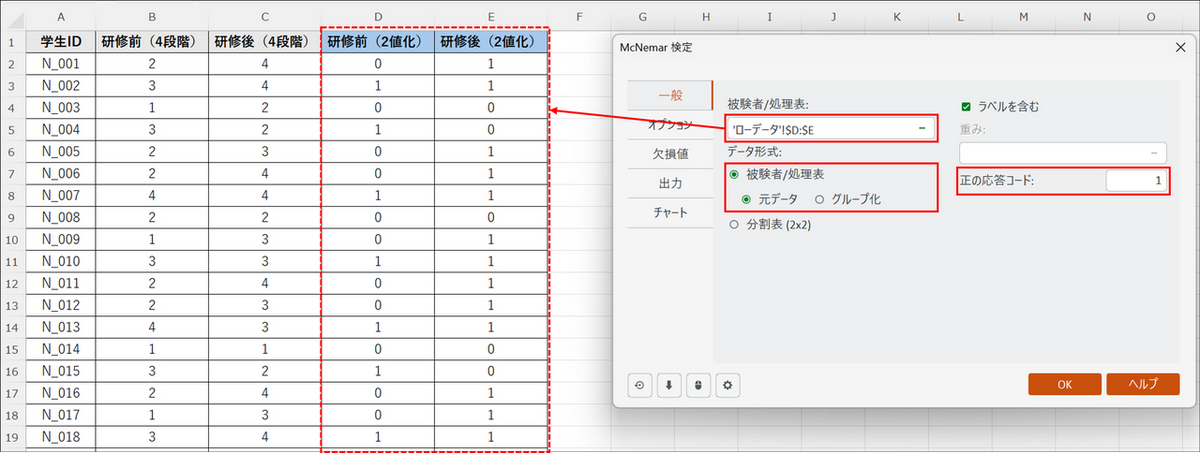
- データ形式:[被験者/処理表] と [元データ] を選択
- 被験者/処理表:2値データに変換した列を選択
- 正の応答データ:今回は「0/1」データのため、「1」と入力
- ラベルを含む:見出しを含めてデータを選択している場合はチェックを入れる。
【補足】クロス集計表で実行する場合
クロス集計表の場合は、以下のようにデータを選択します。
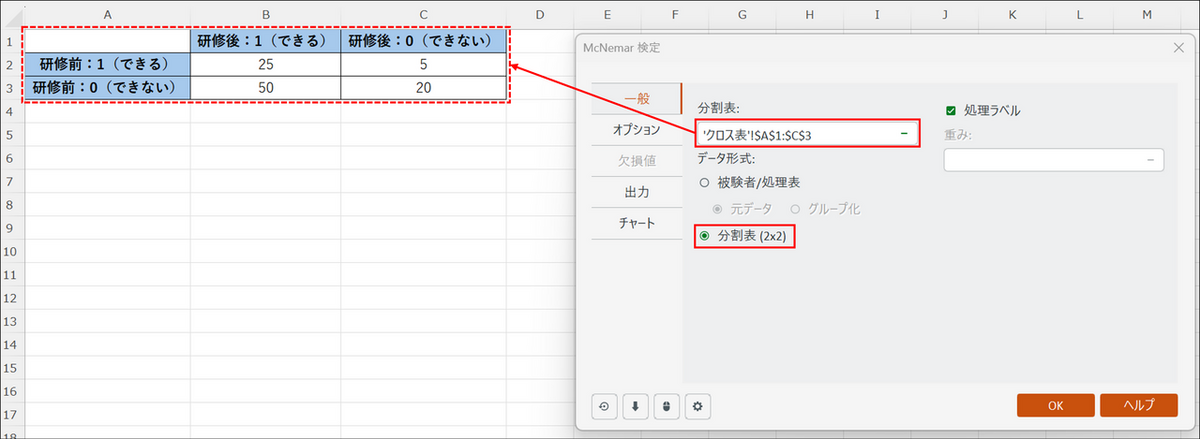
-
[オプション] タブに切り替え、以下のように設定します。
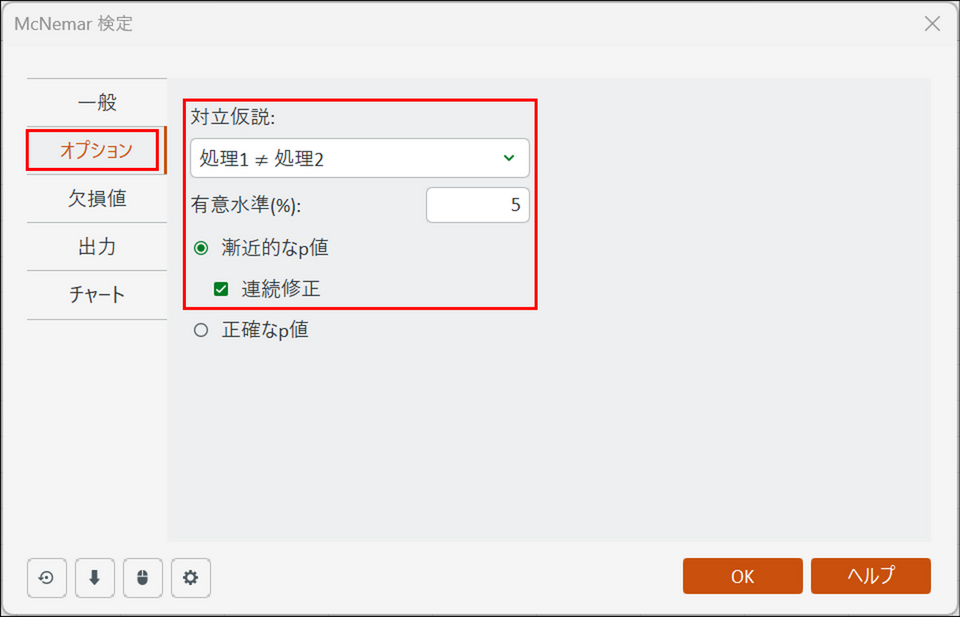
-
[OK] をクリックすると計算が始まり、結果が別シート(McNemar 検定)に出力されます。
マクネマー検定の結果の解釈
記述統計
最初に出力される記述統計で対象となるデータの全体的な分布(構成比)を確認します。出力された表とグラフ(積み上げ棒グラフ)からは、研修の前後で「できる(1)」と「できない(0)」の割合がそれぞれどのように変化したのかを視覚的に把握できます。
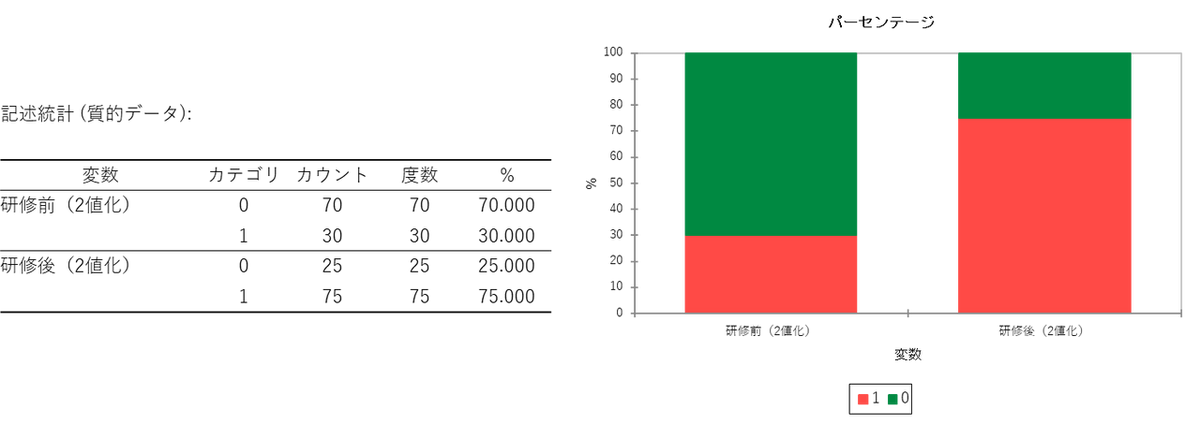
パーセンテージのグラフを見ると、研修後に「1(できる)」の赤い層が大きく拡大していることが一目でわかります。この段階で、全体として学生のスキルが向上している傾向があるという感触を得ることができます。ただし、この記述統計だけでは、この変化が「統計的に意味のある(有意な)変化」なのか、それとも「偶然の範囲内」なのかは証明できません。それを明らかにするために、続く「分割表」と「McNemar 検定」の結果を確認していくことになります。
分割表
記述統計で確認した全体的な割合の変化について、「どのように変化したのか」という詳しい内訳を示すのがこの「分割表(クロス集計表)」です。表の行(横方向)が「研修前」の状態、列(縦方向)が「研修後」の状態を表しています。

この表からは、学生一人ひとりの変化のパターンを以下4つに分類して確認できます。
変化しなかった層(一致ペア)
研修前も後も「できる(1)」のままだった学生:25名
研修前も後も「できない(0)」のままだった学生:20名
※これらは現状維持の層であり、マクネマー検定の計算には使われません。
変化があった層(不一致ペア)
-
研修前は「できる(1)」だったが、研修後に「できない(0)」に下がってしまった学生:5名
-
研修前は「できない(0)」だったが、研修後に「できる(1)」に改善した学生:50名
McNemar 検定 (漸近的なp値) / 両側検定:
分割表で確認した「低下した学生(5名)」と「向上した学生(50名)」という人数の偏りが、本当に統計的な意味を持っているのか(単なる偶然ではないか)を数学的に判定したのが、この「McNemar 検定」の表です。

分析結果の p値(両側)は「 < 0.0001」となっており、設定した有意水準の0.05 を大きく下回っています。これは「今回の変化が偶然起きる確率は0.01%未満である」ということを意味します。したがってこの結果から急変時対応のシミュレーション研修の実施前後で、「患者の異変に気づき、ためらわずに医師へ報告できる」という学生の自己評価には、統計的に有意な改善が見られたと解釈できます。
まとめ
マクネマー検定は、今回のようなシミュレーション研修の効果測定など、同一対象者の「前後比較」を行いたい場合に有効な統計手法です。カイ二乗検定との違いである「データの対応の有無」を正しく理解し 、変化があった層の偏りを調べることで、研修や施策の真の効果を客観的に証明できます。XLSTAT を活用すれば、データの変換から高度な分析まで、普段使い慣れたExcel 上でシームレスに実行でき、結果のレポートも即座に得られます。専門的な数式に悩むことなく、迅速かつ正確な効果測定が可能になりますので、ぜひ今後の研究や実務でのデータ分析に活用してみてください。
参考文献
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したマクネマー検定はすべてのライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。

