XLSTAT による多重コレスポンデンス分析:アンケートデータの隠れた構造を可視化する
- 多重コレスポンデンス分析とは?
- ビジネスでの利用シーン
- コレスポンデンス分析との違い
- 多重コレスポンデンス分析を実行するためのデータセット
- XLSTAT で多重コレスポンデンス分析を実行する手順
- 多重コレスポンデンス分析の結果の解釈
- まとめ
- 参考文献
- XLSTAT の無料トライアル
多重コレスポンデンス分析とは?
多重コレスポンデンス分析(Multiple Correspondence Analysis, MCA)は、「3つ以上の質的変数(カテゴリーデータ)」間の複雑な関連性を探るための統計手法です。例えば、アンケート調査で得られた「性別」「年齢層」「満足度」「購入した商品」「重視する点」といった複数の回答項目全体の傾向を分析し、それらの関係性を「マップ」として可視化します。この手法により、「どのような回答パターンの人が多いのか」「特定の回答(例:満足)は、他のどの回答(例:30代、価格重視)と結びつきが強いのか」が一目でわかるようになります。
ビジネスでの利用シーン
多重コレスポンデンス分析は、特にマーケティングリサーチの分野で強力なツールとなります。
- 顧客セグメンテーション:
アンケート回答者を、回答パターンの類似性に基づいてグループ分け(セグメンテーション)します。(例:「価格重視・機能性も求める層」「ブランドイメージ・デザイン重視層」など) - ブランドポジショニング:
複数の競合ブランドについて「ブランド A=安価・手軽」「ブランド B=高品質・高価格」「ブランド C=流行・若者向け」といった、消費者の認識(イメージ)をマップ上で可視化します。 - 製品開発:
「どのような機能」を「どのターゲット層(属性)」が求めているのか、その結びつきを分析し、新製品のコンセプト立案に役立てます。
コレスポンデンス分析との違い
多重コレスポンデンス分析と名前が似ている分析に「コレスポンデンス分析」がありますが、両者は分析対象となる「変数の数」が決定的に異なります。コレスポンデンス分析(CA)は「2つ」の質的変数間の関連性を見るのに対し、多重コレスポンデンス分析は「3つ以上」の質的変数間の関連性を見る手法です。以下に、それぞれの特徴と違いをまとめます。
| 比較項目 | コレスポンデンス分析 | 多重コレスポンデンス分析 |
| 変数の数 | 2つ | 3つ以上 |
| 主な目的 | 2変数間の関連性の可視化 | 多変数間の全体的な構造の可視化、回答者のグループ分け |
| 主な入力データ | クロス集計表 | 観測値/変数テーブル(生の回答データ) |
| 分析例 | 「好きなブランド」(A, B, C)と「年齢層」(10代, 20代, 30代)の関係性。 | 「性別」「年齢層」「好きなブランド」「購入頻度」「重視する点」の5つの質問項目全体の関連性。 |
| わかること | 「A ブランドは20代に好まれ、B ブランドは30代に好まれる」といった、2つの変数のカテゴリー間の「近さ(関連性の強さ)」がマップ上でわかります。 | 「"A ブランドを好む人" は、"30代"で、"価格を重視"し、"購入頻度が高い"」といった、複数のカテゴリー間の関連性。似たような回答パターンを持つ「回答者のグループ」がマップ上のどのあたりに固まっているか。 |
コレスポンデンス分析のデータ事例
コレスポンデンス分析は2変数間の関係を分析するため、通常はクロス集計表を入力します。
例:「年齢層」と「休日の主な過ごし方」の関係

※生データ(個体/変数)の場合でも、XLSTAT ではデータ形式を[オブザーベーション/変数]として指定すれば、内部でクロス集計を自動生成し、そのまま分析が可能です。
多重コレスポンデンス分析のデータ事例
多重コレスポンデンス分析は、3つ以上のカテゴリ変数を同時に扱うため、クロス集計表の形にまとめられません。そのため、個体 x 変数の生データ(観測値/変数テーブル)を入力データとして用います。
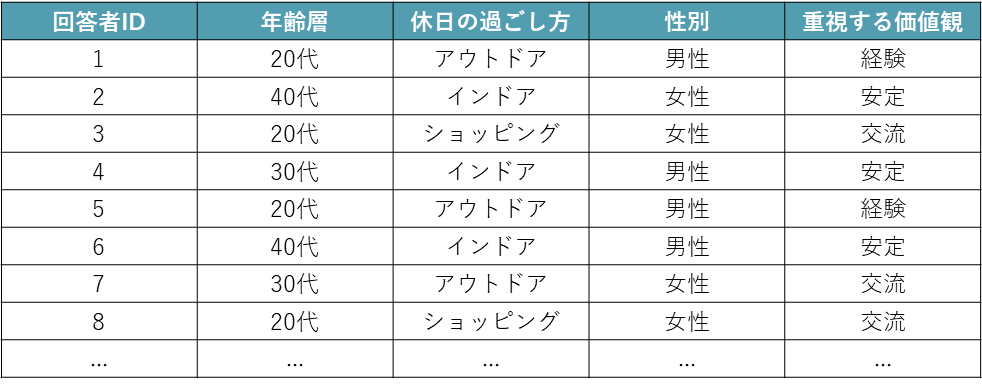
例:「アンケート回答者」ごとのライフスタイル調査
上記コレスポンデンス分析の例に、「性別」と「重視する価値観」を追加したイメージです。
多重コレスポンデンス分析を実行するためのデータセット
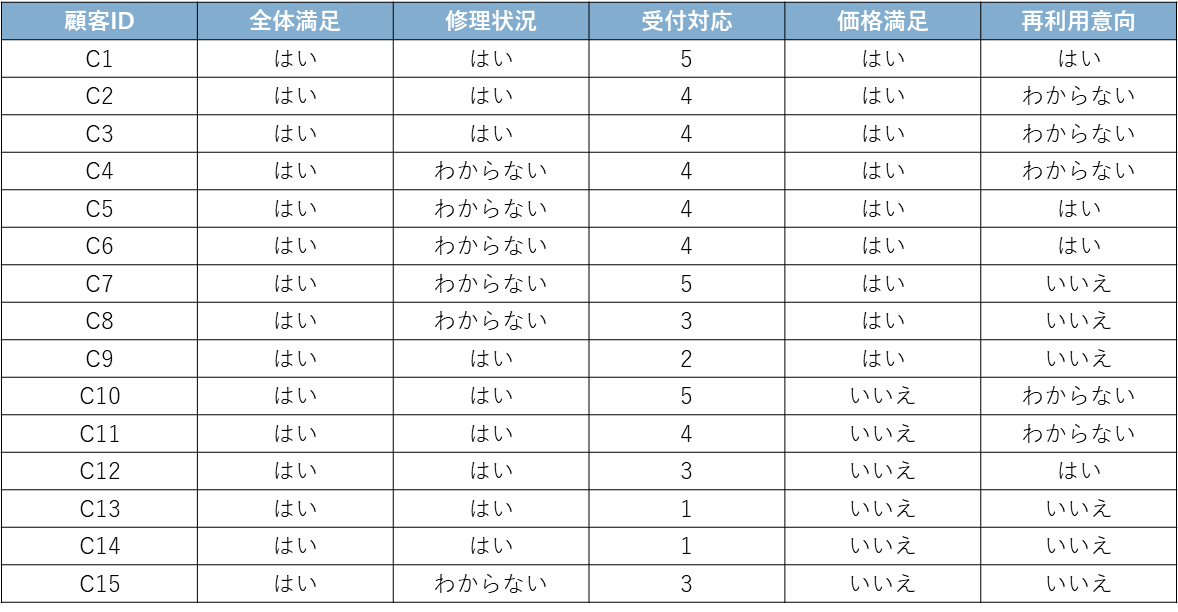
今回は、ある自動車ディーラーが顧客28名に対して行った架空のアンケートデータを使用します。顧客は、車の修理を終えてから1週間後に、以下の5つの質問に回答しました。
質問項目:
- 全体満足:サービス全体に満足していますか? (はい/いいえ)
- 修理状況:問題は解決したと思いますか?(はい/いいえ/わからない)
- 受付対応:受付の対応はいかがでしたか?(1〜5の5段階評価)
- 価格満足:品質と価格のバランスは満足ですか?(はい/いいえ)
- 再利用意向:次回も当社のサービスを利用しますか?(はい/いいえ/わからない)
これらのアンケート回答の様々なパターンの関係性を特定し、「どのようなサービス体験」が「次回の利用意向」に結びついているのかを明らかにします。
サンプルデータのダウンロードはこちらから
dataset-for-MCA.xlsm【補足】「満足度(5段階)」が多重コレスポンデンス分析でOK な理由
「満足度(5段階)」は数値データのように見えますが、多重コレスポンデンス分析の対象として含めて問題ありません。その理由は、この尺度が厳密には「順序尺度」と呼ばれ、分析上はカテゴリーデータの一種として扱えるためです。
- 数値の「差」が等しくない:
例えば「満足」と「非常に満足」の心理的な距離は、「不満」と「非常に不満」の距離と同じとは限りません。 - 数値は「ラベル」である:
ここでの数字は、「5は1の5倍満足」という数量を表すものではなく、「非常に満足」というグループに属することを示すラベルの役割を果たしています。
したがって、カテゴリーデータを対象とする多重コレスポンデンス分析に含めることができます。
XLSTAT で多重コレスポンデンス分析を実行する手順
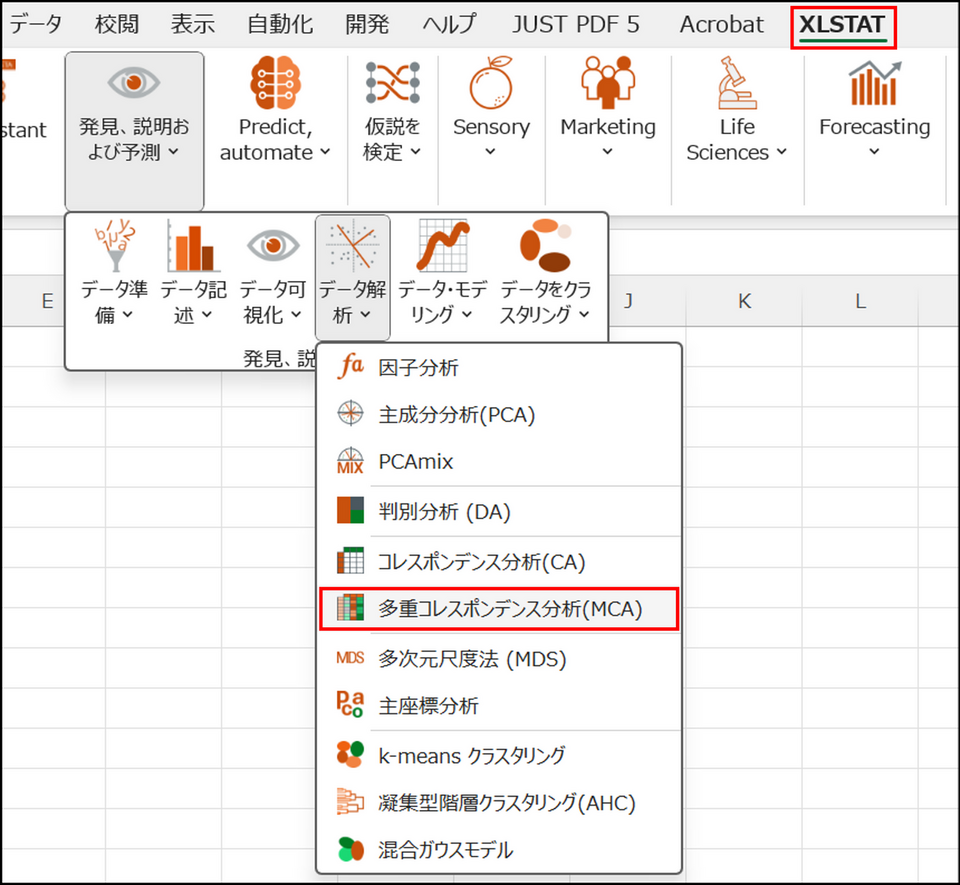
-
XLSTAT を起動し、[発見、説明、および予測] > [データ解析] > [多重コレスポンデンス分析] を選択します。
-
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
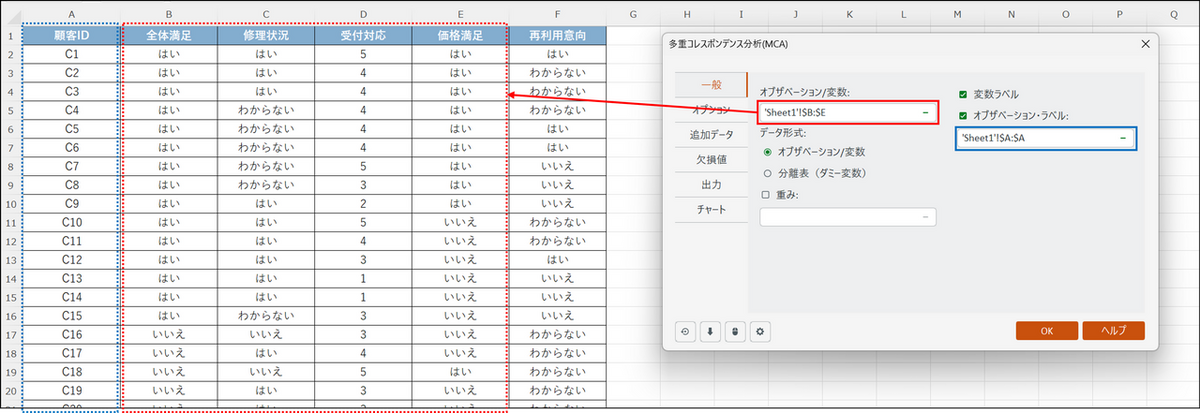
- データ形式:「オブザベーション/変数」を選択します。
- オブザベーション/変数:
分析に使用するデータ列(「全体満足」「修理状況」「受付対応」「価格満足」の列)を選択します(ポイント:ここでは「再利用意向」の列は含めません)。 - 変数ラベル:チェックを入れます。
- オブザベーションラベル:「顧客ID」の列を選択します。
-
[追加データ] タブに切り替え、[追加変数] と[質的変数] の項目にチェックを入れ、「再利用意向」の列を選択します。
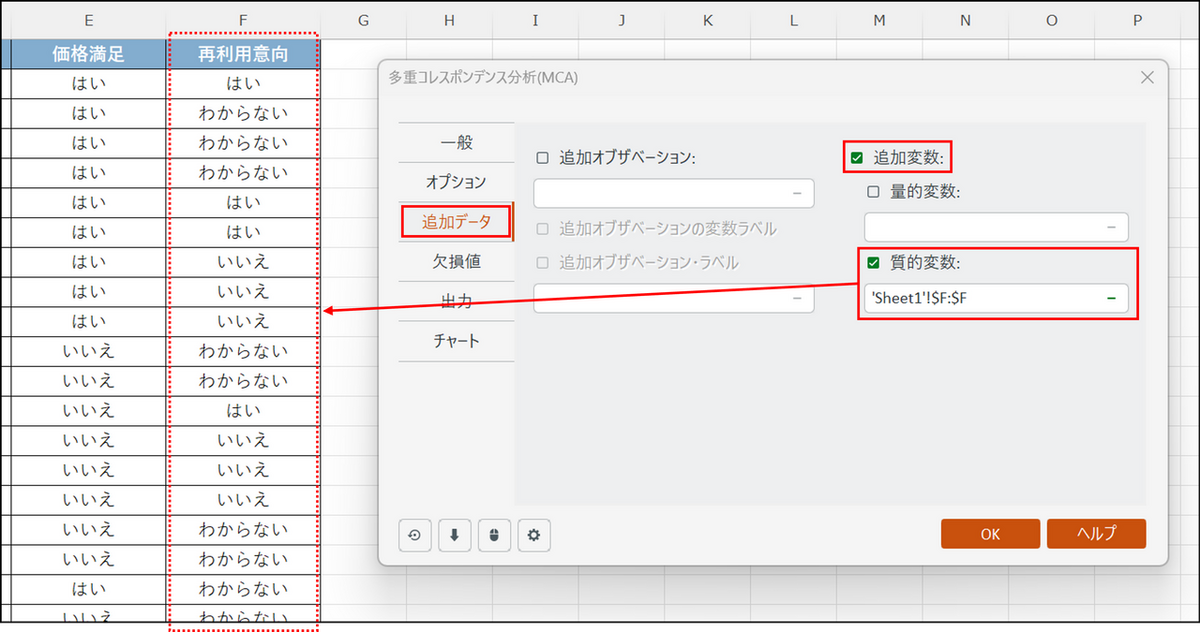
【補足】なぜ「再利用意向」の列を「補足データ」にするのか?
これは、分析の「土台(軸)」を「サービス体験(満足度、受付、価格など)」だけで作り、そのマップ上に「結果(再利用するかどうか)」がどこに位置するかを後から確認するためです。これにより、「どのような体験をした人が、再利用(はい)と答えているか」という原因と結果の関係性が非常に明確になります。
-
[出力] タブに切り替え、「分割表(ダミー変数)」と「バート表」の項目にチェックを入れます。
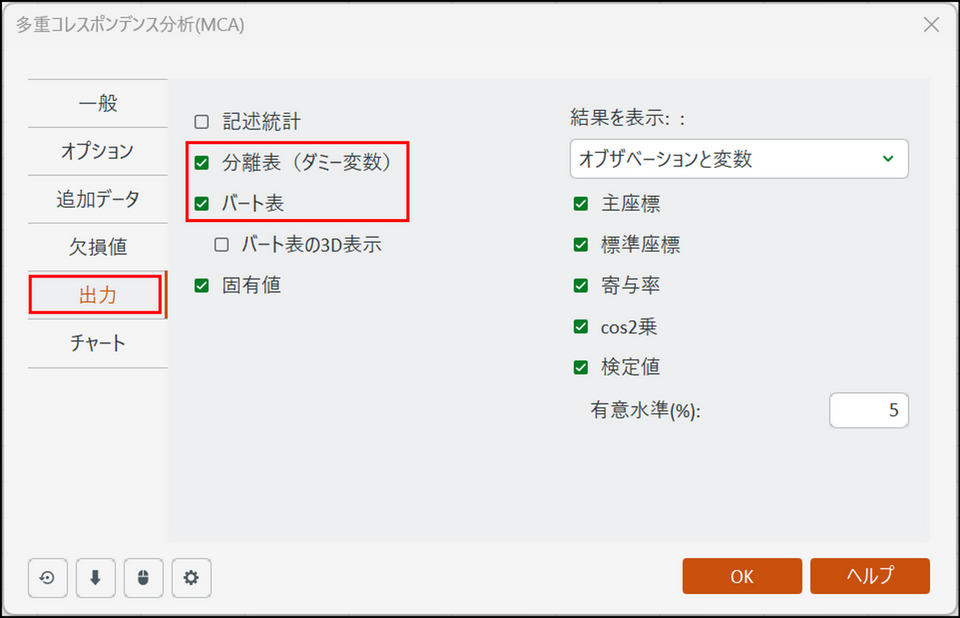
-
[OK] ボタンをクリックすると、計算が始まり、結果が別シート(MCA)に出力されます。
多重コレスポンデンス分析の結果の解釈
分析を実行すると、多くの表やグラフが出力されますが、このページでは主要な出力結果を順に解説します。
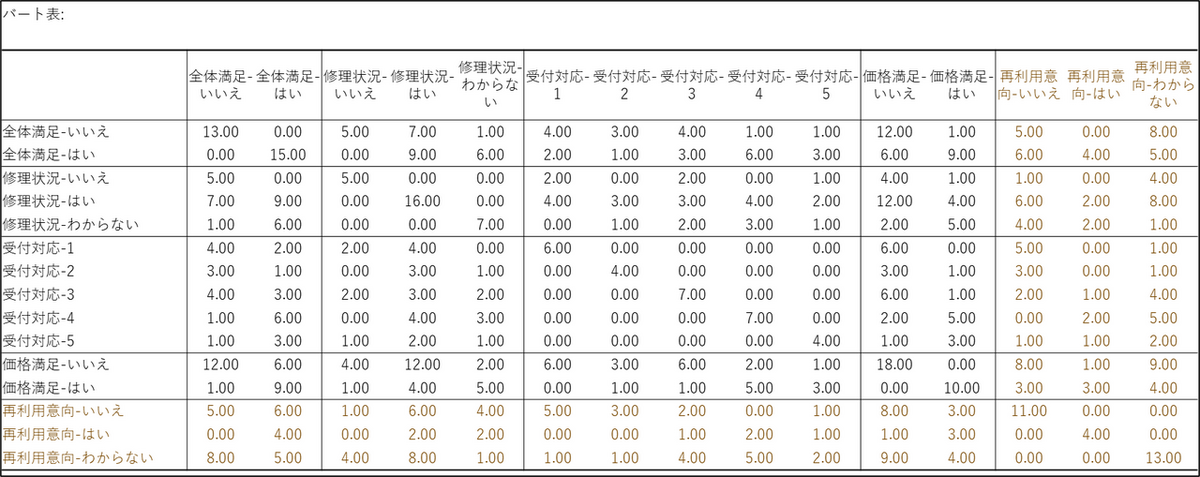
1. 中間計算の表(分離表・バート表)
分析マップの解釈の前に、計算の基礎となる表が出力されます。
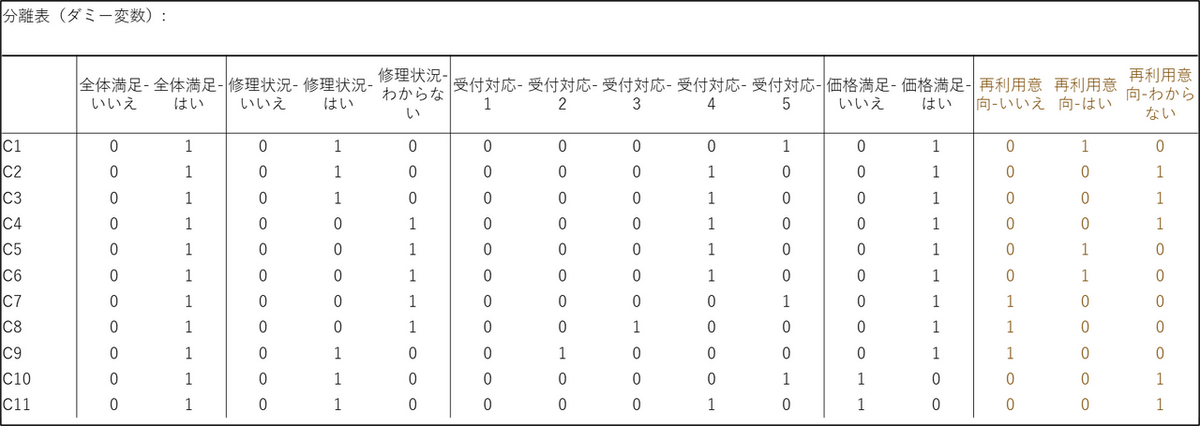
分離表(ダミー表):
元のアンケートデータ(「はい」「いいえ」「1」「5」など)を、多重コレスポンデンス分析で計算できる形式に変換した「0」と「1」の表です。各回答者がどのカテゴリーを選んだか(1)、選んでいないか(0)を示します。
バート表:
分析に使う複数のカテゴリ変数どうしの関係を、一つの大きな表としてまとめたものです。3つ以上のカテゴリ変数を同時に扱う場合、1枚のクロス集計表として整理することはできませんが、それぞれの変数どうしのクロス集計表を並べて(結合して)いくことでバート表が構成されます。例えば、「『全体満足-いいえ』と回答した人」のうち「『修理状況-いいえ』と回答した人」が何人いるか、といった同時出現回数が一覧になっています。
2. 固有値とスクリープロット
これらは、分析によって抽出された「軸」の重要度を示しています。
固有値:
各軸(F1, F2...)がデータ全体のばらつき(イナーシャ)をどれだけ説明しているかを示します。「合計イナーシャ」は、分析におけるデータの「ばらつき」や「情報量」の総量(合計値)を示す数値です。後続の「固有値」の表にある全ての固有値を合計すると、ちょうど「合計イナーシャ」で示される値(「2」)になります。
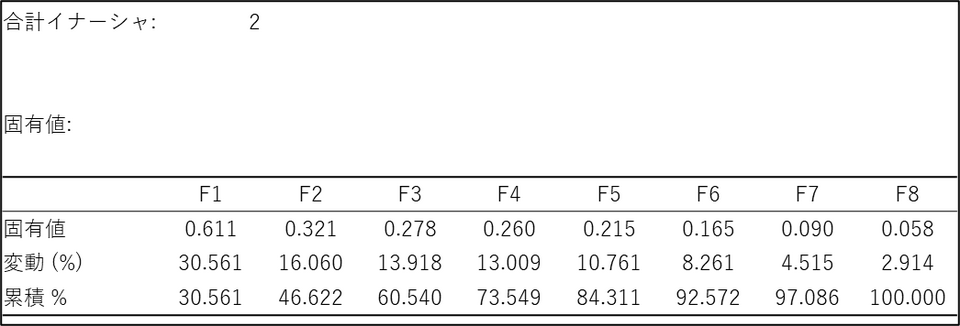
- F1, F2, F3...(列):
これは分析によって見つかった「軸」または「因子」です。
F1:第1軸。データ全体を説明する力が最も強い軸です。
F2:第2軸。F1 の次に説明力が強い軸です。
F3 以降:3番目、4番目...に説明力が強い軸です。
- 固有値:
各軸(F1, F2...)が持つ「情報量」や「重要度」を数値で表したものです。この数値が大きいほど、その軸がデータを説明するために重要であることを意味します。今回の結果ではF1 の「0.611」が最も大きく、F2「0.321」、F3「0.278」と、だんだん小さくなっていきます。
- 変動 (%) :
一般的に「寄与率」と呼ばれる、最も重要な指標の一つです。データ全体の情報量(イナーシャ)のうち、各軸が何パーセントを説明できているかを示します。今回のデータでは、F1 軸だけでデータ全体の約30.6%(= 0.611÷2)の傾向を説明できていると解釈できます。
- 累積 % :
「変動 (%)」を、F1 から順に足し上げていった合計値です。F2 の行の「46.622%」は、F1 軸とF2 軸でデータ全体の約47%の情報を説明できていることを意味します。
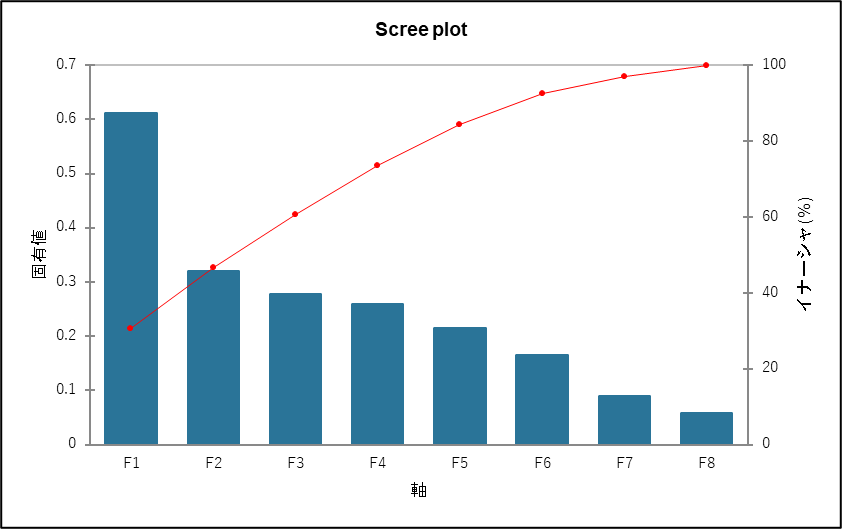
スクリープロット:
上記の固有値の表をグラフ化したものです。青い棒グラフは、各軸(F1, F2…)の固有値を示しており、F1 が最も高く、F2, F3 と進むにつれて減少しているのがわかります。赤い折れ線グラフは、累積寄与率を示しており、各軸までを合計した「情報量の割合」を示します。固有値の表で確認した通り、F2 軸上で累積寄与率は、約47%の位置にあることが確認できます。
3. 座標と寄与率の表
これらは、マップ(グラフ)上の「位置」と「意味」を定義する数値です。
主座標(変数):
これは、多重コレスポンデンス分析のマップを作成するための「座標」を示した表です。F1 をX軸、F2 をY軸、F3 をZ軸...と考えたときに、各アンケート回答(カテゴリー)がマップ上のどの位置にプロットされるかを示しています。
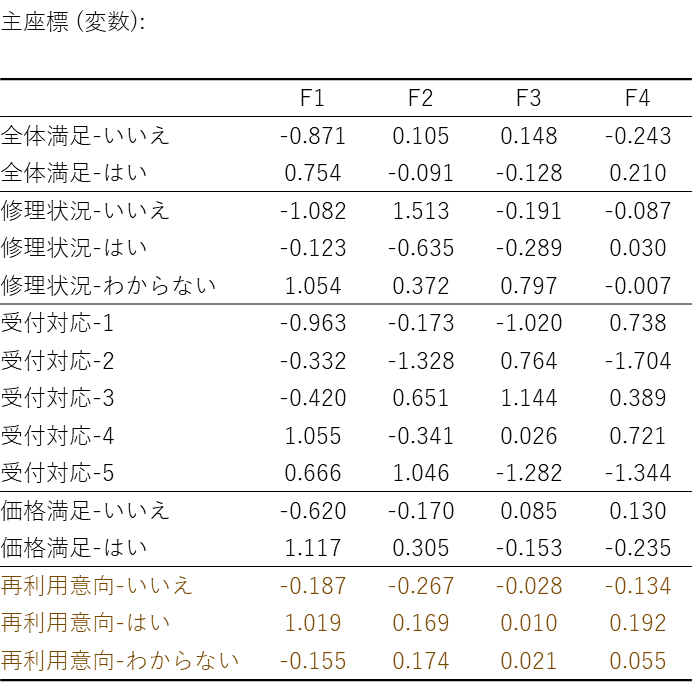
例えば、1行目の「全体満足-いいえ」は、マップ上で(F1 = -0.871, F2 = 0.105)の位置にプロットされます。それに対して、2行目の「全体満足-はい」は、(F1 = 0.754, F2 = -0.091)の位置にプロットされます。このことから両者はF1 軸(横軸)上で正反対の遠い位置にあり、対立的な回答であることを示しています。また、「全体満足-はい」(F1 =0.754)と「価格満足-はい」(F1 =1.117)は、F1 の値が両方ともプラスで近いため、マップ上で近くにプロットされ、関連が強いと解釈できます。
寄与率(変数):
この表は、「各軸(F1, F2など)が『何を意味する軸なのか』を定義するのに、どのカテゴリーがどれだけ強く『貢献』したか」をパーセンテージ(%)で示しています。各列(F1, F2...)のパーセンテージを合計すると100%になります。
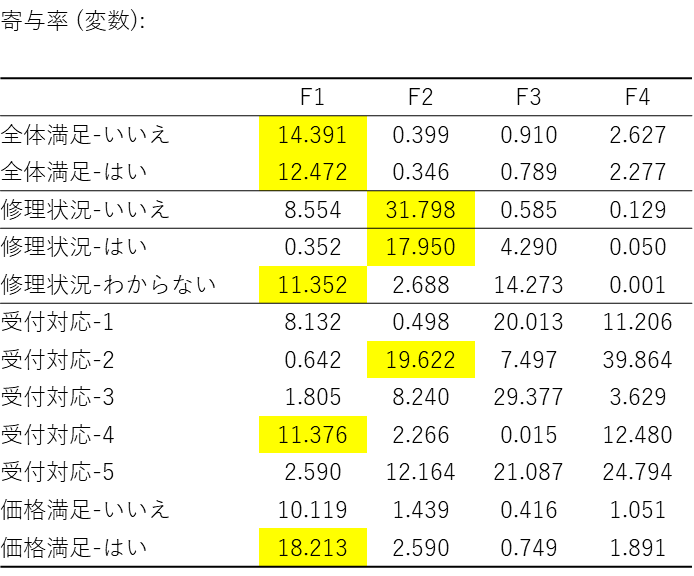
F1(横軸)の解釈:
F1 の列を縦に見ると、以下の数値が特に大きくなっています。
- 価格満足-はい: 18.213%
- 全体満足-いいえ:14.391%
- 全体満足-はい: 12.472%
- 受付対応-4:11.376%
- 修理状況-わからない:11.352%
これらのカテゴリーが、F1(横軸)の「位置決め」に最も強く貢献しています。 前の「主座標」の表と合わせると、F1 のプラス側には「価格満足-はい」や「全体満足-はい」が、マイナス側には「全体満足-いいえ」が来ていました。 つまり、F1 軸は「サービスや価格に対する総合的な満足度」を表す軸であると解釈できます。
F2(縦軸)の解釈:
F2 の列を縦に見ると、以下の数値が突出しています。
- 修理状況-いいえ:31.798%
- 受付対応-2:19.622%
- 修理状況-はい:17.950%
これらの寄与率が非常に高いことから、F2(縦軸)は主に「問題が解決されたかどうか」と「受付の対応(特に受付対応-2=悪い)」という要因によって定義されている軸だと解釈できます。
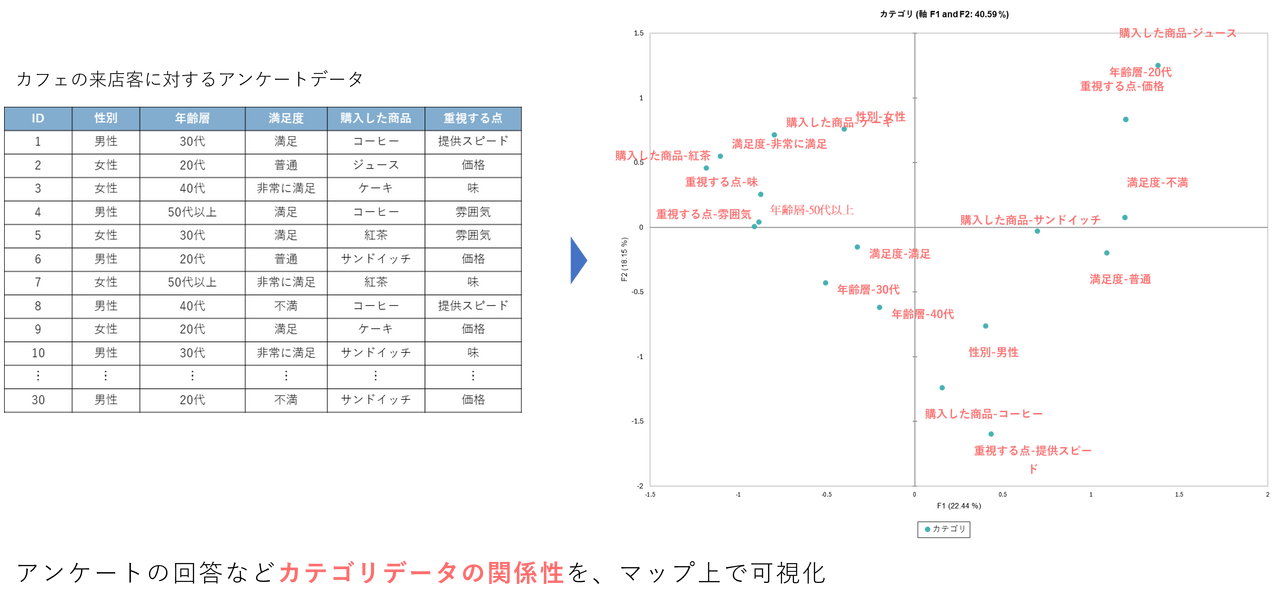
4. 分析マップ(グラフ)の解釈
最終的に、これらの計算結果は3種類のマップとして可視化されます。
カテゴリープロット
アンケートの各回答(カテゴリー)同士の関係性を示します。マップ上で近くにある点(カテゴリー)同士は、関連性が強い(同時に選ばれやすい)ことを示しています。
※軸を解釈しやすくするため、画像には説明を加えています。
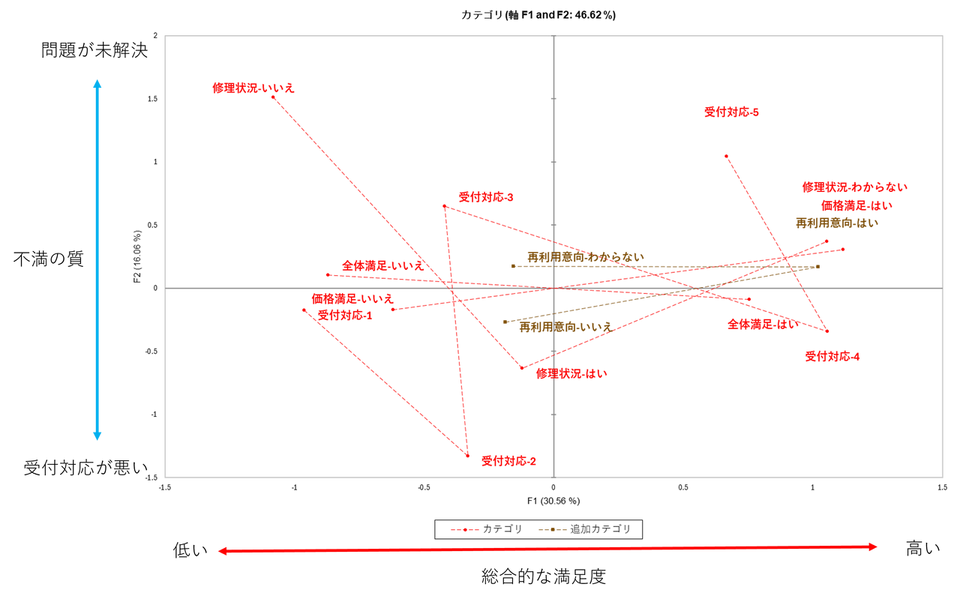
F1(横軸):データ全体の 30.56% を説明する「総合的な満足度」の軸です。
- 右側:「全体満足-はい」、「価格満足-はい」、「受付対応-4」などが集まるポジティブな領域。
- 左側:「全体満足-いいえ」、「価格満足-いいえ」、「受付対応-1」 などが集まるネガティブな領域。
F2(縦軸):データ全体の 16.06% を説明する「不満の質(タイプ)」の軸です。
- 上側:「修理状況-いいえ」が強く影響しており、「問題が解決しなかった」という深刻な問題を示します。
- 下側:「受付対応-2」などがあり、「(修理はともかく)受付の対応が悪かった」という不満を示します。
グラフ上の点線は、「同じ質問項目(変数)に含まれる選択肢同士」をグループとして結んでいます。例えば、「全体満足-はい」と「全体満足-いいえ」は赤い点線で結ばれています。これにより、バラバラに散らばった点が、どの質問の一部なのかが一目でわかります。点線が長く伸びている(選択肢同士が離れている)ほど、その質問は回答者を「明確に区別する要因になっている」ことを意味します。反対に線が短い(点同士が中央付近に集まっている)場合、その質問は、回答者を区別する力があまりない(みんな似たような回答をしている、または特徴がない)ことを意味します。
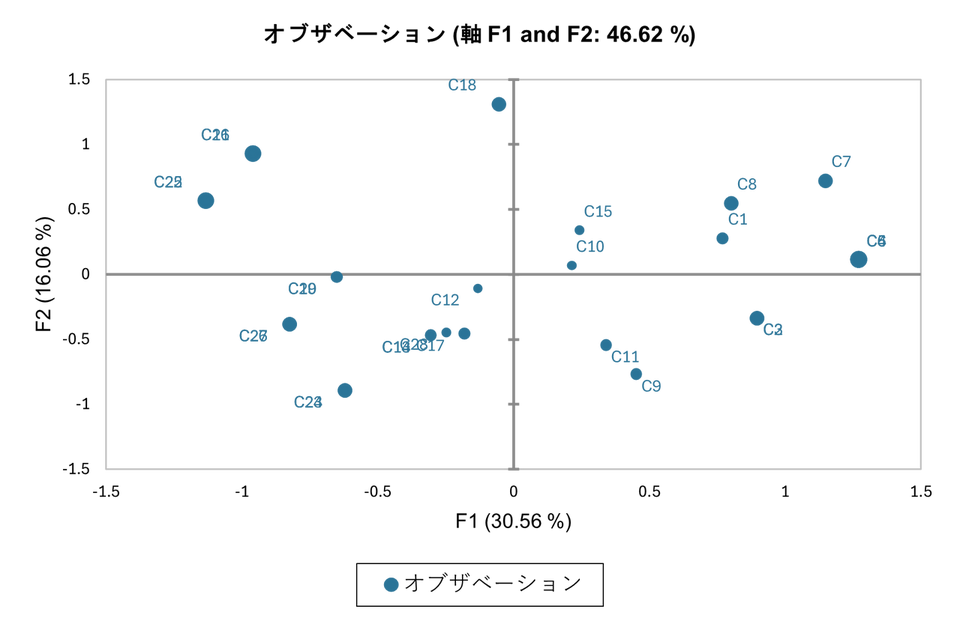
オブザベーションプロット
このグラフは、アンケートに回答した28名の顧客(C1〜C28)を、回答パターンの類似度に基づいて配置したものです。近くにいる顧客ほど似た回答をしており、軸の意味は前のグラフ同様、横軸が「総合満足度」、縦軸が「不満のタイプ(上:問題未解決、下:接客不満)」を表します。
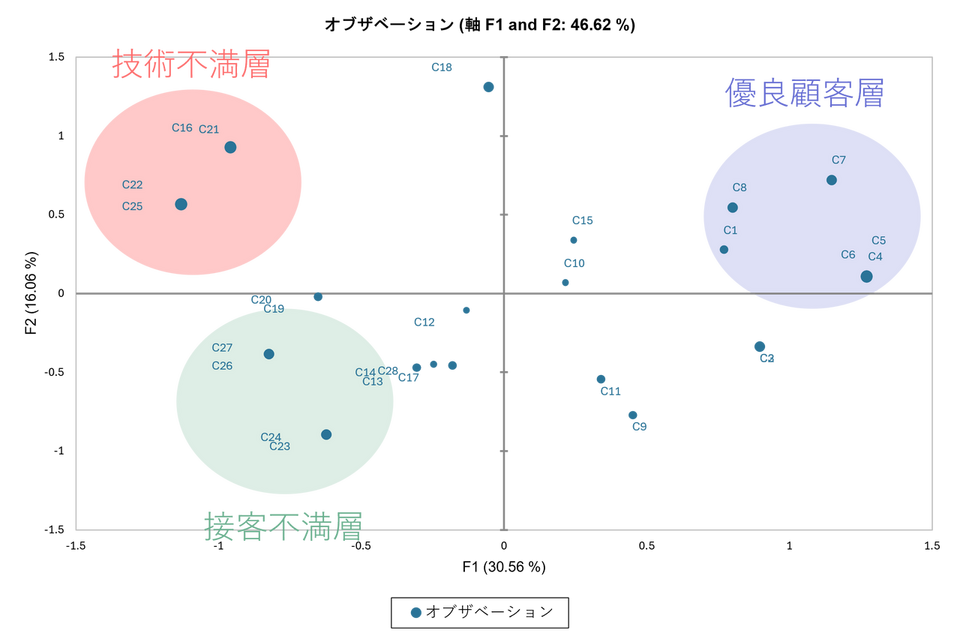
このマップの位置関係から顧客を以下の3つに分類できそうです。
- 右側(C4, C5 など):
サービス・価格ともに満足している優良顧客層。 - 左上(C16, C21 など):
「問題が解決していない」ことに不満を持つ層。技術的なフォローが必要かもしれません。 - 左下(C23, C24 など):
「受付対応」に不満を持つ層。接遇面での謝罪や改善が必要かもしれません。
なお、実行時の設定で「Cos2 でポイントサイズ変更」のオプションが有効になっていると、マップ内の点の大きさが「情報の信頼度」に応じて変化します。大きな点(主に外側)は、その顧客の特徴がこのマップ上で正確に表現されており、位置関係を信頼して解釈できることを示します。一方、小さな点(主に中央)は、回答が平均的であるか、このマップだけでは特徴を完全には捉えきれていないことを示唆しています。
バイプロット
これまで見てきた「カテゴリー」と「オブザベーション」の2つの情報を、1枚のマップ上に重ね合わせたものです。グラフの読み方はシンプルで、「近くにあるもの同士は強い関連がある」と解釈します。回答者(青)が特定の回答(赤)の近くにいる場合、その選択肢を選んだ可能性が高く、回答(赤)が結果(茶)の近くにあれば、そこには強い関連があります。
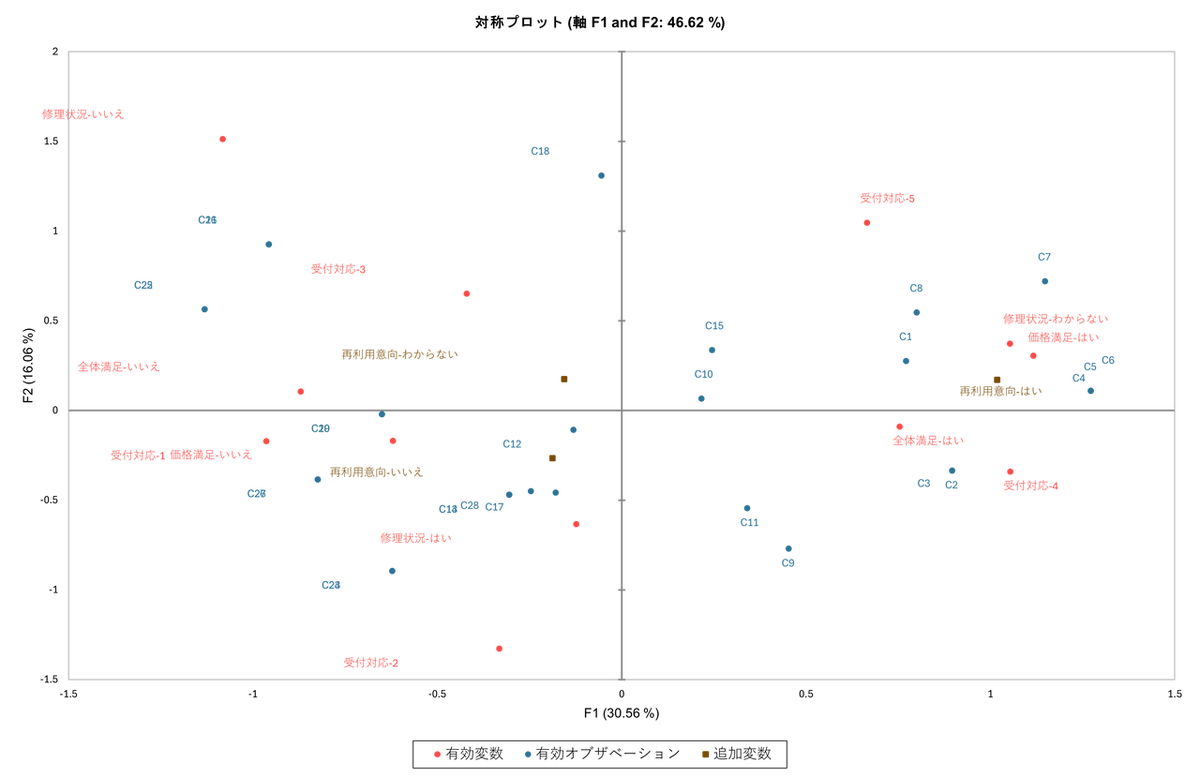
例えば、右上の回答者(C1, C4, C5, C6 など)は、カテゴリーの「全体満足-はい」、「価格満足-はい」と近くに集まっています。さらに、そこには補足変数(追加カテゴリー)の「再利用意向-はい」もプロットされています。このことから、「サービスや価格に満足した顧客が、再利用にも前向きである」という、分析目的であった関係性を明確に可視化できます。

まとめ
多重コレスポンデンス分析は、一見複雑に見えるアンケートデータ(複数の質的変数)に潜む全体的な構造や回答者グループの傾向を、1枚のマップに集約して可視化する手法です。アンケート結果をただ集計するだけでなく、「回答者セグメント」や「回答の背景にある関係性」まで深掘りしたい場合に、多重コレスポンデンス分析は最適です。ぜひ、XLSTAT で多重コレスポンデンス分析を実行し、分析業務を次のレベルへと引き上げましょう。
参考文献
- XLSTAT: Multiple Correspondence Analysis (MCA) in Excel
https://community.lumivero.com/s/article/6374-multiple-correspondence-analysis-mca-excel?language=en_US
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介した多重コレスポンデンス分析はすべてのライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。

