はじめに
研究の現場において、「インタビューやアンケートの自由記述(定性データ)から深い洞察を得たいが、全体の傾向も統計的に示したい」という悩みはありませんか。本ページでは、質的データ分析ソフトNVivo と統計解析ソフトXLSTAT を組み合わせることで、この課題を解決する「混合研究法」の実践プロセスを、具体的な事例とともに解説します。
※なお、このページではNVivo 15 Windows 版を使ってご説明しております。
混合研究法とは?
混合研究法とは、1つの研究プロジェクトの中で質的研究(定性研究)と量的研究(定量研究)の両方のアプローチを組み合わせる手法です。
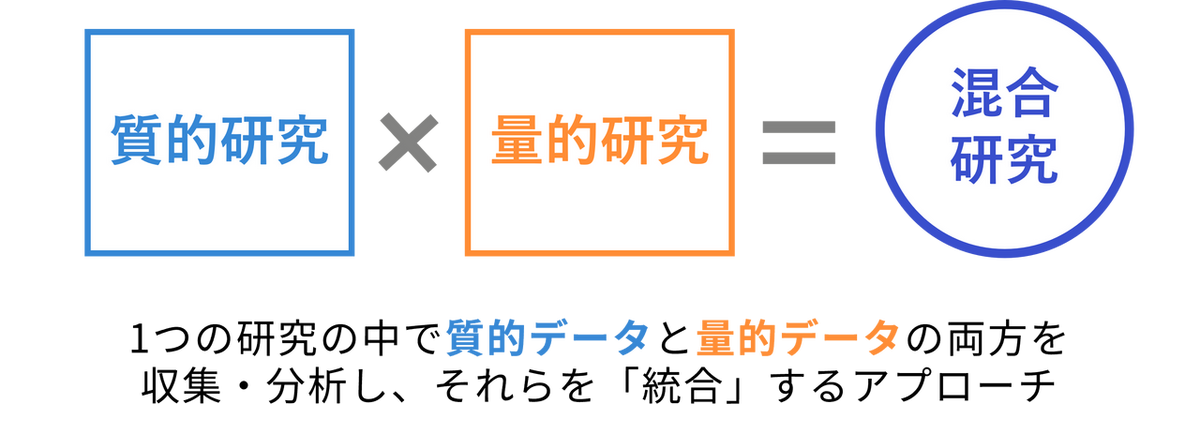
- 質的研究:
現象を記述し、文脈(コンテキスト)を理解する。構造化されていないデータ(インタビュー、自由記述など)から意味を見出すことに長けています。 - 量的研究:
現象を数値で測定し、統計分析を行う。トレンドやパターンを特定し、一般化することに長けています。
なぜこれらを組み合わせるのかといえば、単一のアプローチでは捉えきれない限界を克服し、互いの弱点を補い合うためです。例えば、数値を扱う量的研究だけでは、全体的な傾向はつかめても、「なぜそうなったのか」という背景や、個人の心の機微までは見えてきません。一方で、質的研究だけでは、詳細な背景や内面的な事情は理解できても、それが一部の特殊なケースなのか、全体にも言えることなのか判断しにくいという弱点があります。
定性データが持つ「深さ」と、定量データが持つ「広さ」を統合することで、より豊かな洞察を得られるだけでなく、単独の手法を用いるよりも説得力のある根拠を導き出すことが可能になります。
混合研究法の種類
混合研究法には主に3つのデザインがあります。
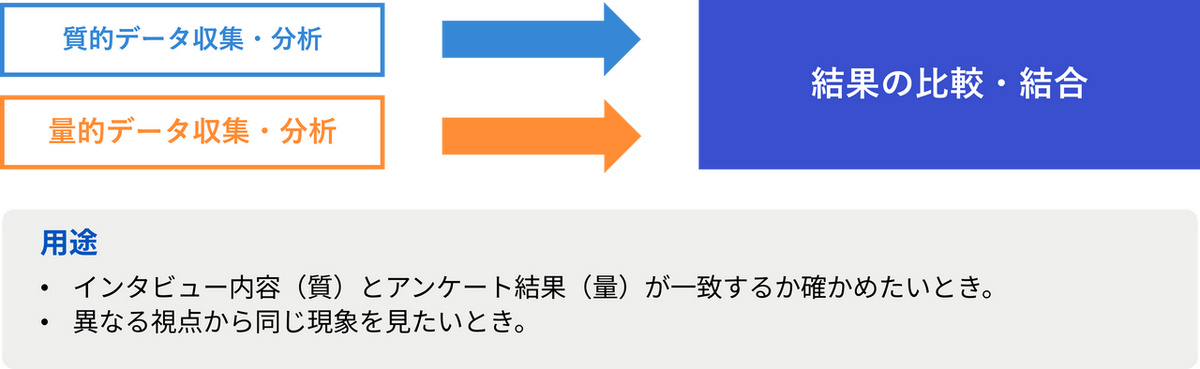
1. 収斂的並行デザイン
定性と定量のデータを同時に収集・分析し、結果を比較・統合する手法。
2. 説明的順次デザイン
まず量的分析を行い、その結果(外れ値や意外な結果など)を詳しく理解するために質的分析を行う手法。

3. 探究的順次デザイン
まず質的分析でテーマや仮説を生成し、その後に量的分析でその一般性を検証する手法。

今回の事例では、まず農家の語り(質的)からテーマを抽出し、それを変数化して統計分析(量的)にかけるため、「探究的順次デザイン」に近いアプローチをとります。
データセットの紹介
今回は下記架空のデータセットを用いて解説します。
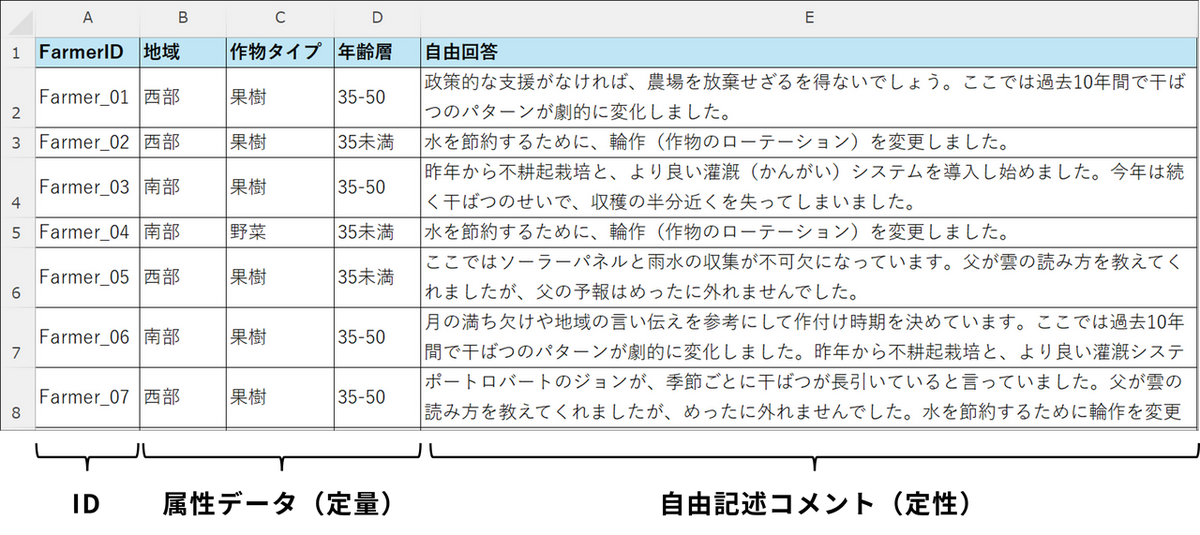
- データセット(30名分):
- 属性データ:
地域、作物タイプ、年齢層 - 自由記述コメント:
気候変動や農業実践に関する語り(例:「政策支援がないと農場を放棄せざるを得ない」「月の満ち欠けで作付けを決める」など)
- 属性データ:
- リサーチクエスチョン:
「農家の社会人口統計学的プロファイル(年齢や地域など)は、気候変動への認識や適応戦略にどう影響するか?」
- 分析の目的:
農家の語り(ナラティブ)から主要なテーマを特定し、それを測定可能な変数へ変換して、グループ間のパターンを統計的に探ること。
サンプルデータのダウンロードはこちらから
Climate_Change_Perception_Farmers_XLSTAT_NVivo.zip
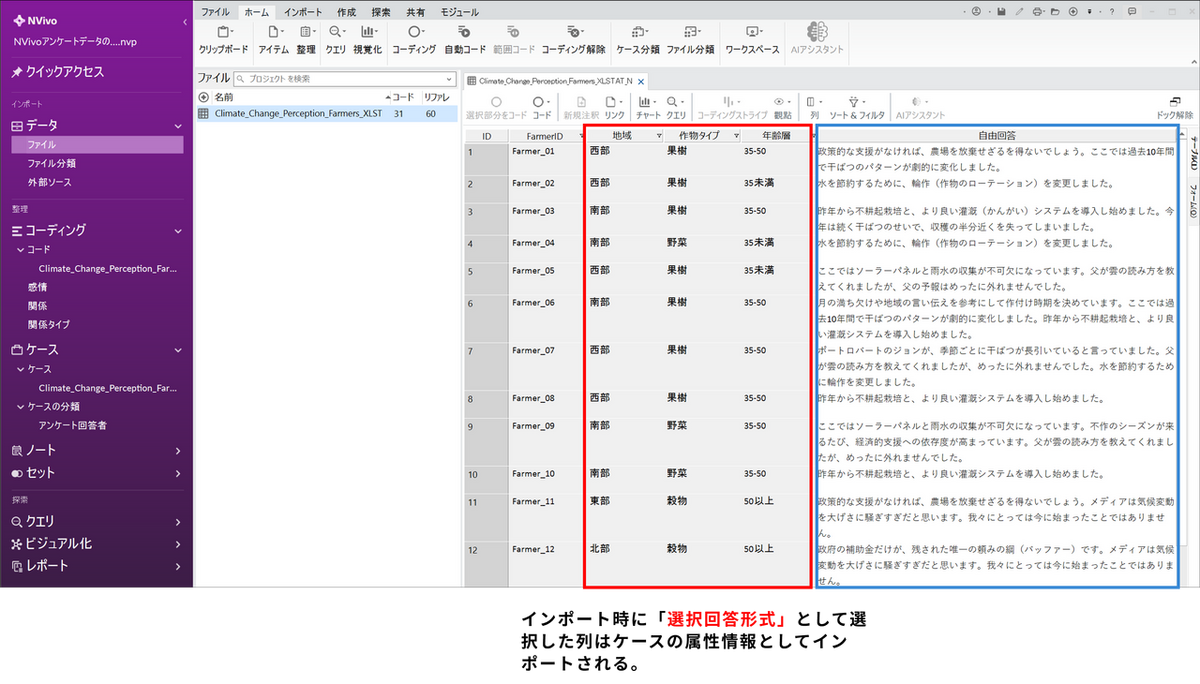
データセットのインポート
まずはデータセットをNVivo のプロジェクトファイルにインポートします。NVivo Windows 版ではExcel 形式のデータをインポートすると、対象者(ID)ごとにケースが自動的に作成されます。また、各ケースには属性情報が付与されています。
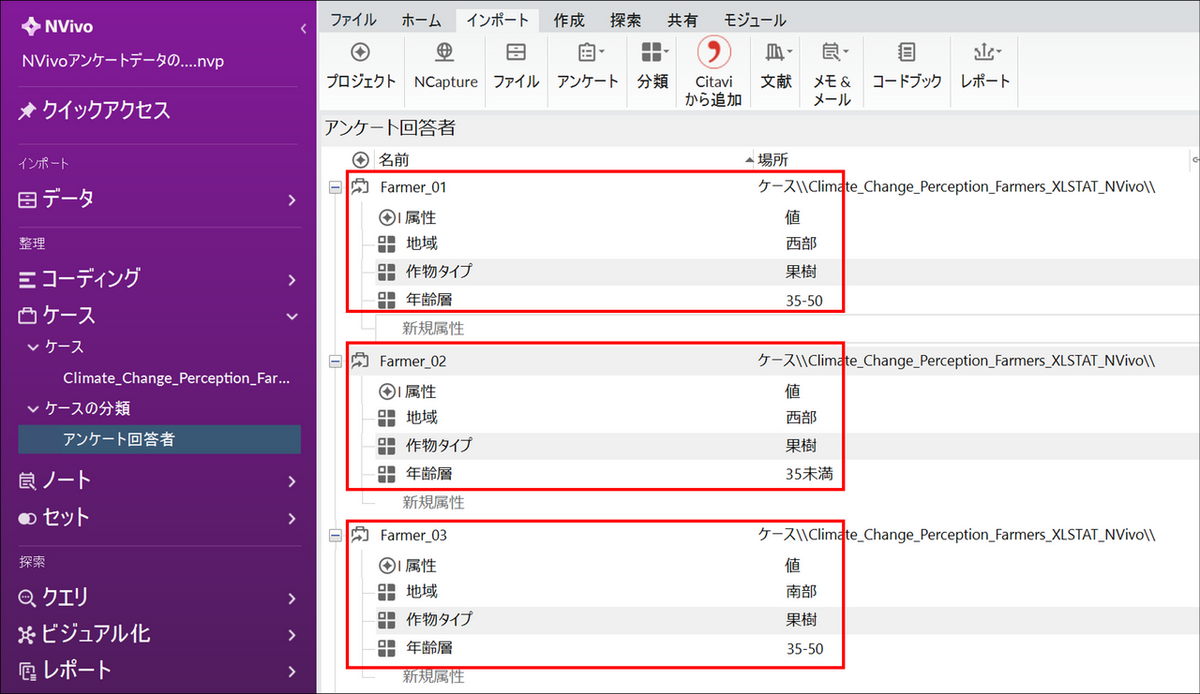
アンケートデータ(Excel)のインポート方法は下記セミナー動画をご参照ください。
NVivo での分析:テーマの抽出
データセットのインポートが完了したら、構造化されていない自由記述のコメントを「コーディング」という手法で分析します。これはテキストデータの中から意味のある箇所を抜き出し、「コード」と呼ばれるラベルを付ける作業です。
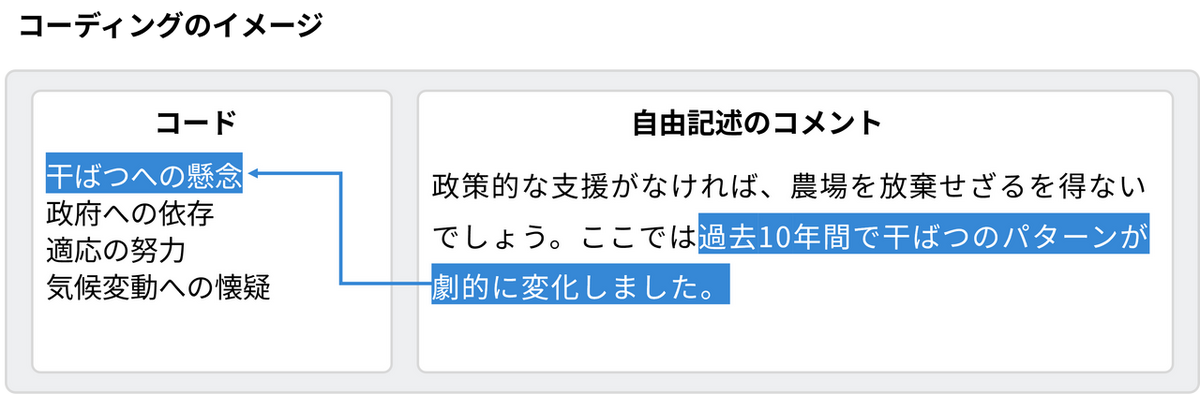
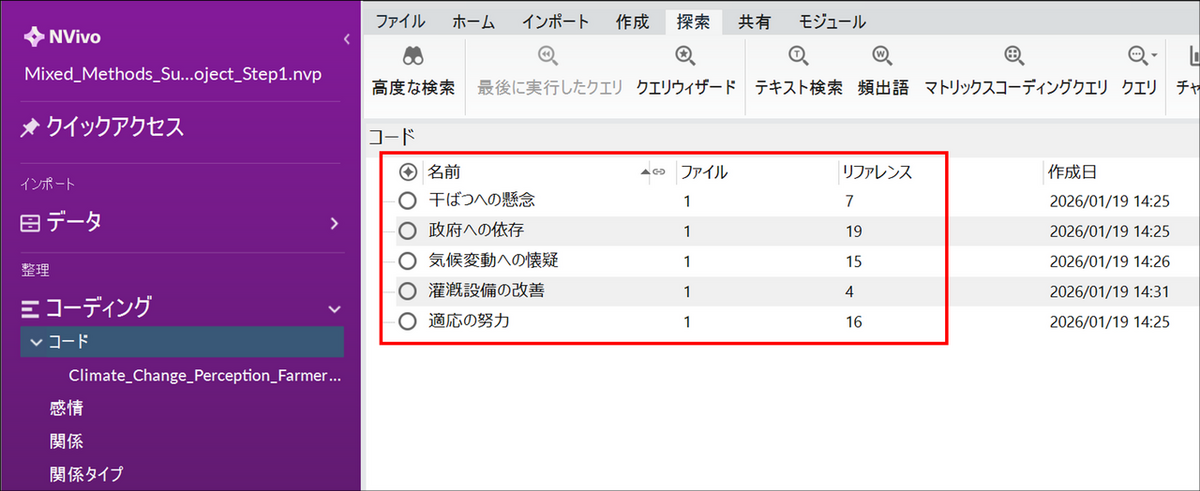
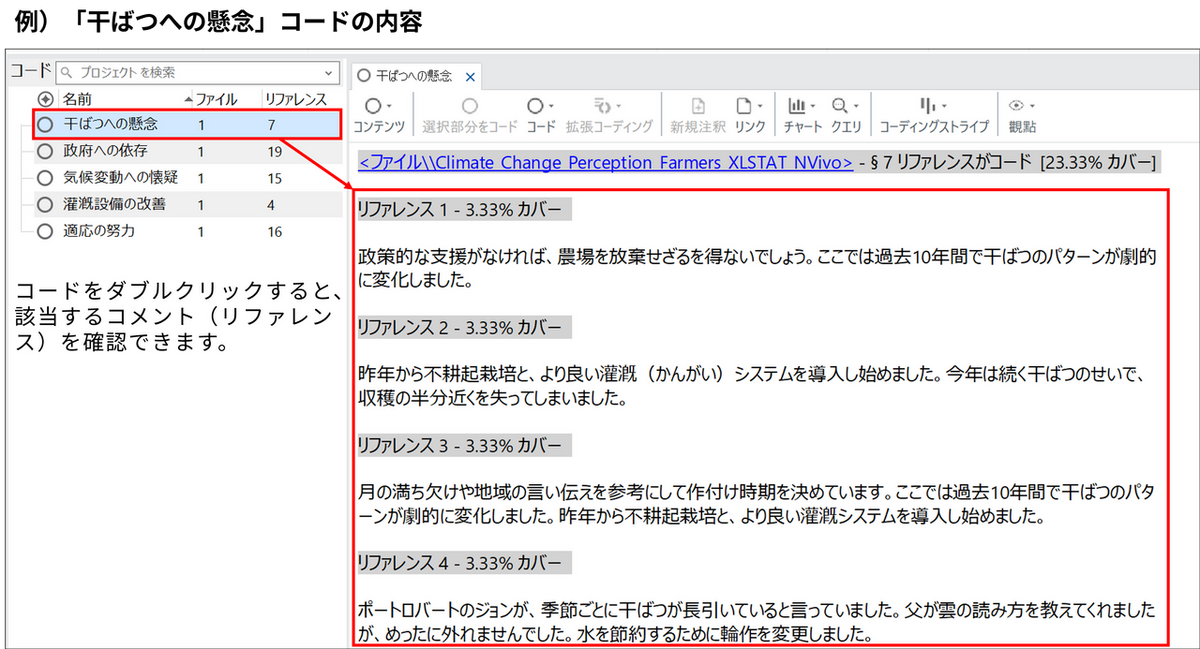
今回の事例では、農家のコメントを読み込み、以下のようなテーマ(コード)を抽出し、コーディングを行いました。
- 干ばつへの懸念
「干ばつパターンが変わった」「収穫の半分を失った」などの言及。 - 政府への依存
「補助金が頼りだ」「政策支援が必要」などの言及。 - 適応の努力
「点滴灌漑を導入した」「不耕起栽培を始めた」などの言及。 - 気候変動への懐疑
「メディアは大げさだ」「自然な変動に過ぎない」などの言及。 - 灌漑設備の改善
「より良い灌漑を使い始めた」「灌漑の改善を伴う不耕起栽培」など、より良い灌漑システムや実践の導入に関する言及。
NVivo のコーディング方法は下記セミナー動画をご参照ください。
NVivo オンラインセミナー:コーディング基礎編 Windows 版
マトリックスコーディングクエリの実行
自由記述コメントのコーディングが完了したら、NVivo で抽出した「テーマ」を、XLSTAT で分析するために「数値データ」に変換します。具体的には、マトリックスコーディングクエリ機能を利用し、農家ごとに、あるテーマについて言及していれば「はい」、していなければ「いいえ」というバイナリ変数の表を作成します。
-
メニューの [探索] タブから[マトリックスコーディングクエリ] をクリック
※画面サイズによりメニューの表示が異なります。
-
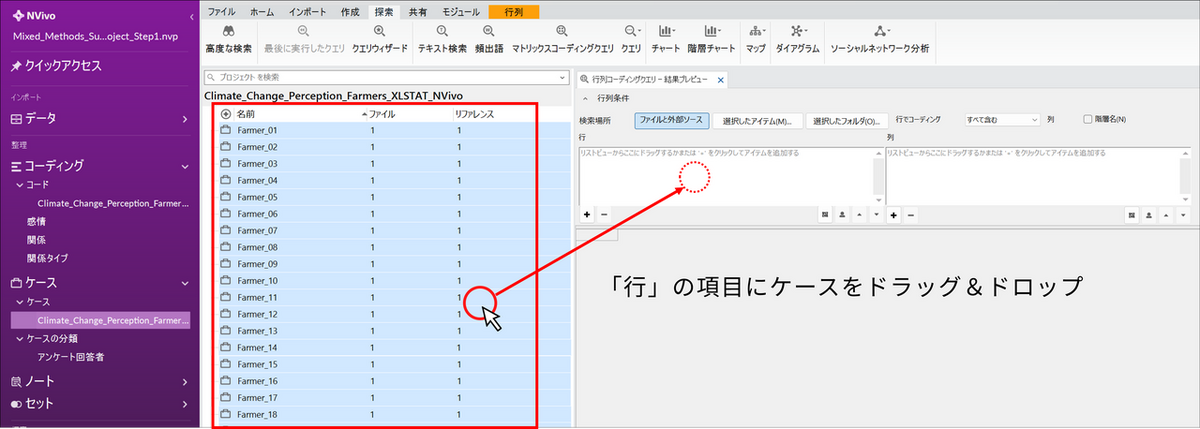
「行」と「列」にそれぞれアイテムを選択します。
- 行:回答者ごとの「ケース」をドラッグ&ドロップします。
- 列:作成した「コード」をドラッグ&ドロップします。
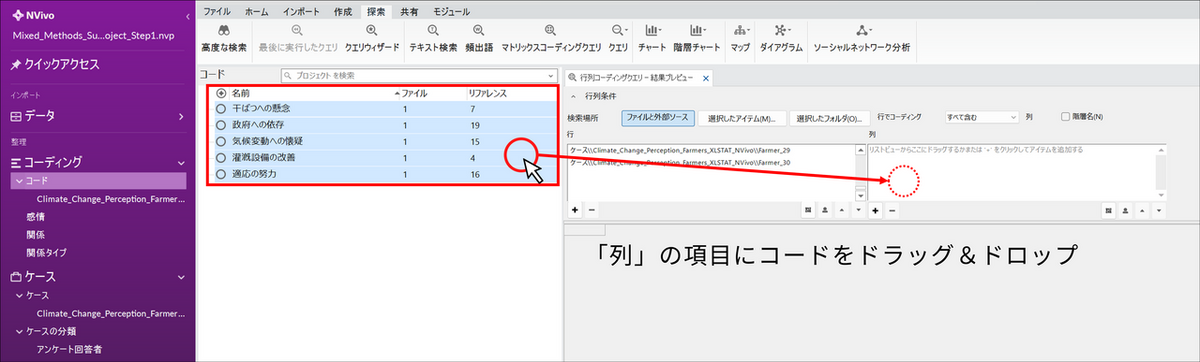
-
[クエリを実行] ボタンをクリックします。
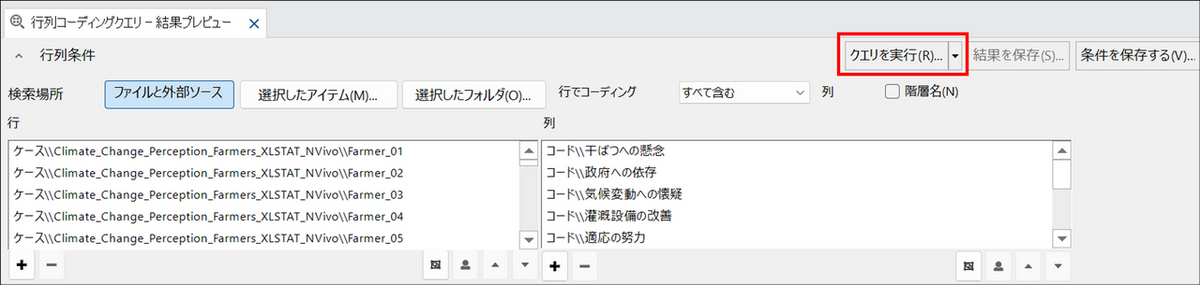
-
各農家(行)が各テーマ(列)に言及している箇所数が表示された表が生成されます。
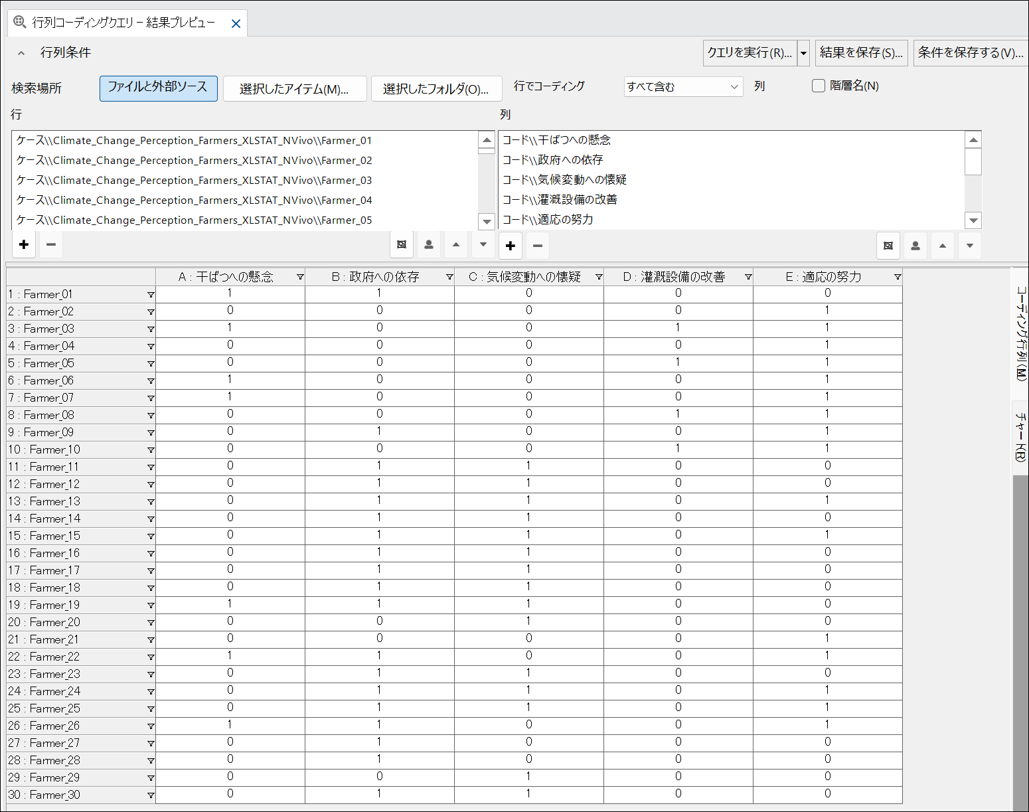
-
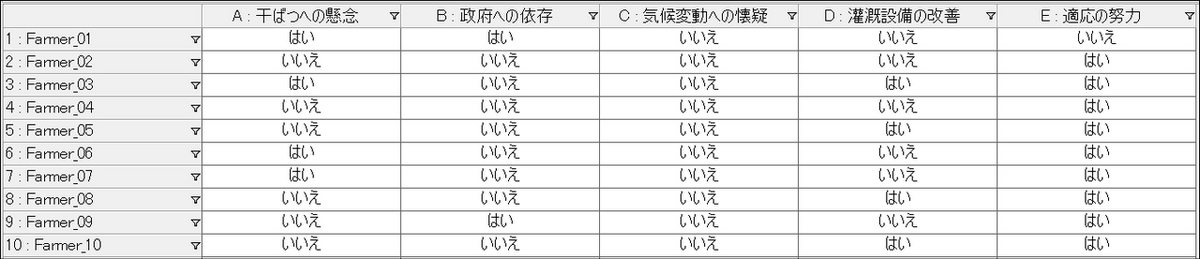
この表の値は、リファレンス数になっているため、XLSTAT での分析用に「言及あり=はい」「言及なし=いいえ」のバイナリ形式(2値変数)に変換します。メニューの[行列] タブから[コーディング存在] を選択します。

出力結果のエクスポートとデータのマージ
-
行列コーディング結果の上で右クリックし、[コードマトリックスをエクスポート] を選択します。
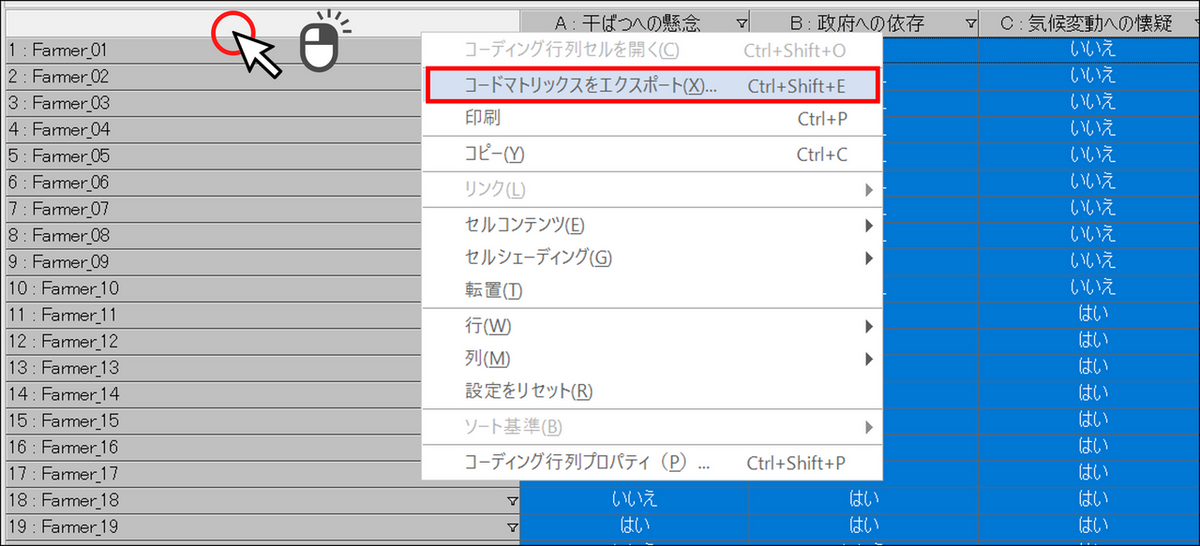
-
ファイル名と場所を指定し、Excel ファイルを保存します。
-
以下のように元のデータセットと行列コーディングの結果をマージ(統合)します。
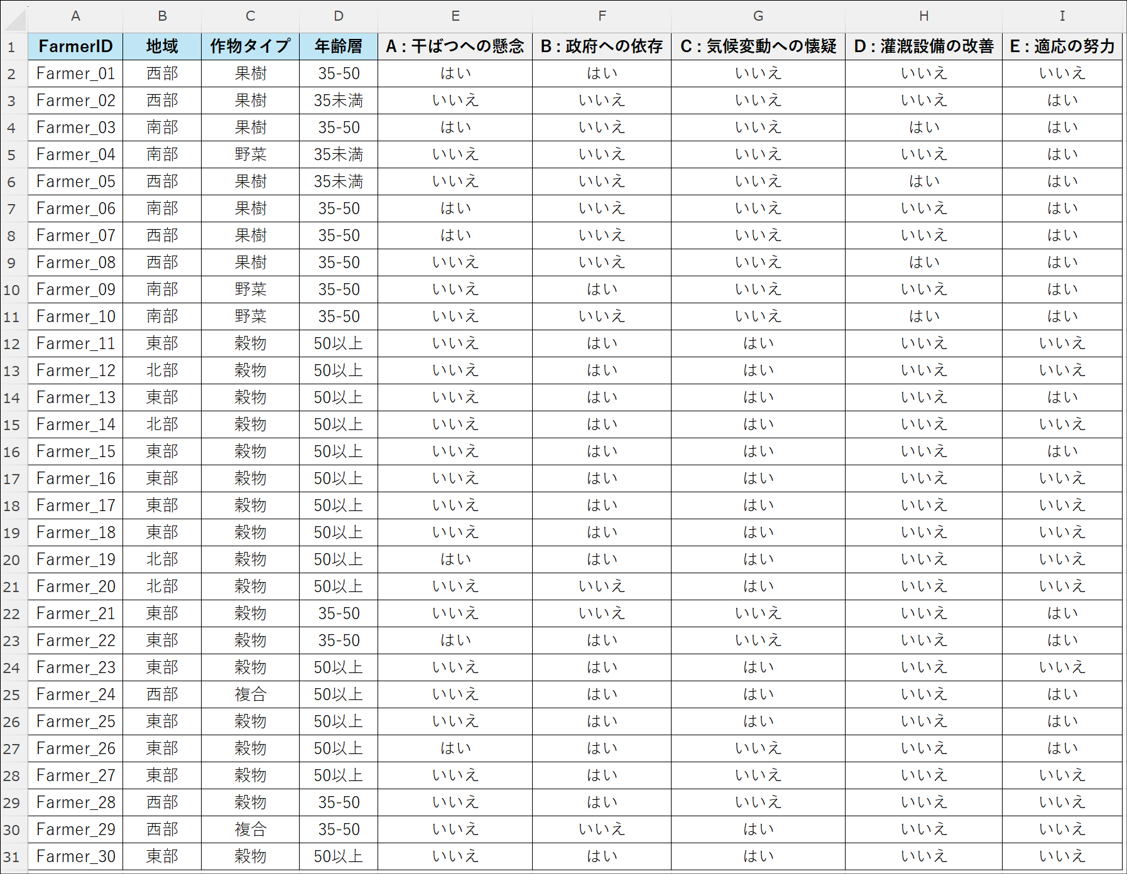
これで、XLSTAT で分析できる準備が整いました。
XLSTAT での分析:可視化と統計解析
ここからはExcel 上のXLSTAT を使用した分析に移ります。上記データセットをExcel で開き、データの全体像把握から詳細分析へと進みます。
クロス表の2Dプロットによる可視化
まず多変量解析を行う前に、変数の関係性をざっと確認しましょう。 XLSTAT の「クロス表の2Dプロット」機能を使用し、「年齢層」と「作物タイプ」の関係を可視化します。
クロス表の2Dプロットの実行手順
-
XLSTAT を起動し、[データ可視化] > [クロス表の2Dプロット] を選択します。
-
ダイアログボックスが表示されたら、以下のように設定します。
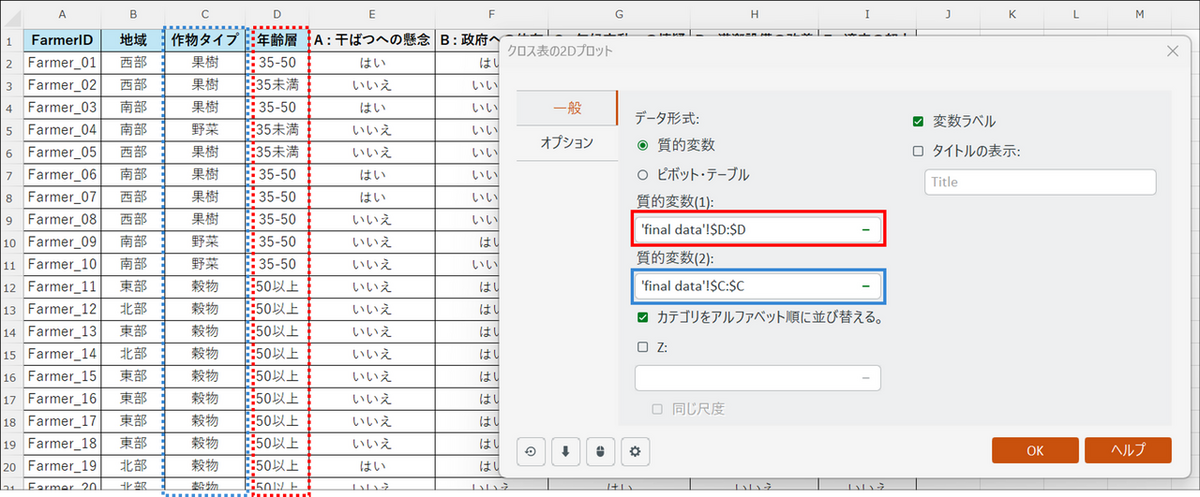
- データ形式:[質的変数] を選択
- 変数ラベル:チェックを入れる
- 質的変数(1):「年齢層」の列を選択
- 質的変数(2):「作物タイプ」の列を選択
-
[OK] をクリックすると、別シート(2D表示)にグラフが出力されます。
計算が完了すると、新しいシートに2D プロットが生成されます。縦軸に「年齢層」、横軸に「作物タイプ」が並び、人数が円の面積で表現されています。
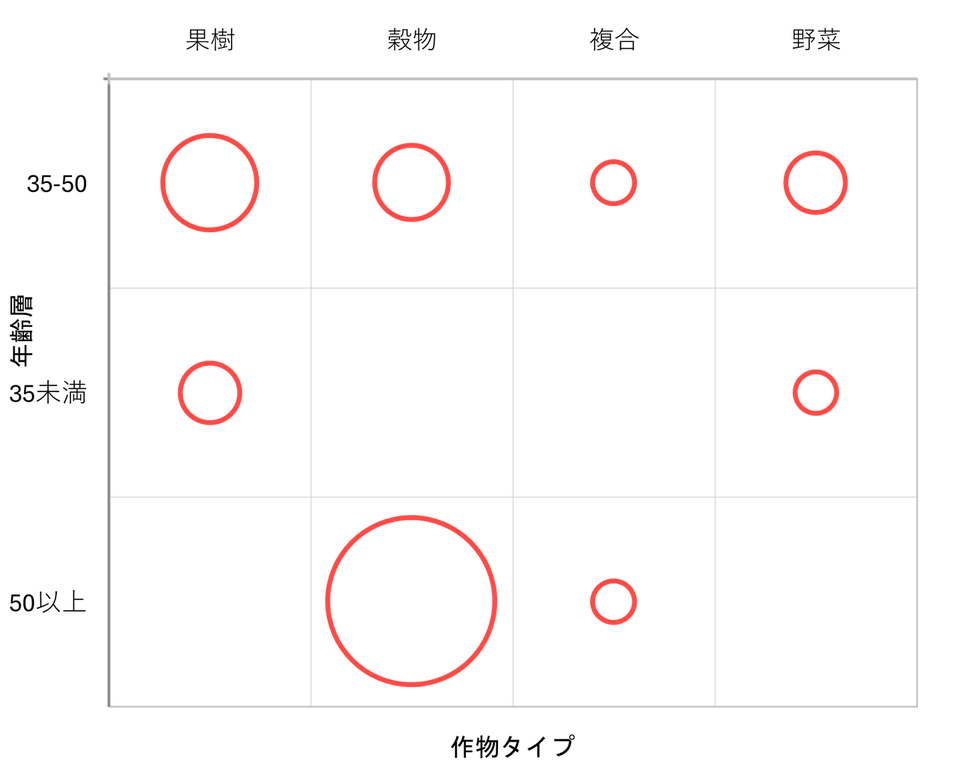
この結果から以下のようなことが読み取れます。
- 「50以上」の層は「穀物」に極端に集中している
画像下段を見ると、「50以上」の行では「穀物」の円が非常に大きく、他の年齢層と比較しても突出しています。一方で、「果樹」や「野菜」には円が存在しません。高齢層の農家は、伝統的な穀物栽培(おそらく米や小麦など)に注力しており、園芸作物(果樹・野菜)を手掛けているケースがこのデータセット内では皆無であることがわかります。 - 「35未満」の若手層は「果樹」と「野菜」に特化している
画像中段を見ると、「35未満」の行では「果樹」と「野菜」のみに円があり、「穀物」や「複合」には円がありません。若手の新規就農者や後継者は、穀物ではなく、より収益性の高い、あるいは新しい農業スタイルである果樹や野菜の栽培を選択している傾向が強く見られます。 - 「35-50」の中堅層はバランス型である
画像上段を見ると、すべての作物タイプ(果樹、穀物、複合、野菜)に円が分布しています。この世代は、上の世代の「穀物」も引き継ぎつつ、下の世代が選ぶ「果樹・野菜」も手掛けており、過渡期的な特徴を持っているか、あるいは経営を多角化している層である可能性が示唆されます。
クロス表の2Dプロットの具体的な操作手順や見方については、以下のページも合わせてご参照ください。
XLSTAT によるクロス集計表の2D プロット:データの相対的な重要度を可視化しよう
多重コレスポンデンス分析の実行
次に、データの背後にある「隠れた構造」を明らかにするために、多重コレスポンデンス分析を実行します。多重コレスポンデンス分析とは、アンケートの回答パターンのような「カテゴリカルデータ(質的変数)」の関係性を、2次元マップ上に可視化する手法です。似ている項目は近くに、関係が薄いものは遠くに配置されるため、データの背後にある隠れたグループや傾向を直感的に発見できます。
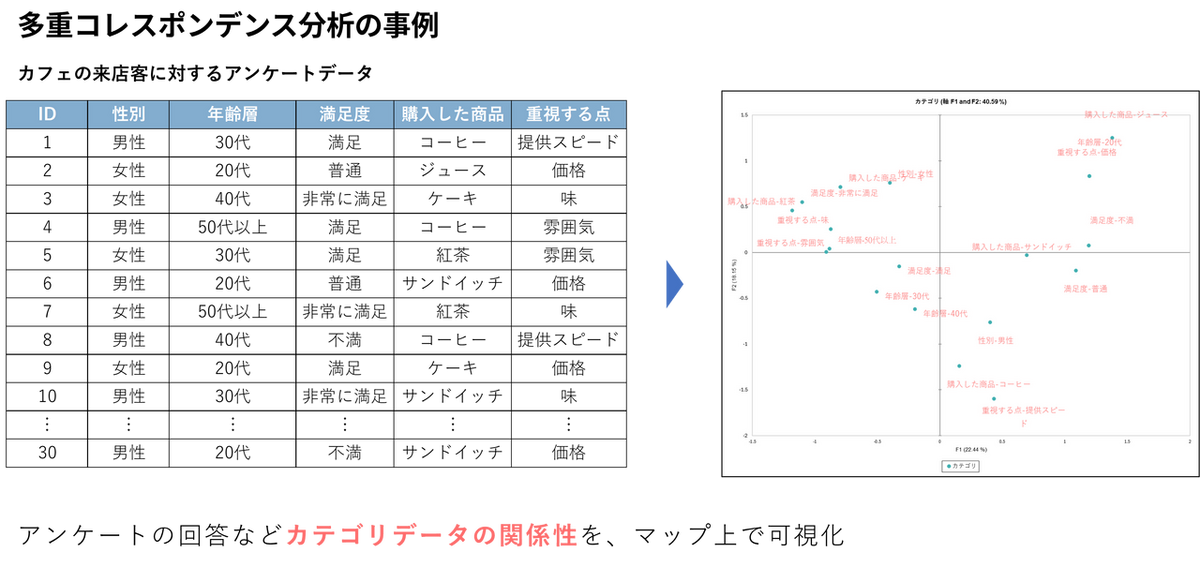
多重コレスポンデンス分析の実行手順
-
XLSTAT を起動し、[発見、説明、および予測] > [データ解析] > [多重コレスポンデンス分析(MCA)] を選択します。
-
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
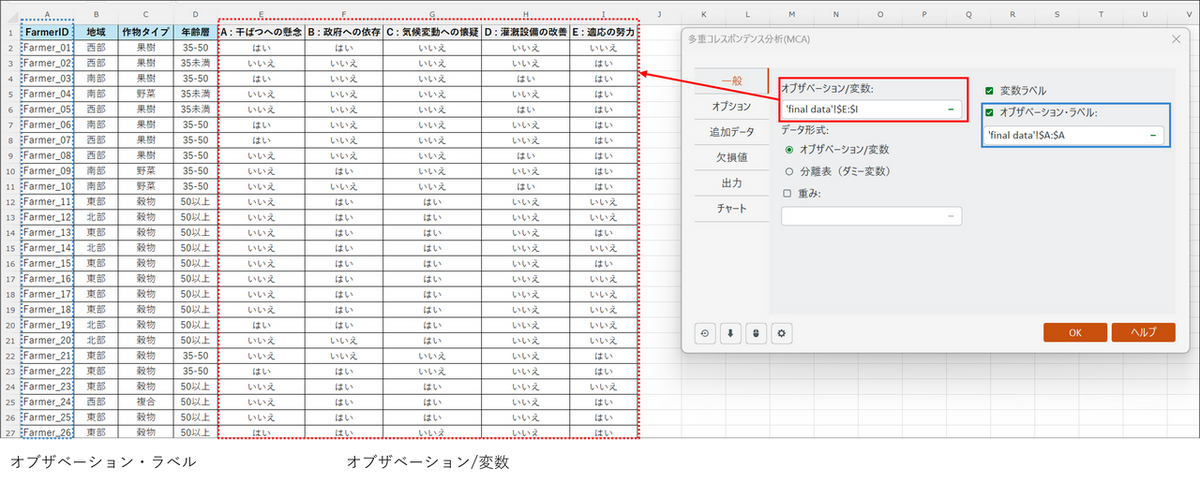
- データ形式:「オブザベーション/変数」を選択します。
- オブザベーション/変数:
分析に使用するデータ列(「A : 干ばつへの懸念」、「B : 政府への依存」、 「C : 気候変動への懐疑」、「D : 灌漑設備の改善」、「E : 適応の努力」の列)を選択します。 - 変数ラベル:チェックを入れます。
- オブザベーションラベル:「Farmer ID」の列を選択します。
-
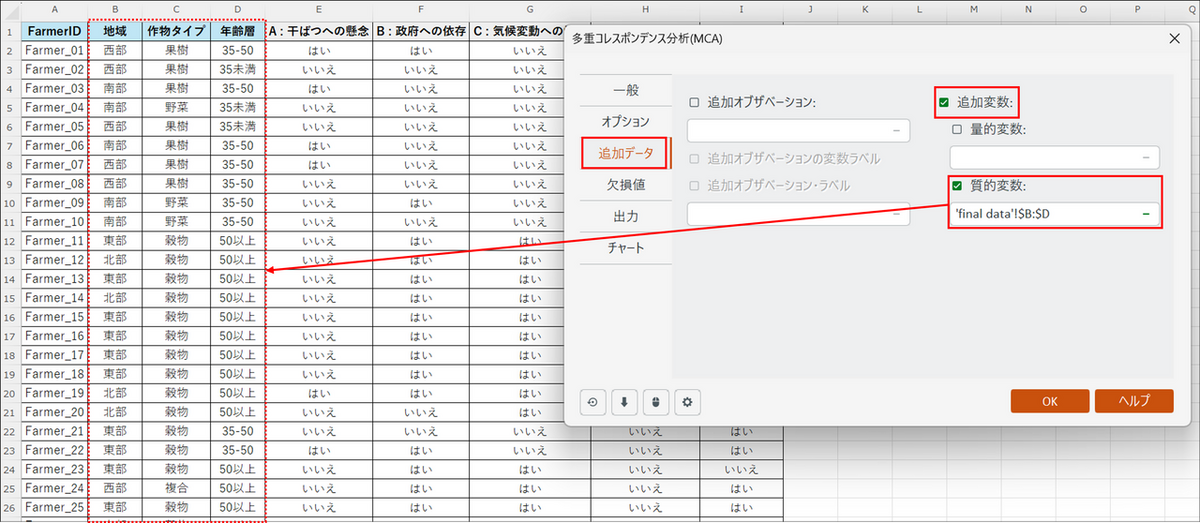
[追加データ] タブに切り替え、[追加変数] と[質的変数] の項目にチェックを入れ、属性(「地域」、「作物タイプ」、「年齢層」)の列を選択します。
-
[OK] ボタンをクリックすると、結果が別シート(MCA)に出力されます。
多重コレスポンデンス分析の具体的な操作手順や見方については、以下のページも合わせてご参照ください。
XLSTAT による多重コレスポンデンス分析:アンケートデータの隠れた構造を可視化する
多重コレスポンデンス分析結果の解釈
多重コレスポンデンス分析を実行すると、結果に「対称プロット」と呼ばれる散布図が得られます。この図を読み解くことで、農家の類型化が可能になります。
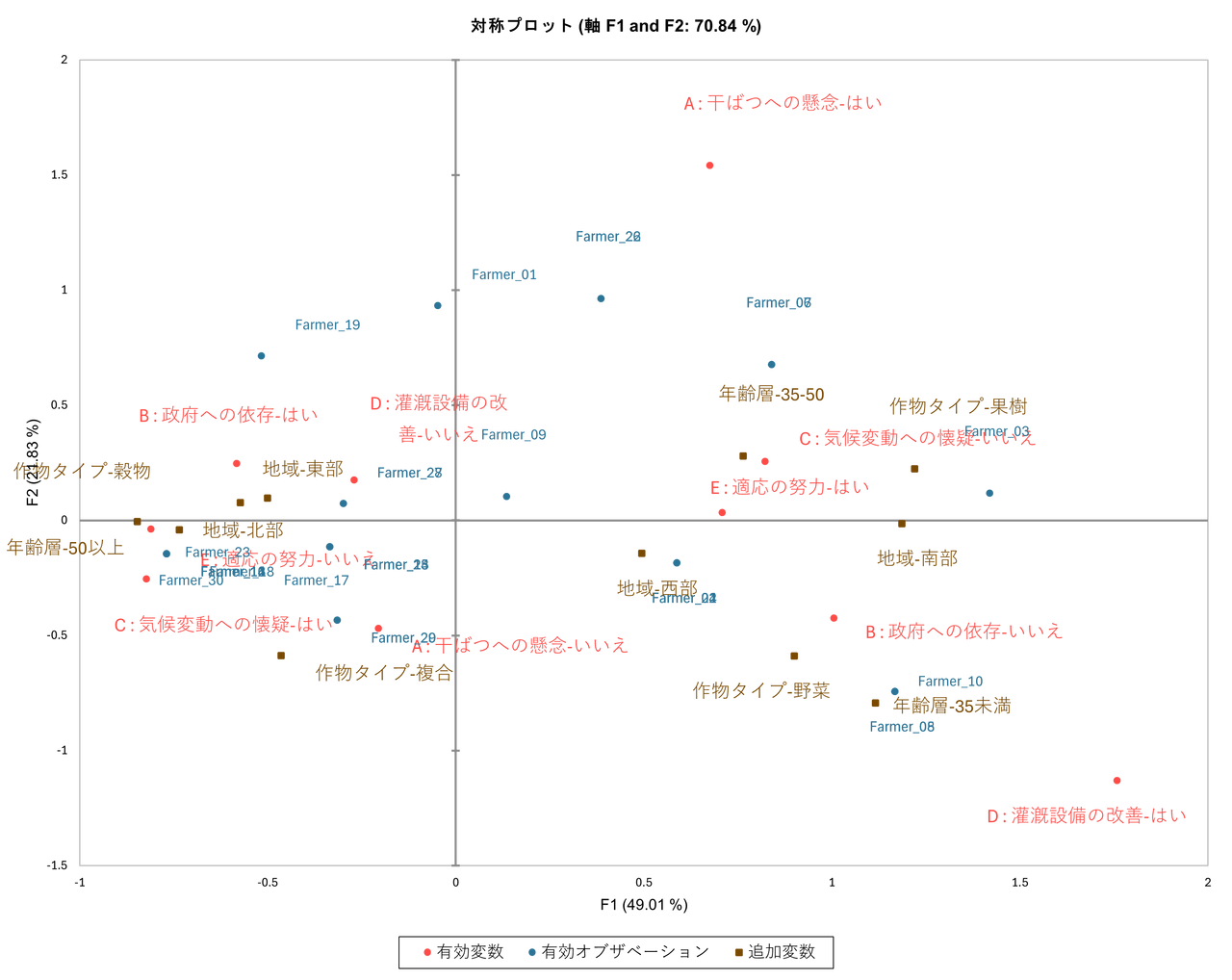
プロット上で近くに配置されている変数やケースは、強い関連性を持っています。今回の分析からは、以下の2つの明確なグループが浮かび上がりました。
- 保守的・依存型(左側)
- 特徴:プロットの左側に集まったグループ。
- 属性:「50歳以上」「北部地域」「穀物栽培」の農家。
- 意識:「気候変動への懐疑」が高く、「干ばつへの懸念」は低い。また、「政府への依存」が高い傾向にあります。
- 適応的・自立型(右側)
- 特徴:プロットの右側に集まったグループ。
- 属性:「30歳未満、35-50歳(若手・中堅)」「南部/西部地域」「野菜/果樹栽培」の農家。
- 意識:「適応への努力」や「灌漑設備の改善」といった変数と強く結びついており、能動的に気候変動対策を行っていることが分かります。
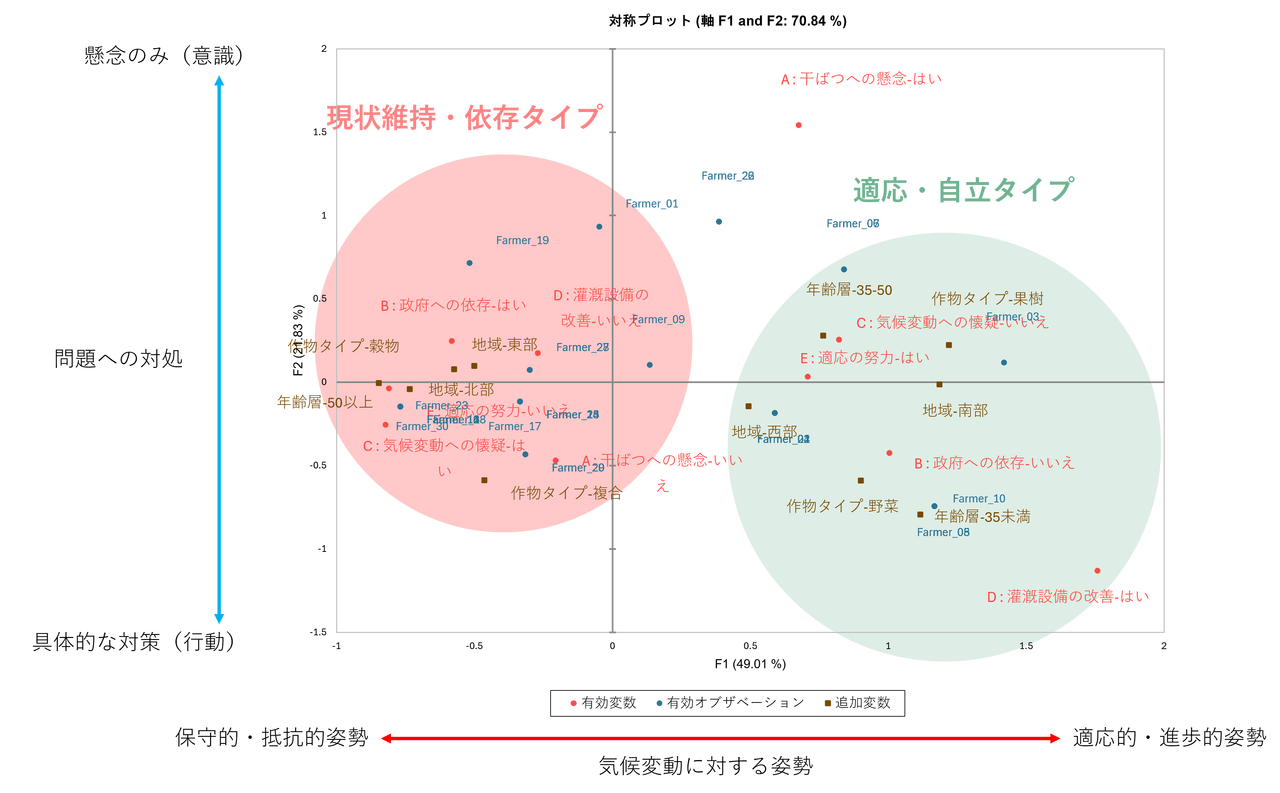
このように、単に「気候変動をどう思うか」という定性データだけ、あるいは「年齢と地域」という定量データだけでは見えなかった、「誰が、なぜ、どのように考えているか」という統合的なプロファイルを明らかにすることができました。
まとめ
混合研究法は、手間の掛かる手法に思えるかもしれません。しかし、NVivo で定性データの豊かな「文脈」を整理し、それをXLSTAT で客観的な「構造」として可視化することで、研究結果の説得力は飛躍的に高まります。「言葉」と「数値」の壁を取り払い、データの持つ物語をより深く、より広く探求するために、ぜひこのワークフローを活用してみてください。
参考文献
- 5 ways to maximize insights and efficiency in mixed methods research (with NVivo and XLSTAT)
https://lumivero.com/gated-content/back-to-school-supercharge-your-research-workflow-on-demand/
-
亀井智子. 地域保健活動に活かす混合研究法:質と量 両者の統合から見えるもの. 保健師教育. 5(1): 7-13, 2021.
-
八田太一. 混合研究法の基本型デザインと統合 : 初学者が陥りやすい落とし穴. 立命館人間科学研究. 39: 49-59, 2019.
