XLSTAT による多次元尺度法(MDS):知覚マップで商品の類似度を可視化しよう
- 多次元尺度法とは?
- 主成分分析との違い
- MDS の種類
- XLSTAT で選択できる6つのモデル
- チュートリアルで使用するサンプルデータ
- XLSTAT で多次元尺度法を実行する手順
- 多次元尺度法の出力結果の解釈
- 3次元データの可視化(3D Plot)
- まとめ
- 参考文献
- XLSTAT の無料トライアル
多次元尺度法とは?
多次元尺度法(MDS:Multi-Dimensional Scaling)は、複数のデータ(対象)間の「類似度」や「非類似度(距離)」をもとに、それらの相対的な位置関係を低次元(主に2次元や3次元)のマップ空間上に可視化する多変量解析手法です。一言で言えば、「地点間の距離データから、元の地図を再現するような手法」と例えることができます。
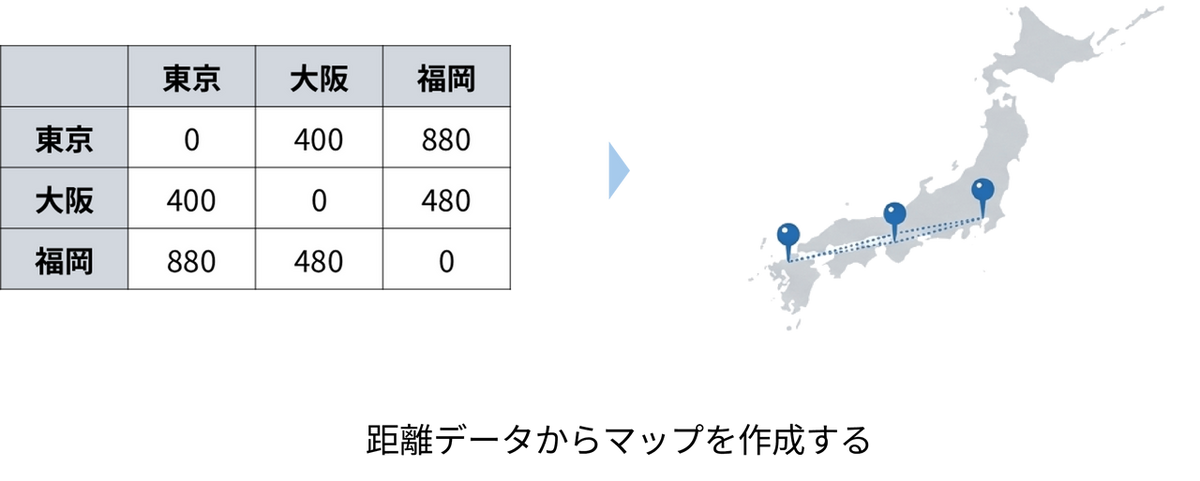
MDS の最大の目的は、データの背後に潜む構造や特性を明らかにし、視覚的に分かりやすくすることです。分析の結果として出力されるマップでは、似ている(類似度が高い/距離が近い)対象は近くに配置され、似ていない対象は遠くに配置されます。これにより、人間にとって直感的に対象同士の関係性を把握できるようになります。
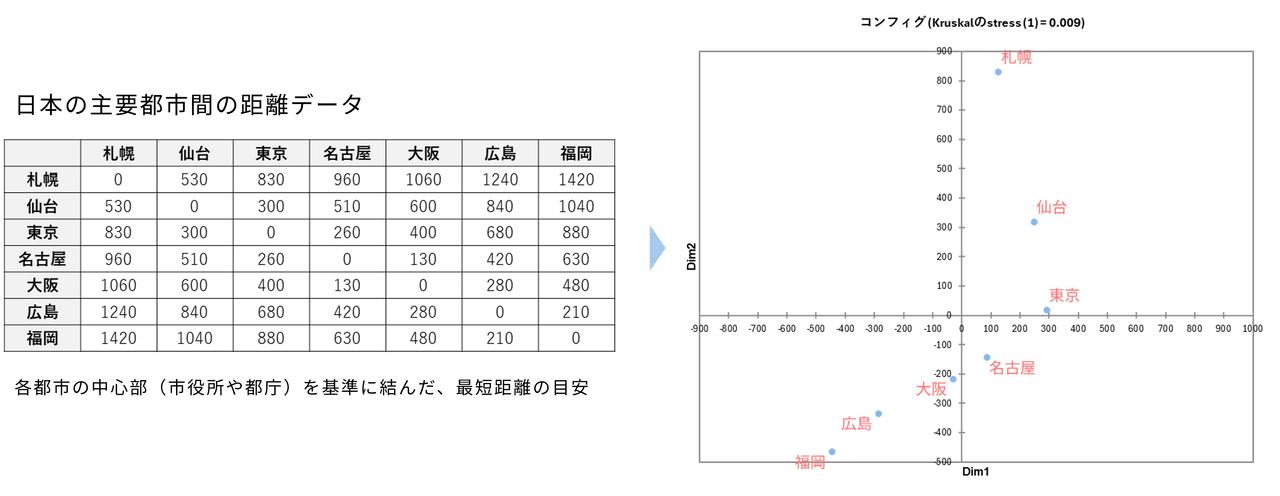
例えば、「東京〜大阪間は約400 km」「東京〜福岡間は約880 km」といった「移動距離の表」だけを渡されても、全体の都市の位置関係を直感的に把握するのは困難です。しかしMDS を使えば、この数値データだけで都市の配置図(地図)を自動的に描き出すことができます。
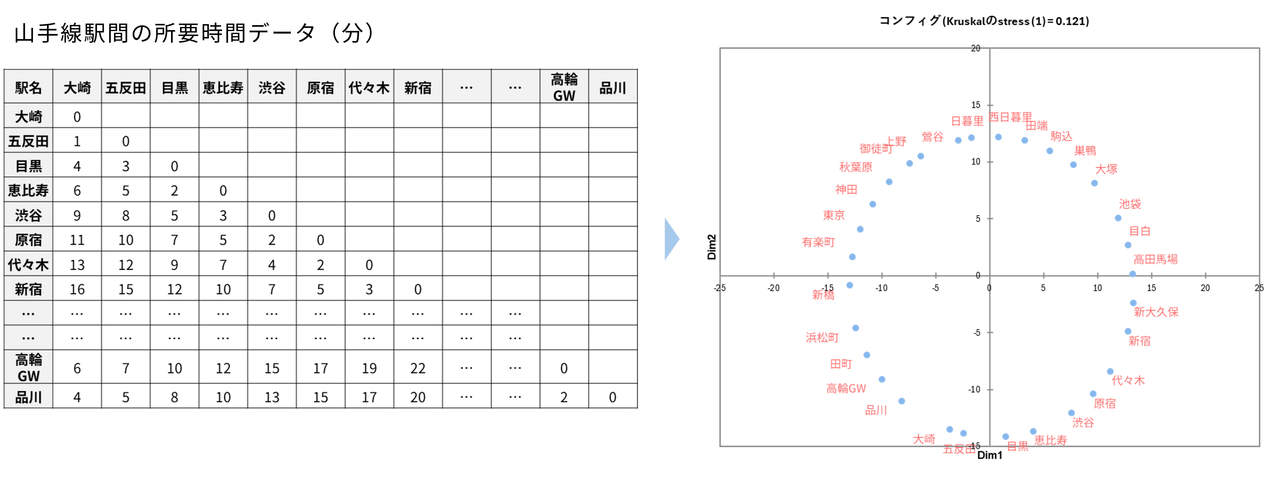
これをさらに分かりやすく示すのが、「JR 山手線の各駅間の所要時間」のデータを用いた例です。「東京駅から神田駅までは2分」「東京駅から新宿駅までは14分」といった駅間の所要時間(距離)の表をもとにMDS を実行すると、実際の地理的な位置情報を一切与えなくても、データ間の距離の整合性を保つように計算が行われ、結果として私たちがよく知っている山手線の丸い路線図(円形の配置)が再現されます。
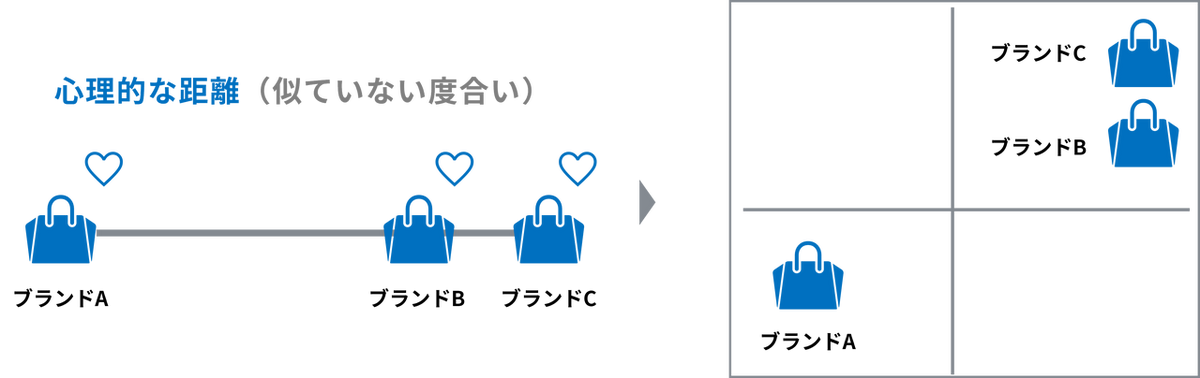
マーケティングの現場では、この「都市や駅間の距離」を「商品同士の似ていない度合い(非類似度)」に置き換えて応用します。アンケート結果などから商品間の距離を計算しMDS にかけることで、自社商品と競合商品が消費者の頭の中でどのような位置関係にあるのかをマップ化し、これにより、「消費者が各ブランドをどういう位置づけで捉えているか」などを直感的に把握できるようになります。
本ページでは、XLSTAT を使用して「多次元尺度法(MDS)」を実行し、消費者の頭の中にある商品のイメージを直感的なマップ(知覚マップ)として可視化する手順を解説します。
主成分分析との違い
データを要約して可視化する手法として「主成分分析(PCA)」も有名ですが、目的と入力するデータが異なります。
| 多次元尺度法(MDS) | 主成分分析(PCA) | |
| 主な目的 | 対象同士の「関係性(近さ・遠さ)」を可視化します。 | データの「ばらつき(情報量)」を保ったまま要約します。 |
| 入力データ | 個体間の「距離・類似度」データ | 個体の「各項目の測定値(生データ)」 |
| 得意なこと | 「似ている・似ていない」のポジショニング確認に適しています。 | たくさんの変数を「総合スコア」にまとめることに適しています。 |
MDS の種類
多次元尺度法(MDS)は、扱うデータの性質(距離の測定水準)によって、大きく「計量的MDS」と「非計量的MDS」の2種類に分けられます。
- 計量的MDS(古典的MDS / Metric MDS):
「AとBの距離は10km、AとCは20km」のように、数値の「大きさそのもの(間隔や比率)」に厳密な意味がある場合に使います。マップ上の距離においても、実際の数値を可能な限り正確に再現しようとします。 - 非計量的MDS(Non-metric MDS):
アンケートの5段階評価など、数値の大きさよりも「順位(ランキング・大小関係)」だけを重視する場合に使います。「AよりBの方が似ている」という順番さえ合っていれば、マップ上の距離が厳密に比例していなくてもよいとする柔軟な手法です。マーケティングの心理データなどではこちらがよく使われます。
XLSTAT で選択できる6つのモデル
XLSTAT では、元のデータとマップ上の距離をどれくらい厳密に合わせるかによって、6つのモデルから選択できます。
| MDS の種類 | モデル名 | 説明 |
| 計量 | 絶対 (Absolute) | マップ上(表現空間)で算出された距離が、元のデータ(非類似度行列)の距離の数値と「そのままの形で」できる限り一致するように配置します。 |
| 比率 (Ratio) | マップ上の距離が、元のデータの距離と「比例関係」に近づくように配置します(すべての距離のペアに対して、単一の比例定数が適用されます)。 | |
| 区間 (Interval) | マップ上の距離が、元のデータの距離と「線形関係(一次関数の関係)」に近づくように配置します(すべての距離のペアに対して、単一の線形関係が適用されます) | |
| 多項式 (Polynomial) | マップ上の距離が、元のデータの距離と「2次多項式の関係」に近づくように配置します(すべての距離のペアに対して、単一の多項式が適用されます)。 | |
| 非計量 | 順序MDS (1) (Ordinal) | マップ上の距離の順位が、元のデータの順位と一致するように配置します。ただし、元のデータに「同順位(タイ)」のものがある場合、マップ上の距離に特別な制限は設けられません。つまり、元データで同じ順位であっても、マップ上の距離が同じになるとは限りません(これをPrimary approach と呼ぶこともあります)。 |
| 順序MDS (2) / Ordinal (2) | マップ上の距離の順位が、元のデータの順位と一致するように配置します。さらに、元のデータに「同順位(タイ)」のものがある場合、マップ上の距離も「まったく同じ(等しい距離)」として配置されます(これをSecondary approach と呼ぶこともあります)。 |
チュートリアルで使用するサンプルデータ
本チュートリアルでは、新商品の開発を想定した実践的な分析シナリオで進めます。市場にある主要な飲料が消費者の頭の中でどのように位置づけられているか(似ている・似ていない)を視覚的なマップ(知覚マップ)にし、競合関係や市場の空き領域を見つけ出すことが目的です。
サンプルとして、架空の清涼飲料水9種について、消費者に10点満点で評価してもらったアンケートの平均値データ(生データ)を使用します。このアンケートデータから、XLSTAT の2つの機能を使ってマップを作成してみましょう。
【アンケート評価データ(10点満点)】

サンプルデータのダウンロードはこちらから
dataset-for-MDS.xlsmXLSTAT で多次元尺度法を実行する手順
事前準備:距離行列への変換
このデータ(5つの変数)のままではMDS を実行することができないため、まずは「飲料同士の距離」を計算し、MDS の入力に必要な「非類似度(距離)行列」に変換します。
-
XLSTAT のメニューから[発見、説明および予測] > [データ記述] > [類似度 / 非類似度行列 (相関)] を選択します。
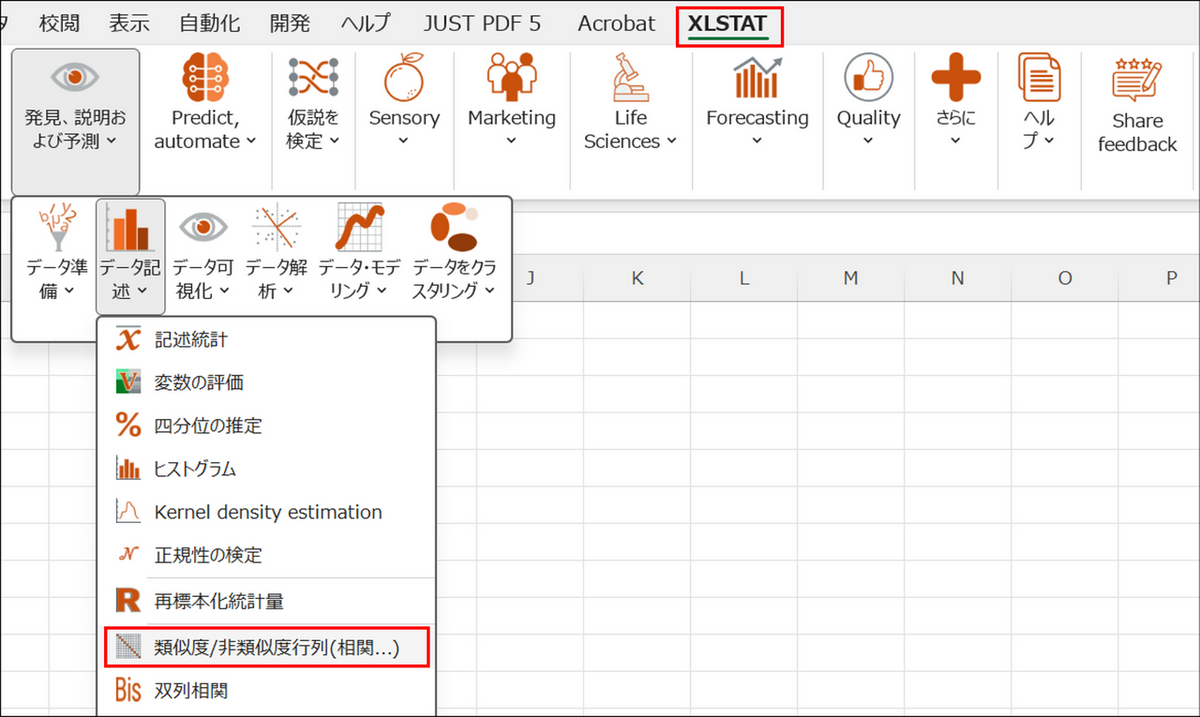
-
ダイアログボックスが開いたら、[一般] タブで以下の設定を行います。
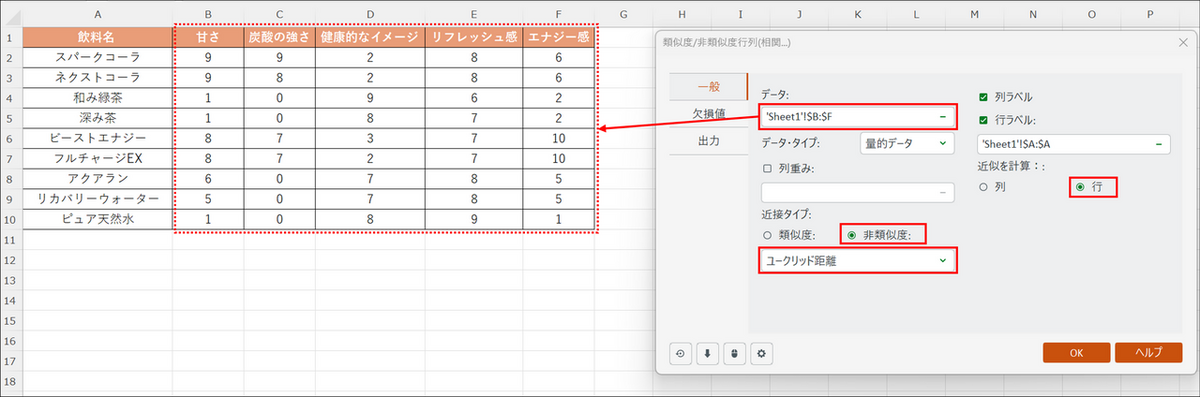
- データ:「甘さ」から「エナジー感」までのデータを見出しを含め選択
- データ・タイプ:[量的データ] を選択
- 近接タイプ:[非類似度] と [ユークリッド距離] を選択
- 列ラベル:先頭行を含めて選択した場合は、チェックを入れる
- 行ラベル:チェックを入れて、「飲料名」の列を選択
- 近似を計算:[行] を選択
-
[OK] をクリックして実行します。
出力された「親近度行列」が、次のMDS で使うデータとなります。

【補足】ユークリッド距離とは?
ユークリッド距離とは、私たちが日常的にイメージする「2点間の直線の距離(最短距離)」のことです。データ分析においては、複数の項目(変数)を持つデータ同士がどれくらい離れているかを、三平方の定理(ピタゴラスの定理)を応用して計算します。
【簡単な計算例(2変数の場合)】
仮に「甘さ」と「炭酸の強さ」の2項目だけで、飲料Aと飲料B の距離を計算してみましょう。
- 飲料A: 甘さ 8、炭酸 6
- 飲料B: 甘さ 5、炭酸 2
まず、それぞれの項目の差を求めます(甘さの差は3、炭酸の差は4)。
次に、それぞれの差を2乗して足し合わせ、ルート(平方根)をとります。
![]()
このようにして計算された「距離=5」が、飲料Aと飲料B の非類似度になります。今回のデータでは5つの項目(5次元)がありますが、XLSTAT が裏側でこれと同じ計算をすべての飲料ペアに対して行い、距離行列を作成してくれています。
多次元尺度法の操作手順
作成した距離行列をもとに、MDS を実行し、マップを作成します。今回は次元を減らすことによる情報の歪みを評価するため、4次元から2次元までまとめて計算します。
-
XLSTAT のメニューから [発見、説明および予測] > [データ解析] > [多次元尺度法 (MDS)] を選択します。
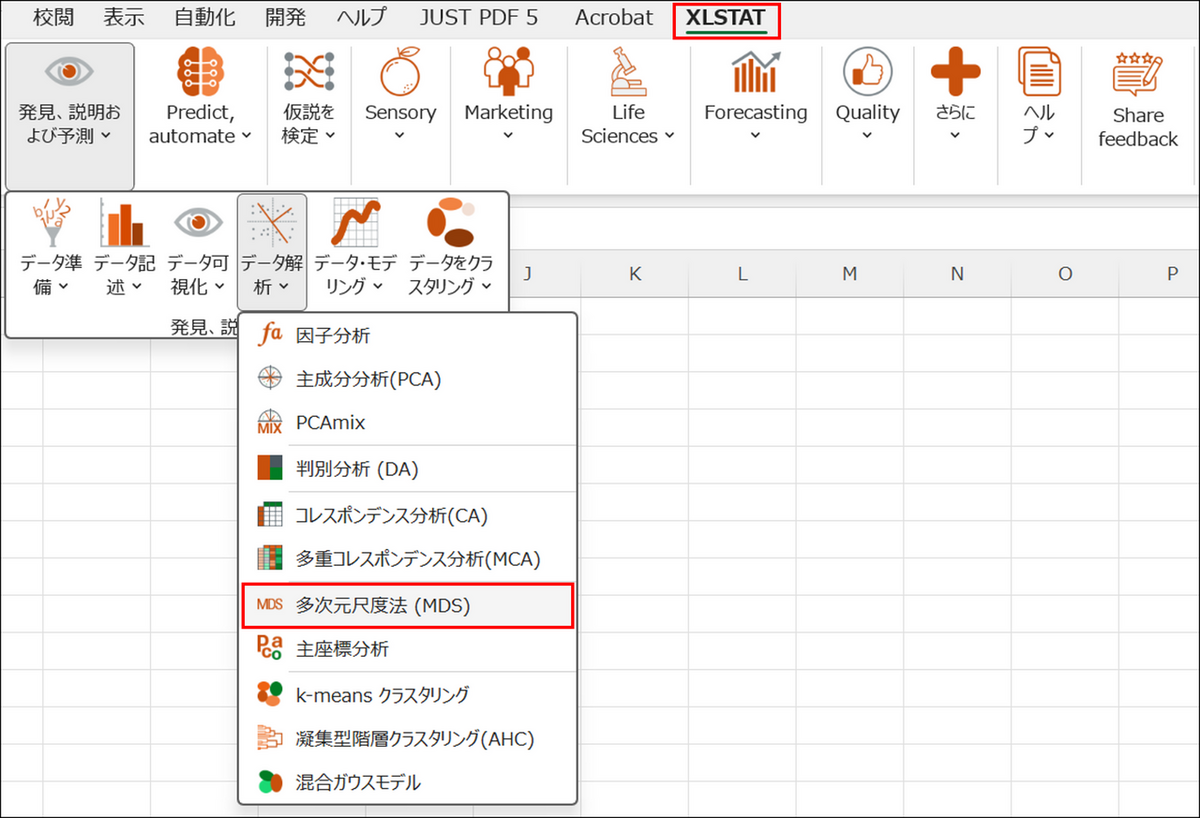
-
[一般] タブで以下のように設定します。
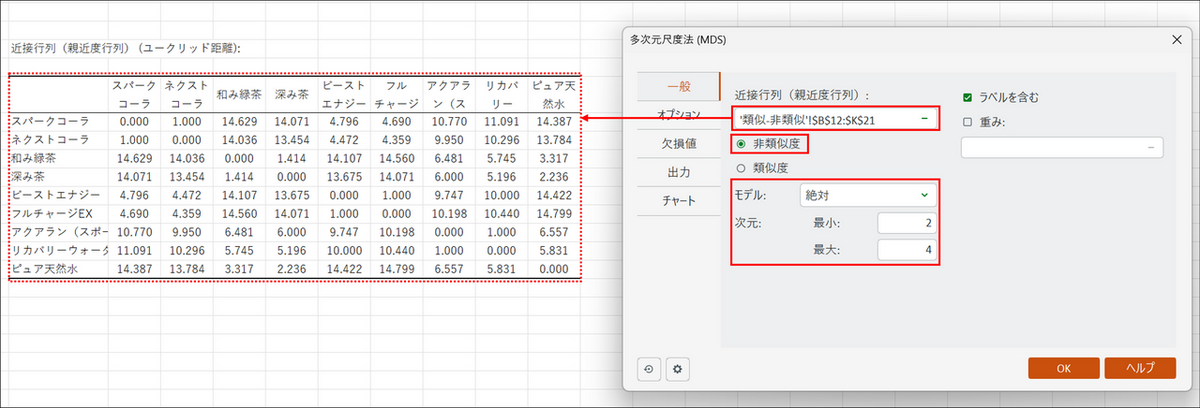
- 近接行列(親近度行列): 「近接行列(親近度行列)」の表を見出しを含めて選択
- [非類似度] を選択
- モデル:今回は元の距離スケールを維持するため[絶対] を選択
- 次元: 最小「2」、最大「4」と入力
- ラベルを含む:先頭行を含めて選択した場合は、チェックを入れる
-
[オプション] タブに切り替え、以下のように設定します。
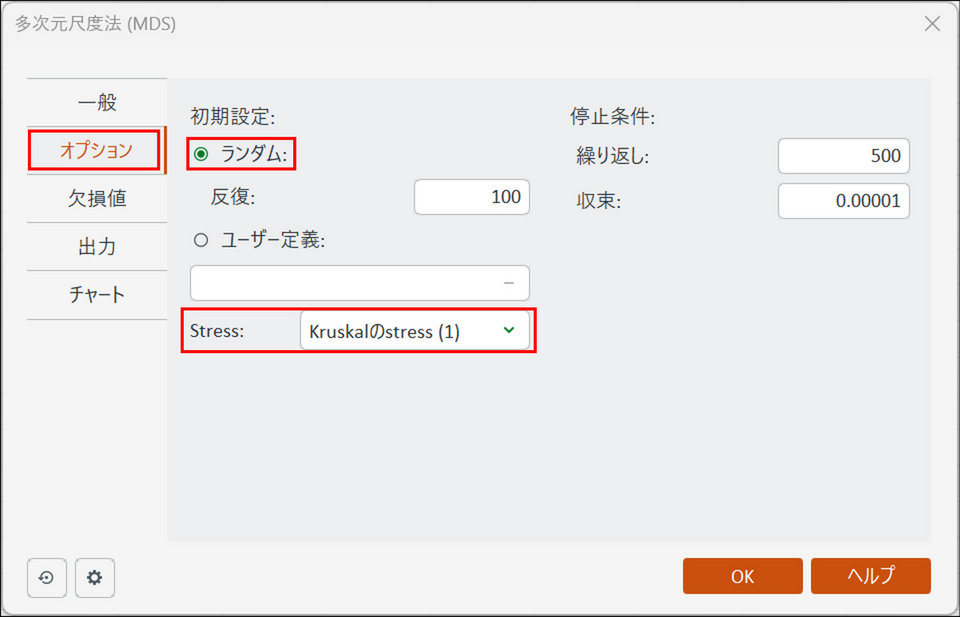
- 初期設定:[ランダム] を選択
- ストレス: [Kruskalのstress (1)] を選択
-
[出力] タブに切り替え、以下のように各項目にチェックを入れます。
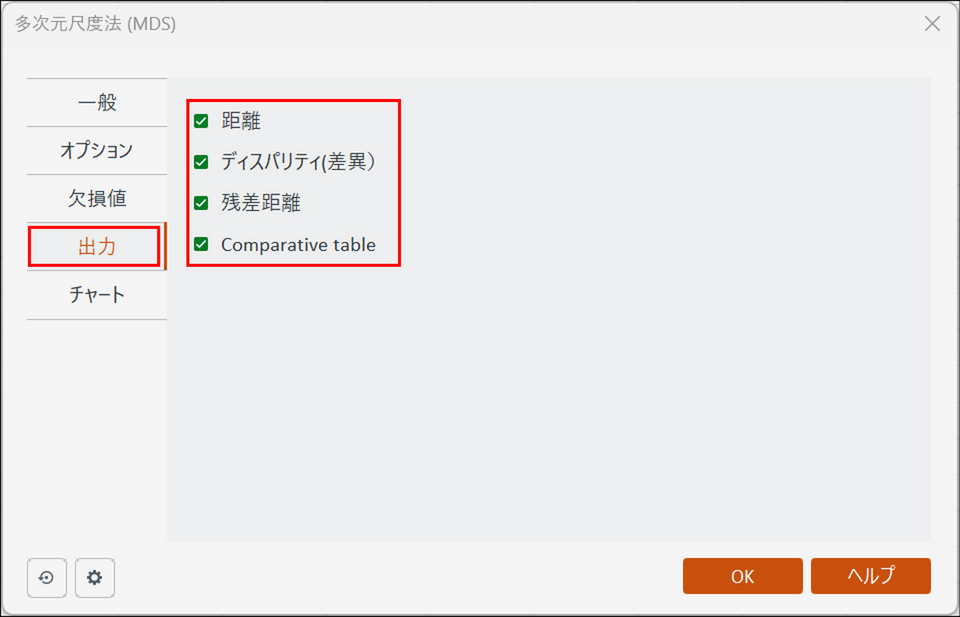
-
[OK] をクリックすると、結果が別シート(MDS)に出力されます。
【注意】初期配置と局所最適解について
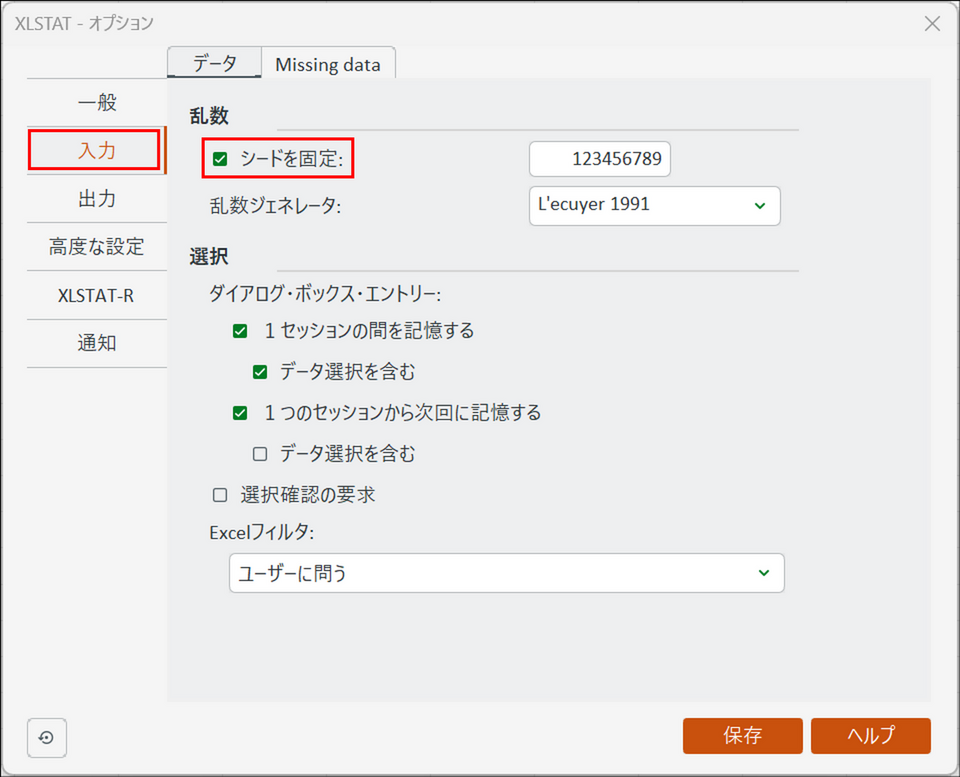
MDS はランダムな初期配置から計算をスタートして最適な配置を探すアルゴリズムです。そのため、実行するたびにマップの向き(回転・反転)が変わるだけでなく、初期値の違いによって異なる解(局所最適解)に収束し、最終的なストレス値やシェパード図、点同士の相対的な位置関係まで変化する可能性があります。もし、分析結果を完全に固定・再現したい場合は、XLSTAT のオプションを開き、[入力] タブの [シードを固定] にチェックを入れてください。
多次元尺度法の出力結果の解釈
ストレス値の推移
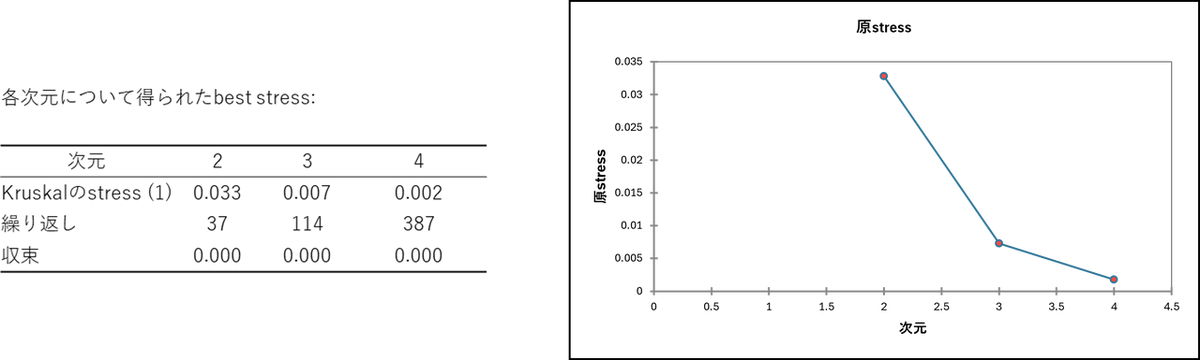
次元数ごとのストレスの表を確認します。ストレス値は、元の距離とマップ上の距離の「ズレ」を表し、0 に近いほど表現の精度が高いことを示します。
XLSTAT で出力される「Kruskal のストレス1」には、以下のような評価の目安があります。
- 0.2 以上:Poor(不十分)
- 0.1 〜 0.2:Fair(まあまあ / 許容範囲)
- 0.05 〜 0.1:Good(良い)
- 0.025 〜 0.05:Excellent(非常に良い)
- 0.00: Perfect(完璧)
今回の分析結果(表とグラフ)を見ると、2次元の段階でストレス値が「0.033」となっており、すでに「Excellent(非常に良い)」の基準をクリアしています。次元を3 や4 に増やすとストレス値はさらに0 に近づきますが、直感的に理解しやすいのは2次元の平面マップです。したがって、今回のデータは無理に3次元にしなくても、2次元の知覚マップで十分に正確な関係性を表現できていると判断できます。
知覚マップ
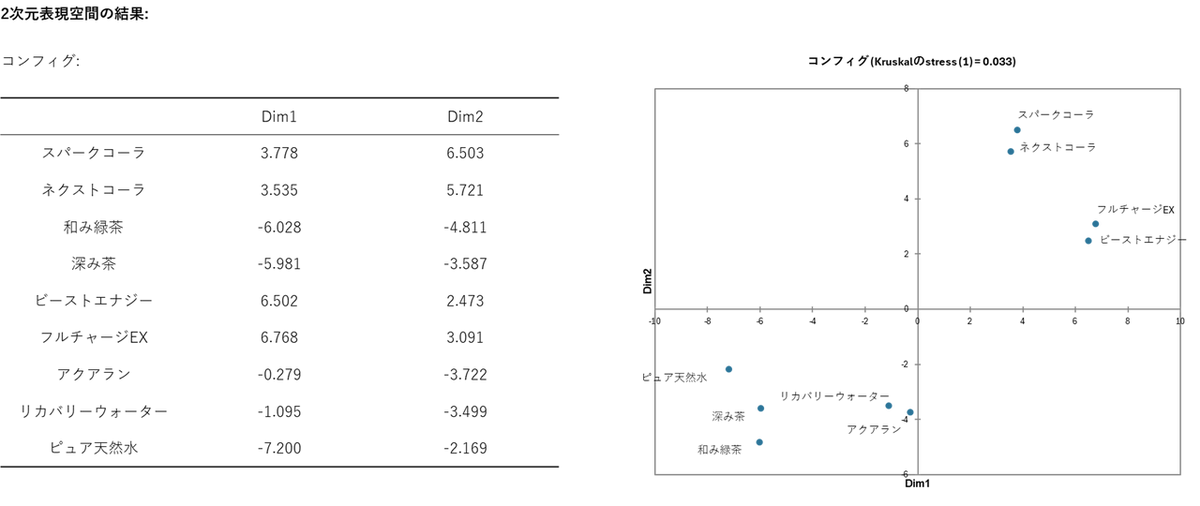
2次元の散布図(知覚マップ)を確認します。MDS が自動で計算した軸(Dim1, Dim2)には最初から意味は設定されていません。配置された商品の関係性から、分析者自身が軸の意味を解釈する必要があります。
軸の意味付け(解釈):
- 横軸(Dim1):
右に「コーラ」や「エナジー飲料」、左に「お茶」や「天然水」が配置されています。元データと照らし合わせると、横軸は「刺激・甘さ(右) ⇔ 健康・すっきり(左)」という価値観を表していると解釈できます。
- 縦軸(Dim2):
上に「コーラ」、下側に「お茶・スポーツ飲料・水」が配置されています。コーラ系は炭酸が強く、下部の飲料は炭酸が0であることから、縦軸は「炭酸の強さ/嗜好性(上) ⇔ 日常的な水分補給(下)」を表していると考えられます。
競合関係のグループ化:
マップ上で距離が近い商品は、消費者に「似ている」と認識されており、直接的な競合関係にあることを示します。今回の結果からは、「コーラ」「エナジー飲料」「緑茶」の各カテゴリ内で商品が極めて近い位置にグループ化されており、それぞれ激しい代替競争やブランドの差別化といった課題が読み取れます。
市場のホワイトスペース(空白地帯)の探索:
マップ上で商品が存在しない空いた領域は、新商品の狙い目となる可能性があります。
- 左上のエリア:
「健康・すっきり(左)」でありながら「炭酸が強い(上)」ポジションが空いています。ここは「健康志向の無糖強炭酸水」などの新商品が入り込む余地(ホワイトスペース)であるという仮説が立てられます。 - 右下のエリア:
「甘さやエネルギー(右)」がありつつ「炭酸がない(下)」ポジションです。エネルギー補給ができる非炭酸ゼリー飲料などが考えられます。
シェパード・ダイアグラム
シェパード・ダイアグラムは、横軸に「実際のアンケートの距離」、縦軸に「マップ上の距離」をプロットしたものです。点が直線状に並んでいるほど、マップが元のデータを正確に再現できていることを示します。
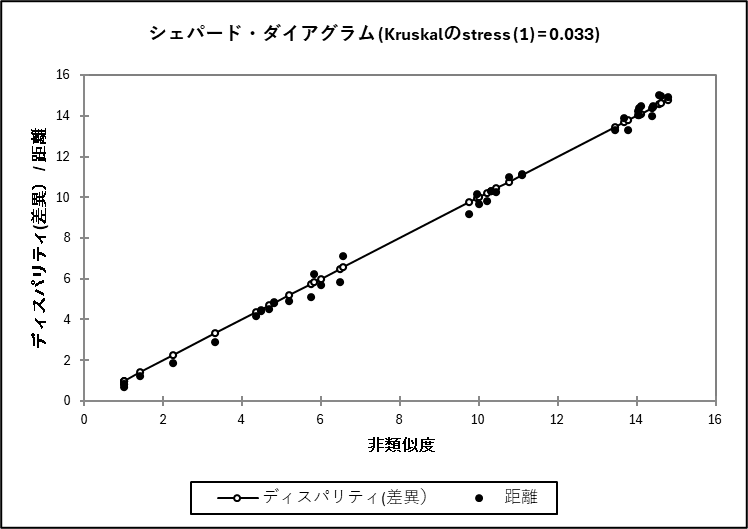
出力されたシェパード・ダイアグラムを見ると、黒い点(マップ上の距離)が、直線(理想的な距離=ディスパリティ)に沿って非常に綺麗に並んでいることがわかります。
例えば、比較表のデータを見ると「スパークコーラ」と「ネクストコーラ」の元の非類似度は 1.000 に対し、マップ上の距離も 0.819 と非常に近い値が保たれています。

全体を通して点が直線から大きく外れてばらついていないため、2次元のマップに落とし込んでも、データの位置関係(遠近感)が歪むことなく、極めて高い精度で再現されていると解釈できます(ストレス値が 0.033 と非常に優秀だったことの裏付けにもなっています)。
3次元データの可視化(3D Plot)
2次元のマップでは重なって見えた商品も、3次元の視点を持つことで全く異なる特徴を持っていることが判明する場合があります。XLSTAT の3D Plot 機能(Windows 版の有料オプション)を使用すると、3D 空間での可視化も可能です。
-
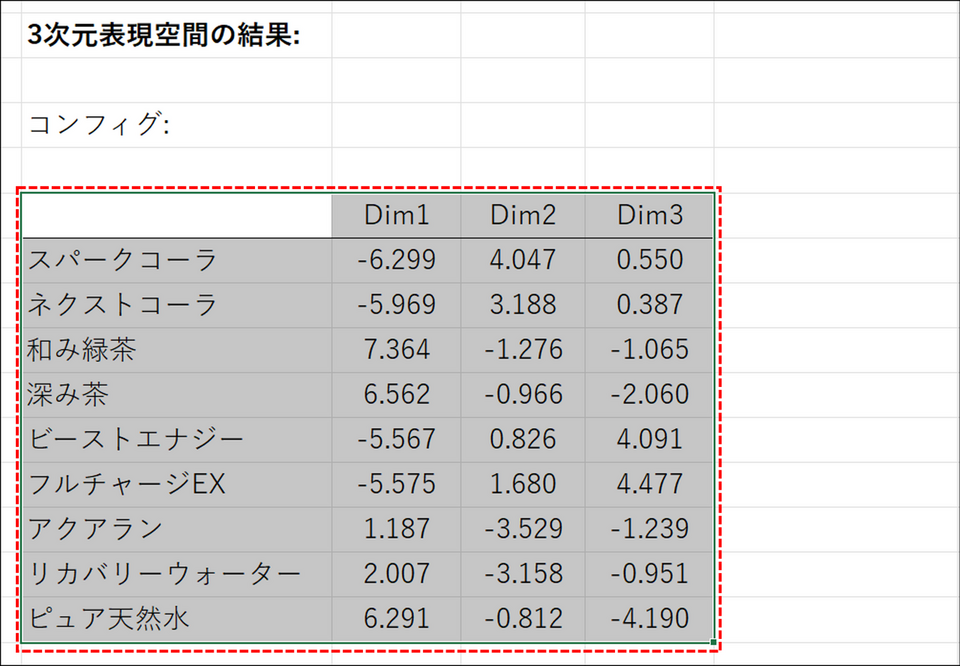
「3次元表現空間の結果」に表示される座標データの表を選択します。
-
XLSTAT メニューの [さらに] から [XLSTAT-3DPlot] > [XLSTAT-3DPlot] を選択します。
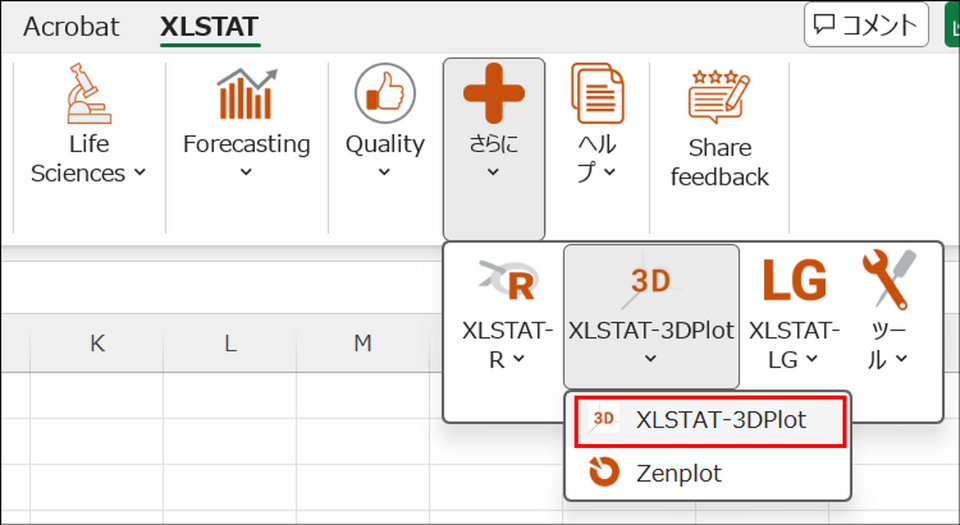
-
表示された画面で[テーブル] を選択して [OK] をクリックします。
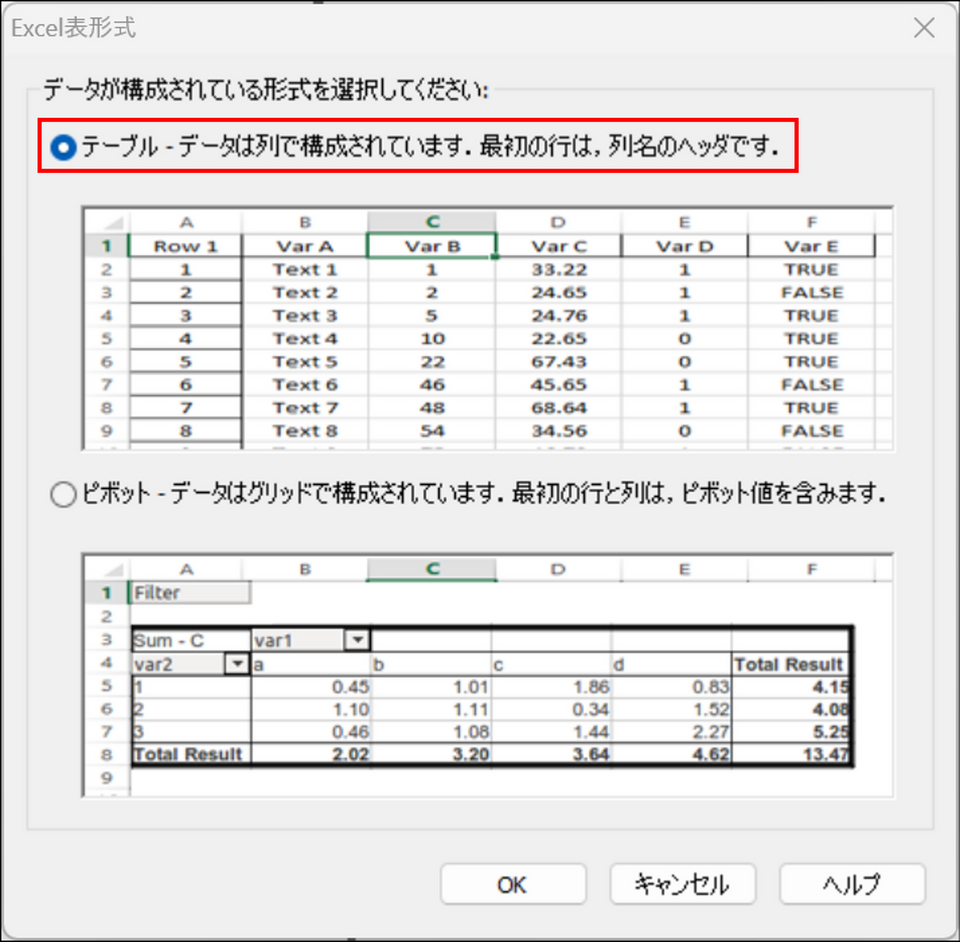
-
3Dプロットの画面が立ち上がったら、メニューの「軸」タブを開き、以下のようにX, Y, Z 軸のデータを設定します。
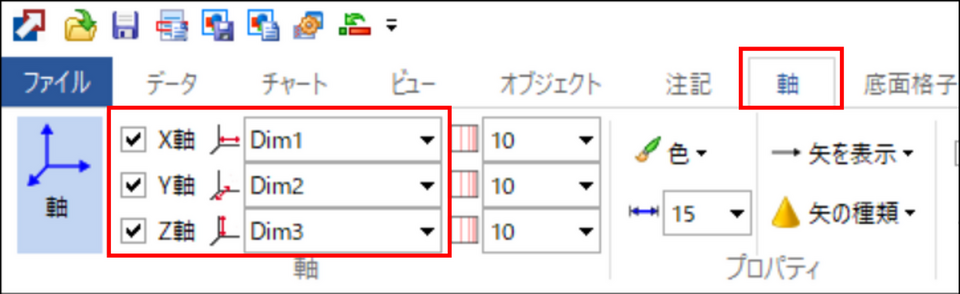
- X軸: Dim1 の列を指定
- Y軸: Dim2 の列を指定
- Z軸: Dim3 の列を指定
-
「注記」タブを開き、左上のプルダウンメニューで [Column1] を指定することでデータポイントに名前を表示させることができます。
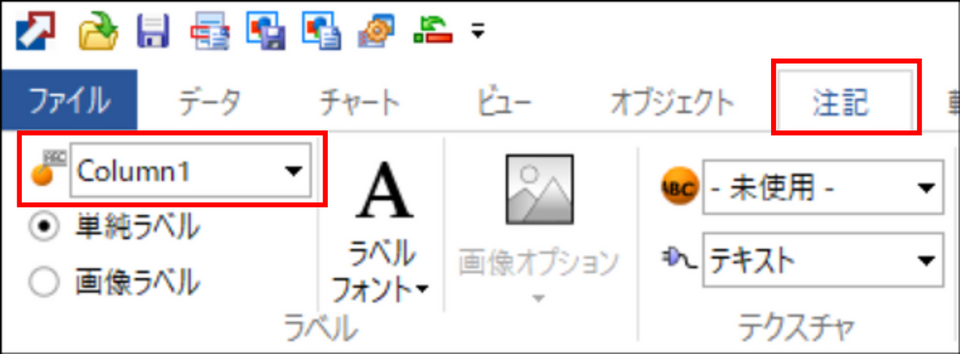
-
ラベルフォントをクリックすると、フォントの種類やサイズを変更できます。
【補足】表示の更新について
XLSTAT-3DPlot の仕様上、ツールを起動した直後や、タブで設定を変更した直後は、グラフエリア(描画領域)を一度クリックしないと画面に表示が反映されない場合があります。画面が真っ白な場合や変更が反映されない時は、まずグラフの上でクリックをお試しください。
そのほかのオプション設定
オブジェクトタブ:
- 色付け:
商品の「カテゴリ区分」などの列データを持っていれば、それを指定することでグループごとに色分けが可能です。
- サイズの変更:
売上規模や特定の指標(貢献度など)のデータを指定して、バブルの大きさを値に比例させることができます。
格子タブ:
3D空間での遠近感や位置関係を把握しやすくするため、底面(Dim1/Dim2 の平面など)に格子状のグリッドを追加することもできます。
視点の移動:
マウスの右クリックを押しながらドラッグしてグラフを回転させ、最も全体像が把握しやすい角度を探します。マウスホイールで拡大・縮小も可能です。
3Dプロットの解釈
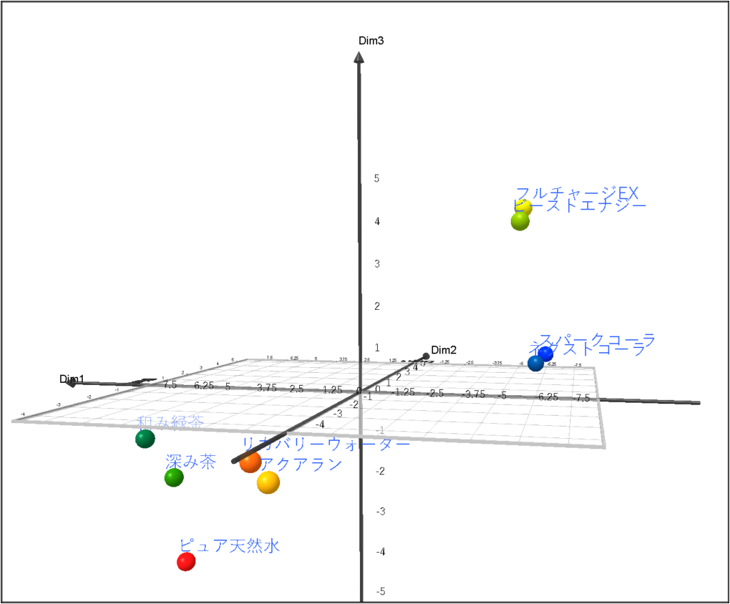
高さを表す第3の軸(Dim3)を確認すると、商品群が縦方向に綺麗に層として分かれていることがわかります。
- 最上部: エナジー飲料(フルチャージEX、ビーストエナジー)
- 中上部: コーラ(スパークコーラ、ネクストコーラ)
- 中下部: スポーツ飲料・緑茶(リカバリーウォーター、和み緑茶など)
- 最下部: 天然水(ピュア天然水)
元のアンケートデータと照らし合わせると、この高さ(Dim3)は「エナジー感(機能的な強さ)」を表していると解釈できます。2次元マップの「甘さ」や「炭酸」の軸に加えて、「機能的価値の高さ」というもう一つの次元で市場を捉え直すことで、さらに多角的な競合分析が可能になります。
まとめ
多次元尺度法(MDS)は、アンケートなどの多変量データを視覚的なマップに変換することで、基礎的な集計だけでは見えにくい「商品間の相対的なポジション」や「市場の空白地帯」を明らかにする分析手法です。XLSTAT を使えば、使い慣れたExcel 上でデータの性質に合わせたモデルの選択から、距離行列の作成、MDS の実行、精度の評価までをシームレスに行うことが可能です。
参考文献
- XLSTAT: Multidimensional Scaling (MDS) in Excel
- 奥 喜正, 髙橋 裕: データ解析の実際 多次元尺度法・因子分析・回帰分析, 丸善プラネット株式会社, 2013.
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介した多次元尺度法(MDS)はStandard と Advanced のライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。
