XLSTAT による一般化プロクラステス解析:評価者のクセを補正して製品のコンセンサスマップを作成しよう
- 一般化プロクラステス解析とは?
- フリーチョイスプロファイリングとの関係
- 一般化プロクラステス解析を実行するためのデータセット
- XLSTAT で一般化プロクラステス解析を実行する手順
- 出力結果の解釈
- まとめ
- 参考文献
- XLSTAT の無料トライアル
一般化プロクラステス解析とは?
一般化プロクラステス解析(Generalized Procrustes Analysis、以下GPA) とは、複数の評価者から得られた官能評価データを統合し、評価者ごとの採点のクセを取り除いた上で、全員の見方をまとめた「コンセンサスマップ」を導き出す多変量解析手法です。官能評価や感性評価の分野で、製品の特徴を客観的に把握するために広く使われています。
官能評価では複数のパネリスト(評価者)に製品を評価してもらい、「甘味」「酸味」「硬さ」といった項目に点数をつけてもらいますが、人によって、点数のつけ方にクセが出るという課題があります。
- Aさんは、どんな項目についてもどんな製品に対しても高めの点数をつける「甘め採点」タイプ(たとえば基本的に7〜9点をつける)
- Bさんは、よほどのことがない限り4〜6点の狭い範囲しか使わない
- Cさんは、1~9点の広い範囲で点数をつける

こうしたクセを放置したまま単純に全員の平均を取ると、製品本来の特徴が見えなくなってしまいます。全体的に高めの点数をつける人が大勢いれば、どの製品もどの項目も「評価が高い」という結果になってしまいますし、厳しく採点する人が多ければ、全体的に「パッとしない」結果になってしまいます。これでは正しい商品開発の判断ができません。
そこでGPA では、次の3つの幾何学的変換を順番に適用し、こうした評価者のクセを統計的に補正します。
- 平行移動(Translation):全体的な甘め/辛め採点のバイアスを補正
- スケーリング(Scaling):評点尺度を広く使う/狭く使うの違いを補正
- 回転(Rotation):項目の軸の向きの微妙なズレを補正
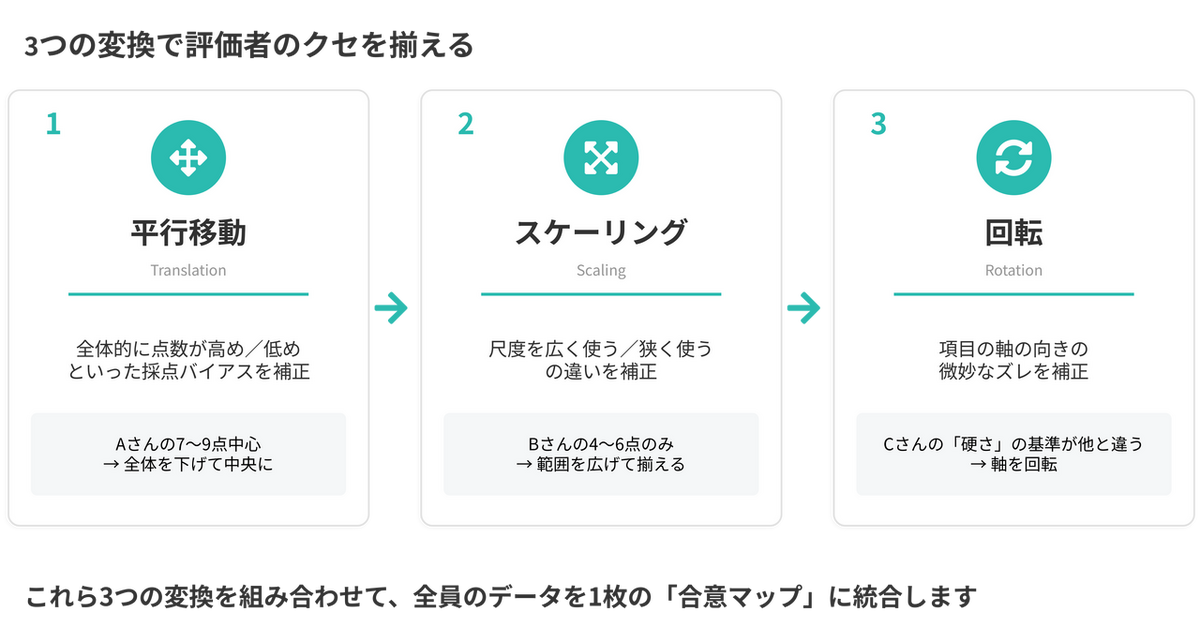
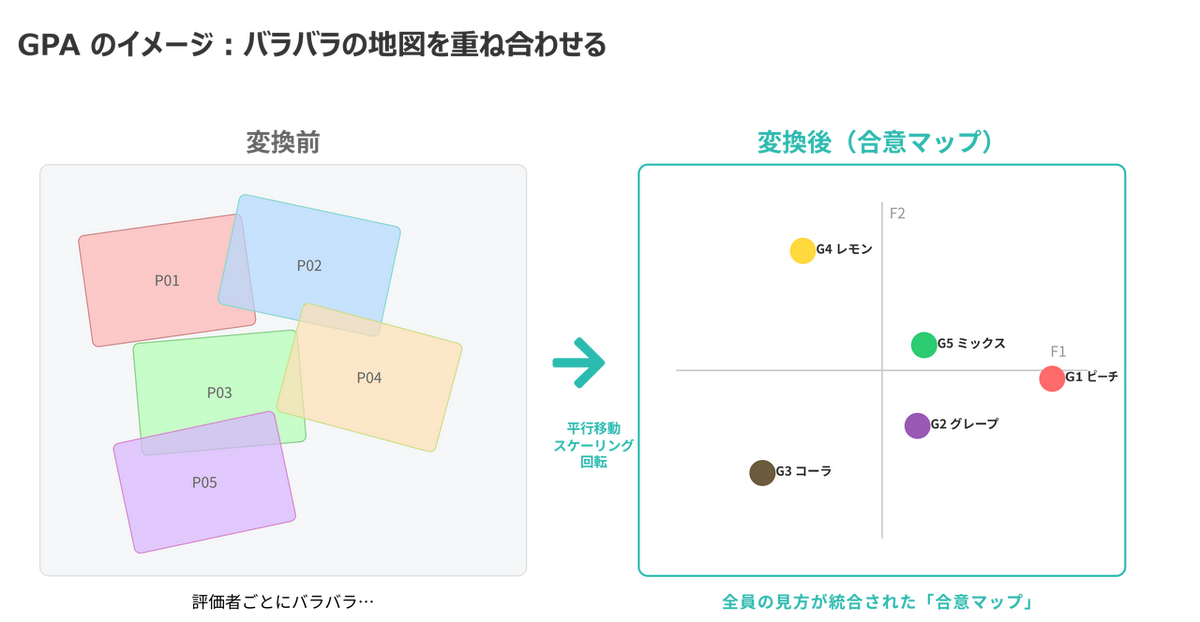
これらの変換によって、評価者ごとにバラバラだった「製品の配置図」をぴったり重ね合わせ、全員の見方を統合した1枚のコンセンサスマップ(コンセンサス・コンフィギュレーション) を作り出します。
イメージとしては、10人が描いた「似ているけど少しずつズレた地図」を、ずらしたり、伸縮させたり、回転させたりして、ぴったり重なるように調整していく作業です。重ね合わせた結果として浮かび上がる「みんなの見方の共通部分」こそが、製品の本当の姿と言えます。
コラム:「プロクラステス」~ 名前の由来はギリシャ神話の強盗
ギリシャ神話に登場する「プロクルーステス」は、通りがかった旅人を自分の鉄のベッドに寝かせ、相手の体がベッドからはみ出せばその部分を切り落とし、ベッドより短ければ長さに合うまで無理やり身体を引き伸ばしたという逸話をもつ人物です。一般化プロクラステス解析では、比較したいデータを拡大・縮小、回転、平行移動させて基準となる形にぴったりと合わせる処理を行います。この「対象のサイズや向きを補正して、特定の枠に一致させる」という数学的な操作が、プロクルーステスの神話のモチーフと似ていることから、その名が冠されています。

フリーチョイスプロファイリングとの関係
GPA(一般化プロクラステス解析)が特によく使われる手法のひとつにフリーチョイスプロファイリング(Free Choice Profiling、以下FCP) があります。一般化プロクラステス解析は、もともとFCP のように「評価者ごとにデータの構造が異なる」状況を扱うために開発された背景を持ちます。
通常の記述的官能評価(QDA など)では、すべての評価者が 同じ用語・同じ尺度 を使う必要があります。例えば「甘味」「酸味」「苦味」という決められた項目を、全員が共通の定義に基づいて採点します。そのためには長時間の訓練が必要で、用語の意味合わせにも手間がかかります。一方、FCP では、各評価者が自分自身の言葉で自由に製品を表現することができます。
- Aさんは「フルーティー」「まろやか」「後味キレ」の3項目で評価
- Bさんは「華やか」「渋い」「ボディ感」「余韻」の4項目で評価
- Cさんは「軽い」「爽やか」「甘い香り」の3項目で評価
このように、評価者ごとに使う言葉も項目数もバラバラになるのがFCP の特徴です。訓練不要で一般消費者も参加しやすく、率直な感じ方を拾えるメリットがある一方で、従来の平均や主成分分析ではデータを統合できないという難しさがあります。
ここでGPA が活躍します。GPA は各評価者のデータを座標として扱い、平行移動・スケーリング・回転で重ね合わせることで、使っている言葉や項目数が違っても、全員の見方を1枚のコンセンサスマップに統合できます。
このような「評価者ごとに異なるデータ構造」を統合して共通傾向を可視化するために、GPA はFCP 解析の代表的な手法としてよく用いられています。なお、FCP データの解析にはSTATIS などの多変量解析手法が用いられることもあります。
今回のチュートリアルでは全員が同じ項目で評価したシンプルなデータを使いますが、GPA の真価が発揮されるのは、こうしたFCP のような個人差が大きいデータの統合場面になります。
一般化プロクラステス解析を実行するためのデータセット
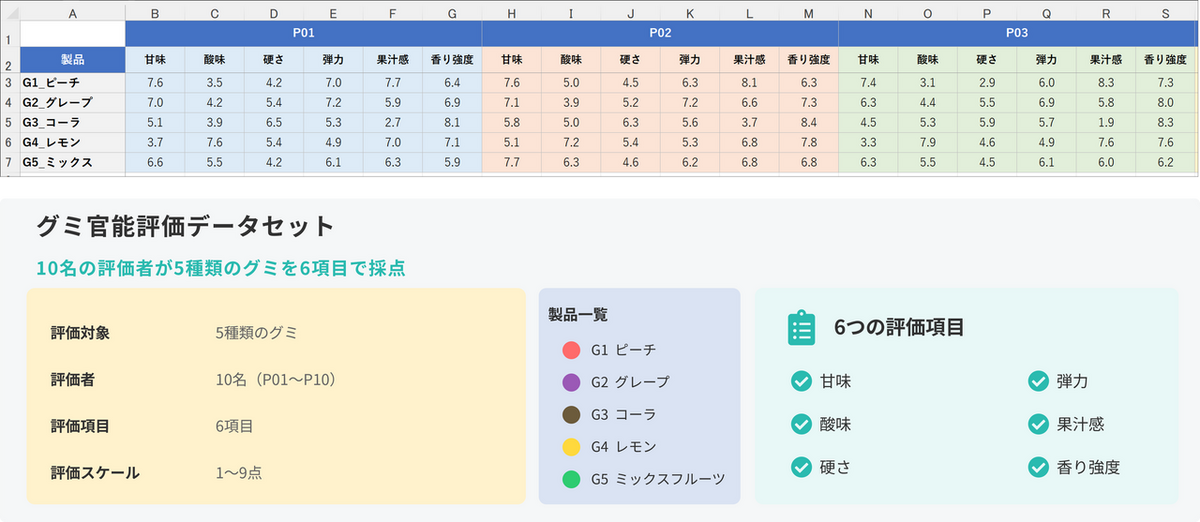
今回は、グミの官能評価データセットを使ってGPA を実行していきます。
サンプルデータのダウンロードはこちらから
dataset-for-GPA.xlsmこのデータセットでは10名の評価者が、5種類のグミについて6つの評価項目をすべて共通で採点しています。評価項目も尺度も全員共通なので、GPA による評価者のクセの補正が素直に適用できるシンプルな構造になっています。XLSTAT でGPA を実行するには、データを横並び形式で配置する必要があります。
- 行:各製品(5行)
- 列:評価者ごとに6項目がまとまって並ぶ(10名×6項目=60列)
つまり、「評価者P01 の6項目、続いてP02 の6項目、続いてP03 の6項目……」というように、評価者1人分のブロックを横に10個並べた形です。先頭列には製品ラベルを入れておきます。
なお、このデータセットには、下記の通り、GPA で検出されるような評価者のクセが意図的に含まれています。
- ある評価者は尺度を狭く使い(3〜7点の範囲)、別の評価者は広く使う(1〜9点の範囲)
- ある評価者は全体的に点数が高め(甘め採点)、別の評価者はやや辛め
- 項目によって「強く感じる/弱く感じる」の個人差もある
こうしたクセがGPA の結果にどう反映されるかを見ることで、手法の実力を実感できるデータセットになっています。
XLSTAT で一般化プロクラステス解析を実行する手順
-
XLSTAT を起動し、[Sensory] > [官能プロファイリング] > [一般化プロクラステス分析] を選択します。
-
[一般] タブで以下のように設定します。
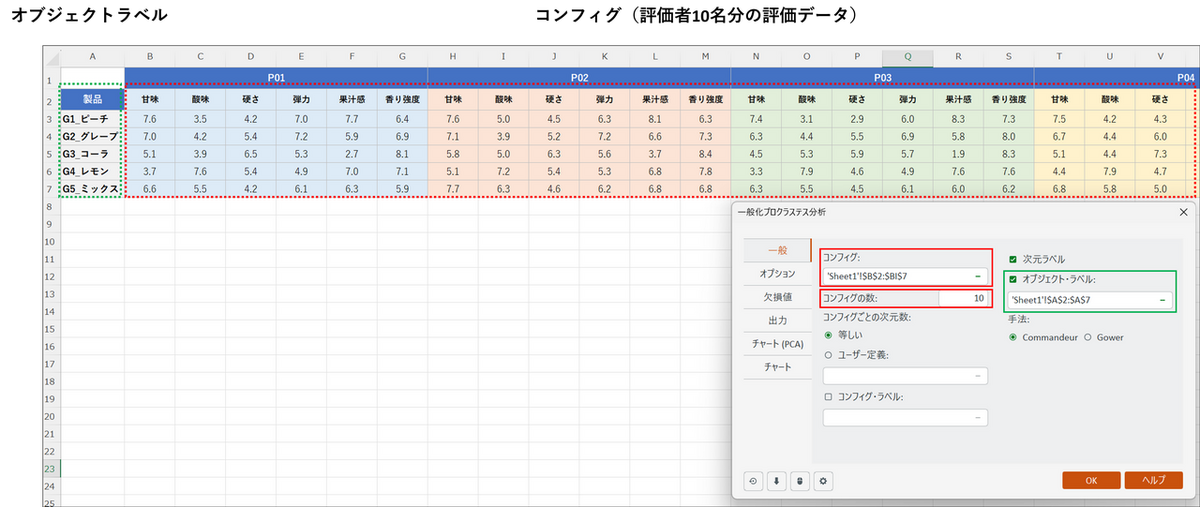
- コンフィグ:
データ範囲を選択します。今回は各評価者の6項目×5製品のブロックを、10名分すべて含む範囲を指定します。 - コンフィグの数:
「10」と入力します(評価者が10名のため)。 - 次元の数:
今回は全員が同じ6項目で評価しているので、[等しい] を選択します。 - オブジェクト・ラベル:
チェックを入れ、製品名を指定します。
【補足】補足:評価者ごとに項目数が異なる場合の設定
フリーチョイスプロファイリング(FCP)のように、評価者ごとに使用する項目の数が異なるデータを扱う場合は、「ユーザー定義」 を選択します。「ユーザー定義」を選択すると、その下のデータ範囲指定欄が有効になります。ここには、各コンフィグ(評価者)の次元数を1列に並べたセル範囲を指定します。例えば、4人の評価者がそれぞれ3項目、5項目、4項目、6項目で評価した場合、Excel シート上のセルに縦方向に「3, 5, 4, 6」と入力し、その範囲を列名を含めて指定します。

このとき、データの横並び配置も評価者ごとのブロック幅が異なる点に注意してください。評価者1は3列分、評価者2は5列分……というように、各ブロックの列数がその評価者の項目数と一致している必要があります。GPA は次元数の異なるコンフィグ同士でも変換・統合が可能なので、FCP のように自由度の高いデータでも問題なく解析できます。
- コンフィグ:
-
[オプション] タブに切り替え、以下のように設定します。
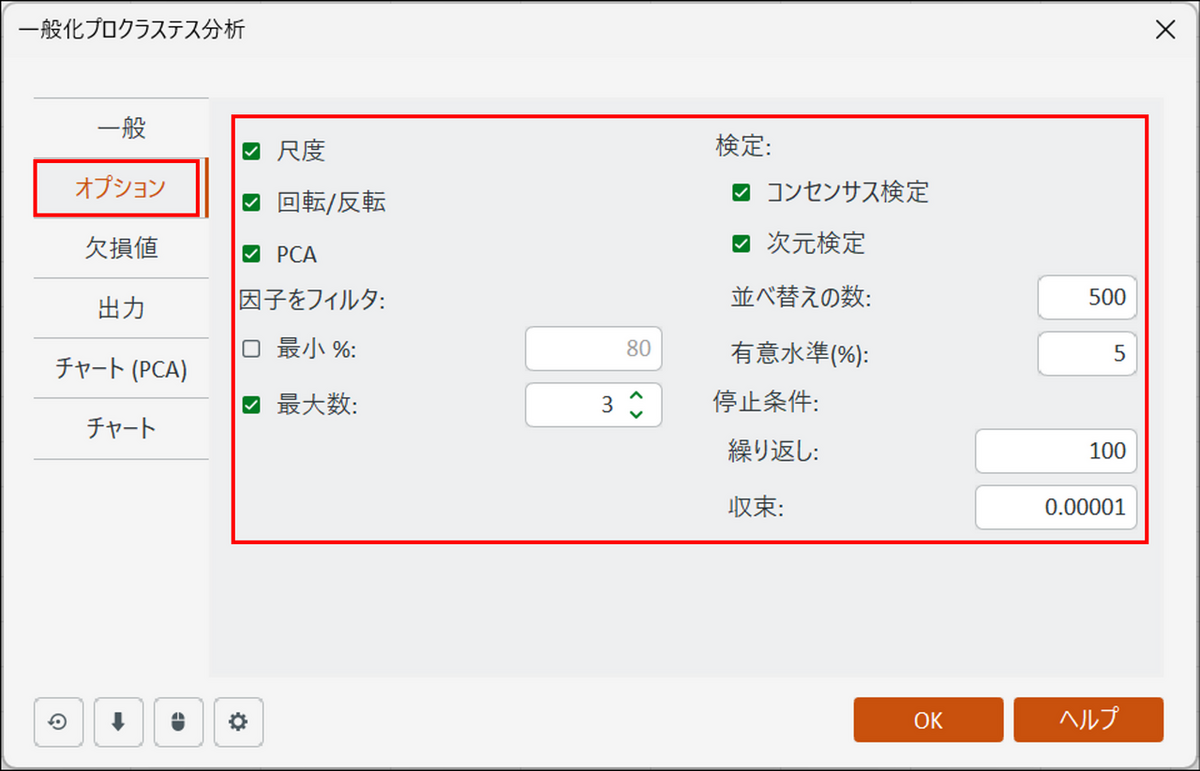
-
[出力] タブに切り替え、以下のように設定します。
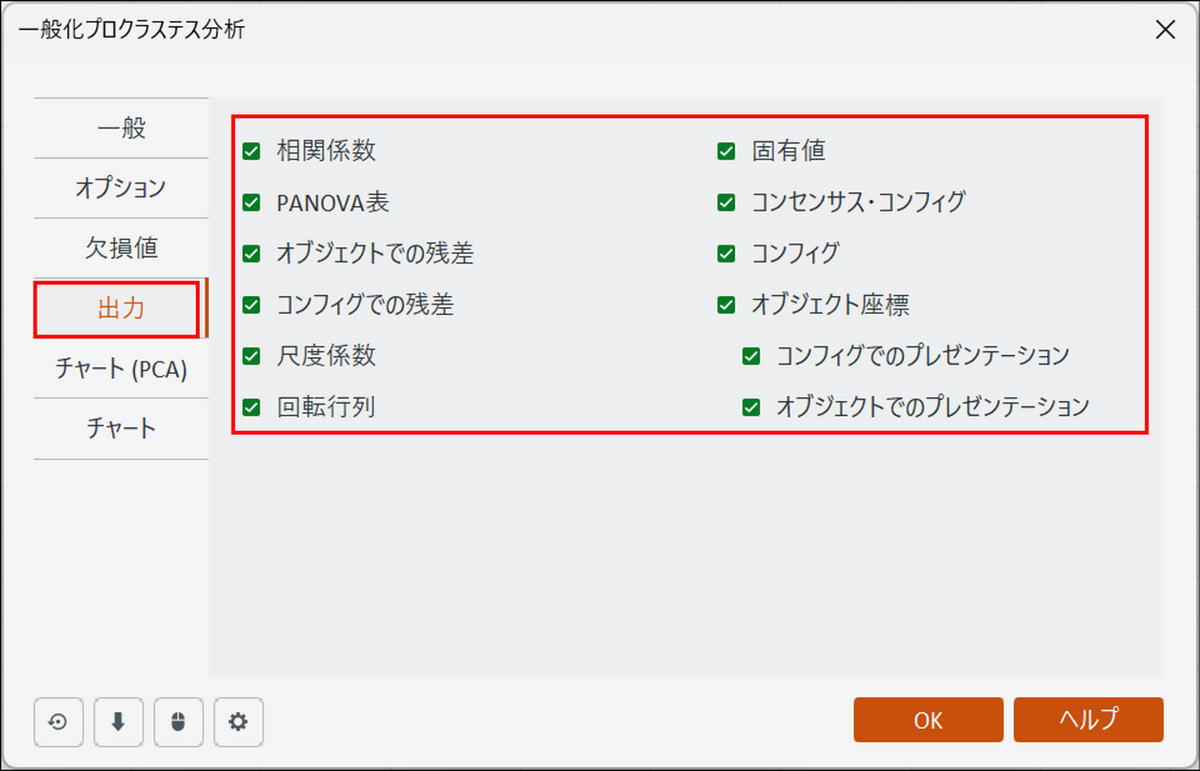
-
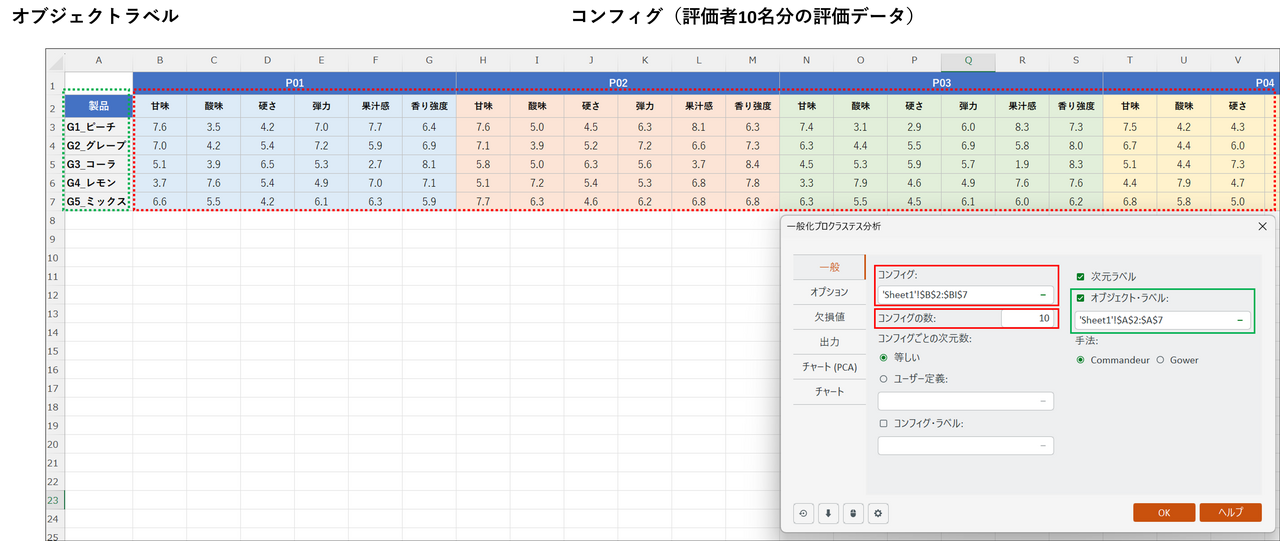
[OK] ボタンをクリックすると計算が始まり、結果が別シート(GPA)に出力されます。
出力結果の解釈
結果には多くの表やグラフが出力されますが、注目すべきポイントは6つです。順番に見ていきましょう。
① PANOVA 表:どの変換が効いたか
PANOVA(Procrustes ANOVA)表は、データの全体のばらつき(分散)を減らすことに対して、 平行移動・スケーリング・回転の3つの変換がそれぞれどれだけ効果があったのかを示しています。p値が0.05 以下であれば、その変換が統計的に有意に効いたと判断できます。
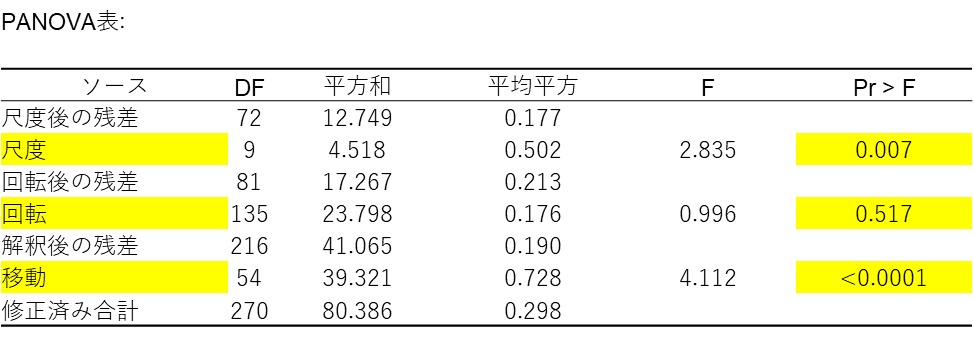
- 尺度: p値 = 0.007 → 有意に効いた
- 回転: p値 = 0.52 → 効いていない
- 移動: p値 ≈ 0 → 有意に効いた
今回のデータでは、評価項目(言葉)の定義や意味については全員の認識が揃っていた(回転不要)が、採点の甘辛(移動)や点数幅の広さ(尺度)には個人のクセが強く出ていたため、GPA による補正が有効に機能していたことが示されています。
② オブジェクト別残差:どの製品で評価者の意見が揃ったか
残差が小さい製品ほど、評価者の意見が揃っていることを意味します。
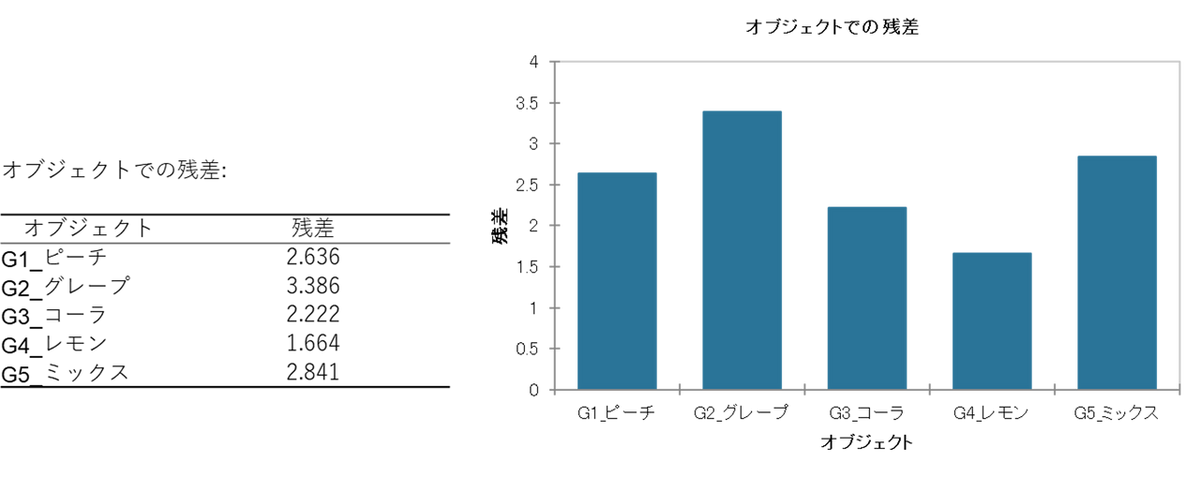
「誰が食べても明らかに酸っぱいレモン」のような尖った特徴を持つ製品は評価が揃いやすく、「中庸な味のグレープ」のような特徴の弱い製品は評価が割れます。商品開発の観点では、特徴が薄い製品は消費者にも印象が弱い可能性があるという示唆が得られます。
③ コンフィグ別残差:どの評価者がコンセンサスから外れているか
残差が大きい評価者ほど、他の人と違う評価をしている可能性があります。
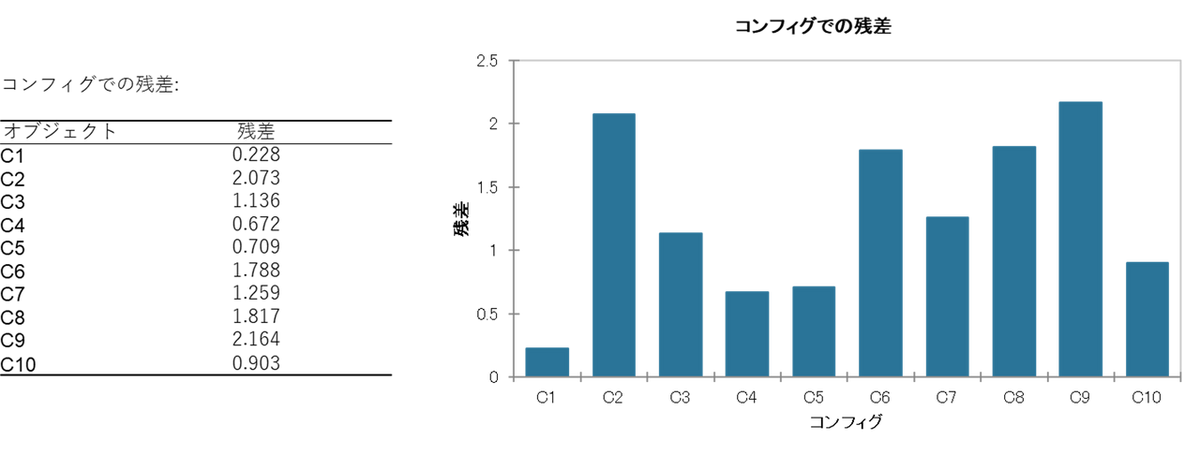
- 残差最小:C1(P01)= 0.23 → 標準的で模範的な評価者
- 残差最大:C9(P09)= 2.16、C2(P02)= 2.07 → やや独特な評価の傾向
残差が極端に大きい評価者は、評価基準の再確認や再訓練の候補になります。ただし「外れている=悪い」とは限りません。独自の視点を持った貴重な意見である可能性もあります。
④ 尺度係数:評価者の採点スケールのクセ
尺度係数から、各評価者がスケールを広く使っているか狭く使っているかがわかります。
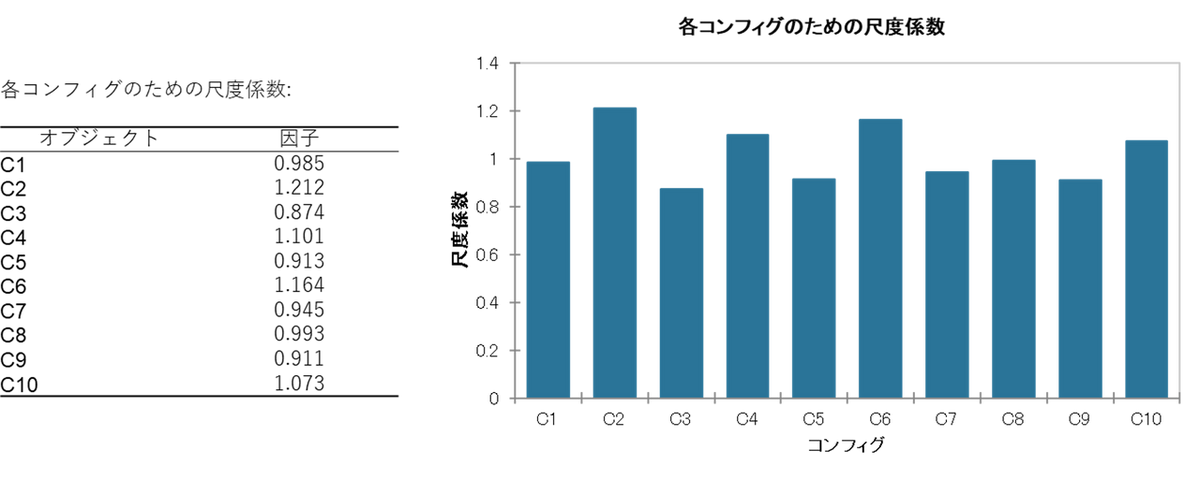
- 1より小さい:スケールを「広く」使っている(差を大きくつける傾向)
- 1より大きい:スケールを「狭く」使っている(無難に中央付近で採点)
今回の結果では、C3(0.87)、C9(0.91)は広く使うタイプ、C2(1.21)、C6(1.16)は狭く使うタイプと判定されました。この情報は評価者の調整に役立ちます。ほかの評価者と違うスケールで採点している人を特定できれば、評価基準のすり合わせができます。
⑤ コンセンサス検定:合意は本物か
コンセンサス(全員の評価の合意)の配置が統計的に意味のあるものかどうかを検証するために、パーミュテーション(データをランダムに並べ替える手法)を用いたコンセンサステストが行われます。
このテストでは、実際のデータから計算されたRc が、ランダムに並べ替えたデータから得られたRc の値の95%よりも高いかどうかを確認します。Rc とは、「元のデータのバラつきを、コンセンサスがどれくらい上手く説明できているか」を示す指標(割合)です。
テストでは、以下の2つを比較します。
- 実際の評価データから計算されたRc
- ランダムなデータから計算された大量のRc
まず、実際のデータにGPA を適用して得られたRc を計算します。Rc は0〜1 の値を取り、1 に近いほど「全員の見方がよく揃っている」ことを意味します。今回のデータでは Rc = 0.891 でした。つまり、全体のばらつきの約89%がコンセンサスで説明できたことになります。
次に、「もし評価者がランダムに点数をつけていたら、どの程度のRc が得られるか?」を調べます。データをシャッフルして評価者と製品の対応をランダムに入れ替えたうえで、同じGPA を実行してRc を計算します。この操作を何百回も繰り返します(今回は500回)。
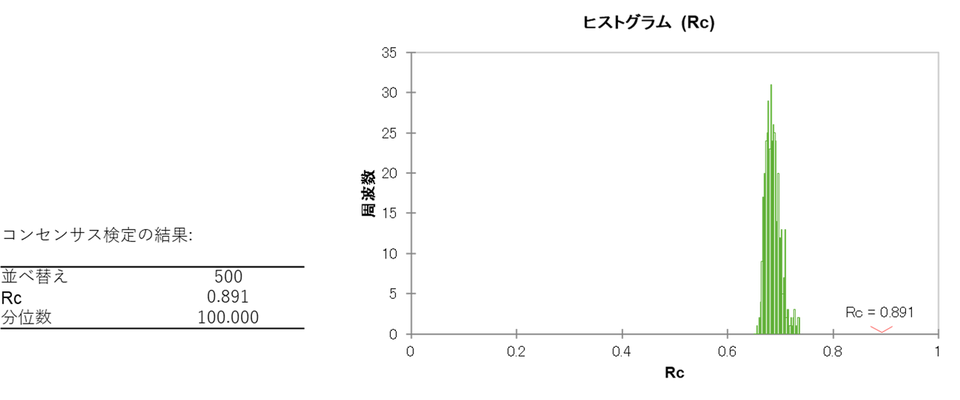
結果の読み方
XLSTAT が出力するヒストグラムでは、横軸がRc の値、縦軸が出現頻度を表しています。緑色の棒グラフがランダムデータから得られたRc の分布、右端の赤いマークが実際のデータのRc(0.891)です。
今回の結果では、ランダムデータから得られるRcは0.7 あたりに集中しており、実際のRc = 0.891 はこの分布よりも明らかに右側に位置しています。分位数は100 となっており、これはランダムデータ500回分のRc のすべてが、実際のRc を下回ったことを意味します。
有意性の判定基準は以下の通りです。
- 分位数 ≥ 95:
実際のRc がランダムの95パーセンタイルを超えている
→ コンセンサスは統計的に有意 - 分位数 < 95:
ランダムでも同程度のRc が得られる可能性がある
→ 有意ではない
今回は分位数 = 100で、95 を大きく上回っています。したがって、このコンセンサスは統計的に有意であり、評価者たちは製品の違いを共通して感じ取っていると結論づけることができます。
⑥ 製品マップ: 結果の視覚化
GPA の最終成果物は、コンセンサスに基づく製品マップです。第1軸と第2軸で全体の分散の94%以上を説明できるので、2次元マップで製品の位置関係がほぼ完全に把握できます。
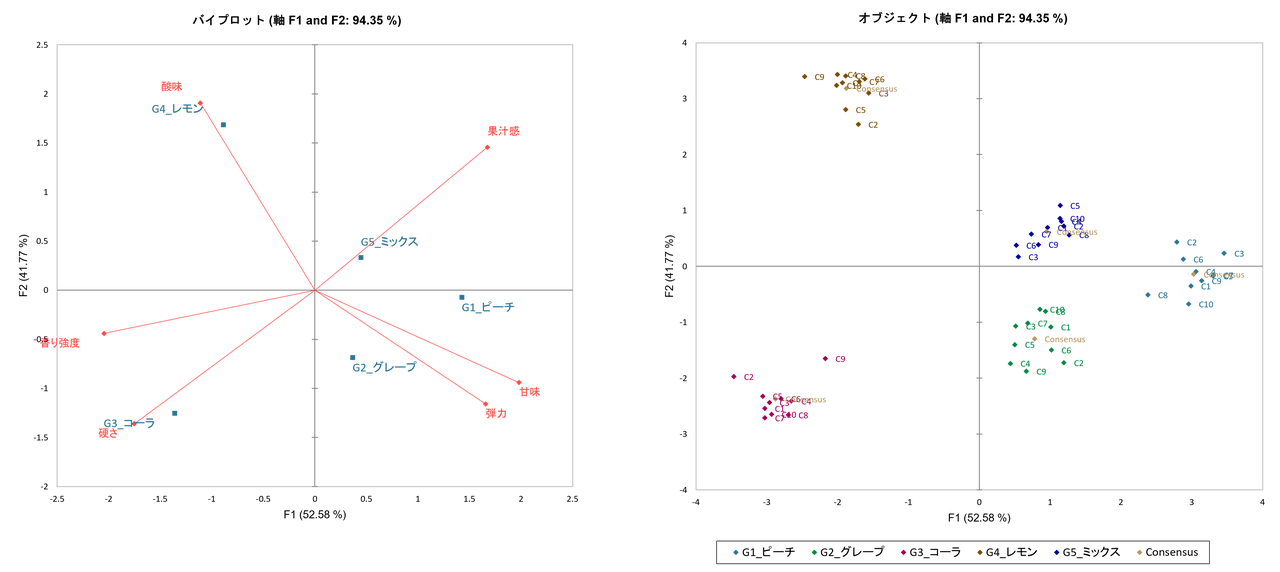
軸の解釈:
- F1軸:「硬くて香りが強い」↔「甘くてジューシーで弾力あり」
- F2軸:「酸味・果汁感あり」 ↔「酸味が弱い」
製品の位置:
- G1ピーチ:右側(甘くジューシーな柔らかい系)
- G4レモン:上端(酸味が突出)
- G3コーラ:左下(硬く香りが強い)
- G2グレープ・G5ミックス:中央付近(特徴が中庸)
マップには各評価者の配置(C1〜C10)とコンセンサス配置が重ねて表示されます。点の散らばりが小さい製品ほど合意が強く、散らばりが大きい製品ほど評価が割れていることを意味します。このマップが、GPA によって得られた「評価者10人の合意で見た、5つのグミの味の地図」 となります。
まとめ
一般化プロクラステス解析(GPA)は、複数の評価者から得られたデータを、平行移動・スケーリング・回転という3つの幾何学的変換で統合し、評価者ごとのクセを取り除いた上で全員のコンセンサスマップを導き出す手法です。
単純な平均では見えなくなってしまう「製品の本当の特徴」を浮かび上がらせ、さらに「どの評価者が外れているか」「どの製品で意見が割れているか」といった、商品開発に欠かせない情報も同時に得られます。フリーチョイスプロファイリングのように評価者ごとに異なる言葉や項目数でデータを集める手法とも相性がよく、現代の官能評価になくてはならない解析手法と言えます。GPA は数学的には複雑な手法ですが、XLSTAT を使えば、普段使い慣れたExcel 上で手軽に実行できます。新製品の開発、品質管理、消費者調査にXLSTAT のGPA をご活用ください。
参考文献
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介した一般化プロクラステス解析はStandard と Advanced のライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。
