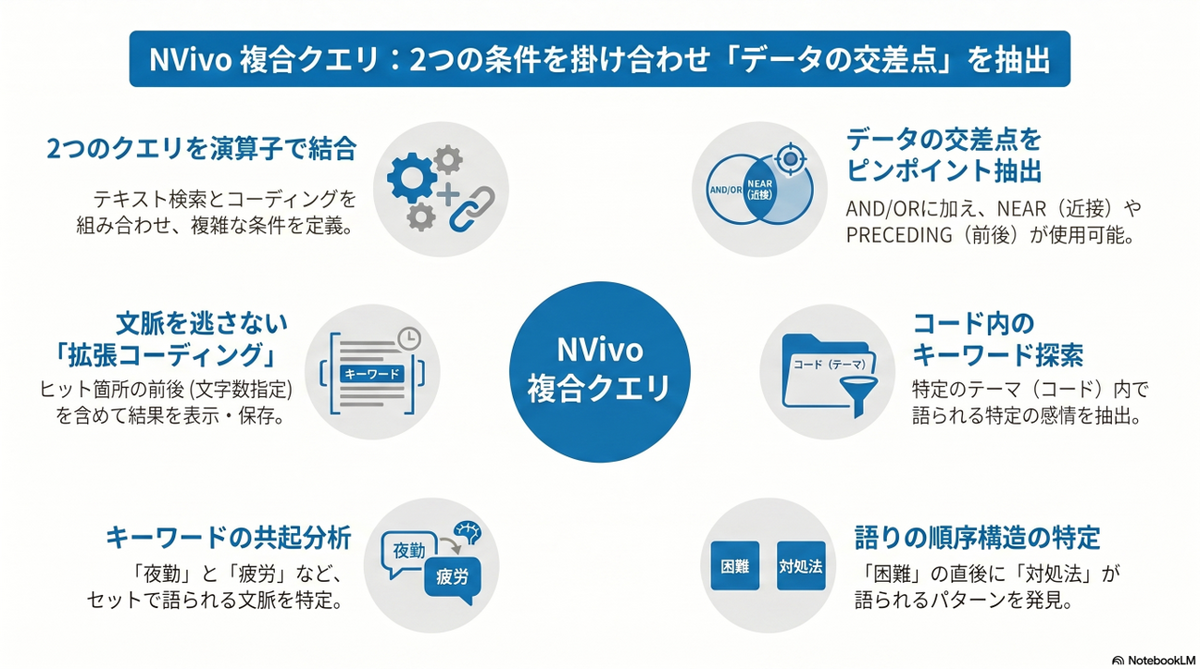
- 複合クエリとは?
- 複合クエリの演算子
- 基本操作の流れ
- NEAR / PRECEDING 選択時の詳細設定 —「コーディング検索演算子」オプション
- 具体例で学ぶ 3つのユースケース(看護学インタビュー分析)
- クエリ結果の保存と活用
- 複合クエリを効果的に使うためのポイント
- まとめ
- 参考文献
複合クエリとは?
「あるコードに集めた語りの中で、特定のキーワードが出てくる箇所だけ見たい」「2つの言葉が近くでセットになって語られている文脈を拾いたい」「あるテーマの直後に別のテーマが語られるパターンを見つけたい」——こうした検索は、テキスト検索やコーディングクエリを単独で使うだけでは実現できません。
NVivo の複合クエリを使えば、テキスト検索とコーディングクエリを2つ組み合わせることで、例えば次のような検索が可能になります。
- コーディングした語りの中から、特定のキーワードを含む箇所だけを抽出する
- 2つのキーワードが近接して出現する箇所を見つける
- あるコードの語りの直後に、別のコードが語られているパターンを特定する
本ページでは、複合クエリの基本的な操作手順とともに、看護学分野のインタビュー分析を例にした3つのユースケースで具体的な使い方をご紹介します。考え方はどの分野にも応用できます。
※このページでは NVivo 15 Windows 版を使ってご説明しております。Mac では複合クエリはご利用いただけません。
※テキスト検索クエリやコーディングクエリの基本的な使い方については、以下のページをご覧ください。
複合クエリの演算子
複合クエリでは、2つのサブクエリを「演算子」で結合します。演算子によって検索の意味が変わるため、目的に合ったものを選ぶことが重要です。
| 演算子 | 意味 | 事例 |
| かつ(AND) | 両方の条件を同時に満たすコンテンツ |
条件: 結果: |
| または(OR) | いずれかの条件を満たすコンテンツ | 条件:
テキスト「不安」または テキスト「恐怖」 |
| AND NOT | 一方の条件を満たし、もう一方を満たさないコンテンツ |
条件:
|
| NEAR コンテンツ | 一方のコンテンツの"近く"にもう一方がある箇所 |
条件:
|
| PRECEDING コンテンツ | 一方のコンテンツの"前"にもう一方がある箇所 |
条件:
|
| SURROUNDING コンテンツ | 一方のコンテンツが、もう一方のコンテンツを囲んでいる箇所 |
条件:
|
NEAR や PRECEDING では、近接距離(単語数など)や取得範囲を細かく指定できます。なお、SURROUNDING は AND と似ていますが、一方のコンテンツがもう一方を完全に囲んでいる(包含している)場合にのみヒットする点が異なります。
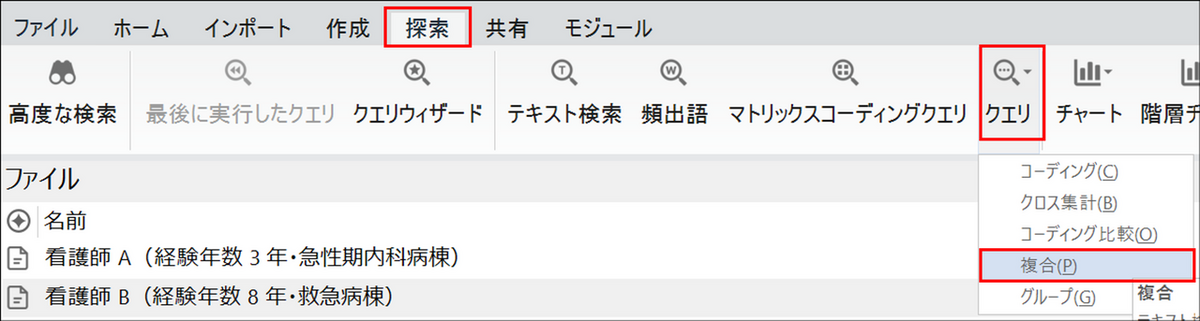
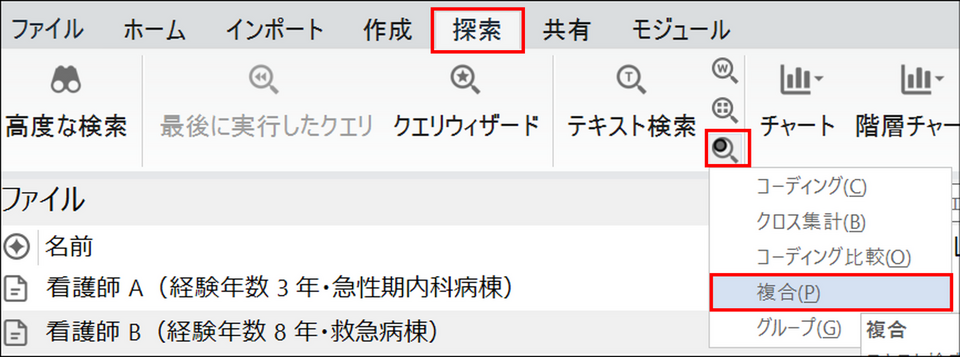
基本操作の流れ
-
クエリを起動する
メニューの[探索] タブ内の[クエリ] をクリックし、[複合] を選択します。
-
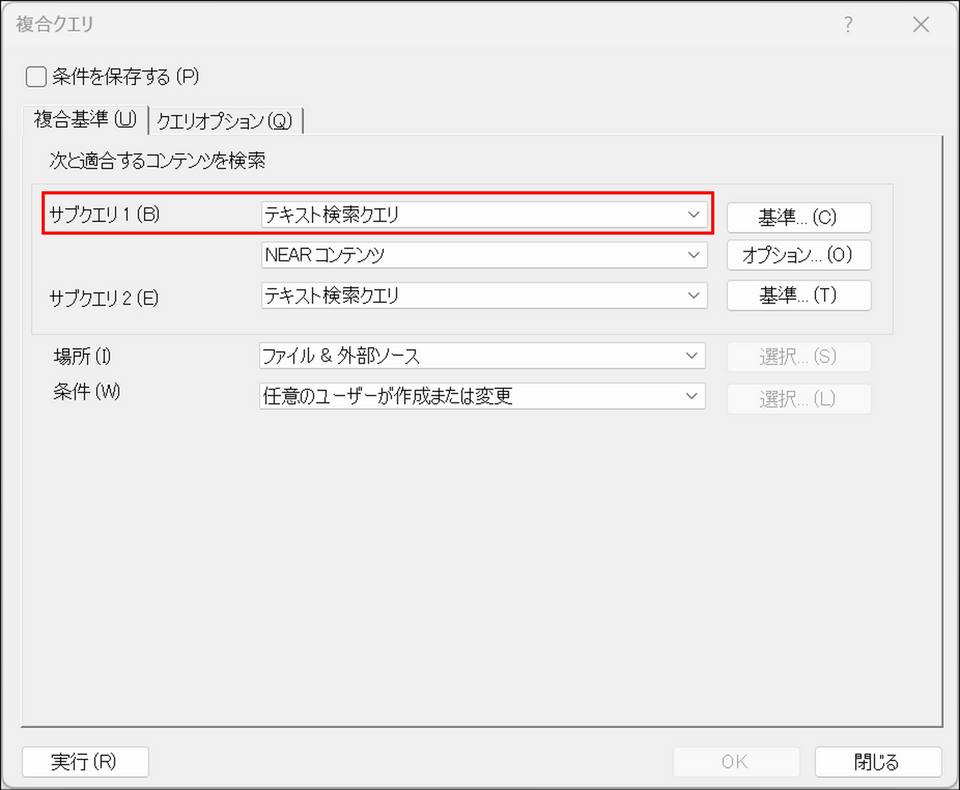
サブクエリ 1 を設定する
クエリの種類(テキスト検索 or コーディングクエリ)を選び、[基準] ボタンで検索条件(検索ワードやコード)を定義します。
-
演算子を選ぶ
かつ/ または / NEAR / PRECEDING などから目的に合った演算子を選択します。NEAR・PRECEDING を選んだ場合は、近接距離や取得オプションを設定します(詳細は後述)。
-
サブクエリ 2 を設定する
サブクエリ 1 と同様に、もう一方の検索条件を定義します。
-
検索の範囲を絞る(任意)
「場所」でクエリの対象(ファイル&外部ソース/選択したアイテム/選択したフォルダなど)を指定できます。「条件」では、特定のユーザーが作成・変更したアイテムに限定することも可能です。例えば、看護師A のインタビューだけを対象に複合クエリを実行したい場合などに活用できます。
-
クエリを実行する
[実行] ボタンをクリックすると、結果が詳細ビューのリファレンスタブに表示されます。
補足:クエリ条件の保存について
ダイアログ画面上部の「条件を保存する」にチェックを入れ、クエリ名を入力した状態で実行すると、クエリ設定をプロジェクトに保存でき、後から同じ条件で再実行できます。
NEAR / PRECEDING 選択時の詳細設定 —「コーディング検索演算子」オプション
演算子で「NEAR コンテンツ」または「PRECEDING コンテンツ」を選ぶと、[オプション] が表示されます。
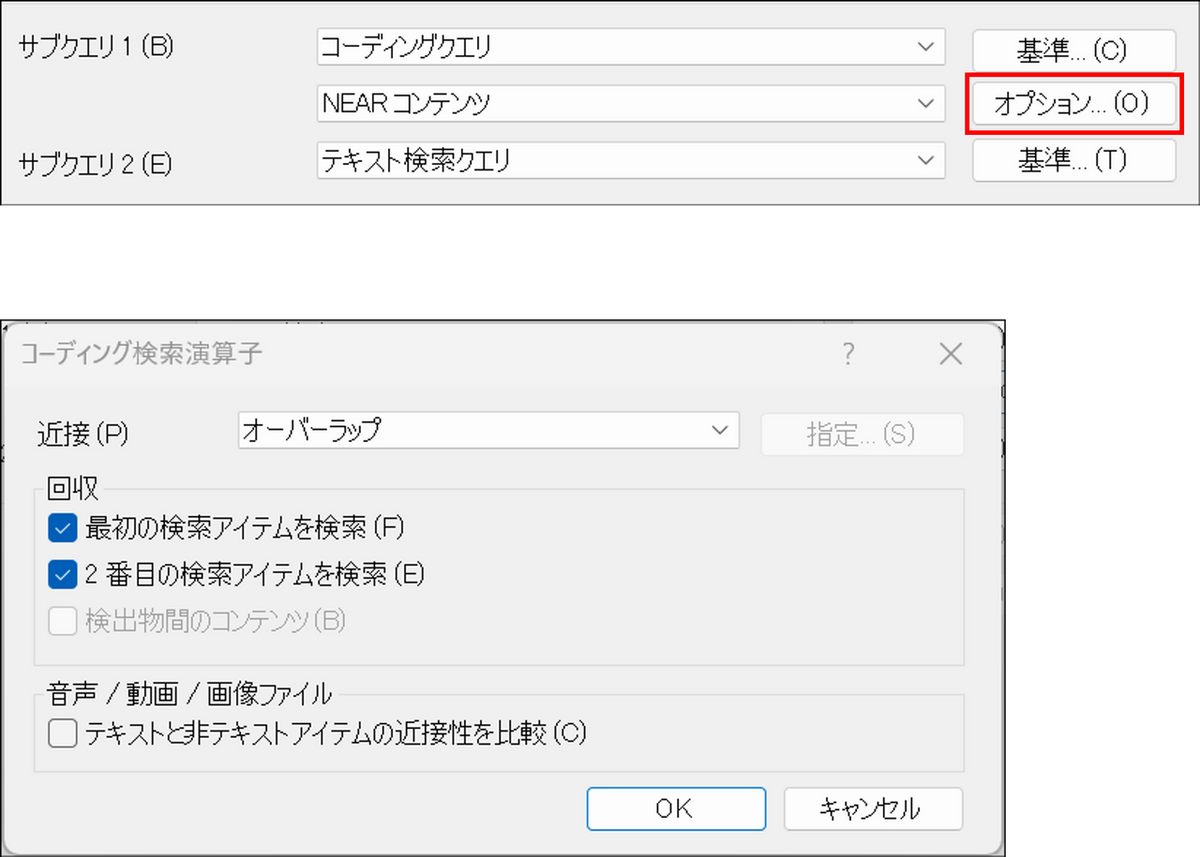
オプションでは「近接」と「回収」の 2 つの設定を行います。
近接 — 2つの検索対象がどの程度近くにあればヒットとするか
「近接」では検索対象同士の距離の範囲を定義します。
| 選択肢 | 意味 | 向いている場面 |
| オーバーラップ | 2つのコーディング範囲が重なっている(テキストが共有されている)箇所のみ | 同じ発言に複数のコードが重複して付けられている場合の分析 |
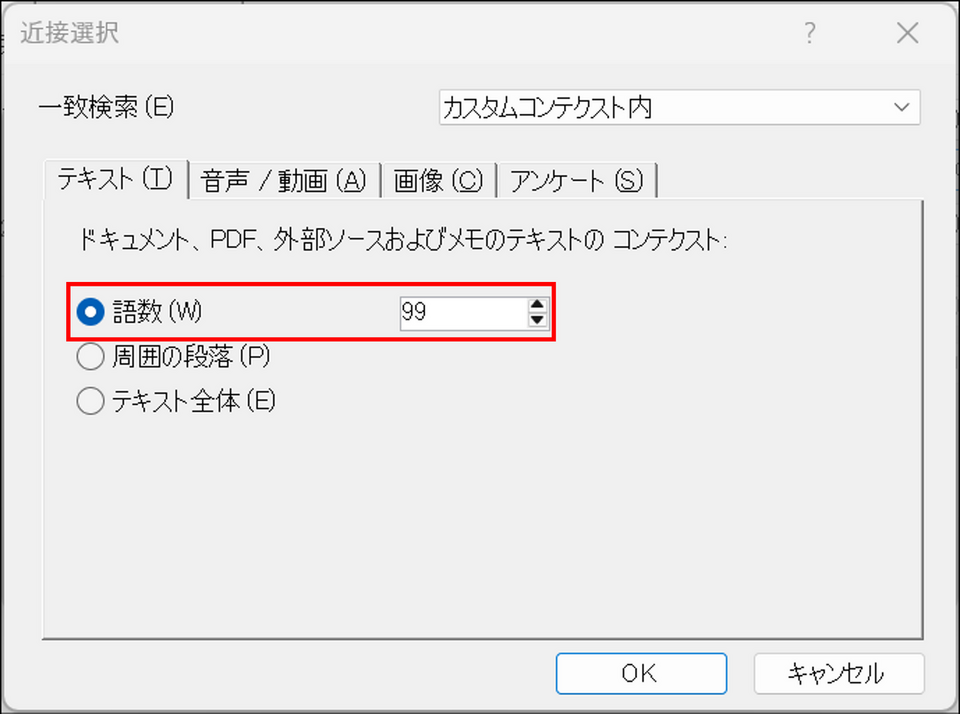
| カスタムコンテクスト内 | 指定した距離(日本語では文字数、上限 99)の範囲内に両方が存在する箇所 | 距離を厳密にコントロールして近接関係を調べたい場合。「指定」ボタンで距離を設定する |
| 同一領域アイテム内 | 同じファイル(ドキュメントやメモなど)内に両方が存在する箇所 | コード間の距離が離れていても同一ファイル内であればヒットさせたい場合 |
| 同一コーディングリファレンス内 | まったく同じコーディング参照(同一のコードで囲まれた範囲)内に両方がある箇所 | 1つのコーディング範囲の中に別の条件も含まれているかを確認する場合 |
日本語テキストでの注意:
「カスタムコンテクスト内」の距離は、英語では語数(Words)、日本語では文字数でカウントされます。上限は「99」です。
回収 — ヒットした箇所からどの範囲のテキストを結果に含めるか
クエリがヒットした際に、結果として取得するコンテンツの範囲を指定します。
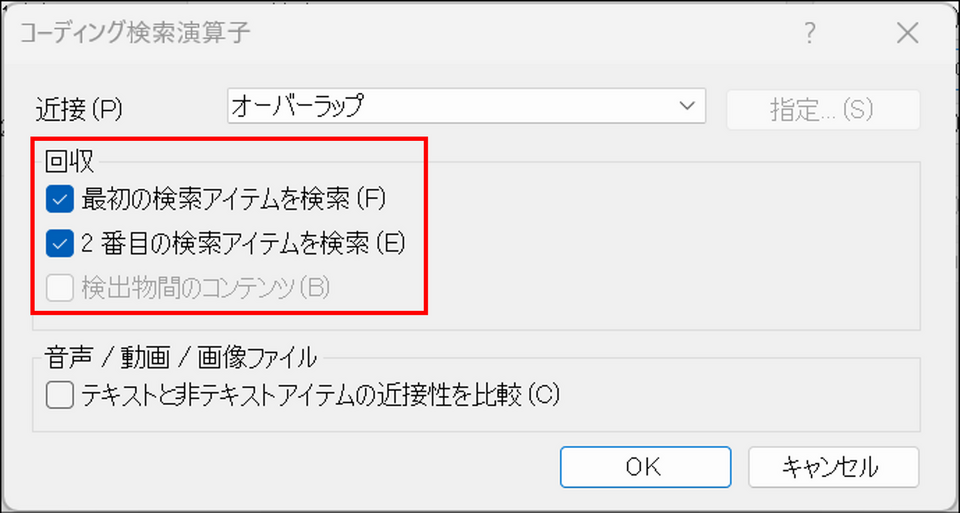
| チェックボックス | 効果 |
| 最初の検索アイテムを検索 | サブクエリ 1 に該当するコンテンツを結果に含める |
| 2 番目の検索アイテムを検索 | サブクエリ 2 に該当するコンテンツを結果に含める |
| 検出物間のコンテンツ | サブクエリ 1 とサブクエリ 2 の間にあるテキストも結果に含める(「オーバーラップ」選択時は使用不可) |
例えば、「コード A PRECEDING コード B」の検索で、上記の3つすべてにチェックを入れると、コード A の語り → 間のテキスト → コード B の語りが一続きのリファレンスとして取得され、語りの流れ全体を文脈ごと確認できます。逆に「最初の検索アイテム」だけにチェックを入れれば、コード B の直前にあるコード A の語りだけを抽出できます。
【補足】設定のヒント
まずは「最初の検索アイテム」と「2番目の検索アイテム」の両方にチェックを入れて実行し、結果を確認してから「検出物間のコンテンツ」を追加するかどうかを判断するとよいでしょう。
具体例で学ぶ 3つのユースケース(看護学インタビュー分析)
以下の例は、急性期病棟に勤務する看護師4名を対象に「臨床現場でのストレスと対処」をテーマとした半構造化インタビューを実施し、NVivo で分析しているという想定です。
サンプルデータのダウンロードはこちらから
https://rs.usaco.co.jp/product/nvivo/asset/sample-project-for-compound-query.zip
ユースケース1:コーディングされた語りの中で特定キーワードを探す
研究上の問い
「患者急変への対応」にコーディングした語りの中で、看護師たちは「不安」という感情をどのように表現しているのか?
設定例
| 項目 | 設定内容 |
| サブクエリ1 | コーディングクエリ → コード「患者急変への対応」 |
| 演算子 | かつ |
| サブクエリ2 | テキスト検索 → 検索語「不安」 |
補足:前後の文脈を表示するには?
デフォルトのまま実行すると、結果には「不安」という検索語そのものしか表示されず、前後の文脈を読み取ることができません。
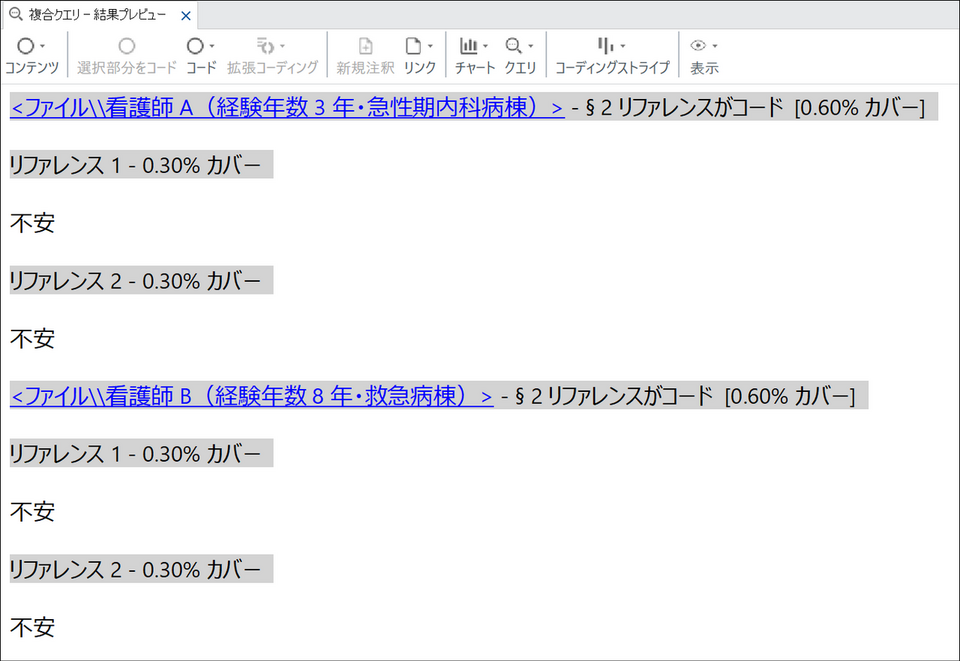
文脈を含めて確認するには、以下 2つの方法があります。
方法1:結果プレビューの「コンテンツ」メニューで切り替える
クエリをそのまま実行した後、結果プレビュー画面で文脈の広さを変更できます。
-
結果プレビューを全選択(ショートカットキー:Ctrl + A)します。
-
結果プレビュー上部のリボンにある「コンテンツ」をクリックし、「コーディングコンテクスト」セクションから表示範囲を選択します。
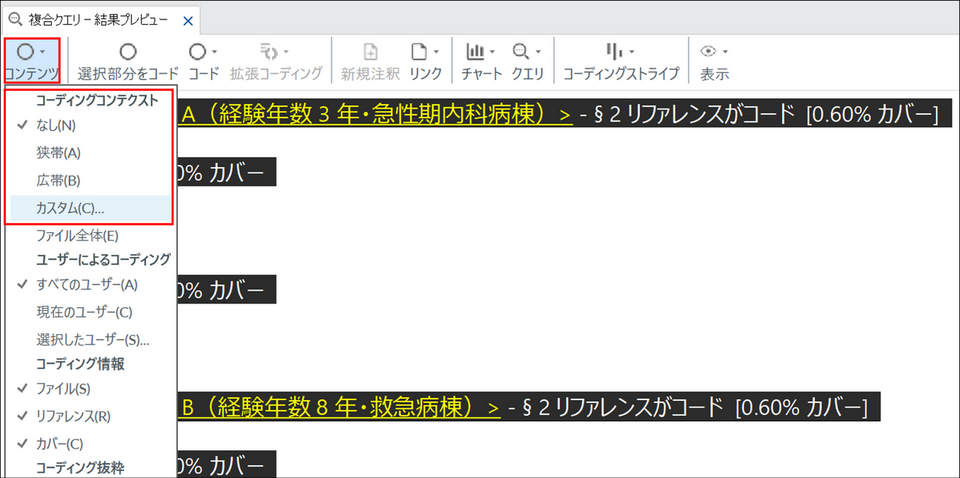
- なし:検索語のみ表示します(デフォルト)。
- 狭帯:検索語の前後に短い文脈(日本語の場合5文字)を表示します。短い文脈を素早く確認したいときに便利です。
- 広帯:より広い範囲の前後文脈を表示します。語りの流れを把握したい場合に有効です。
- カスタム:前後に含める範囲を手動で指定します。
-
選択すると表示が切り替わり、各リファレンスに前後の文脈が追加されます。
例)「カスタムコンテクスト」で前後50文字を指定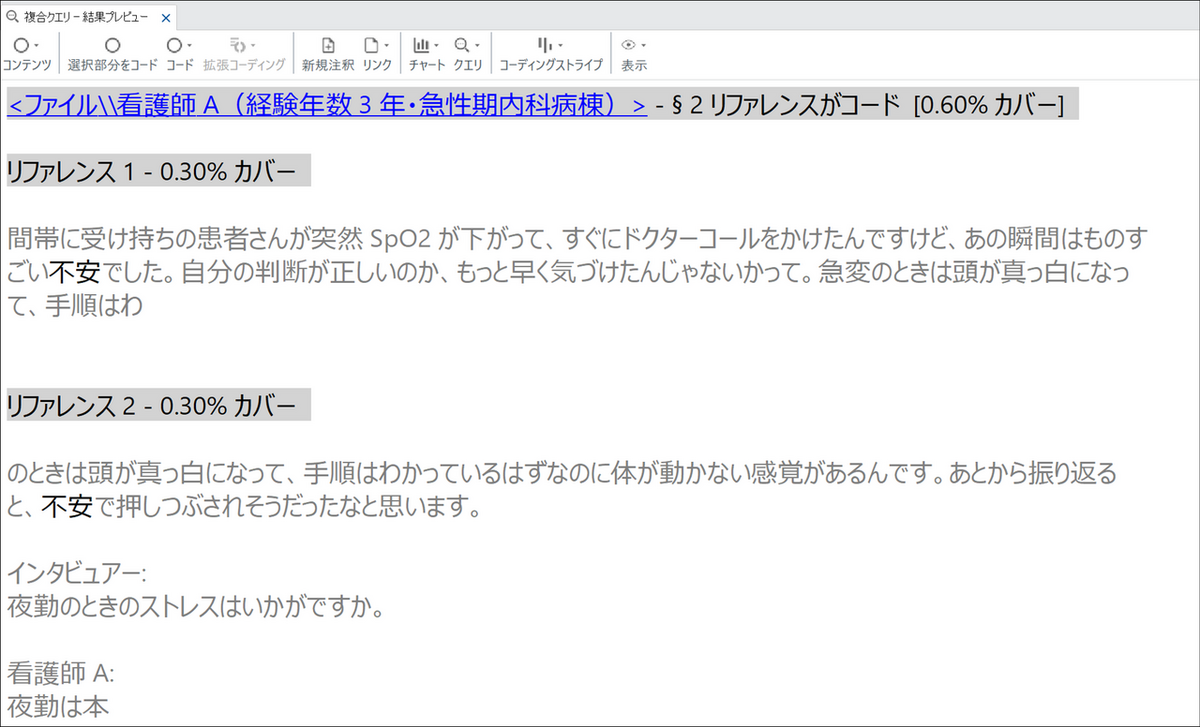
この方法は表示上の切り替えのみで、結果をコードとして保存する際のコーディング範囲には影響しません。クエリを再実行する必要がなく、結果画面上で即座に文脈の広さを切り替えられるのが利点です。まずはこの方法を試し、結果を保存する際により厳密な範囲を指定したい場合に方法2を使うとよいでしょう。
日本語テキストでの注意点:
狭帯・広帯・カスタムで指定する範囲の単位は、英語テキストでは「語数(Words)」ですが、日本語テキストでは「文字数」になります。たとえば「狭帯」を選択した場合、英語では前後5語、日本語では前後5文字が追加されます。日本語で十分な文脈を得るには「広帯」を選択するか「カスタム」で前後 50〜99 文字に設定するとよいでしょう(カスタムコンテクストの上限は 99 文字です)。
方法2:クエリ設定の「拡張コーディング 」を変更する
クエリの実行前に範囲を設定しておくことで、結果そのものに文脈を含めることができます。方法1が表示上の変更であるのに対し、こちらは結果をコードとして保存する際のコーディング範囲自体が広がります。結果をコードとして保存する場合は、この方法で範囲を確定させておくのがおすすめです。
-
複合クエリのダイアログで[クエリオプション] タブを開きます。
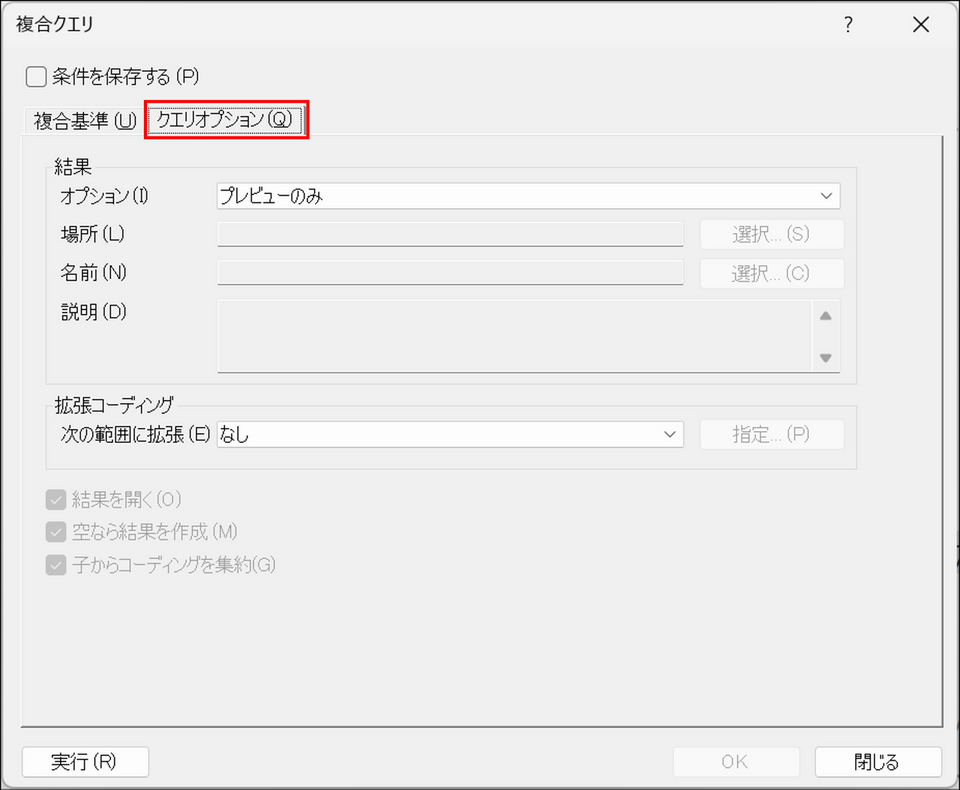
-
[次の範囲に拡張] のドロップダウンから範囲を選択します。
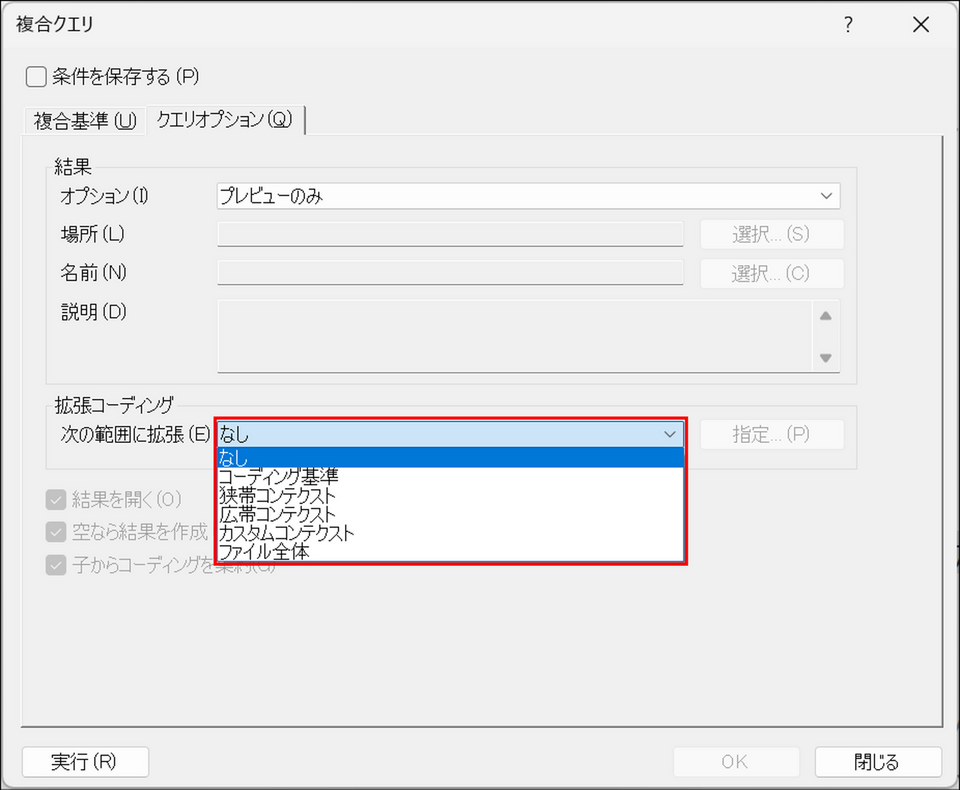
- なし:検索語のみ
- コーディング基準:サブクエリのコーディング範囲に基づいて表示します
- 狭帯コンテクスト:検索語の前後5語(日本語の場合5文字)を表示します。
- 広帯コンテクスト:検索語を含む段落全体を表示します
- カスタムコンテクスト:前後に含める範囲を手動で指定。英語では語数、日本語では文字数でカウントされる(上限は 99)。
-
設定後に[実行] をクリックすると、検索語だけでなくその周囲の文脈が結果に含まれます。
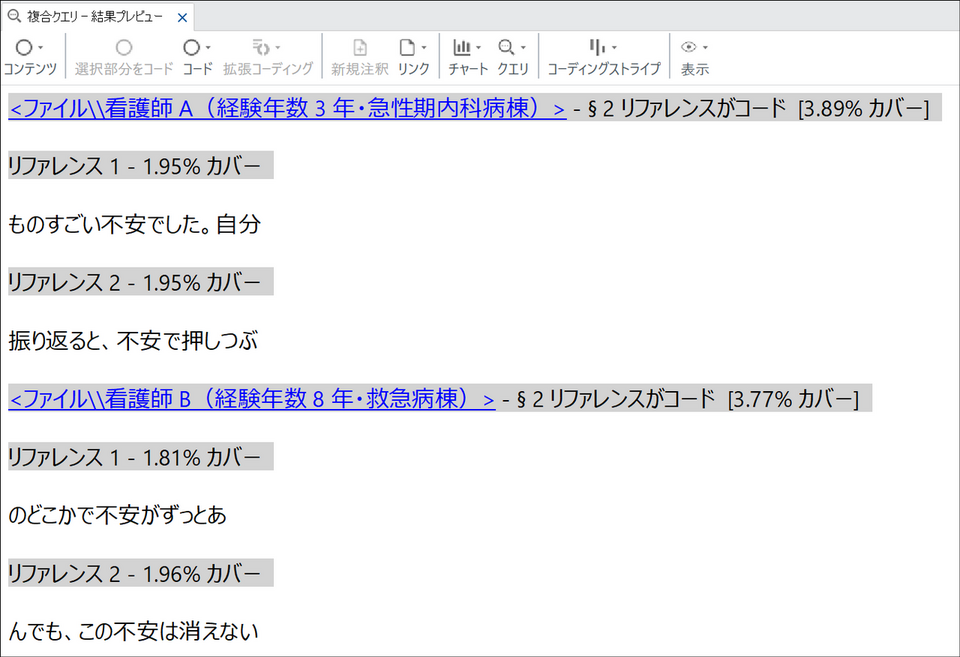
何がわかるか
いずれの方法でも、「患者急変への対応」としてコーディングされた範囲のうち、「不安」という語を含む発言が前後の文脈とともに確認できるようになります。急変場面で看護師がどのような不安を抱え、それをどのような言葉で語っているかを集中的にレビューでき、コード全体を読み返すよりも感情表現に焦点を当てた分析が効率的に進められます。
応用のヒント
テキスト検索の語を「怖い」「焦り」「パニック」などに変えて繰り返し実行すれば、急変対応に伴う感情のバリエーションを網羅的に把握できます。
ユースケース2:2つのキーワードが近接して現れる文脈を探す
研究上の問い
インタビューの中で「夜勤」と「疲労」がセットで語られている箇所を見つけ、夜勤特有の疲労体験を分析したい。
設定例
| 項目 | 設定内容 |
| サブクエリ 1 | テキスト検索 → 検索語「夜勤」 |
| 演算子 | NEAR コンテンツ |
| サブクエリ 2 | テキスト検索 → 検索語「疲労」 |
NEAR コンテンツを選択すると「コーディング検索演算子」オプションを指定できます。今回は「近接」で「カスタムコンテクスト内」を選び、「指定」で「周囲の段落」を選択します。
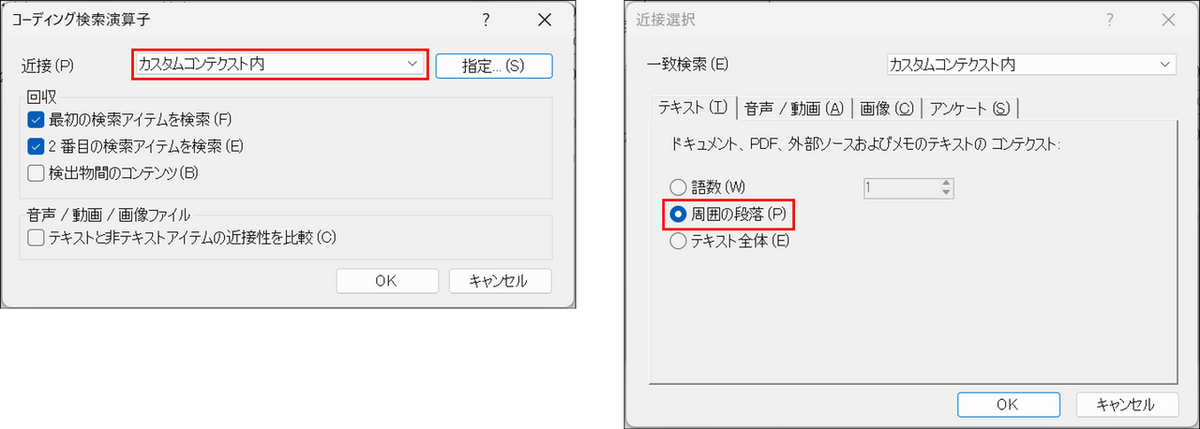
補足:結果に検索語しか表示されない場合
デフォルトのまま実行すると、結果には「夜勤」「疲労」という検索語だけが別々のリファレンスとして表示され、前後の文脈を読み取ることができません。
これはユースケース1 と同じ問題です。以下いずれかの方法で文脈を含めて確認してください。
- 方法1(手軽):
結果のリファレンスを全選択した状態で、結果プレビューのリボン「コンテンツ」→「コーディングコンテクスト」から「広帯」や「カスタム」を選択します。日本語では文字数でカウントされるため、カスタムで前後 50〜99 文字に設定すると、「夜勤」「疲労」それぞれの前後の文脈が表示されます。 - 方法2:
複合クエリのダイアログで[クエリオプション] タブで「拡張コーディング」を「広帯コンテクスト」以上に変更してから実行する。
結果の読み方
文脈を広げると、たとえば以下のような内容が確認できます。
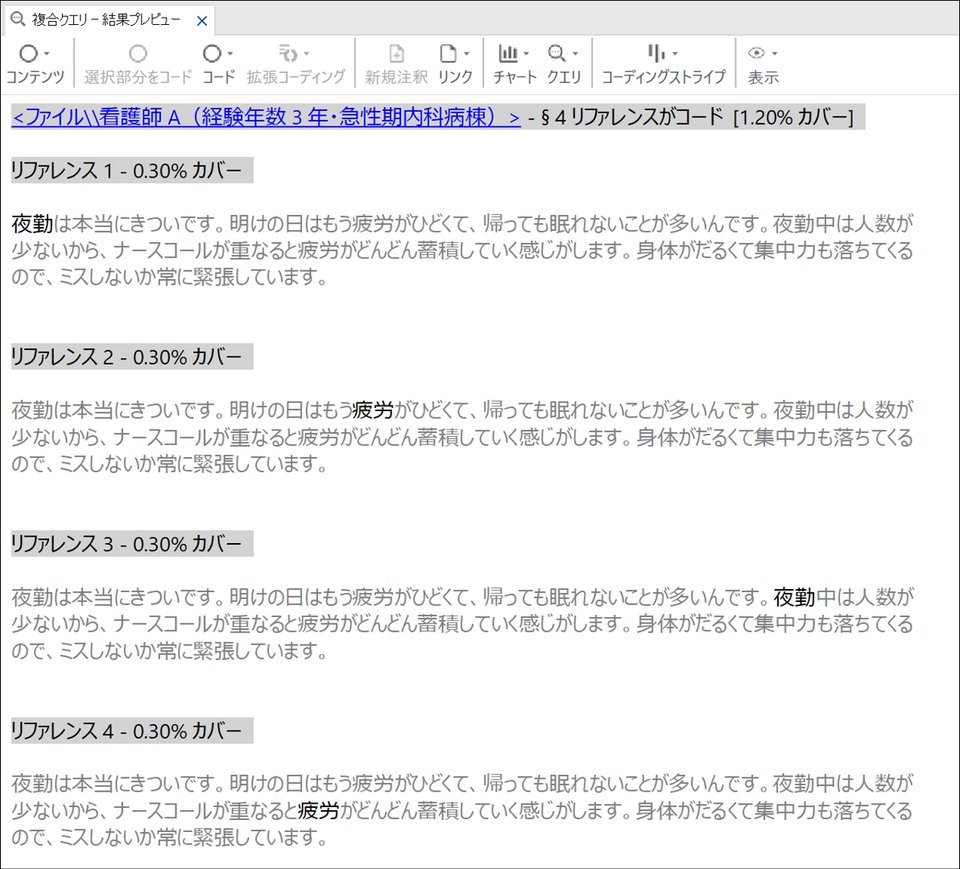
| 看護師 | 読み取れる内容 |
| A(急性期内科) | 夜勤明けの疲労と不眠、勤務中のナースコール対応による疲労蓄積 |
| B(救急) | 連続夜勤後の回復困難、疲労による判断力低下への恐怖 |
| C(ICU) | 16 時間夜勤の明け方の集中力低下、勤務後の消耗 |
| D(外科) | 術後管理の身体的疲労(足の疲れ・筋肉痛)、疲労回復に丸一日 |
文脈を広げた状態で各リファレンスを読むと、同じ「夜勤×疲労」でも身体的疲労(D)、判断力への影響(B)、回復の困難さ(A・C)など、疲労の質の違いが浮かび上がります。
何がわかるか
単に「夜勤」で検索した場合に含まれるシフト調整や業務内容の話題をフィルタリングし、身体的・精神的疲労に関連する文脈だけを効率よく取り出せます。
ユースケース3:コード同士の近接・順序関係を調べる
研究上の問い
看護師が「バーンアウト」について語った直後に、どのような「対処行動(コーピング)」を語っているかを分析し、燃え尽き体験と対処行動の関係を明らかにしたい。
設定例
| 項目 | 設定内容 |
| サブクエリ1 | コーディングクエリ → コード「バーンアウト」 |
| 演算子 | PRECEDING コンテンツ |
| サブクエリ2 | コーディングクエリ → コード「コーピング」 |
コーディング検索演算子の設定
PRECEDING を選択すると「コーディング検索演算子」ダイアログが表示されます(各設定項目の詳細は前述の「NEAR / PRECEDING 選択時の詳細設定」を参照)。このユースケースでは以下のように設定します。
- 近接:
「カスタムコンテクスト内」を選択し、「指定」で 99 文字に設定。サンプルデータではこの設定で 4 名全員がヒットします。99 文字でヒットしない場合は「同一領域アイテム内」に切り替えてみてください。 - 回収:
「最初の検索アイテムを検索」「2 番目の検索アイテムを検索」「検出物間のコンテンツ」の 3 つすべてにチェックします。これによりバーンアウトの語り → 間のテキスト → コーピングの語りが一続きのリファレンスとして取得され、語りの流れ全体を読み取ることができます。
結果の読み方
カスタムコンテクスト 99 文字で実行した場合、以下のような結果が得られます。
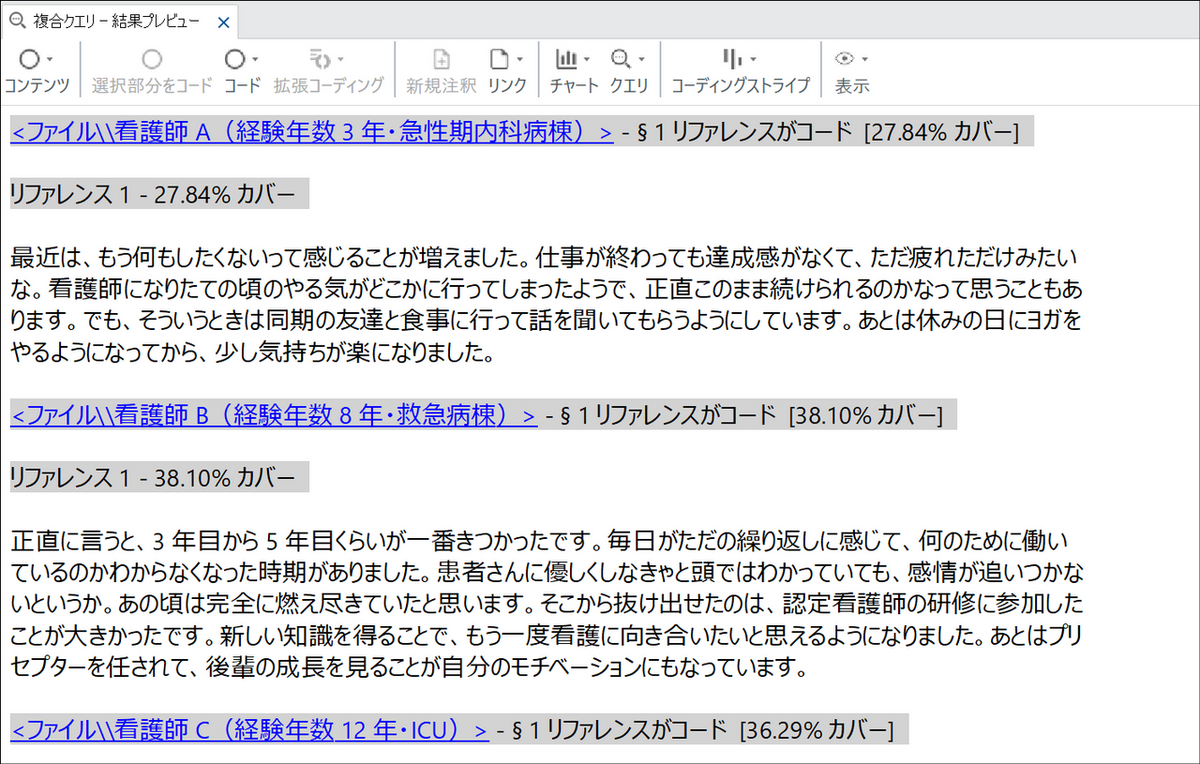
| 看護師 | 結果の内容 |
| A(急性期内科) | やる気の喪失・達成感のなさ → 同期との食事・ヨガ |
| B(救急) | 繰り返しの日々・感情の疲弊 → 認定看護師研修・プリセプター |
| C(ICU) | 看取りによる無力感・感情の麻痺 → カウンセリング・デジタルデトックス |
| D(外科) | 過重労働による心身の限界 → 有給取得・旅行・ランニング |
いずれもバーンアウトからコーピングまでの語りが 1 つのリファレンスにまとまっており、「燃え尽き → 対処行動」のパターンがきちんと捉えられています。
結果から読み取れること
この結果を一覧すると、以下のような分析の視点が得られます。
- 対処行動の類型化
社会的サポート(同期との食事)、身体活動(ヨガ・ランニング)、専門的支援(カウンセリング・研修)、休息(有給取得)など、コーピングの種類を整理できる。 - バーンアウトの深さとコーピングの関係
感情の麻痺まで至った看護師 C は専門家のカウンセリングを選択しており、バーンアウトの深刻さと対処行動の種類にパターンがあるかを検討できる。 - 語りの順序構造
PRECEDING で順序を固定しているため、「燃え尽きを語った後にどう立ち直ったかを語る」という語りの構造そのものが分析対象になる。
応用のヒント
演算子を NEAR に変えると順序を問わない近接検索になり、逆に「対処行動 → バーンアウト」のパターン(対処がうまくいかず燃え尽きに至る語り)も拾えます。PRECEDING と NEAR の結果を比較することで、語りの方向性の違いを検討する材料になります。
クエリ結果の保存と活用
クエリ結果に興味深い内容が見つかったら、後から参照できるように保存しておくと分析が捗ります。
-
メニューの[探索] タブにて [最後に実行したクエリ] をクリックします。

-
ダイアログ画面が開くので、[クエリオプション] タブに切り替えます。
-
[結果] の[オプション] にて[プレビューのみ] 以外を選択します。
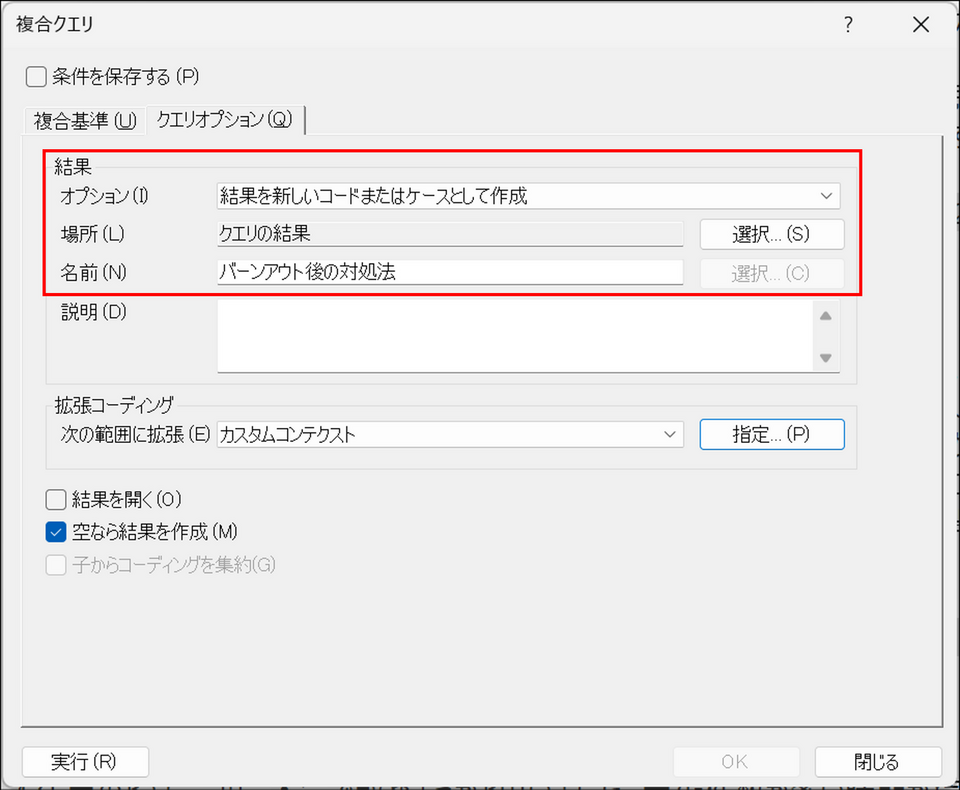
- 結果を新しいコードまたはケースとして作成
結果を新しいコードにまとめます。 - 結果を既存コードまたはケースにマージ
結果を既存コードまたはケースへマージします。 - 結果を新規静的セットとして作成
該当するソースファイル(インタビューデータなど)の一覧をセットとして保存します。コードがコーディング範囲そのものを保存するのに対し、セットはファイル単位のリストを保存する点が異なります。
- 結果を新しいコードまたはケースとして作成
-
名前と保存場所を指定して「OK」をクリックします。
例)新規コードとして保存した場合
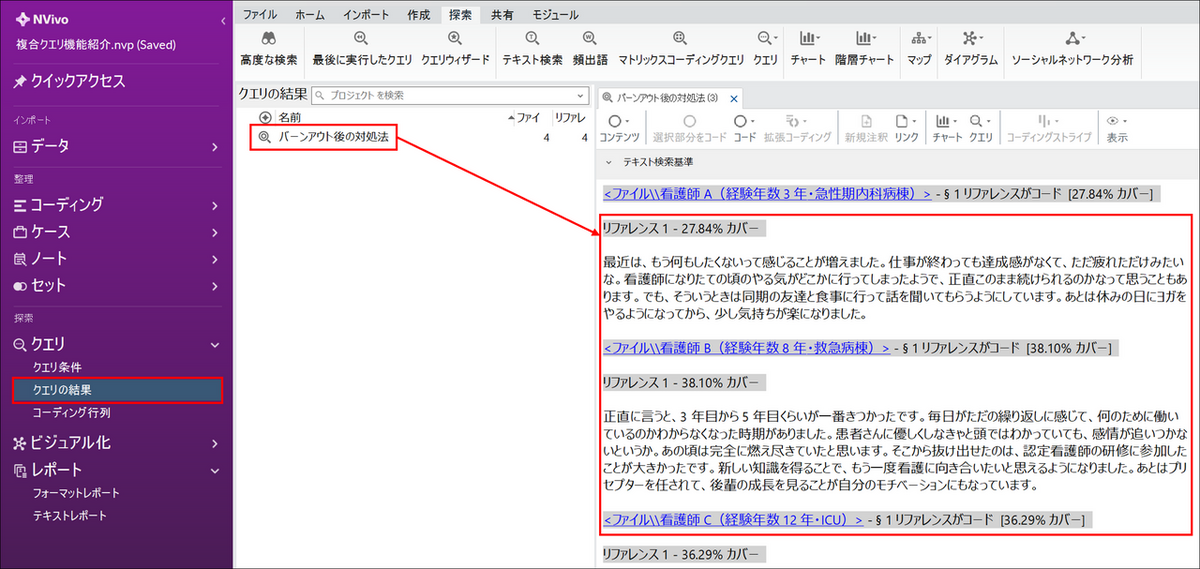
※保存先を指定しない限り、新しいコードはデフォルトで「クエリの結果」フォルダに作成されます。
複合クエリを効果的に使うためのポイント
複合クエリを効果的に使うため、以下の点を意識するとよいでしょう。
- コーディングの粒度を揃える
サブクエリにコーディングクエリを使う場合、コードの範囲が広すぎると結果にノイズが増えます。段落単位など一定の粒度でコーディングしておくと、NEAR や PRECEDING の結果が解釈しやすくなります。
- 前後の文脈を必ず確認する
テキスト検索を含む複合クエリでは、デフォルト設定のままだと検索語そのもの(例:「不安」の 2 文字)しか結果に表示されません。結果プレビューのリボンにある「コンテンツ」→「コーディングコンテクスト」から「狭帯」や「広帯」を選ぶと、その場で前後の文脈を確認できます。結果をコードとして保存する場合は、クエリ設定の「クエリオプション」タブで「拡張コーディング」の範囲をあらかじめ広げておくのがおすすめです。
- 結果を保存して比較する
ユースケースごとの結果をコードとして保存し、後からマトリックスコーディングクエリなどで横断的に比較すると、分析の深みが増します。
まとめ
複合クエリは「テキスト検索 × コーディングクエリ」や「コーディングクエリ × コーディングクエリ」といった組み合わせにより、単一クエリでは到達しにくいデータの関連性を浮かび上がらせます。本ページで紹介したように、コード内でのキーワード検索、キーワード同士の共起分析、コード間の順序パターンの発見など、研究の問いに直結する多様な探索が可能です。ぜひご自身のプロジェクトデータに合わせて試してみてください。
