NVivo でデータ分析する際に、「この単語はどこで使われているんだろう?」と思ったことはありませんか。そんな時に役立つのが、テキスト検索クエリです。テキスト検索クエリを活用することで、インタビューのトランスクリプトやアンケートデータ、論文PDF など、さまざまな種類のテキストデータから、特定の単語やフレーズを簡単に見つけることができます。このページでは、テキスト検索クエリの基本的な使い方から高度なテクニックまで、様々な活用方法をご紹介します。
※なお、このページではNVivo 15 Windows 版を使ってご説明しております。
- テキスト検索クエリとは?
- テキスト検索クエリで検索対象となるアイテム
- テキスト検索クエリの操作手順
- 検索結果画面の見方
- 検索条件を保存する
- 検索結果をコードとして保存する
- テキスト検索時の処理について
- 覚えておくと便利な検索演算子や特殊文字
- まとめ
- 参考ページ
テキスト検索クエリとは?
テキスト検索クエリは、NVivo プロジェクト内のアイテムから特定の単語やフレーズを検索できる機能です。以下のような場面で活用できます。
- 特定の単語やフレーズの出現箇所を特定
インタビューデータに対して、テキスト検索クエリを実行することで、特定の単語がどのような文脈で登場するのかを確認することが可能です。また、ワードツリー機能を使用することで、検索した単語と結びつきの強い語句を可視化することもできます。
- プロジェクト初期段階での分析
ファイル内で特定のアイデアやトピックスがどの程度頻繁に言及されているのかを調べることができます。これは分析の初期段階でプロジェクトの方向性を検討する際に役立ちます。
- 特定のテーマやトピックスで発言内容をコーディング
単語やフレーズで検索した結果に対してコードを割り当てることができます。例えば、「太陽光発電」や「風力発電」の出現箇所をすべて見つけて、「再生可能エネルギー」というコードにコーディングすることができます。
テキスト検索クエリで検索対象となるアイテム
テキスト検索クエリでは以下のアイテム内のテキストを検索することが可能です。
- Word / PDF ファイル
- オーディオ/ビデオのトランスクリプト
[コンテンツ] フィールドのみが検索され、カスタムのトランスクリプトフィールドは無視されます。 - データセット
コーディング可能なフィールドのみが検索され、分類フィールドは無視されます。
また、テキスト検索クエリでは、以下の項目は検索されません。
- ストップワード
テキストコンテンツの言語に関連付けられたストップワード(「the」「a」「is」など)は通常検索されません。ただし、検索フレーズ内の単語の間にある場合や、テキストコンテンツの言語が中国語または日本語の場合は、ストップワードも検索されます。ストップワードのリストは、テキスト内容の言語に合わせて編集可能です。 - 記号や句読点
「,」「.」「;」などの記号や句読点は検索されません。 - 単語の一部
通常、単語の一部は検索されません(例えば、「cat」を検索した場合に「catch」は検索されない)。ただし、テキスト言語が中国語または日本語の場合は、単語の一部も検索される場合があります。 - フレームワークマトリックスのサマリー内の単語やフレーズ
フレームワークマトリックスのサマリー内に記載されている単語やフレーズは検索されません。 - 画像内の単語
画像ファイル内のテキストは検索されません。スキャンした紙のドキュメントから作成されたPDF ファイルは画像として認識されます。このようなPDF ファイル内のテキストを検索したい場合は、光学文字認識(OCR)を使用して画像をテキストに変換してからNVivo にインポートする必要があります。
テキスト検索クエリの操作手順
-
メニューの[探索] タブから [テキスト検索] をクリック

-
[選択したアイテム] をクリック
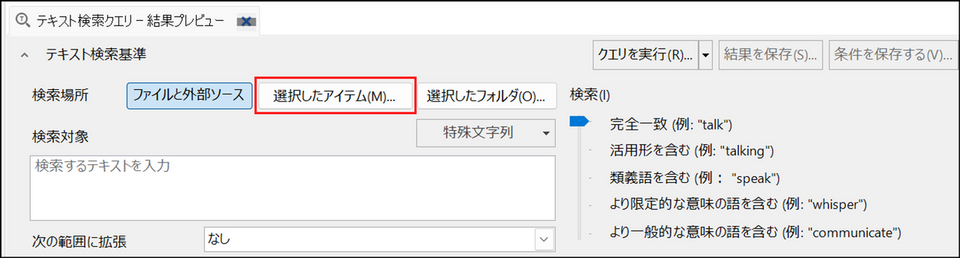
-
検索対象のアイテムにチェックを入れ、[OK] をクリック
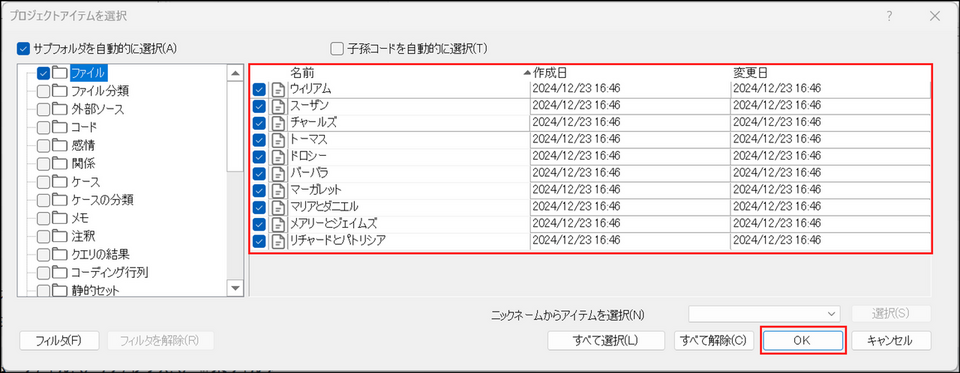
-
[検索対象] の項目に検索したい単語やフレーズを入力
※正確なフレーズを検索する場合は、二重引用符(" ")で囲みます。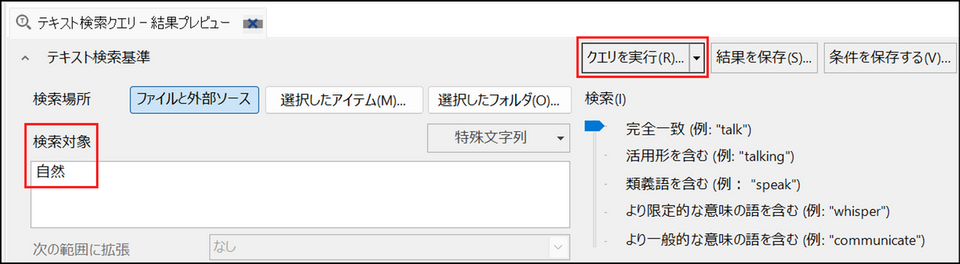
-
[クエリを実行] ボタンをクリック
→ 検索が実行され、画面下部に結果が表示されます。
検索結果画面の見方
検索結果画面の右側にはタブが表示され、タブを切り替えることで表示内容が変更されます。
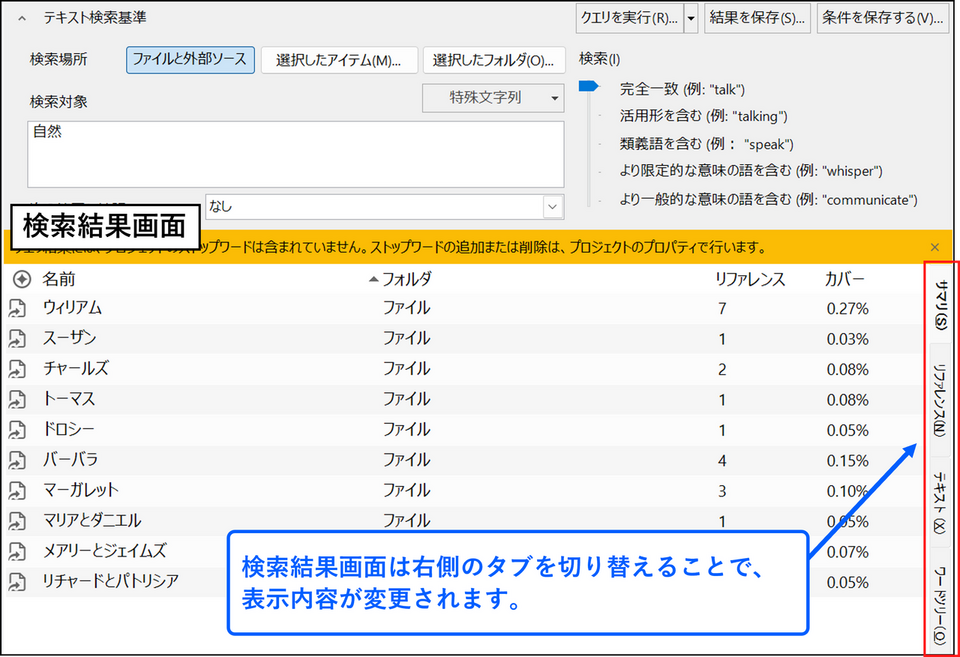
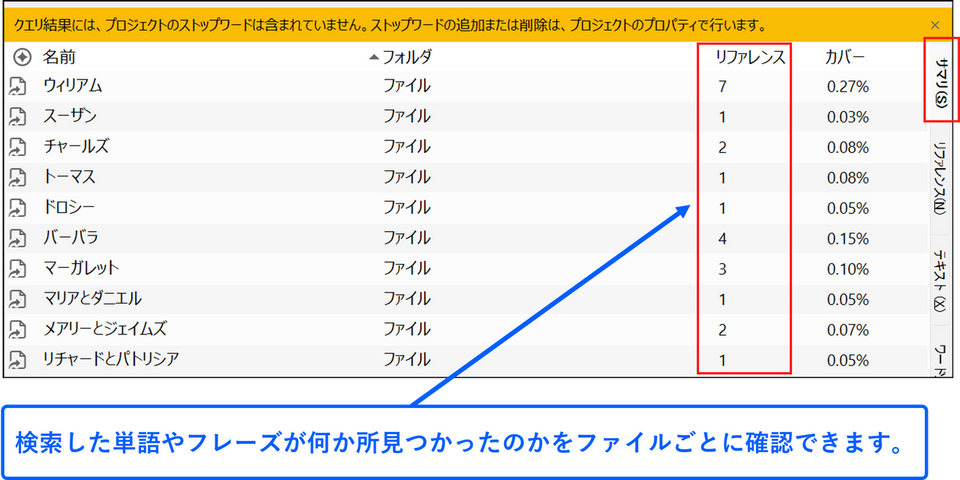
サマリ
[サマリ] タブでは、検索した単語・フレーズがどのアイテムで何箇所見つかったのかを確認できます。
リファレンス
[リファレンス] タブを選択すると、検索語を含む箇所が結果画面に表示されます。
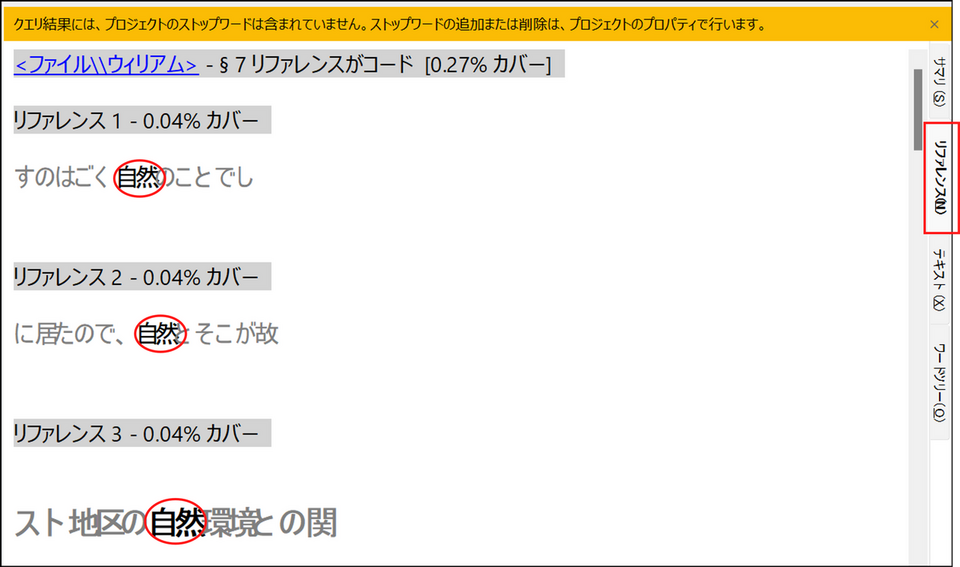
【補足】結果画面の「リファレンス番号」と「カバー率」について
リファレンス番号
元データの中で何番目に見つかった箇所なのかを示しています。元データの最初の方で見つかった箇所には小さい番号が付与されます。
カバー率
元データ全体の文章量のうち、当該箇所の文章が占める割合を示しています。
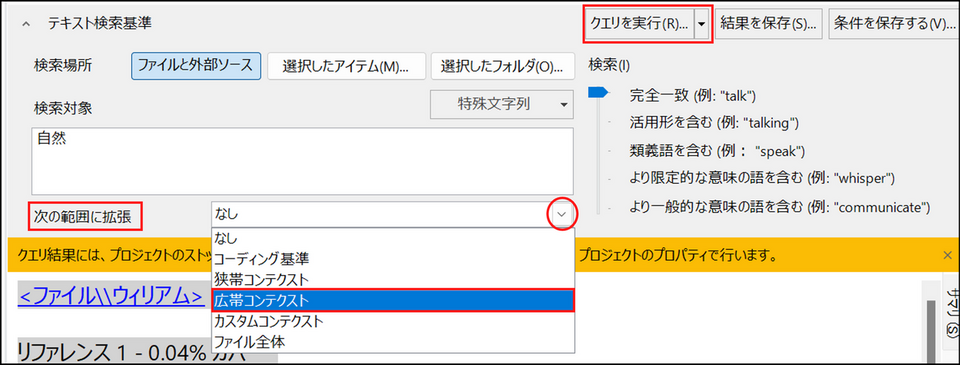
[次の範囲に拡張] の項目で、[広帯コンテクスト] を選択し、再度[クエリを実行] ボタンをクリックすると、範囲を広げて検索結果を表示することができます。

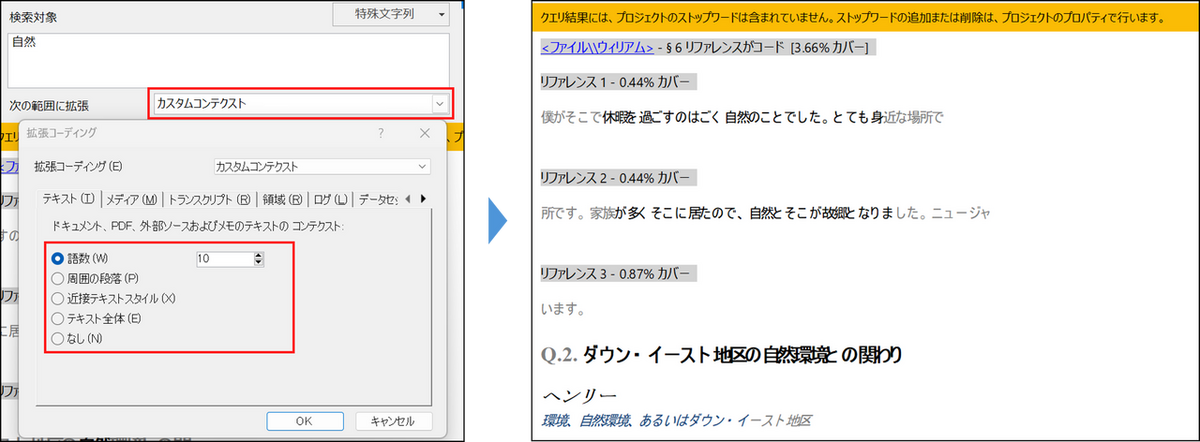
カスタムコンテクストを選択すると、より細かく範囲を指定することも可能です。
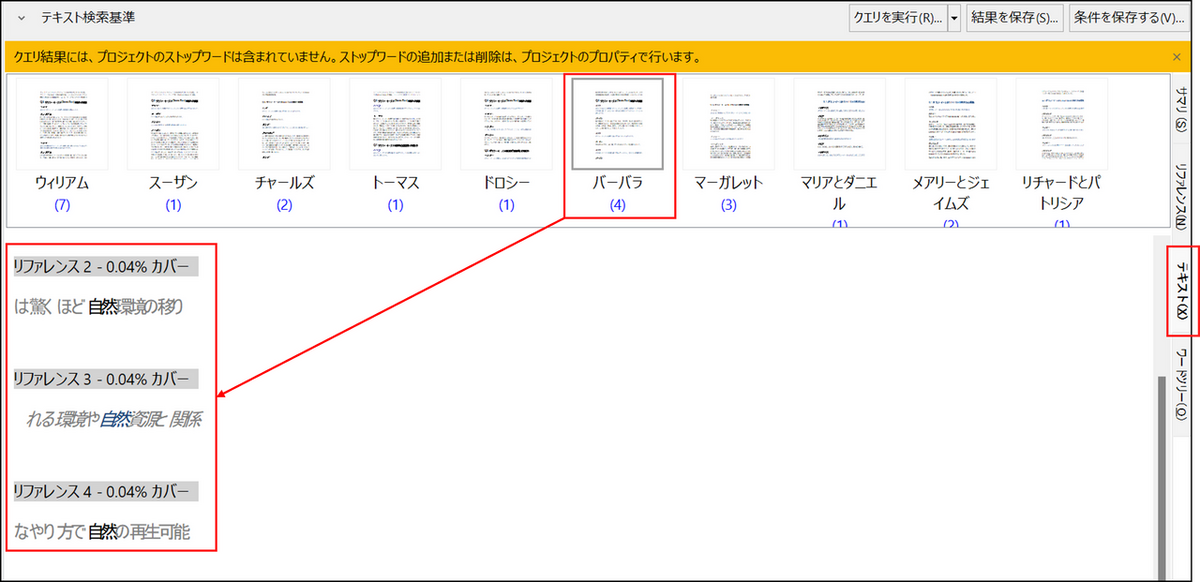
テキスト
[テキスト] タブを選択すると、ファイルごとに検索語を含む箇所を確認することが可能です。サムネイルのファイル名の下部に表示される括弧内の数字は、そのファイル内で検索語が何箇所見つかったのかを示しています。
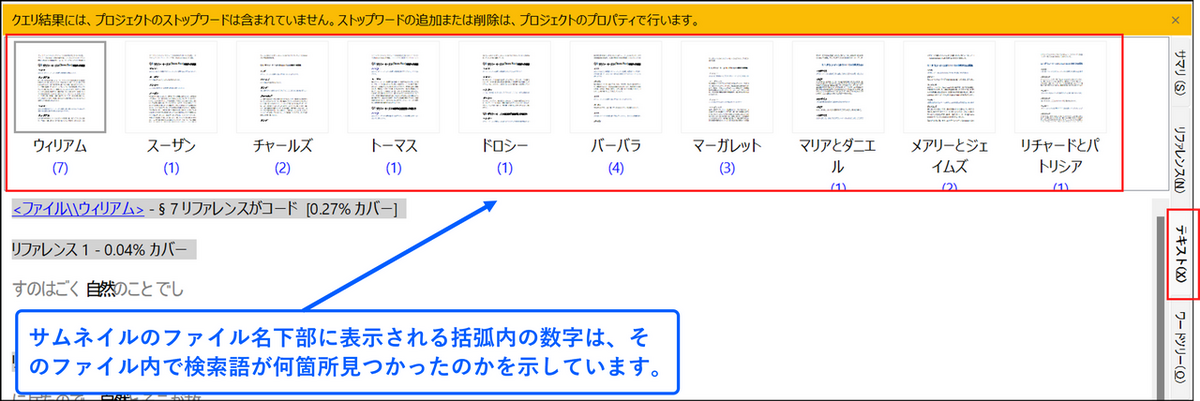
ファイルのサムネイルを選択すると、選択したファイル内で見つかったデータを確認することができます。
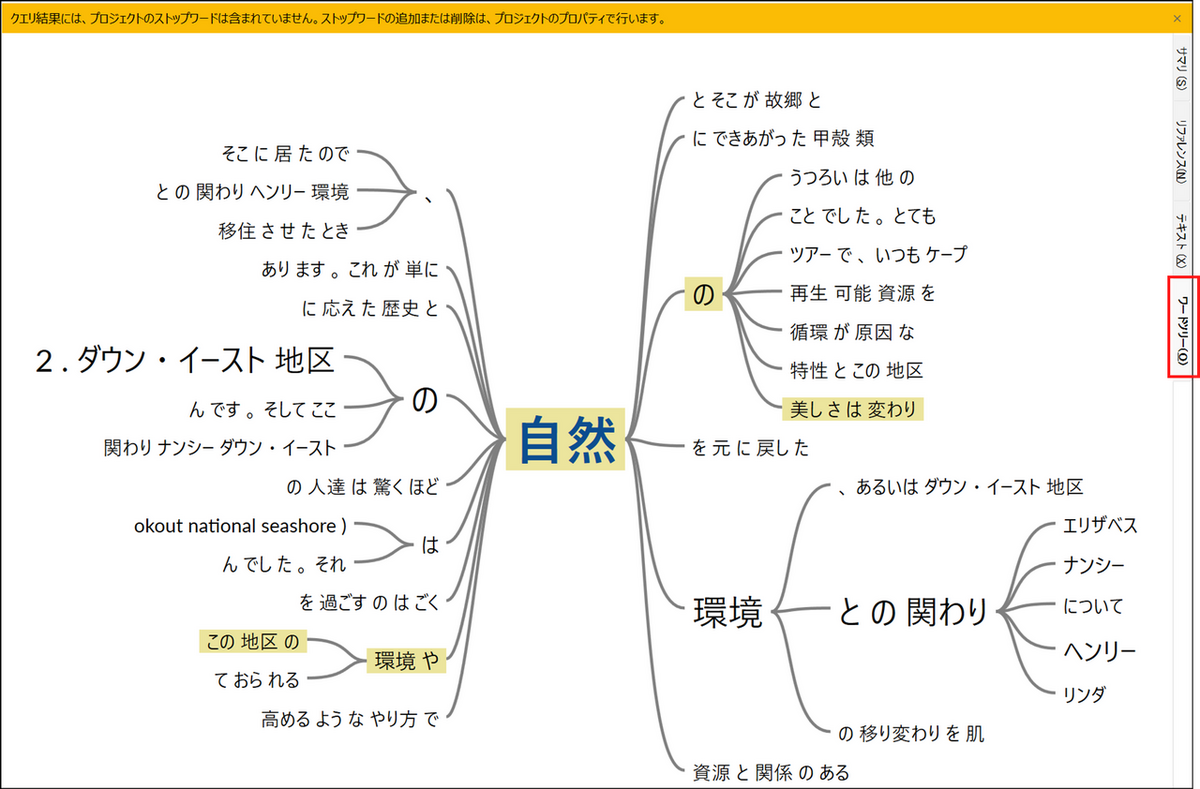
ワードツリー
[ワードツリー] タブを選択すると、その単語やフレーズの周辺に出現する単語がツリー形式で表示され、その単語を取り巻くテーマやフレーズを見つけることができます。フォントの大きさは、その単語やフレーズが見つかった数に応じて変化します。ワードツリー上の単語をクリックすると、他の関連単語がハイライト表示されます。
【注意】
[広帯コンテクスト] などで検索範囲を拡張した場合は、[ワード ツリー] タブは表示されません。検索範囲を拡張された場合は、[次の範囲に拡張] の項目を[なし] に変更し、再度検索を実行してください。
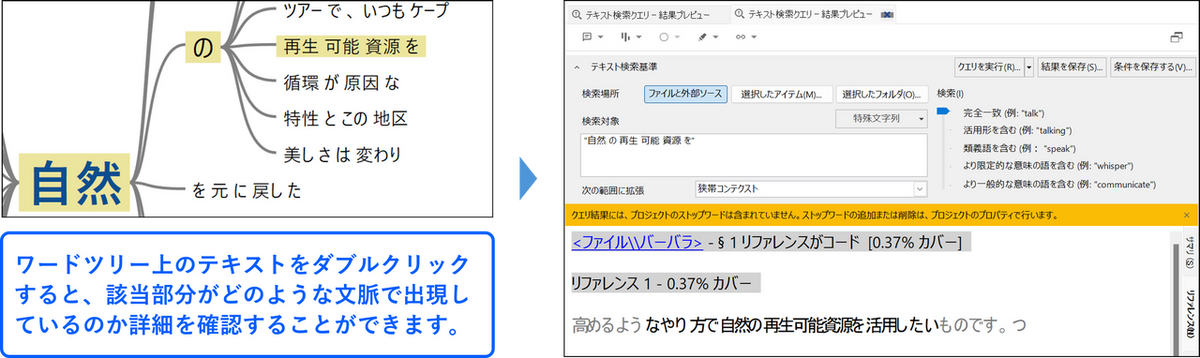
ワードツリーで気になる単語やフレーズがあれば、ダブルクリックすることで該当部分が出現するテキストの詳細を確認することができます。
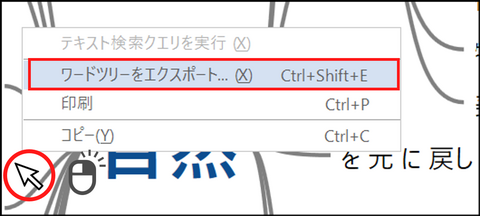
ワードツリーの画面上で右クリックし、[ワードツリーをエクスポート] を選択すると、画像として保存することが可能です。
メニューの[ワードツリー] で表示設定を変更することも可能です。
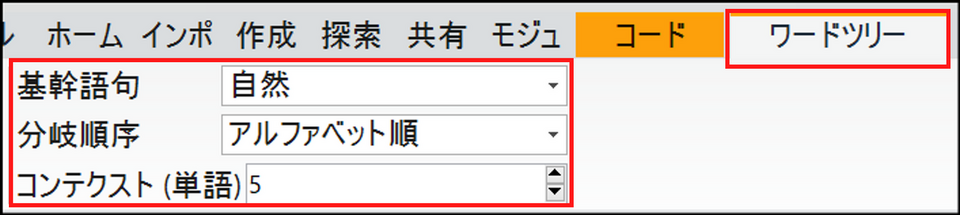
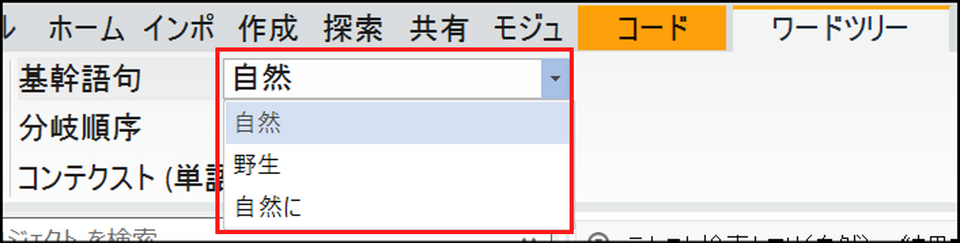
基幹語句
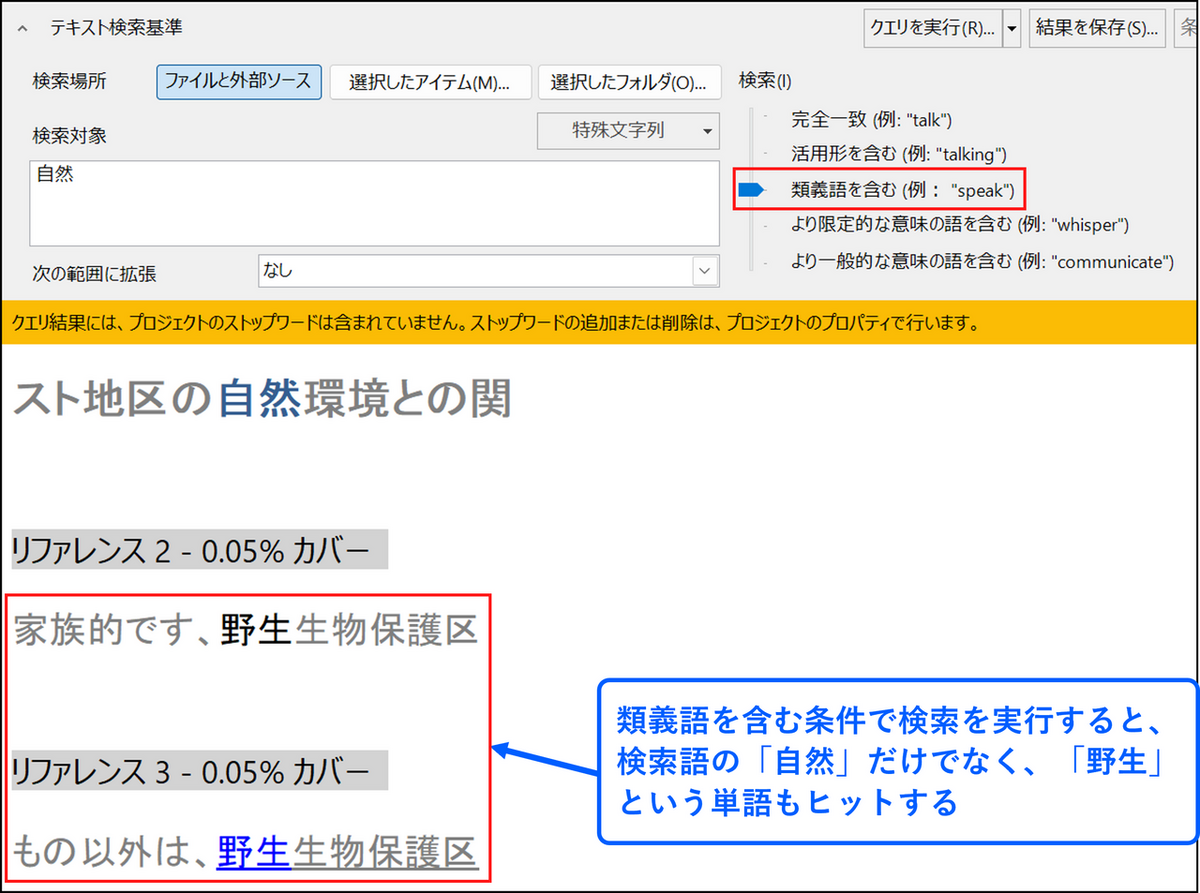
類義語の候補がある場合、基準となる単語を変更します。例えば、「自然」を検索して、類義語を含めると、「野生」が基幹語になる場合があります。類義語を含めた検索については「テキスト検索時の処理について」の項目をご参照ください。
分岐順序
ワードツリー枝部分の語句の表示順序をアルファベット順または出現頻度順に並び替えることができます。
コンテクスト(単語)
基幹語の両側に表示される語数を変更します。
検索条件を保存する
検索を実行後、検索条件を保存しておくことで、あとで同じ条件で検索を実行することができます。
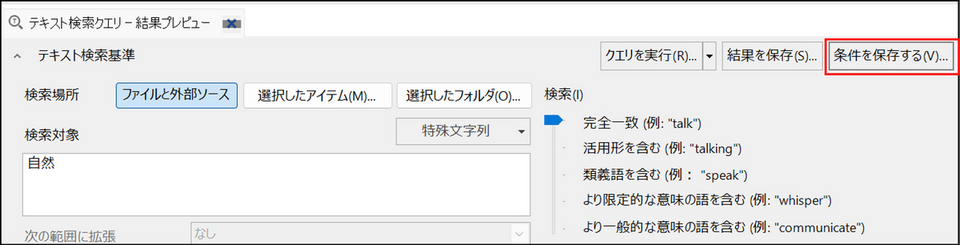
-
検索を実行後、[条件を保存する] ボタンをクリック
-
名前を入力し、[OK] ボタンをクリック
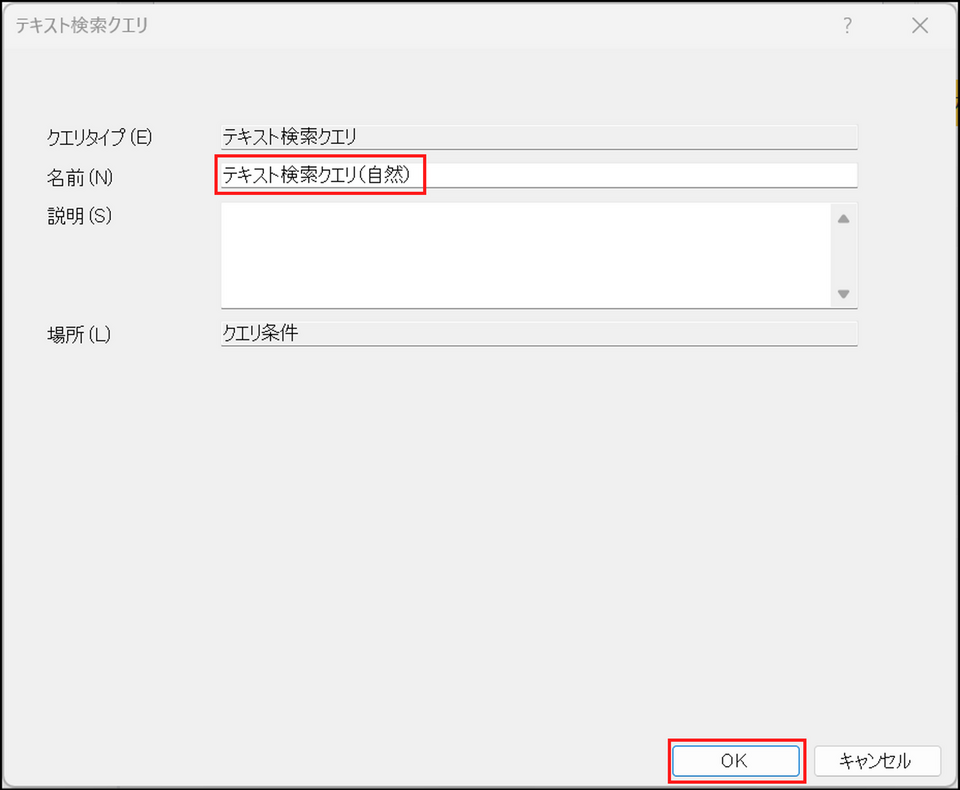
保存した検索条件は、ナビゲーションビュー[クエリ] > [クエリ条件] フォルダに保存されます。
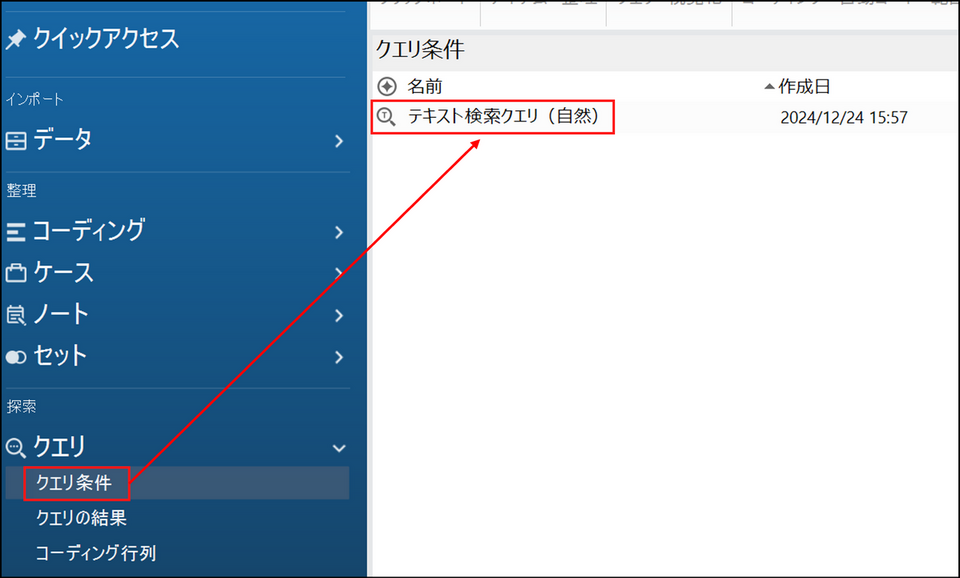
条件をダブルクリックすると保存した条件でテキスト検索クエリの画面が開きます。
検索結果をコードとして保存する
テキスト検索クエリの結果画面に表示されたテキストをそのままコードとして保存することも可能です。
-
検索を実行後、[結果を保存する] ボタンをクリック
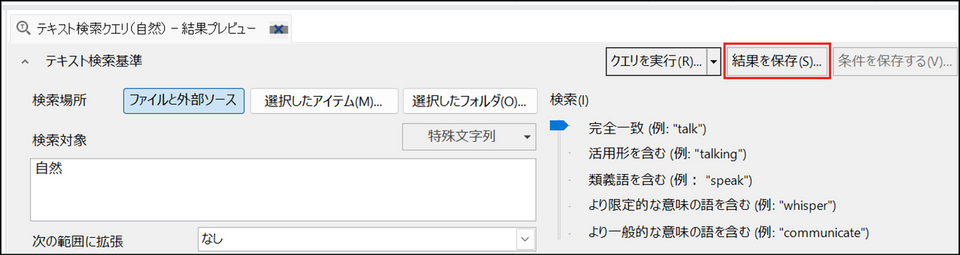
-
オプションで [結果を新しいコードまたはケースとして作成] を選択
-
場所の項目で[選択] ボタンをクリック
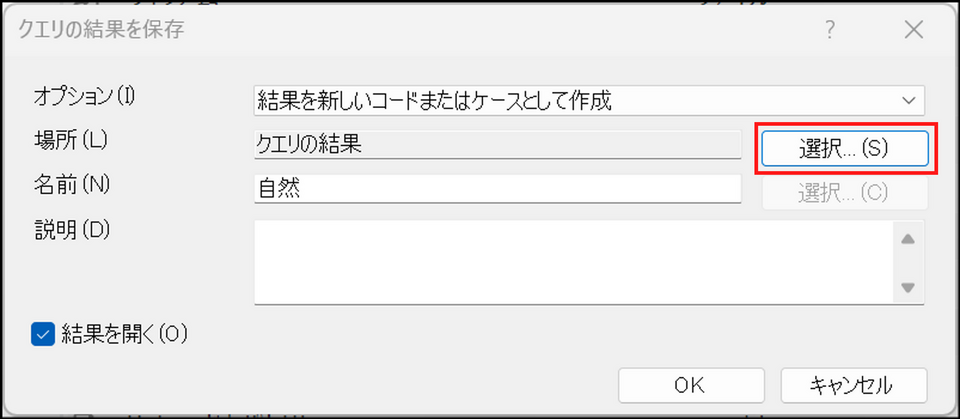
-
[コード] フォルダを選択し、[OK] をクリック
※すでにコードフォルダ内にサブフォルダを作成している場合は、保存先のフォルダを指定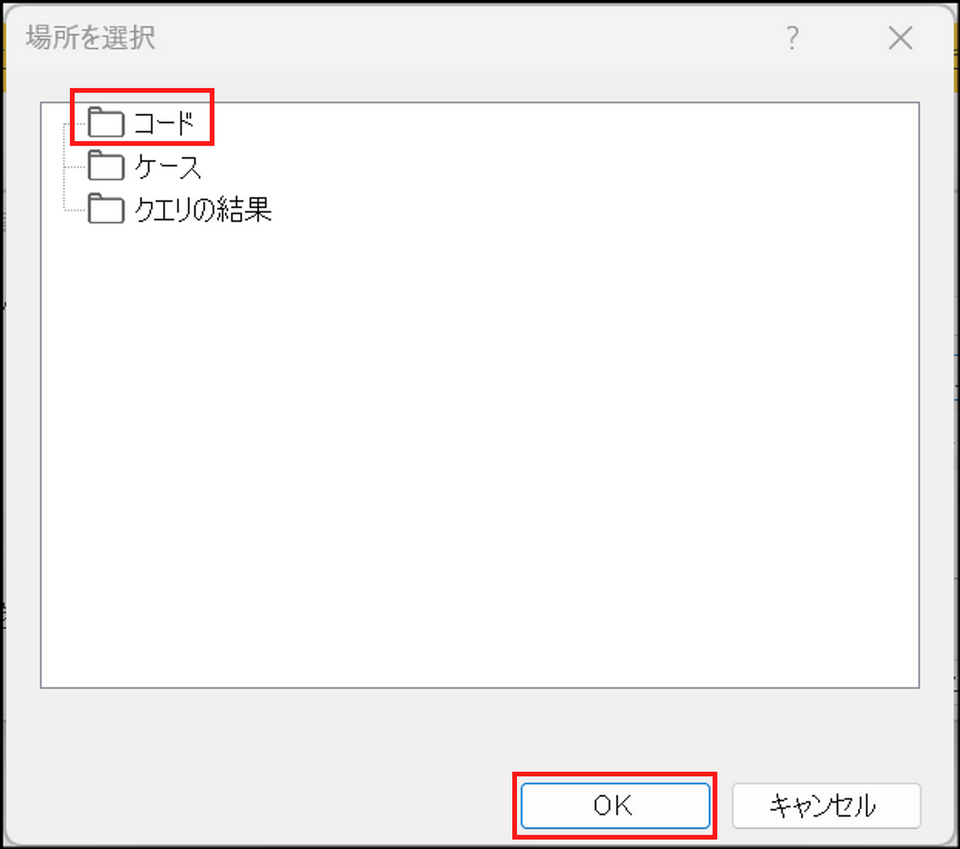
-
[名前] にコード名を入力し、[OK] ボタンをクリック
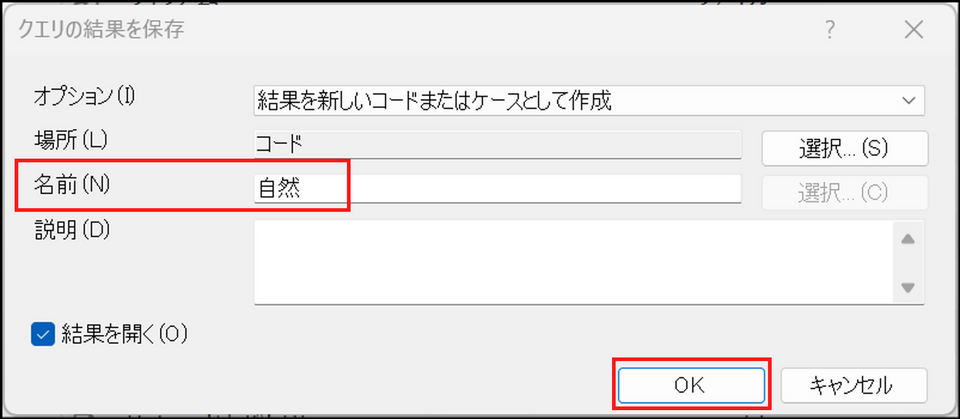
指定したフォルダにコードが保存されます。[結果を開く] にチェックを入れていた場合は、コードの内容が表示されます。
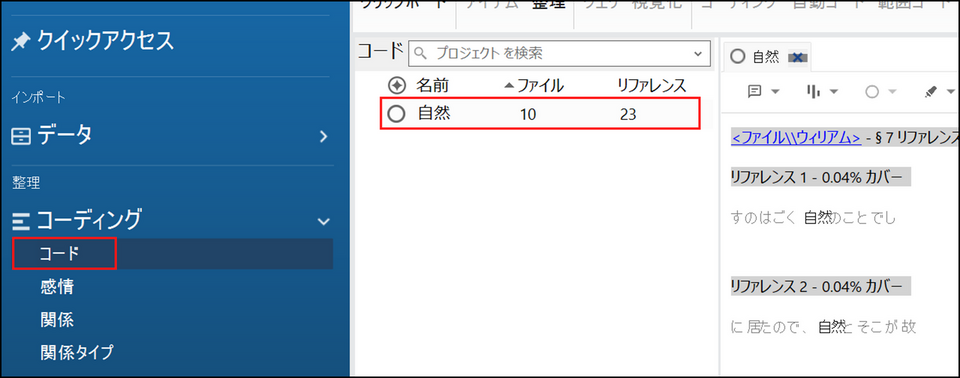
テキスト検索時の処理について
テキスト検索クエリでは完全一致だけでなく、同義語などの類似した単語も検索することができます。テキストマッチのレベルは5段階あり、スライダーで調整することができます。

レベルが高くなるにつれて、検索範囲が広がります。 なお、日本語の場合は活用形を考慮しないで検索するため、レベル1 と 2 の違いはありません。
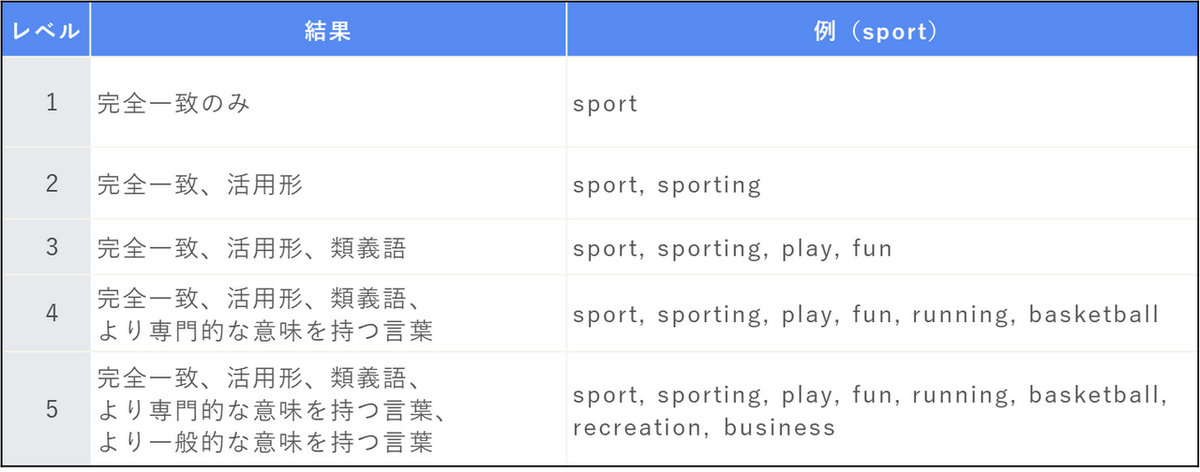
例)「自然」を[類義語を含む] 条件で検索した場合
覚えておくと便利な検索演算子や特殊文字
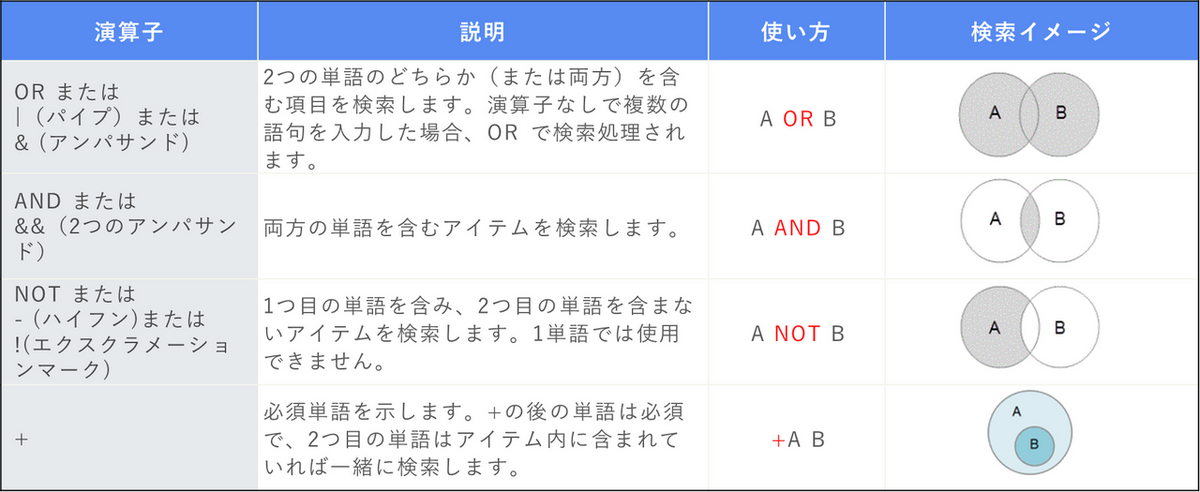
テキスト検索クエリでは演算子や特殊文字を使うことで、テキスト検索の幅を広げたり、結果を絞り込むことができます。

まとめ
NVivo のテキスト検索クエリは、プロジェクト内のテキストデータを効率的に分析するための強力なツールです。適切な検索条件を設定することで、必要な情報を迅速かつ正確に抽出することができます。本ページを参考に、テキスト検索クエリを活用して、分析にお役立てください。
参考ページ
- Operators & special characters
https://help-nv.qsrinternational.com/15/win/Content/queries/special-characters-operators.htm

