XLSTAT によるCATA データ分析:製品の特徴を明らかにする
記事執筆:一般社団法人学術・教育総合支援機構 芥川 麻衣子、川﨑 洋平
一般社団法人学術・教育総合支援機構公式HP:https://iaae.jp/
CATA とは?
CATA(Check-All-That-Apply) 法は官能評価で使われる分析手法の1つです。Check-All-That-Apply (該当するものすべてにチェック)の名称通り、パネリストに複数の評価用語の中から試料の特徴を表すと思う用語をチェックリストの中からすべてチェックしてもらい、その後それぞれの評価用語がチェックされた数をもとにして試料の特性を明らかにするという手法です。
例えば、複数のりんごをCATA 法で評価する場合は、パネリストにそれぞれのりんごを試食してもらい、あらかじめこちらが用意した特性(甘い、酸っぱい、にがい、など)に当てはまるものがあれば、それぞれチェックを入れてもらいます。また、パネリストには各りんごの好みを総合評価(0点から10点)してもらい、理想のりんごが持つ特性にもチェックを入れてもらいます。こうすることで消費者に好まれるりんごの特性や理想のりんごに近づけるために必要な特性を明らかにすることができます。
CATA 法の評価イメージ

このページではXLSTAT を用いてCATA 分析を行う手順と解釈について説明します。
CATA データ分析を実行するためのデータセット
このページでは6つのりんご(5つの品種と1つの理想とする品種)について、119名の消費者から得られたデータを使用します。このデータには15の評価語による評価と、理想とする品種を除く5つの品種の総合評価が含まれています。
回答データは以下のように各消費者と製品ごとに表形式でまとめてあります。
A 列:消費者のID
B 列:製品(りんご)のID。このデータでは5製品の評価。”Ideal” は理想の製品。
C 列:総合評価(0~10)
D 列以降:特性の情報(0/1)。0: その特性に当てはまらない、1: その特性に当てはまる。
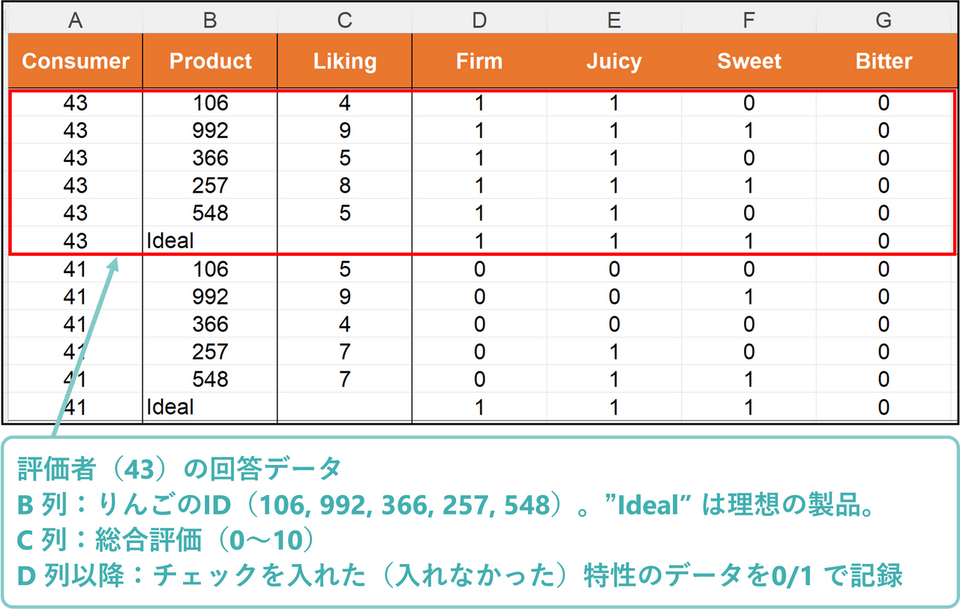
データの形式は1行に1消費者、1製品についての評価があり、縦に並んでいます。なお、データは全ての消費者が全ての製品について評価をしている状態でなければなりません。
サンプルデータのダウンロードはこちらから
demo_CATA_EN_0.xlsCATA データ分析の操作手順
-
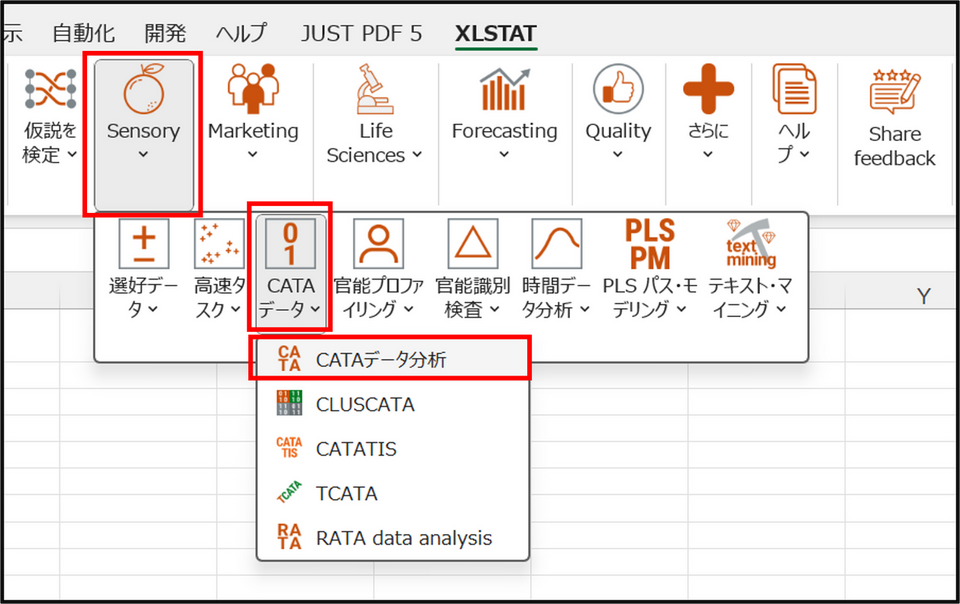
XLSTAT を起動し、[Sensory] > [CATA データ] > [CATA データ分析] を選択します。
-
ダイアログボックスが表示されるので、下記項目を指定します。
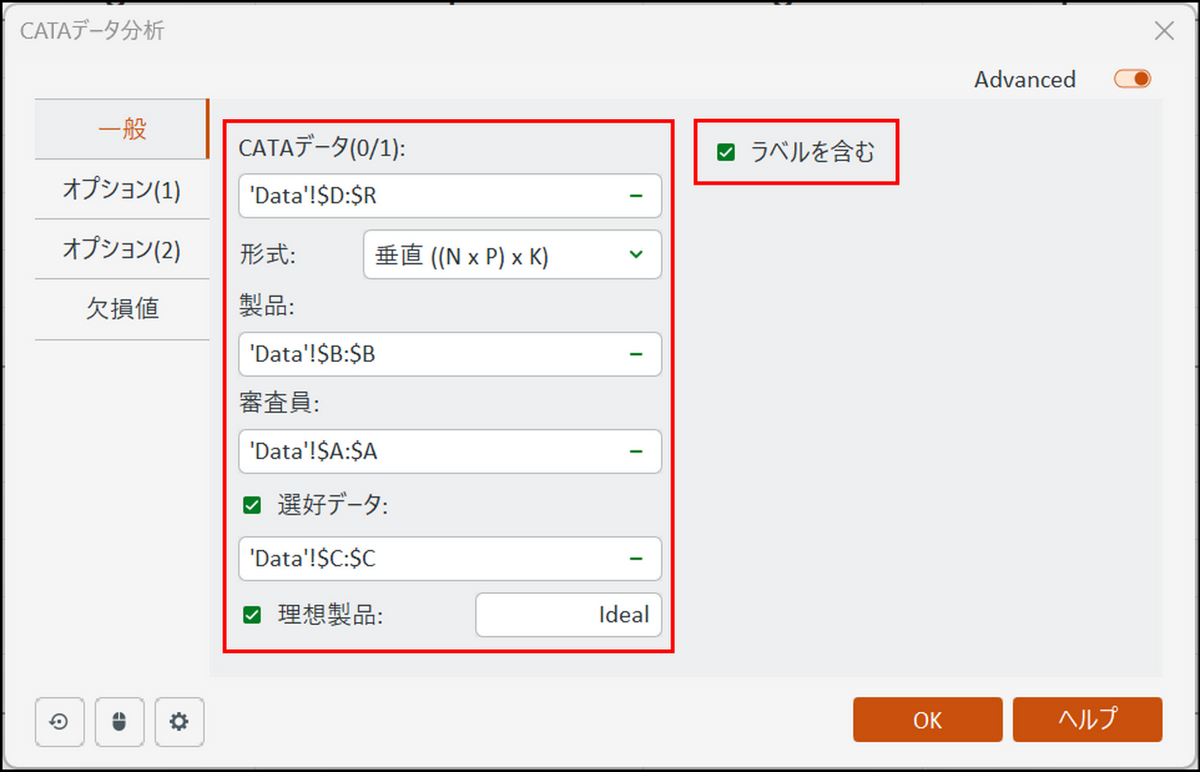
- [CATAデータ(0/1)]:
評価語による評価の部分を選択します。今回のデータであれば、D 列からR 列を選択します。 - [形式]:
今回のデータは縦に並んだデータのため、 [垂直] を選択します。 - [製品] :
Products の列を選択します。 - [審査員]:
Consumer の列を選択します。 - [選好データ]:
チェックを入れ、Liking の列を選択します。 - [理想製品] :
チェックを入れ、理想的な製品を表す語”Ideal” を入力します。
- [CATAデータ(0/1)]:
-
[オプション(1)] タブに切り替え、下記項目にチェックを入れます。
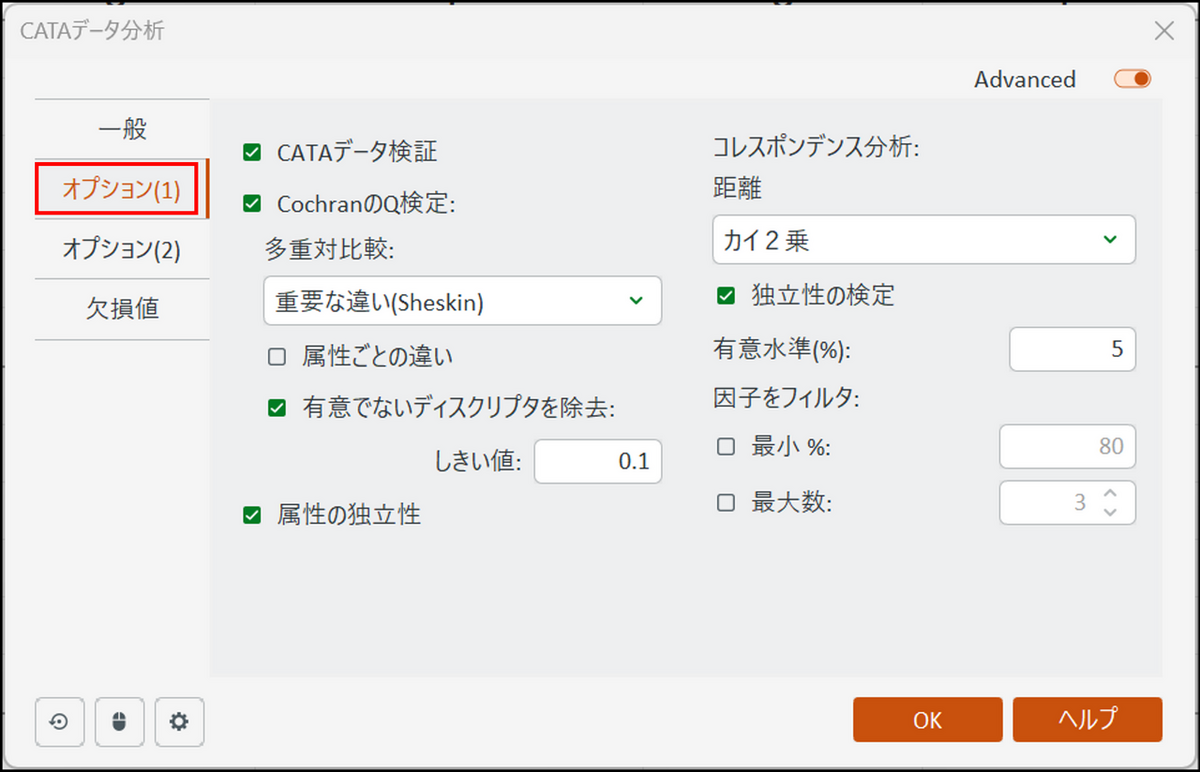
- [CATAデータ検証]:
- [CochranのQ検定]:
- [多重対比較] の項目では [重要な違い(Sheskin)] を選択します。これはSheskin の手法に基づく多重比較の方法です。
- [有意でないディスクリプタを除去]:
チェックを入れ、[しきい値] は「0.1」に設定します。 - [属性の独立性]:
- [距離]: [カイ2乗] を選択します。
- [独立性の検定] :
チェックを入れ、[有意水準(%)] を「5」に設定します。
-
[OK] ボタンをクリックすると、計算が実行されます。
-
ダイアログボックスが表示され、コレスポンデンス分析のグラフに表示する軸の選択と確認ができます。
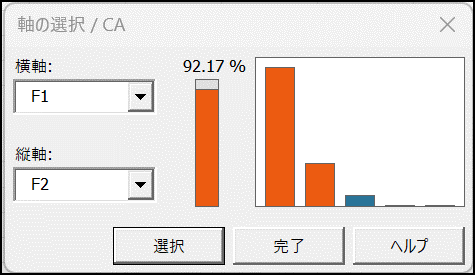
今回はこのままF1 と F2 を選択した状態で実行します。[完了] をクリックすると、結果が別シート(CATA)に出力されます。
CATA データ分析の結果の解釈
CATA データ分析の結果は、表とグラフで表示されます。前半では、CATA データの検証結果を確認します。
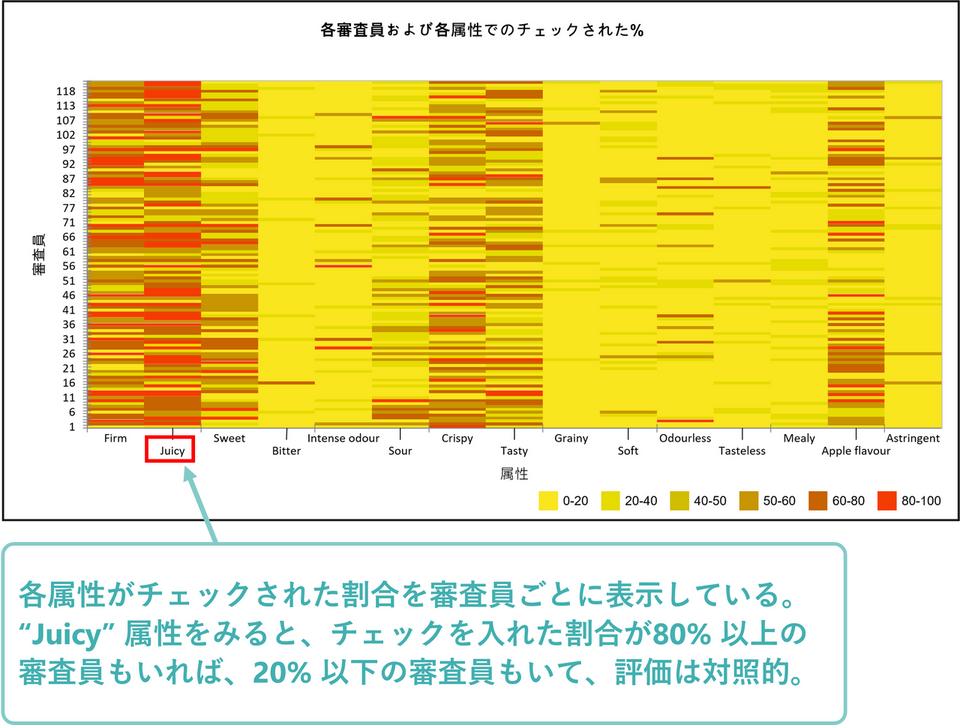
チェックを入れた属性数の割合
最初の表とグラフでは消費者ごとにチェックを入れた属性数の割合を示しています。この項目ではチェックを入れた回数が極端に多い、もしくは少ない消費者がいないかを確認します。

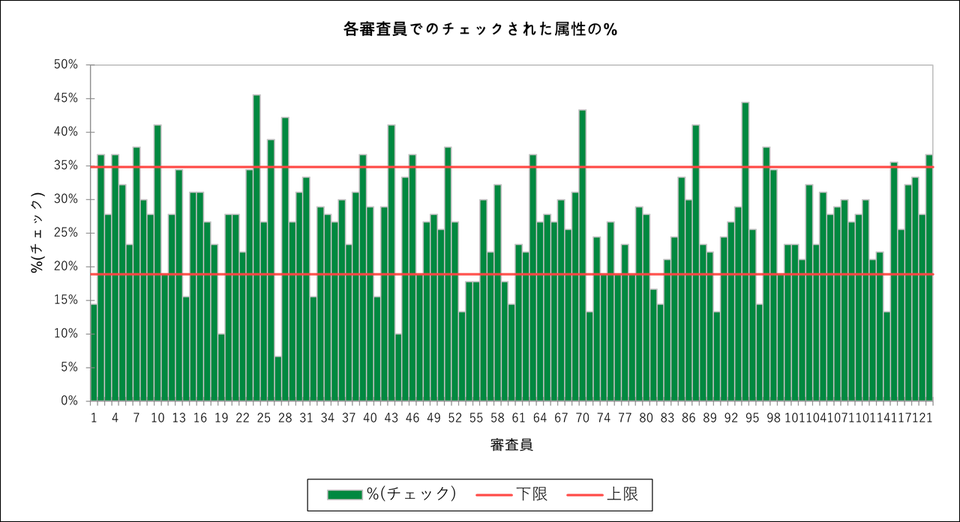
今回のデータでは、20〜35%の割合でチェックを入れた消費者が大半でしたが、ID 27 の消費者はたった7%しかチェックしていないということが分かります。
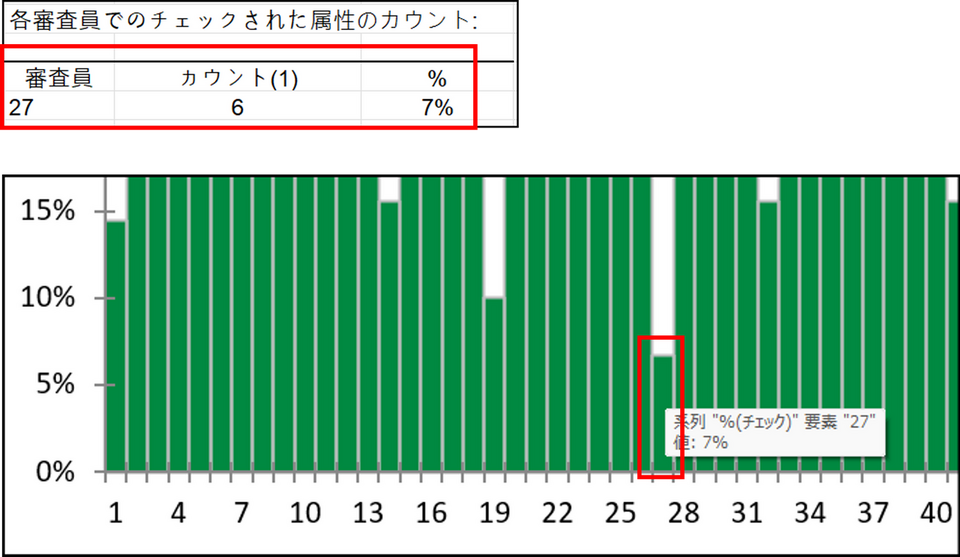
続いて評価語毎にチェックされた属性の割合が表示されます。
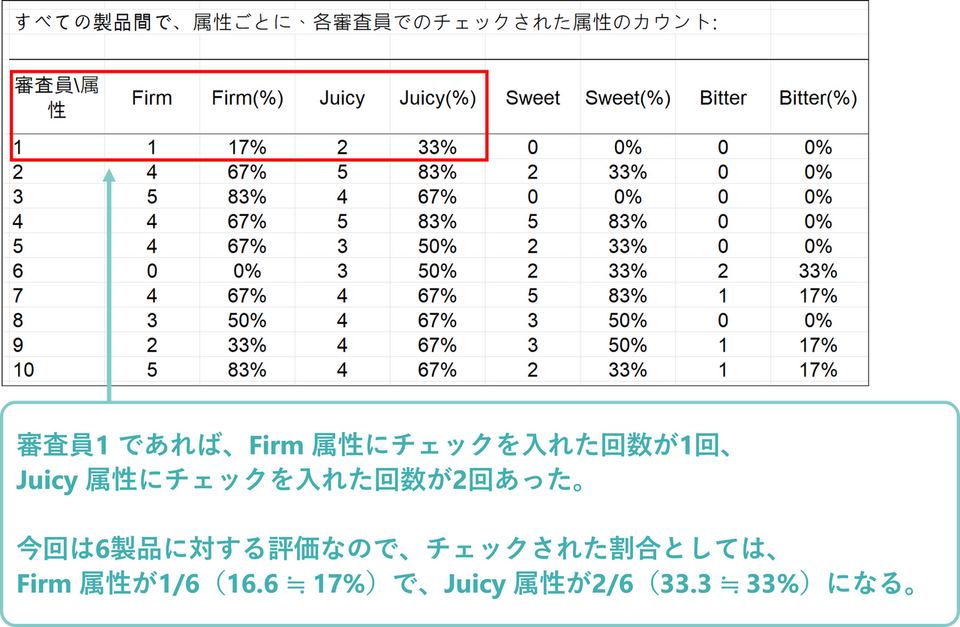
消費者と評価語の掛け合わせたグラフを見ると、”Juicy” という評価語は6品種中チェックされた割合が20%以下の消費者もいれば、80%以上の消費者もいて、対照的な評価語というのが分かります。
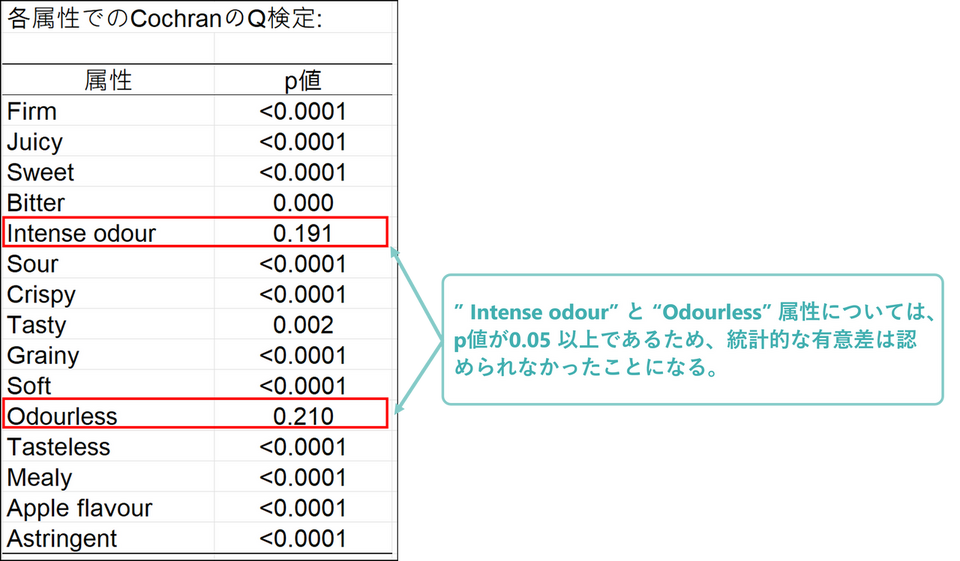
コクランのQ検定
コクランのQ検定とは、対応のある3群以上の2値変数についての割合を比較するための検定です。詳細については下記ページも合わせてご参照ください。
XLSTAT によるコクランのQ検定:製品デザインの好みを比較しよう!
今回の結果では、” Intense odour” と “Odourless” 以外の属性では有意な差があることが分かります。
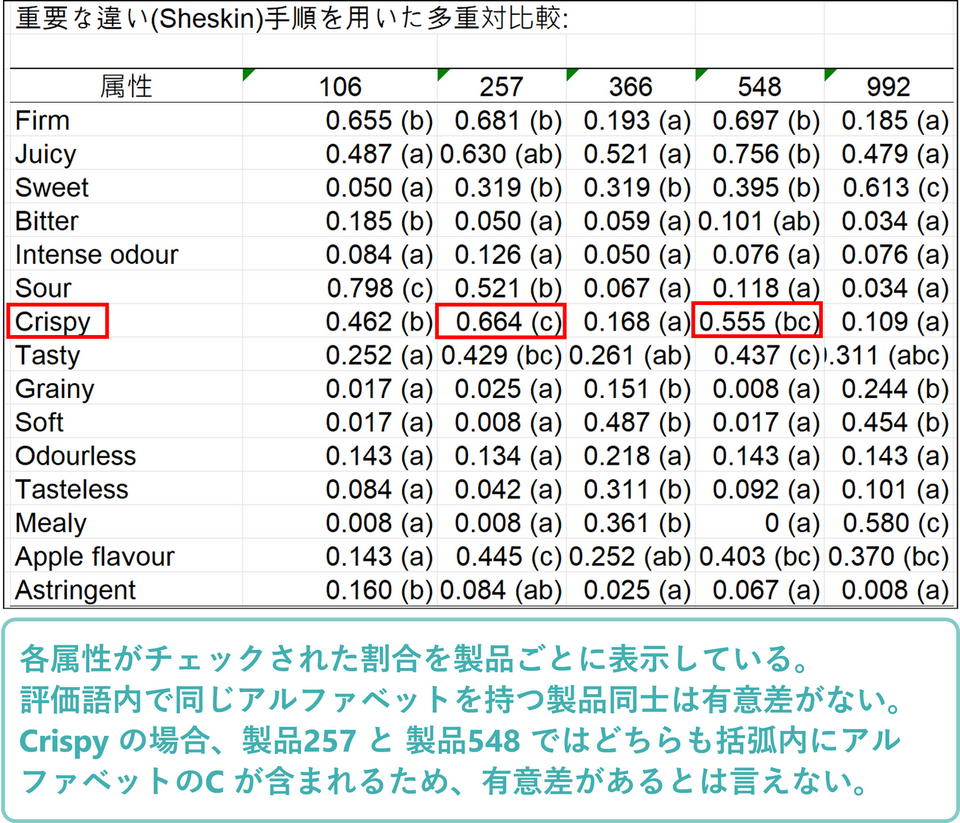
多重比較の結果は、評価語ごとにチェックされた割合を示しています。括弧内のアルファベットは評価語内で同じアルファベットを持つ製品同士は有意差がないという見方です。例えば、”Crispy” という評価語に着目すると、製品257 が最もチェックされていますが、次に多い製品548 にもアルファベットのC がついているので、有意差があるとは言えません。他の品種とは有意差があると言えます。
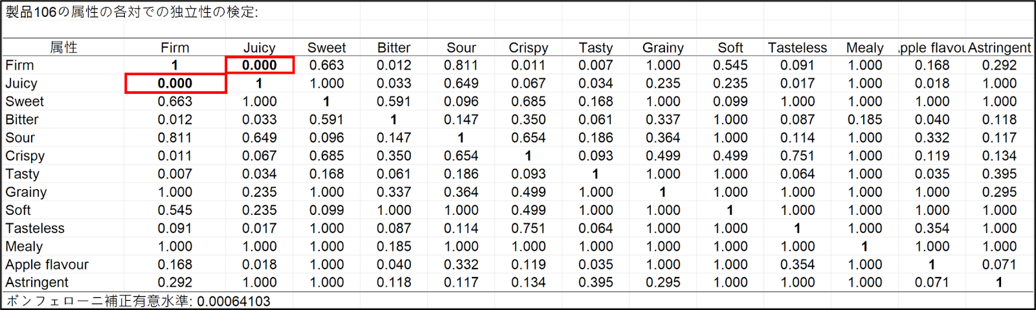
評価語の独立性の検定からは評価語が冗長でないかを判断します。例えば、製品106 について、”Juicy” と ”Firm” は冗長であり、評価が似通ってしまっていることがわかります。
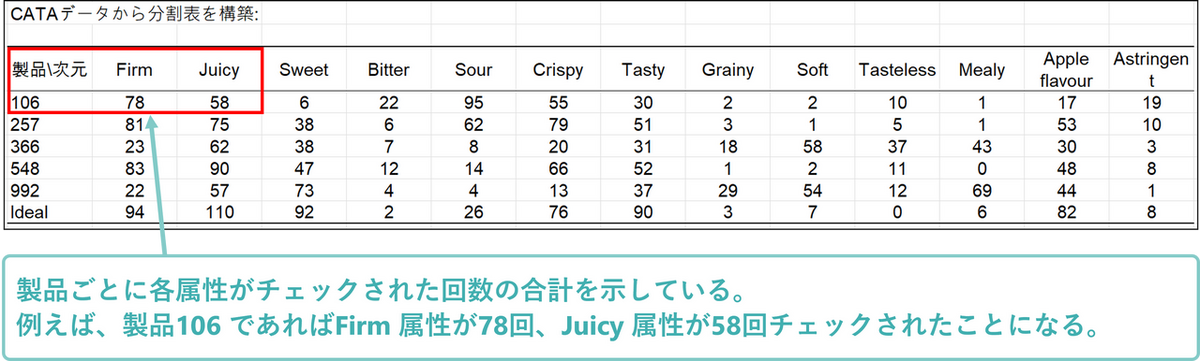
分割表
分割表は、製品ごとに各属性がチェックされた回数の合計値が記載されています。これは次のコレスポンデンス分析(CA)を構築するために使用されます。
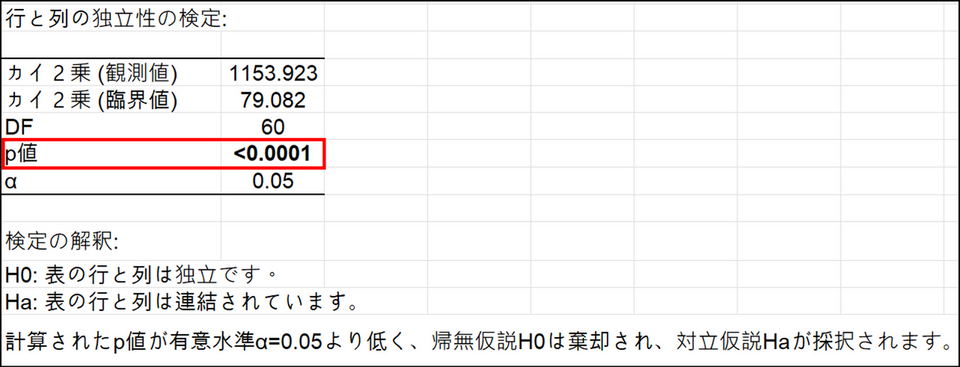
行と列の独立性の検定
上記分割表の独立性を検定します。この検定が有意(p値<0.05)ということは、評価語による官能的プロファイルに関して製品間に違いがあると考えてよいことを表しています。こちらの独立性の検定は現在古典的なコレスポンデンス分析(カイ2乗距離を使用)のみ可能です。
コレスポンデンス分析
続いてコレスポンデンス分析の結果が表示されます。コレスポンデンス分析は、アンケート調査などで得られた2つのカテゴリ変数間の関係を調べるための手法です。詳細については下記ページも合わせてご参照ください。
XLSTAT によるコレスポンデンス分析:映画の評価と観客の年齢層の関係を探る
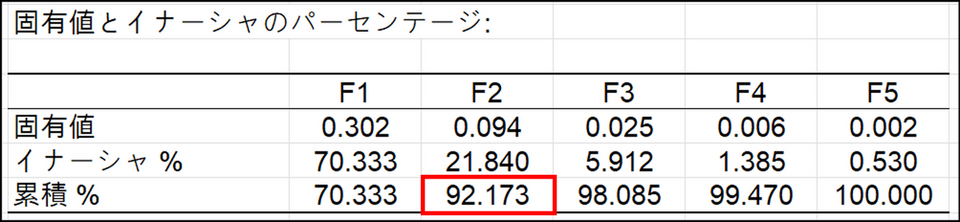
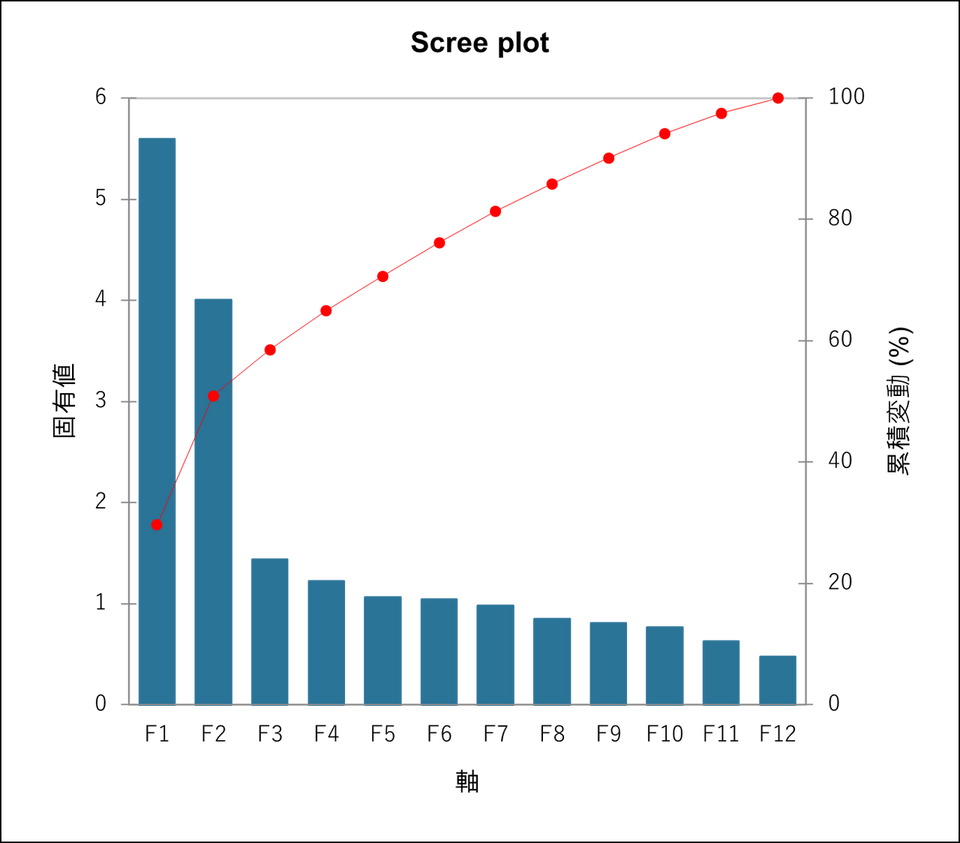
コレスポンデンス分析(固有値)
固有値は各因子(次元)によって抽出された分散に対応しており、分析結果の要約度合いを示しています。分析の質を評価するには、固有値の表か、それに対応するスクリープロットを参照します。最初の2つ(または数個)の固有値の合計が全体の分散に近い場合、分析の質は非常に高いと言えます。今回の例では最初の2つ(F1 と F2)の固有値の合計が全慣性(total inertia)の92%(70.333 + 21.840)を占めているため、分析結果は良好であると判断できます。
コレスポンデンス分析(対称プロット)
次に、行と列の対称プロットが表示され、因子 F1 と F2 上で、各属性と製品がどこに配置されているかを確認できます。赤字で表記されているのは特性の情報、青字で表記されているのは製品の情報です。理想の製品は緑色の△で表示されています。関係の強い要素同士は近く、関係の弱い要素同士は遠くに配置されるようになっています。
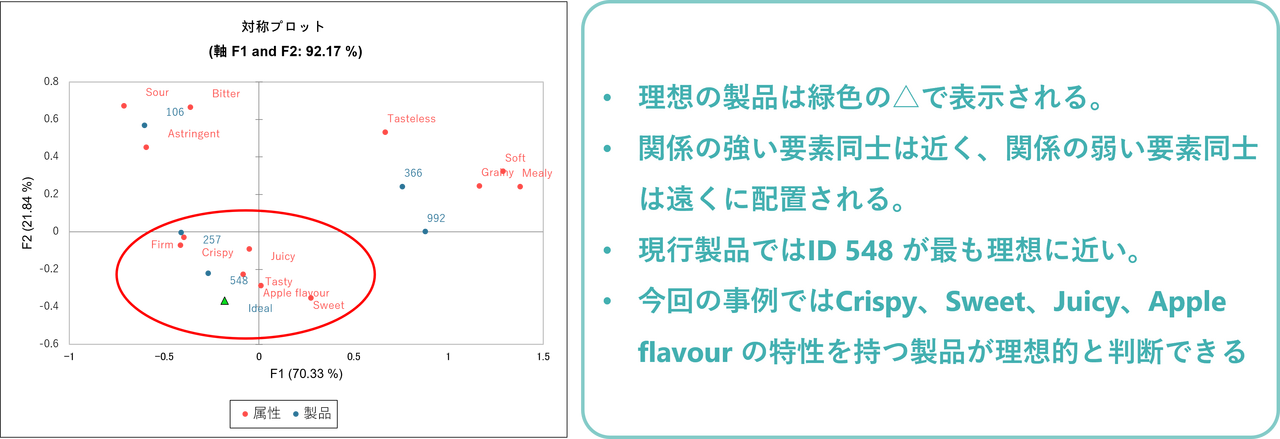
今回の事例では、理想的な製品はしっかり歯応えがあり(Crispy)、甘くて(Sweet)ジューシー(Juicy)でりんごの風味がある(Apple flavour)ものということが分かります。一方、酸っぱい(Sour)、渋い(astringent)、粒々している(Grainy)、やわらかい(Soft)、粉っぽい(Mealy)、味がない(Tastless)りんごは、理想から遠いと言えます。製品548 は理想的な製品に最も近いと言えますが、製品106 は酸味、甘味、渋みがあると評価され、理想的な製品からは遠いと言えます。このように評価対象の製品が持つ特性と理想製品の特性をマッピングすることにより、理想の製品に重要な要素を探しだすことができます。
コレスポンデンス分析(相関行列)
属性と総合評価を含めた相関行列が表示されます。例えば、甘味と酸味は負の相関があります。これは、製品に対して甘味を感じる時、酸味は感じない、或いは酸味を感じる時は、甘味は感じないということを示しています。総合評価に対する相関を見ると、理想的な製品と結びつきのあったジューシー、おいしい、りんごの風味が弱いながらも正の相関があるようです。

主成分分析
続いて主成分分析の結果が表示されます。主成分分析は、多数の変数を持つデータを、より少ない指標や合成変数(主成分)に要約する統計学的な分析手法です。詳細については下記ページも合わせてご参照ください。
XLSTAT による主成分分析:アメリカ51州の人口変動から地域別の特徴と傾向を探る
主成分分析(固有値)
固有値はコレスポンデンス分析と同様の解釈となります。分析の質を評価するには、固有値の表か、それに対応するスクリープロットを参照します。今回の例では最初の2つ(F1 と F2)の固有値の合計が全慣性(total inertia)の50.88%(29.652 + 21.230)です。

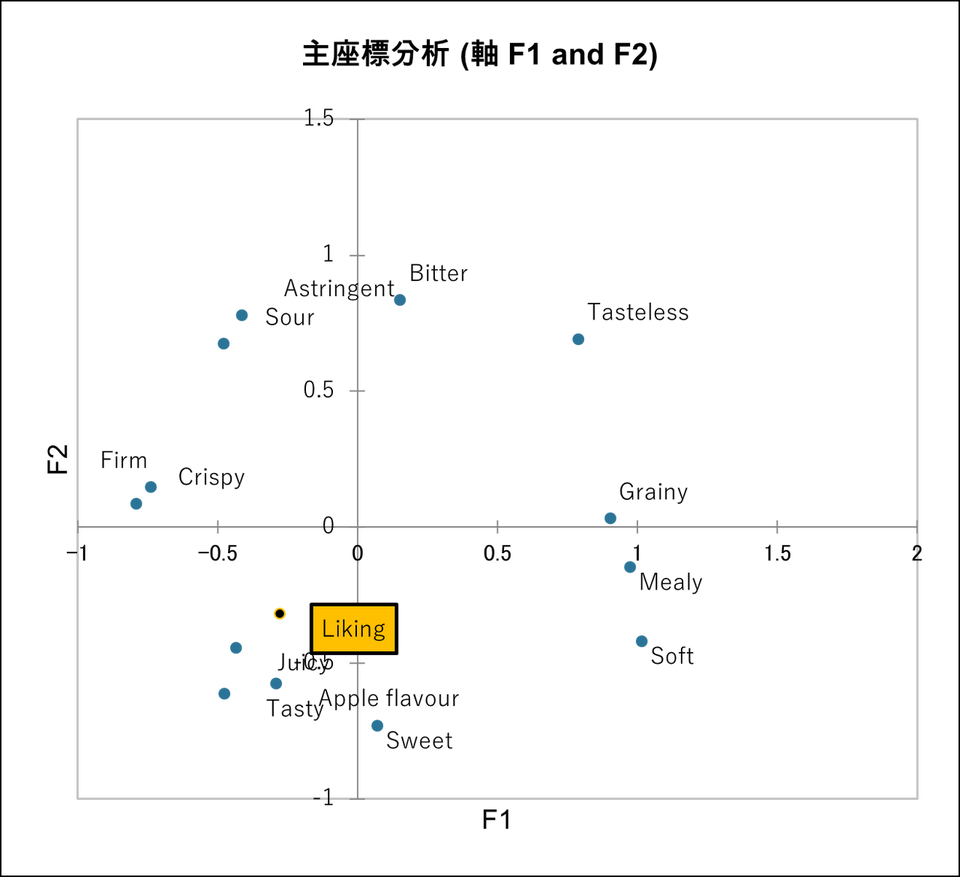
主成分分析(主座標分析)
こちらも行と列のF1(factor 1)を横軸、第二主成分であるF2(Factor 2)を縦軸とした主座標分析から読み取ります。総合評価”Liking” の近くに”Jucy”, ”Tasty”, ”Apple flavour” があり、コレスポンデンス分析の結果と同様に甘さ、ジューシーさ、リンゴの風味が選好に寄与することを示しています。
ペナルティ分析
続いてペナルティ分析の結果が表示されます。ペナルティ分析は、消費者のフィードバックに基づいて、製品の特性改善を目指す官能データ分析です。詳細については下記ページも合わせてご参照ください。
なお、ペナルティ分析は総合評価の項目がある場合に出力可能です。
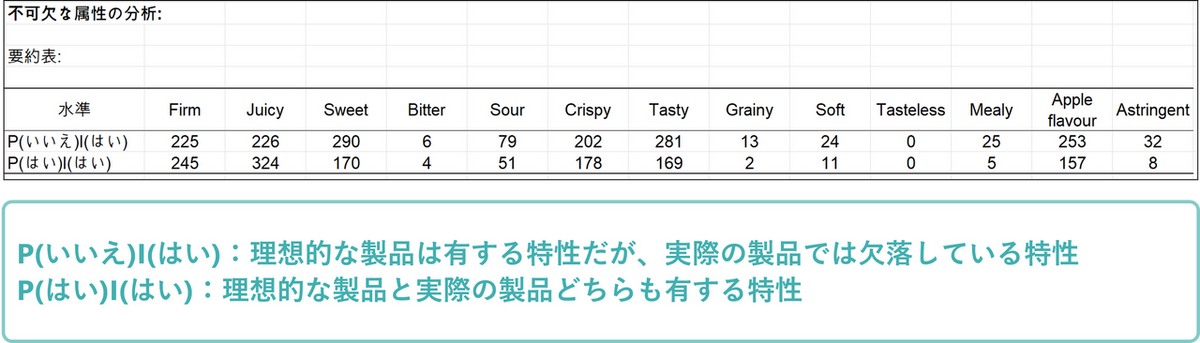
ペナルティ分析(不可欠な属性の分析)
次の結果では総合評価を高めるために「不可欠な属性」 を見つけるための情報が表示されます。この表では評価語ごとに、「理想的な製品ではチェックされたが、他の製品ではチェックされなかった(理想的な製品は有する特性だが、実際の製品では欠落している特性)(P(いいえ)|(はい))」と「理想的な製品でチェックされ、他の製品でもチェックされた(理想的な製品は有する特性であり、かつ実際の製品でも有する特性)(P(はい)|(はい))の頻度と割合を示しています。
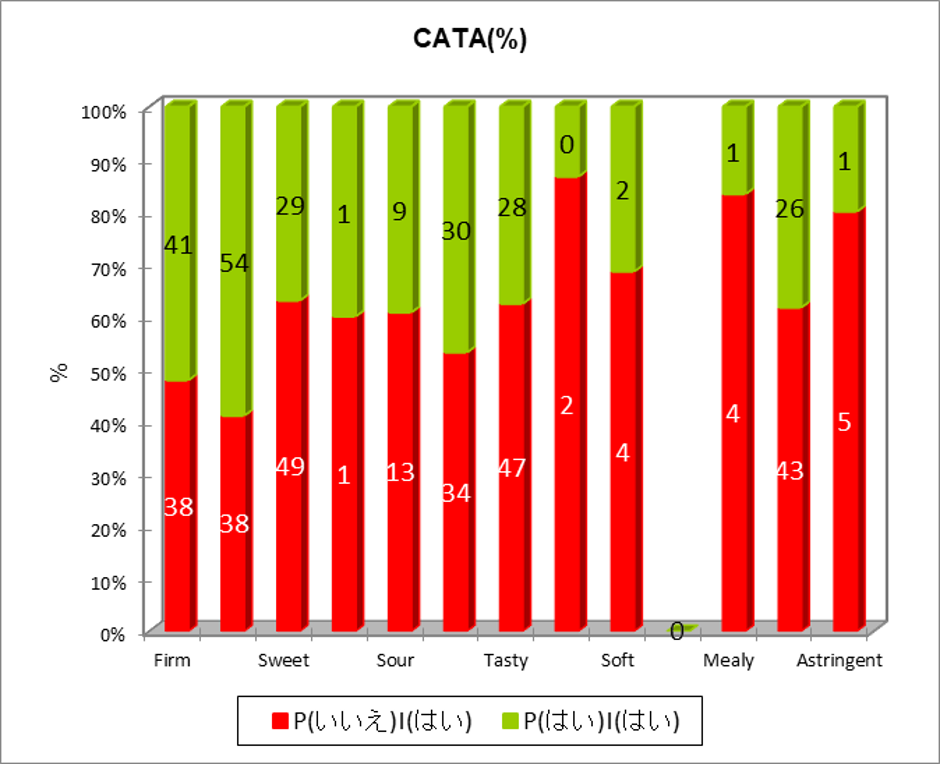
ペナルティ分析(比較表)
次に、”P(いいえ)|(はい)” と ”P(はい)|(はい)” の2群における総合評価の平均値の差を”平均降下”として検討します。平均降下とは、理想的な製品に比べて、他の製品がその評価語の影響で総合評価の得点を低くしていると解釈されます。例えば総合評価の平均値について、”firm” の ”P(いいえ)|(はい)” 群は「5.604」、”P(はい)|(はい)” 群は「7.118」です。表にある”平均降下” は「P(はい)|(はい)- P(いいえ)|(はい)」で「1.514」です。”firm”という属性がないことにより総合評価の得点を「1.1514」低くしていると解釈されます。

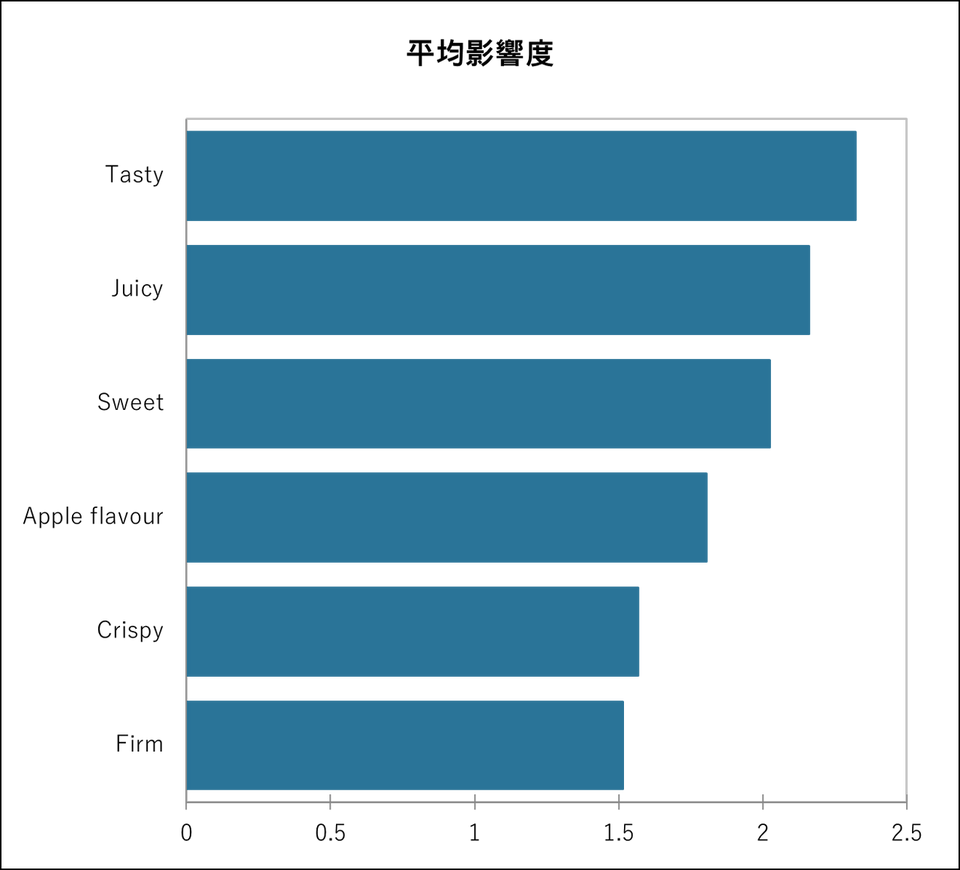
ペナルティ分析(平均影響度)
平均影響度とは、平均降下について、有意差があったものを大きい順に棒グラフで示しています。増加は青、減少は赤の棒グラフで表されます。青の棒グラフは、平均値を増加させる” 不可欠な要素” と言えます。
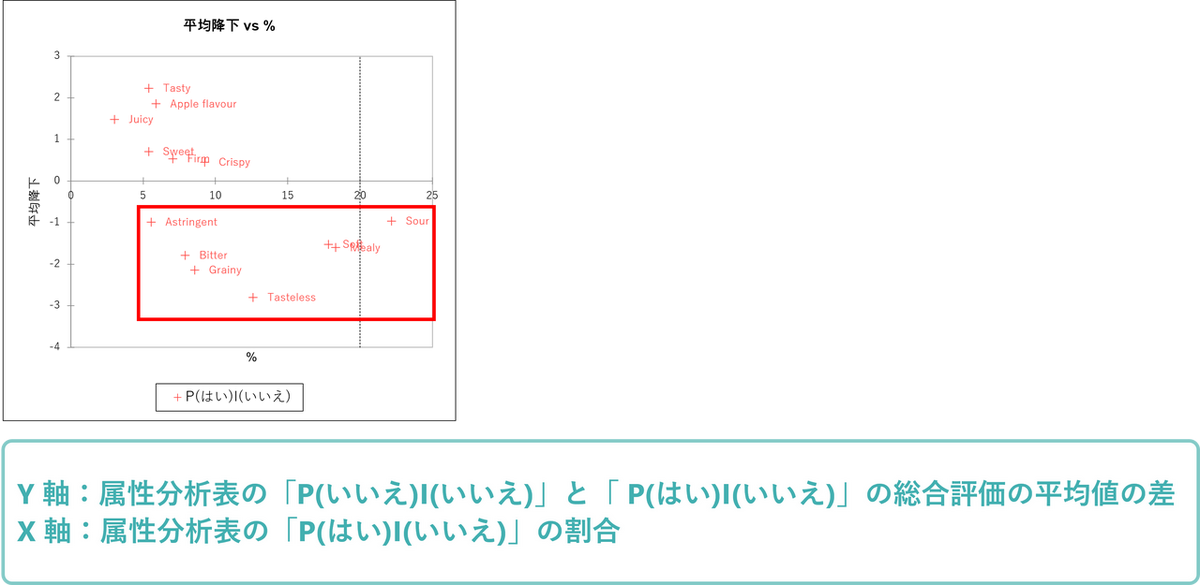
「平均降下 vs. 割合チャート」による「必須属性」と「あると良い属性」の特定
次に平均降下と割合のチャートを確認します。このチャートでも「なくてはならない」要素を特定します。各軸の意味は以下の通りです。
- Y 軸:
消費者が現在の製品と理想的な製品の両方でチェックを入れた群と理想製品だけでチェックを入れた群の、総合評価の平均値の差。 - X 軸:
理想的な製品でチェックを入れ、現在の製品ではチェックを入れなかった割合。
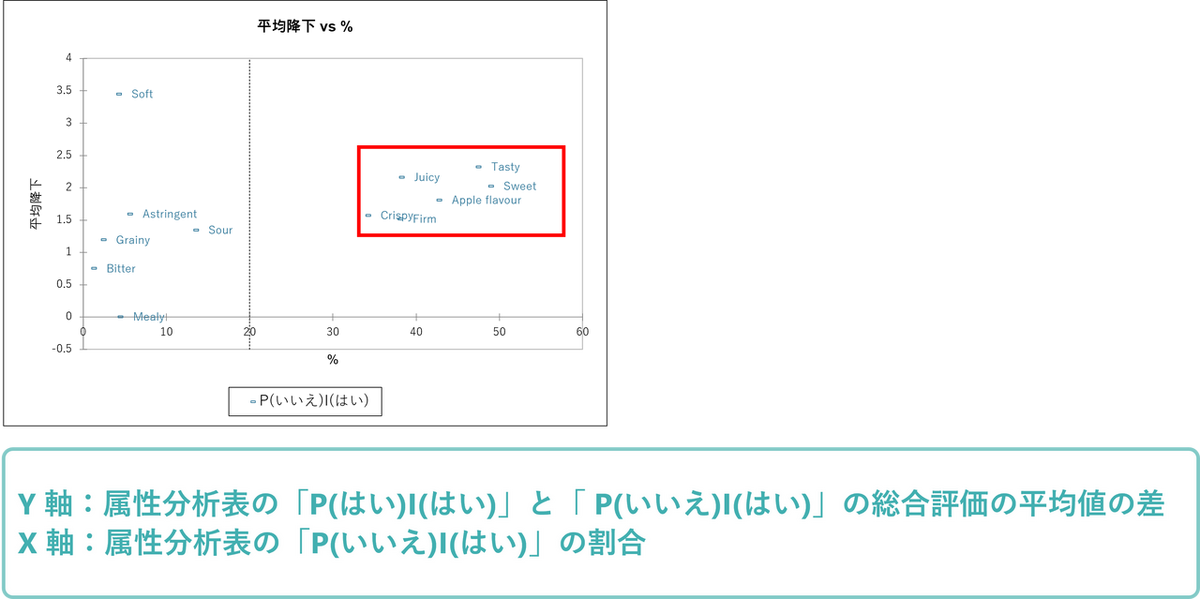
従って、平均値の増加が大きく、割合も大きいものは「不可欠な要素」と言えます。今回の事例では、”Tasty”, “Sweet”, “Juicy”, “Apple flavour”, “Crispy”, “Firm” がここでも必須の要素であることが示唆されています。
ペナルティ分析(「あると良い属性」と「否定的な属性の分析」)
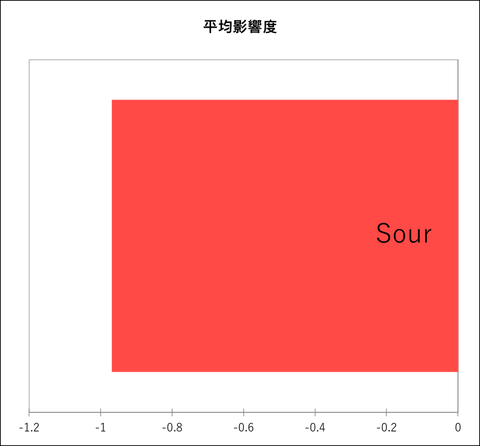
次は総合評価を高めるために「あると良い属性」を見つけるための情報を表示します。結果表の流れは総合評価を高めるために「不可欠な属性」を見つける分析と同じです。平均影響度チャートは、有意な平均影響を持つ属性を示します。平均の上昇は青色で表示され「好ましい」、平均の下降は赤色で表示され「あってはならない」属性として識別されます。今回の事例では”Sour” 属性のみが「あってはならない」属性として特定されています。
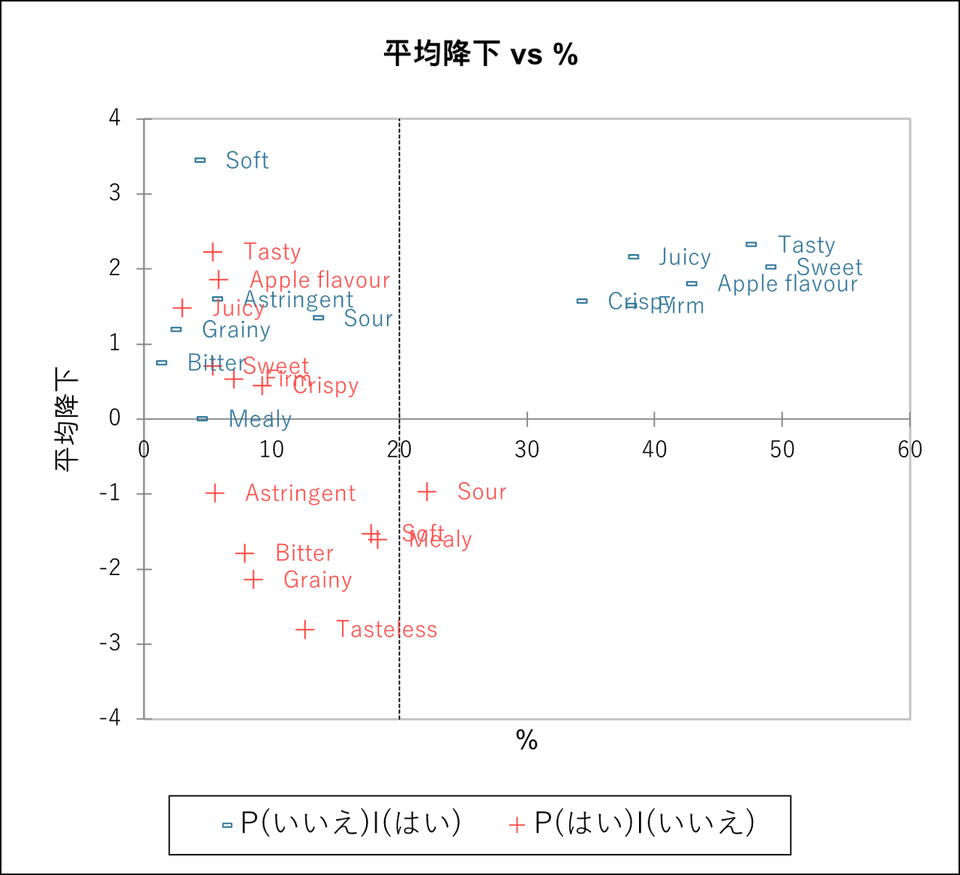
「平均降下 vs. 割合チャート」による「必須でない属性」と「あると良い属性」の特定
平均降下と割合のチャートについて、今度は「必須でない属性」と「あると良い属性」を特定します。各軸の意味は以下の通りです。
- Y 軸:
消費者が現在の製品と理想的な製品の両方でチェックを入れなかった群と現在の製品だけでチェックを入れた群の、総合評価の平均値の差。 - X 軸:
現在の製品でチェックを入れ、理想的な製品ではチェックを入れなかった割合。
読み取りは先に説明した「必須属性」と「好ましい属性」の特定と同様です。これは、属性が実際の製品をよく表しているものの、理想製品ではあまり選択されていない状況に対応しています。
したがって、Y 軸で低い座標に関連付けられている属性("Astringent”, “Bitter”, “Grainy”, “Tasteless”, “Soft”, “Mealy”, “Sour”)は、ここでも「あってはならない」と見なされています。
ペナルティ分析の要約
上記2つのペナルティ分析の結果を1つのグラフに要約しています。ここでもまた、"Tasty", "Sweet", "Apple flavor", "Firm", "Crispy", "Juicy" が不可欠な属性として現れ、"Sour" は「あってはならない」属性として現れています。
属性ごとの分割表
次に、評価語ごとに 2x2 の分割表が表示されます。各表の左側には理想的な製品の値、上部には調査対象製品の値が示されます。セルには総合評価の平均値(消費者と製品を合わせた)と割合が示されています。表の読み取り方法は下記の図の通りです。

上記の解釈に基づき、Firm 属性を確認すると、理想的な製品と実際の製品の両方にチェックがされた場合(セル [1,1]) の値(7.1)が、理想的な製品にのみチェックされた場合 (セル [1,0]) の値(5.6)よりも高いので、Firm 属性は「不可欠」と判断されます。

一方でSour 属性を確認すると、理想的な製品と実際の製品どちらにもチェックされていない場合(セル [0,0]) の値(6.6)が、実際の製品にのみチェックされた場合 (セル [0,1]) の値(5.7)よりも高いので、Sour 属性は「不要」と判断されます。

検討結果について要約表が出力されます。

今回の事例では、15個の属性のうち 6個が「不可欠」、1個が「害がない」、1個が「不要」 であることがわかりました。残りの属性はどのカテゴリにも分類できませんでした。
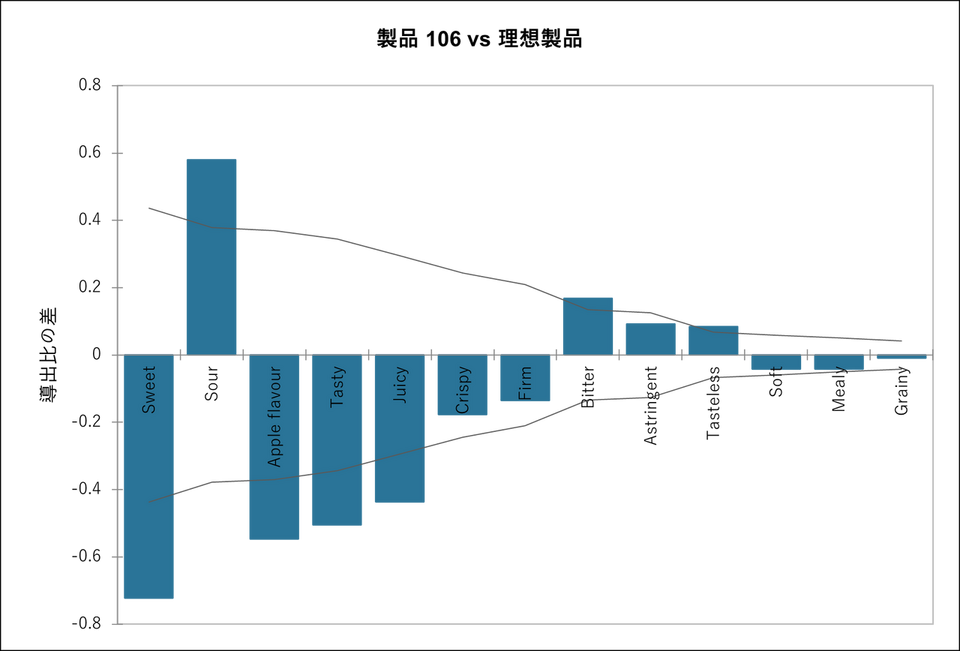
各製品と理想製品の比較
最後に、各製品と理想製品を比較したグラフが表示され、属性ごとに、製品が理想製品と似ているか、異なっているかが示されます。差が大きいほど課題が多く、グラフの左側の方に位置します。逆に、特定の属性について製品が理想製品に似ているほど、グラフの線が 0 に近くなります。差が負の値であれば、その属性は十分に存在せず、正であれば過剰であることを示しています。
まとめ
CATA 分析はコクランのQ検定、コレスポンデンス分析、主成分分析、ペナルティ分析を内包した多角的な分析です。XLSTAT を使うと簡単な操作でプロファイルを作成することができ、分析結果を得ることができます。開発元のヘルプページにてサンプルのデータが公開されていますので、数値や要因数を変更してどのような結果が得られるのかを確認してみてください。
記事執筆:一般社団法人学術・教育総合支援機構 芥川 麻衣子、川﨑 洋平
一般社団法人学術・教育総合支援機構公式HP:https://iaae.jp/
参考文献
- CATA Check-All-That-Apply analysis tutorial in Excel
https://help.xlstat.com/6491-cata-check-all-apply-analysis-tutorial-excel
※ 本記事はこちらのチュートリアルページをもとに作成しています。記事内で紹介したサンプルデータもこちらからダウンロードすることができます。
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したCATA データ分析はStandard と Advanced のライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。
