XLSTAT によるペナルティ分析:商品改良に重要な要素を特定する
記事執筆:一般社団法人学術・教育総合支援機構 倉山 太一、川﨑 洋平
一般社団法人学術・教育総合支援機構公式HP:https://iaae.jp/
ペナルティ分析とは?
ペナルティ分析は、官能データ分析の一種です。消費者や専門家を対象に実施された調査に基づいて、製品改良の方向性を探ります。この手法では2種類のデータが使用されます。
- 嗜好スコア:
製品の全般的な満足度指数(例:フライドポテトが好きかどうか、10点満点の嗜好スコア)、または製品の特性(例:自動車の快適性を1から10で評価)に対応します。 - JAR 水準(5段階評価):
JAR は ”Just About Right” 「ちょうど良い」という意味を表します。この評価は、対象製品の1つまたは複数の特性について、1から5までの段階で評価します。1は「非常に物足りない」、2は「物足りない」、3は「JAR(ちょうど良い)」、4は「過剰である」、5は「かなり過剰である」に相当します。例えば、フライドポテトであれば「塩味」を、車の快適性であれば「エンジン音の大きさ」を評価することができます。
ペナルティ分析は、ANOVA のような多重比較に基づいています。この解析のポイントは、JAR 水準上でのランキング(消費者が感じる属性の理想度)と、その属性に対する好みのスコア(好みの強さや満足度)との間に有意な関連があるかを見つけ出すことです。すなわち、対象となる商品には複数の特性がありますが(例えば「フライドポテト」なら、「塩味」、「甘味」、「温度」などです)、通常これらは消費者が「ちょうど良い」と感じること(JAR 水準で3点)が最も好ましいとされ、過剰(JAR が4または5)であっても不足(JAR が1または2)していても、商品の評価である嗜好スコア(好き・嫌い)を下げます。ペナルティ分析では、そのような考え方に基づいて、商品の複数の特性についてJAR 水準で評価し、これと嗜好スコアの相関関係から、「ちょうどよい」から外れた評価が、どの程度、当該商品の嗜好スコアの低下に結びつくのかを、最終的に「ペナルティ値」として表現します。この解析を通じて、商品における、ある特定の性質が、その製品の嗜好スコアに強く影響する可能性を探索し、必要に応じて改善するなど、商品開発に役立てることが可能です。
ペナルティ分析を実行するためのデータセット
ここでの目的は、新商品開発のため、いくつかの可能な方向性を特定することです。このページで紹介するデータセットは以下のようになっています。

今回は例えばフライドポテトについて10段階の嗜好スコア(Liking scores:好き・嫌い)と、5段階のJAR 変数(Saltiness:塩味、Sweetness:甘味、Acidity:酸味、Crunchiness:歯ごたえ)が一行ずつ並んでいます。このデータを用いて、塩見や甘みが過剰、または不十分であった場合に、それが消費者の嗜好に与える影響を解析します。ペナルティ分析を行う場合は、上記と同様の構成でデータセットを用意する必要があります。またシート右上の項目は、JAR の5段階評価を単純化し、3段階に集約させるための設定です。必要に応じて事前に入力しておき、この後のセットアップ段階で選択します。
サンプルデータのダウンロードはこちらから
Demo_Penalty_EN.xlsペナルティ分析の操作手順
-
XLSTAT を起動し、[Sensory] > [高速タスク] > [ペナルティ分析] を選択します
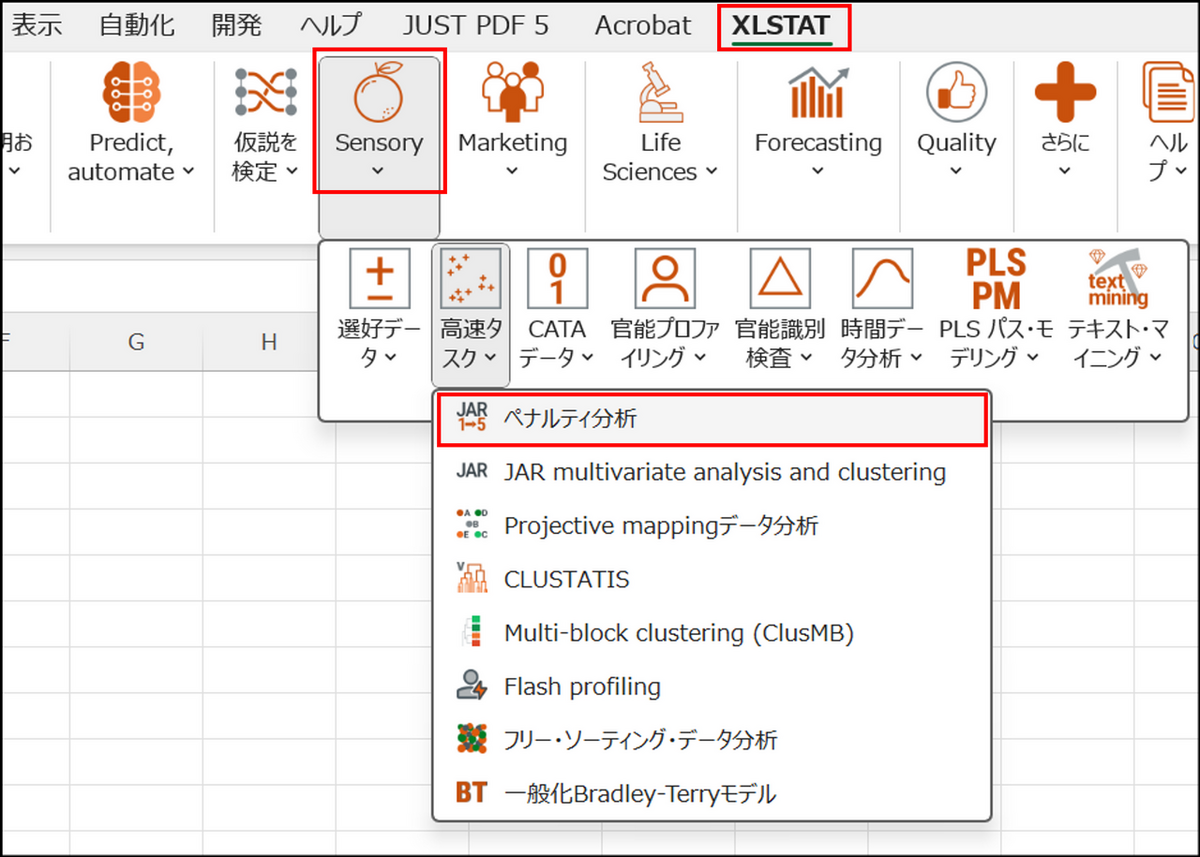
-
ダイアログボックスが表示されるので、下記項目を指定します
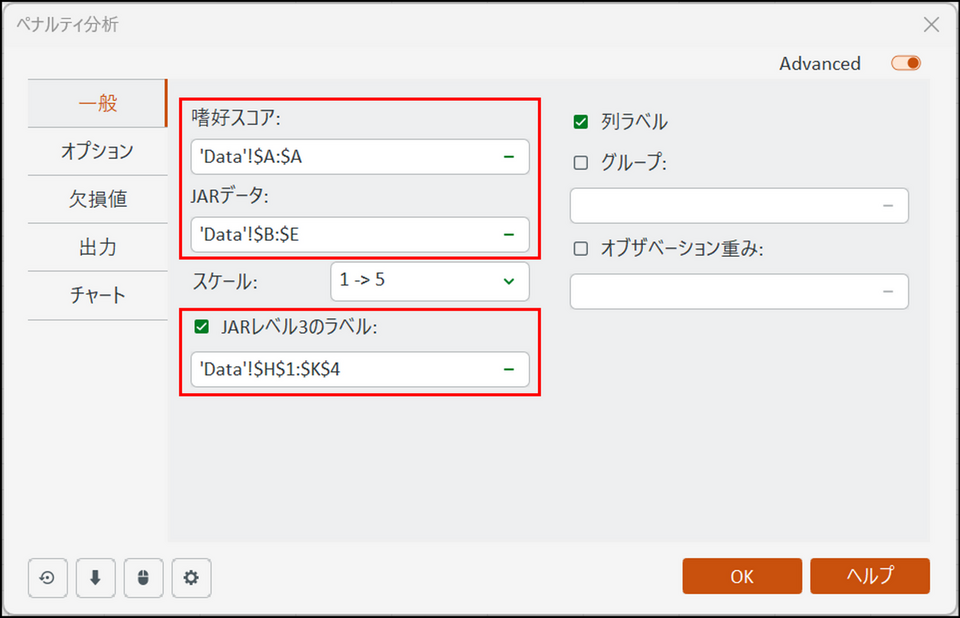
- [嗜好スコア]:
嗜好スコアのデータが記録されているセルを選択します。データの選択は入力欄にカーソルを置き、その後でエクセル上のデータを直接指定することで可能です。今回はシート上のLiking scores の列を列名も含めて選択します。 - [JARデータ]:
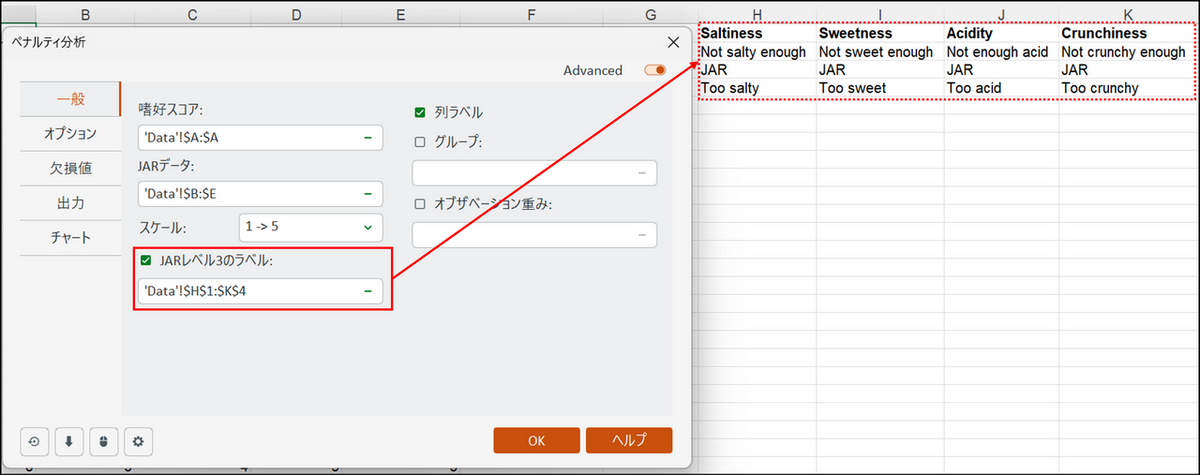
JAR 水準のデータを選択します。シート上のSaltiness、Sweetness、Acidity、Crunchiness の列を列名も含めて選択します。 - [JARレベル3のラベル】:
項目にチェックを入れ、3段階にまとめたJAR 水準のセルを選択します。この設定により5段階で評価されているJAR 水準は3段階(「物足りない」、「ちょうど良い」、「過剰である」)に単純化されます。
- [嗜好スコア]:
-
[オプション] タブで母集団のサイズのしきい値(%)を定義します。
JAR 水準の評価において、回答数が極端に少ない項目は統計的な信頼度に欠けるため、計算を実行しない設定にしておきます。定義値以下では信頼性が十分でない可能性があるため、比較テストを実行しません。規定値は20%となっており、これは例えばJAR 水準を3つに分けた場合、回答数が全サンプル数の20%に満たなかったレベルではペナルティ値の計算を実行しない設定です。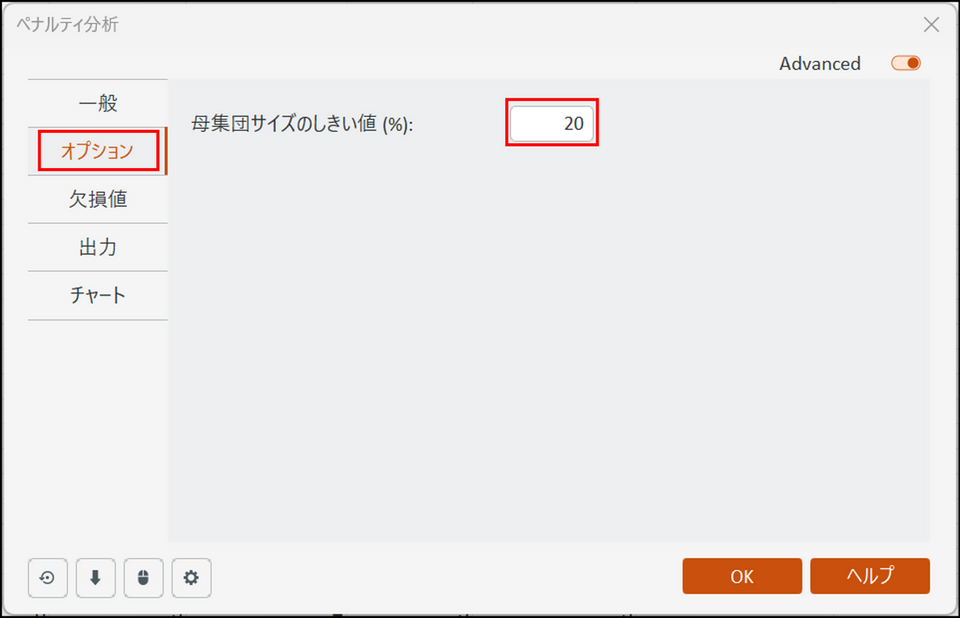
-
[出力タブ] にて出力項目の指定をします。今回は嗜好スコアが1から10の順序尺度であるため、相関係数の項目で[Spearman(スピアマンの相関)] が選択されています。
-
[OK] をクリックすると計算が始まり、結果が別シート(ペナルティ分析)に出力されます。
ペナルティ分析の結果の解釈
結果の最初には、嗜好スコアとさまざまなJAR 変数についての記述統計量が表示されます。

続いて以下の相関行列が表示されます。
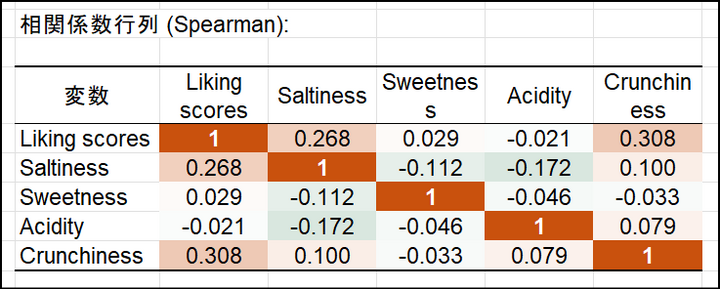
この表における、相関係数の解釈には注意が必要です。その理由は、嗜好スコア(Liking score)とJAR 変数(Saltiness、Sweetness、Acidity、Crunchiness)の関係において、JAR 水準が真の順序データではないためです。すなわち嗜好スコアは単調増加(1から10に評価が高い)であるにもかかわらず、JAR 水準では「3」が最も評価が高く、「4, 5」も「1, 2」も「3」より順位が低く、昇順・降順が途中で入れ替わる尺度です。したがって例えば嗜好スコアを縦軸に、JAR 水準を横軸にデータをプロットすると、その分布はJAR 水準が3(ちょうど良い)を中心とした山型で、左右対称な分布になります。そうなると相関関係(係数)は、JAR=3 を頂点として正負が折り返すことになりますので、甘味が「過剰」と感じる人と、「不十分」と感じる人で同じように嗜好スコアの点数が下がっていれば、分布は左右対称となります。すなわちJAR=3 を頂点として相関関係の正負が逆転し、打ち消しあうので、全体の相関は「0」に近くなるはずです。別の結果として、例えば塩味が足りない(JAR=1, 2)ほど、嗜好スコアが低下し、過剰な時(JAR=4, 5)はそれほど嗜好スコアに影響しなかった場合は、全体的にみると分布は右肩上がりとなり、相関係数が「1」に近づきます。今回のデータでは ”Crunchiness”、”Saltiness” でその傾向が見られます。
ただし、分布が見かけ上、右肩上がり(正の相関)であったとしても、「甘味が弱い」と判断している集団のサンプル数が少なければ(重みが小さい)、全体的な影響は小さくなりますので、そのことを考慮する必要があります。実際、今回の例で最終的に計算されるペナルティ値では、JAR 水準が3 以外のカテゴリー(例:甘すぎる、甘味が足りないと評価したカテゴリー)におけるペナルティ値を、それぞれのサンプル割合によって最終的に重み付けした上で算出します。したがって、ここでの相関係数は、各項目の傾向を捉えるための参考値として参照してください。
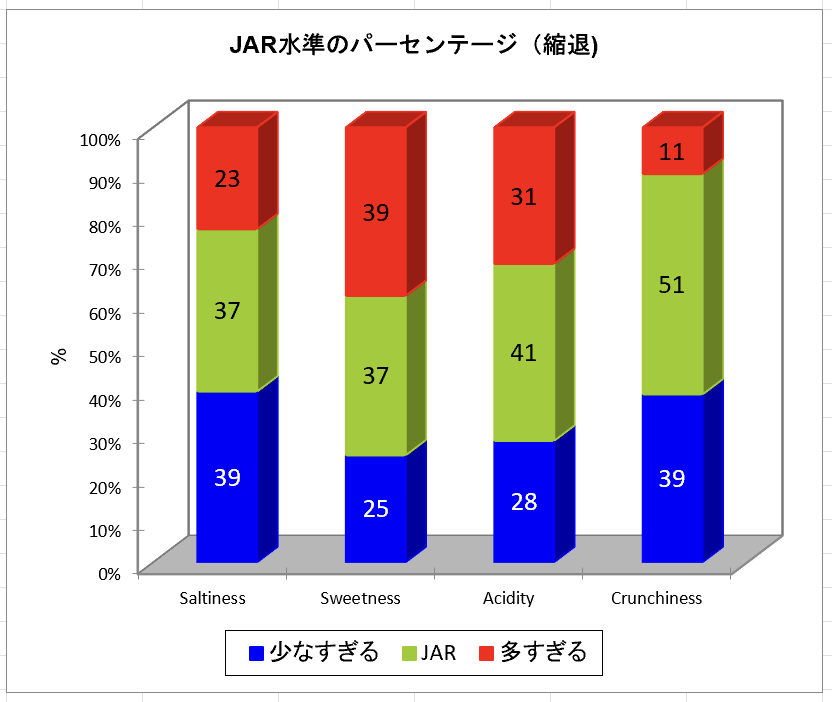
次の表は、JAR 水準の要約です。続く図では、この表に基づいてJAR 水準が各次元でどのように分布しているのかを素早く確認することができます。


そして、JAR のデータは3段階の尺度(too little / JAR(just about right)/ too much)に集約されます。これはもともとのJAR の5段階評価のうち、1~2が「too little」、3が「JAR」、4~5が「too much」になるという意味です。対応する度数表とグラフを以下に示します。

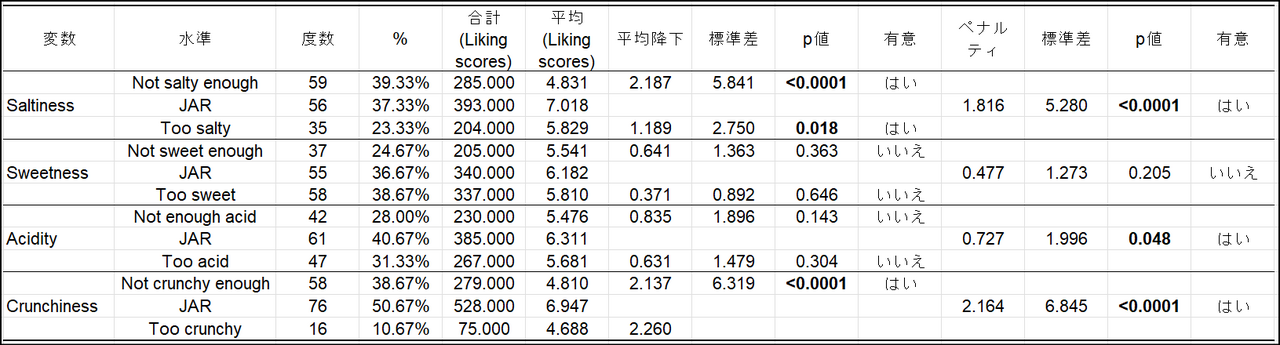
次の表はペナルティ分析に対応しています。
各 JAR 変数に対して、以下の情報が表示されます。
- 変数:JAR 水準の名前。
- 水準:JAR の3つの要約レベル(JAR 水準は本来5段階ですが、1点および2点を「not ~ enough(不十分)」、3点はそのまま「JAR(適切)」、4点および5点を「too ~(過剰)」の3段階に要約しています)。
- 度数:各レベルに対応するサンプル数。
- %:各レベルに対応するパーセンテージ。
- 合計(Liking scores):各レベルに対応する嗜好スコアの合計
- 平均(Liking scores):各レベルに対応する嗜好スコアの平均
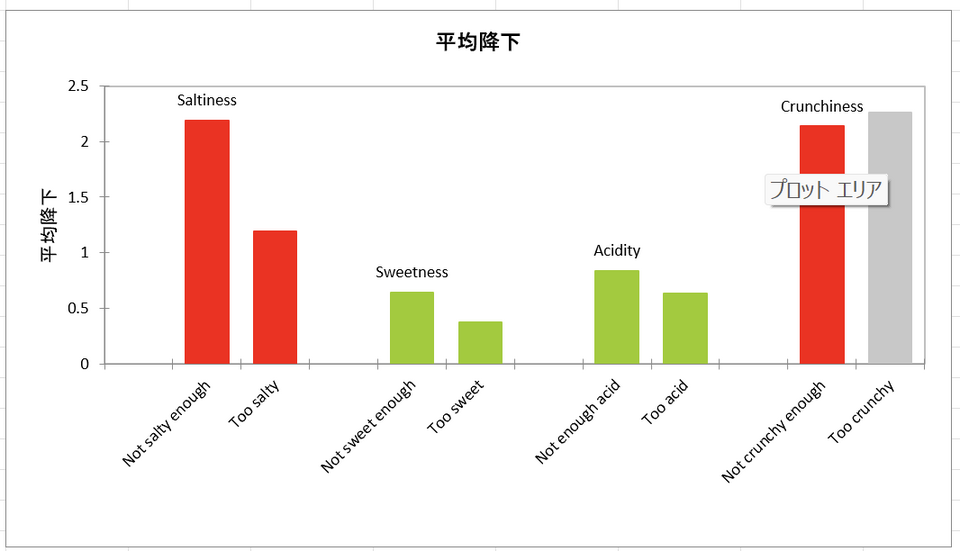
- 平均降下:JAR 水準の「過剰( too 〜 )」レベルと「不足( not ~ enough )」レベルにおける平均降下値。これは、JAR(ちょうど良い)と回答した消費者の嗜好度平均から「過剰」および「不足」と回答した消費者の嗜好スコアを引いた値です。例えば上の「ペナルティ表」でSaltiness(塩味)の一番上の行にある「不足:not salty enough」の平均降下「2.187」は「JAR」と回答した消費者の嗜好スコア「7.018」から「不足」と回答した消費者の嗜好スコアである「4.831」を引いた値になります。この情報は、例えば今回の商品が「フライドポテト」だったと仮定すれば、その塩味が消費者にとって「不足」と感じた場合は、嗜好スコアで表される商品の好感度が何ポイント下がるかを示すもので、重要な指標です。要するに「平均降下値」は、嗜好スコアについてのJAR (ちょうど良い)との差になりますので、この値が大きければ好感度が下がるという解釈になります。
- 標準差:比較検定に使われる中間統計量。
* 2つのグループ間の平均降下値の差を、それぞれのグループの標準偏差で除したもの - p 値:記載されている p 値は、JAR=3 の時の嗜好スコアの平均値と他の2つのレベル(過剰・不足)の嗜好スコアの平均値の比較です(3群での多重比較です)。
- 有意:p 値が有意か否かの解釈は選択された有意水準(ここでは5%)で判断され、自動的に「はい」または「いいえ」で提供されます。例えば「Saltiness」においては、JAR=3 と答えた消費者よりも、「過剰」および「不足」と答えた消費者における、当該商品の嗜好スコアは有意に小さい、という意味になります。
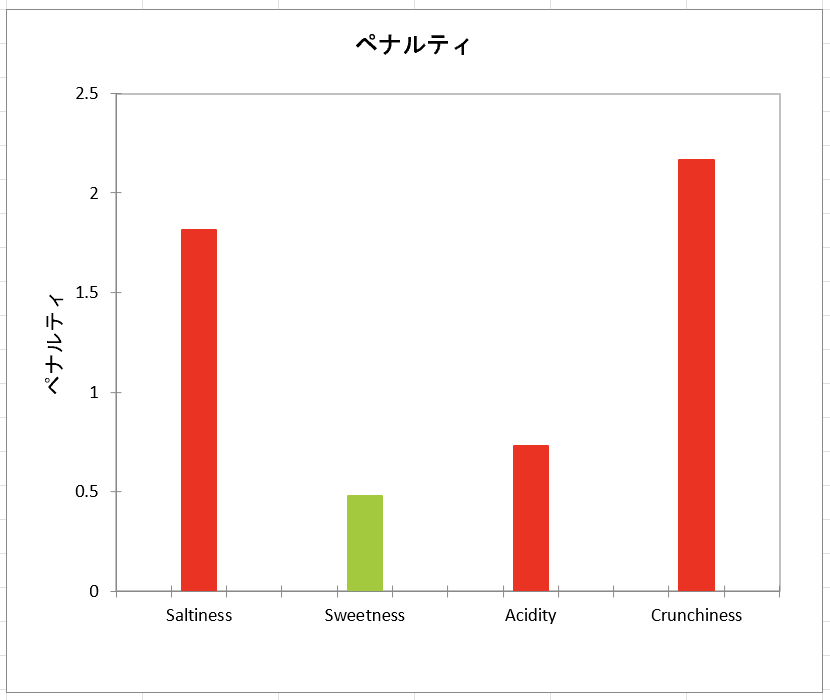
- ペナルティ:計算されたペナルティ値が表示されています。これはJAR=3 の時の嗜好値平均 から他の2つのレベルの(過剰・不足)嗜好平均値の平均値を減算したものに、それぞれのサンプルの割合を重み係数として乗算したものです。式として1つにまとめると以下のようになります1。
加重ペナルティ
=( 不足の平均降下 × 不足の割合[%] + 過剰の平均降下 × 過剰の割合[%] )
÷ ( 不足の割合[%] + 過剰の割合[%] )
この統計量が、この手法の名前である「ペナルティ分析」の由来となっています。この数値は、商品が消費者の期待通りでなかったために、何ポイント嗜好値が下がったのかを示しています。この事例ではSaltiness(塩味)のペナルティ値は「1.816」であるのに対し、Sweetness (甘味)のペナルティ値は「0.477」なので、「Sweetness よりも Saltiness の改善が商品開発においては重要」という解釈が可能です。 - 標準差:ペナルティ値の標準化差分、比較検定に使用される中間統計量です。
- p値:JAR 水準の平均と他の水準の平均との比較検定に対応します。これは、ペナルティが「0」か、有意に異なるかについての検定結果に相当します。
- 有意:p 値が有意か否かの解釈は選択された有意水準(ここでは5%)に基づいて判断され、自動的に「はい」または「いいえ」で提供されます。例えば「Saltiness」は全体的なペナルティ値が有意、と結論されます。したがって、当該商品において、「Saltiness」はその好感度に影響するという解釈が可能です。
表において、塩味のカテゴリーでは、塩味は全体として嗜好スコアに影響し(p<0.05)、特に消費者が当該商品を「塩味不足(not salty enough)」と感じる時に、「塩味過剰」に比べて強いペナルティが課される(好感度が低下する)ことがわかります(降下平均それぞれ2.187と1.189)。もし商品が「フライドポテト」であった場合は、塩加減を強めにすることは嗜好スコアの上昇につながる、という仮説が成り立ちます。
甘味(Saltiness)のカテゴリーでは、どの検定も有意ではありませんでした。すなわち、商品開発、改善の過程において甘味の調整は必要ないかもしれません。
酸味(Acidity)のカテゴリーでは、全体的なペナルティ値は有意ですが、2つの嗜好値(酸味が足りない、または酸味が強すぎる)の平均値に有意差はありません。このことは、酸味は顧客にとって重要であることを意味しますが、一方で、この調査の検出力が十分でなく、特定の嗜好平均値の低下を検出できなかった可能性を示します。
歯ごたえ(Crunchiness)については、 "too crunchy" レベルのサンプルサイズ割合が先に設定した閾値である20%より低いため、嗜好値低下の平均値は計算されていません。なお、製品の歯ごたえが十分でない場合( "not crunchy enough" )、製品は大きなペナルティを受けます。
次の2つのグラフは、上に記載された結果を要約したものです。バーが赤いときは差が有意であることを意味し、緑色のときは差が有意でないことを意味します。バーが灰色のときは回答者数が不十分であったため、平均降下が計算されなかったことを意味しています。
まとめ
ペナルティ分析は、消費者のフィードバックに基づいて、製品の特性改善を目指す官能データ分析です。製品の嗜好スコアと、商品特性の「ちょうど良い」度合いを示すJAR 水準(5段階評価)を用いて分析を行い、ペナルティ値を算出します。この分析を用いることにより、対象製品のどの特性が改善の余地を持っているか、またどの特性を優先的に改善すべきか等について、数値的に検討する事が可能となります。
記事執筆:一般社団法人学術・教育総合支援機構 倉山 太一、川﨑 洋平
一般社団法人学術・教育総合支援機構公式HP:https://iaae.jp/
参考文献
- How to Calculate Penalty Analysis in Q.
https://help.qresearchsoftware.com/hc/en-us/articles/4407535666703-How-to-Calculate-Penalty-Analysis-in-Q (参照 2024/2/23 )
- Penalty analysis in Excel tutorial.
https://help.xlstat.com/6651-penalty-analysis-excel-tutorial
※ 本記事はこちらのチュートリアルページをもとに作成しています。記事内で紹介したサンプルデータもこちらからダウンロードすることができます。
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したペナルティ分析はStandard と Advanced のライセンスでご利用いただけます。
無料トライアルに申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。

