XLSTAT によるk-means クラスタリング:購買データをグループ分けして顧客分析をしよう
- クラスター分析とは?
- k-means クラスタリングの実行過程(理論説明)
- k-means クラスタリングの注意点
- k-means クラスタリングを実行するためのデータセット
- k-means クラスタリングの操作手順
- k-means クラスタリングの結果の解釈
- クラスタリングの結果を可視化する(応用)
- クラスターの解釈
- まとめ
- 参考文献
- XLSTAT の無料トライアル
クラスター分析とは?
クラスター分析は、データ分析において、似たような特徴を持つデータのグループ(クラスター)を自動的に見つけ出すための手法です。例えば、たくさんの顧客データがあるとき、この分析を行うことで、顧客をいくつかのグループに分け、それぞれのグループの特徴を明らかにすることができます。これにより、顧客のニーズに合わせたマーケティング戦略を立てたり、顧客満足度を高めるための施策を検討したりすることができます。この手法は、顧客データ、購買履歴、アンケート結果など、様々な種類のデータに適用可能です。
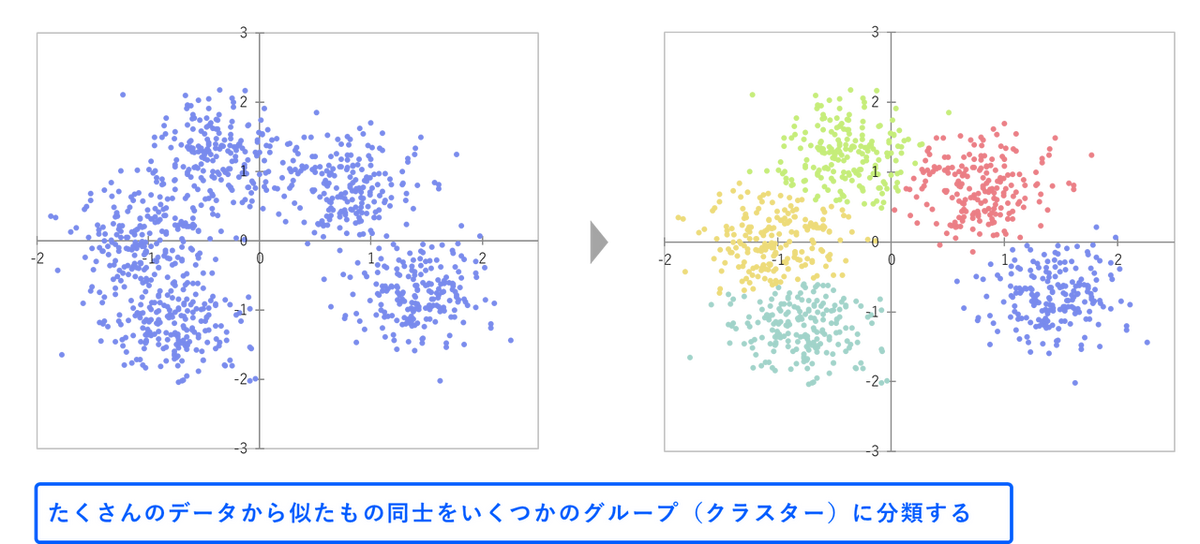
クラスター分析には、大きく分けて階層型クラスター分析と非階層型クラスター分析の2種類があります。両者の特徴と使い分けの詳細は下記ページをご参照ください。
XLSTAT による階層型クラスター分析:類似度に基づいて消費者データをグループ分けする
このページでご紹介するk-means クラスタリングは、非階層型クラスター分析に分類される手法です。
k-means クラスタリングの実行過程(理論説明)
k-means クラスタリングでは、指定したクラスター数 k に基づいて、データを k 個のグループ(クラスター)に分割していきます。k-means クラスタリングの実行過程は以下の通りです。
-
クラスター数を設定する
最終的にいくつのクラスターに分けるのかを分析者が決定します。実行時にクラスターの数をあらかじめ決めるかどうかは階層型クラスター分析との大きな違いです。
-
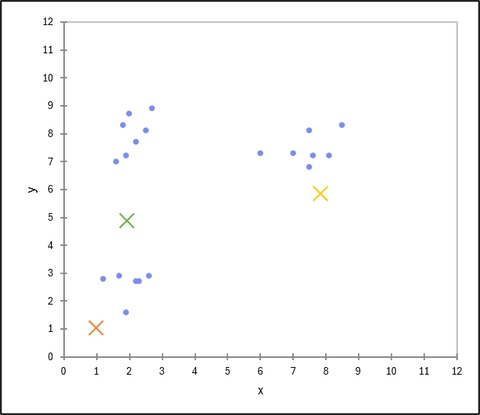
初期クラスターの重心をランダムに決める
ランダムに k 個の初期クラスターの重心を決定します。仮に3つのクラスターに分けるのであれば、ランダムに重心の初期値を3つ設定します(図中の✕記号)。
-
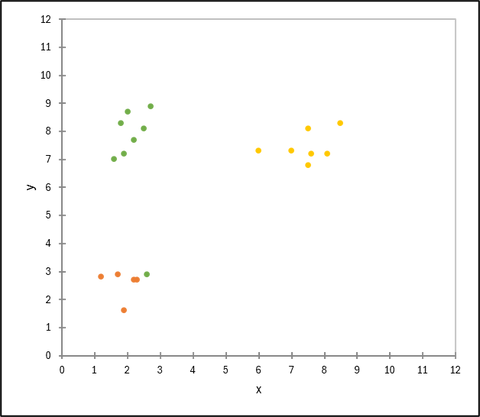
各データ点を最も近い重心のクラスターに割り当てる
各データ点を、最も近いクラスター重心に割り当てます。この際の距離の計算には通常ユークリッド距離が用いられます。ユークリッド距離の詳細は 階層型クラスター分析のページ をご参照ください。
-
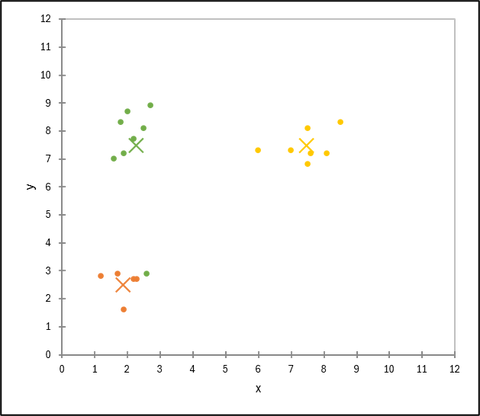
クラスターの重心を更新する
各クラスターに割り当てられたデータ点の平均値を計算し、その平均値を新しいクラスターの重心とします。
-
クラスターの割り当てと重心の更新を変化がなくなるまで繰り返す
上記の割り当てと更新を重心が変化しなくなるまで続けます。
この繰り返し処理によって、最終的にデータは、それぞれのクラスター内でデータ点同士の距離が近く、異なるクラスター間の距離が遠くなるようにグループ分けされます。
k-means クラスタリングの注意点
k-means クラスタリングは計算負荷が軽く、大規模データに適していますが、いくつか注意するべき点があります。
- 重心の初期値により結果が変わる可能性がある
k-means クラスタリングでは最初の重心の指定はランダムに行われるため、重心の初期値により同じデータでも実行する度に結果が変わる可能性があります。そのため、複数回初期値をランダムに変えて実行し、最も良い結果を採用するなどの対策が必要です。また、重心の初期値の選択を改良したk-means++ を利用するという方法も有効です。XLSTAT では実行時のオプションでk-means++ を選択することが可能です。
- クラスター数を事前に決定する必要がある
k-means クラスタリングではクラスターの数を分析者が事前に決定する必要がありますが、クラスターの数が不適切である場合、クラスタリングの性能が悪くなる可能性があります。そのため、後述のエルボー法やシルエットスコアといった指標を参考にして最適なクラスター数を推定する必要があります。
k-means クラスタリングを実行するためのデータセット
このページではあるスーパーマーケットの顧客購買データ(1,000名分)を利用します。このデータには、顧客ID、年間購入金額(千円)、来店頻度(回/月)などの情報が含まれています。
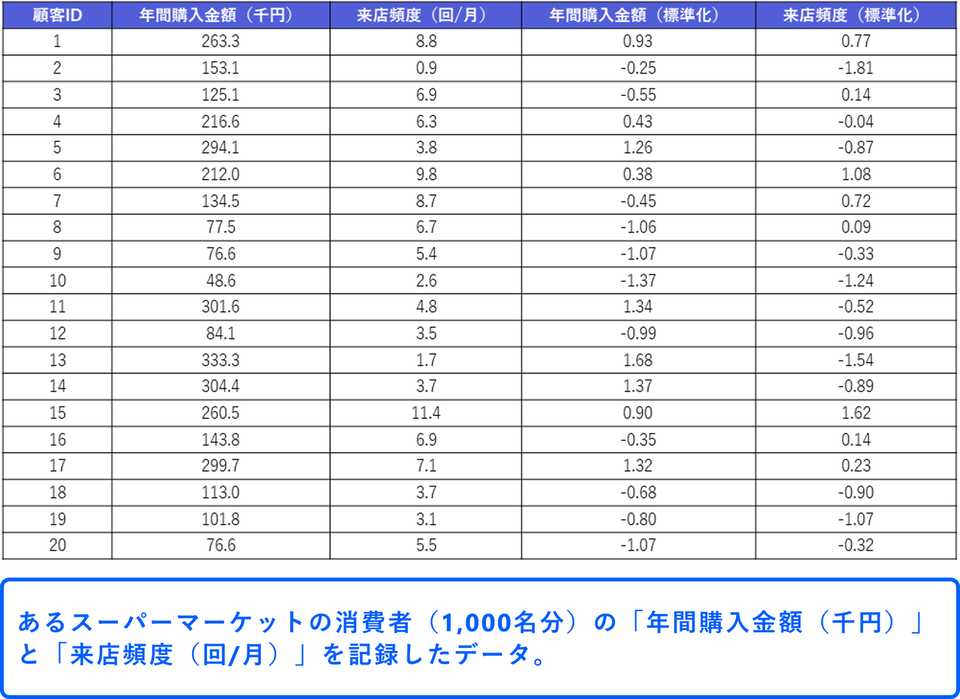
また、年間購入金額と来店頻度のデータは単位が異なるため、あらかじめ各データを標準化しておきます。XLSTAT でデータを標準化する方法は下記ページをご参照ください。
今回は標準化した年間購入金額と来店頻度の変数を用いてk-means クラスタリングを行い、どのような特徴をもつ消費者がいるのかを確認してみます。
サンプルデータのダウンロードはこちらから
dataset-for-k-means-clustering.xlsmk-means クラスタリングの操作手順
-
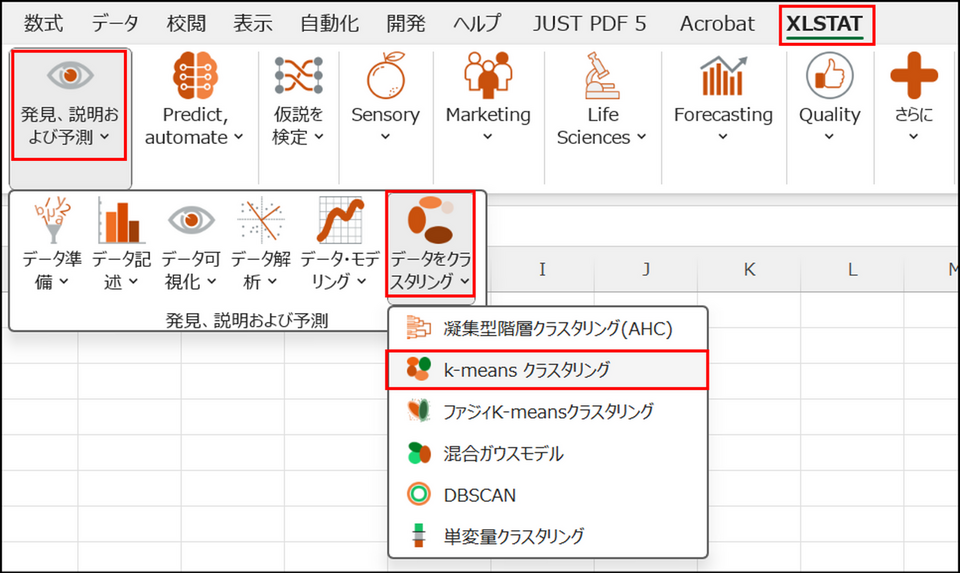
XLSTAT を起動し、[発見、説明および予測] > [データをクラスタリング] > [k-means クラスタリング] を選択します。
-
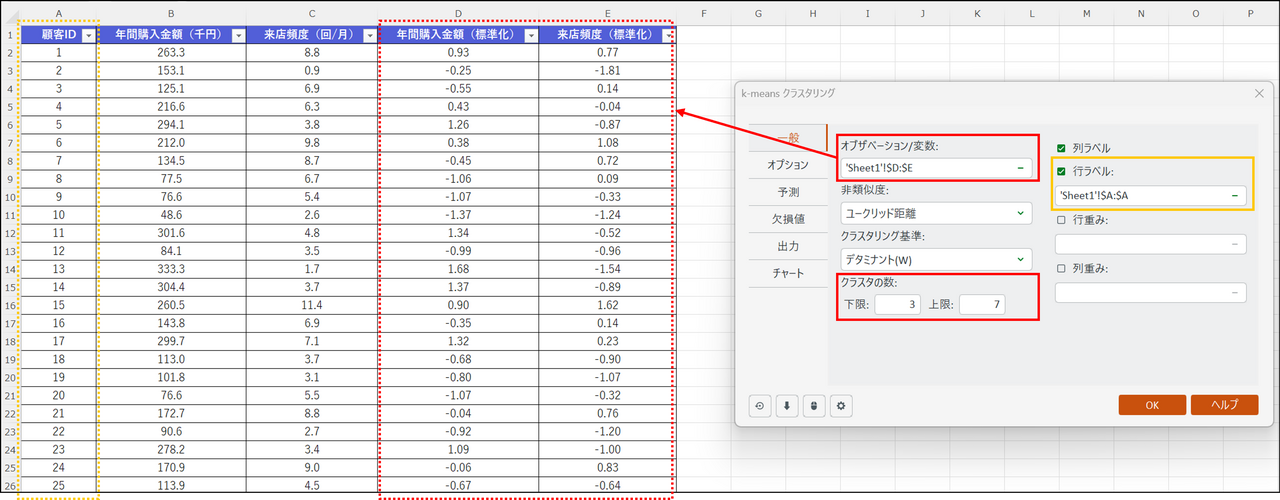
ダイアログボックスが表示されるので、[一般] タブで以下のようにデータを選択します。
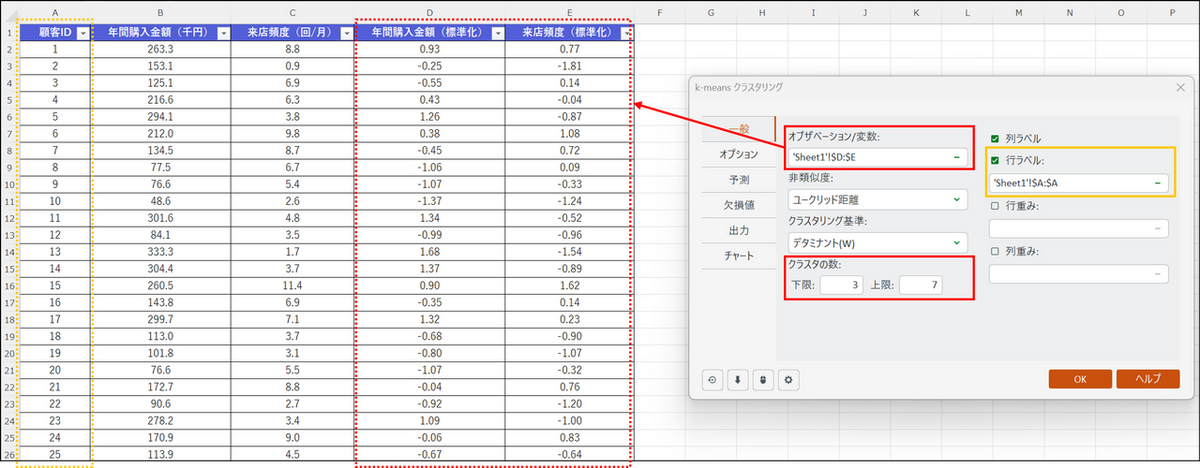
- オブザベーション/変数:
標準化した年間購入金額と来店頻度の変数列を列名も含めて選択 - 非類似度:
[ユークリッド距離] を選択 - クラスタリング基準:
[デタミナント (W)] を選択 - クラスタ数:
作成するクラスタの数を指定します。今回は下限「3」、上限「7」とします。
- オブザベーション/変数:
-
[オプション] タブに切り替え、以下の項目を指定します。
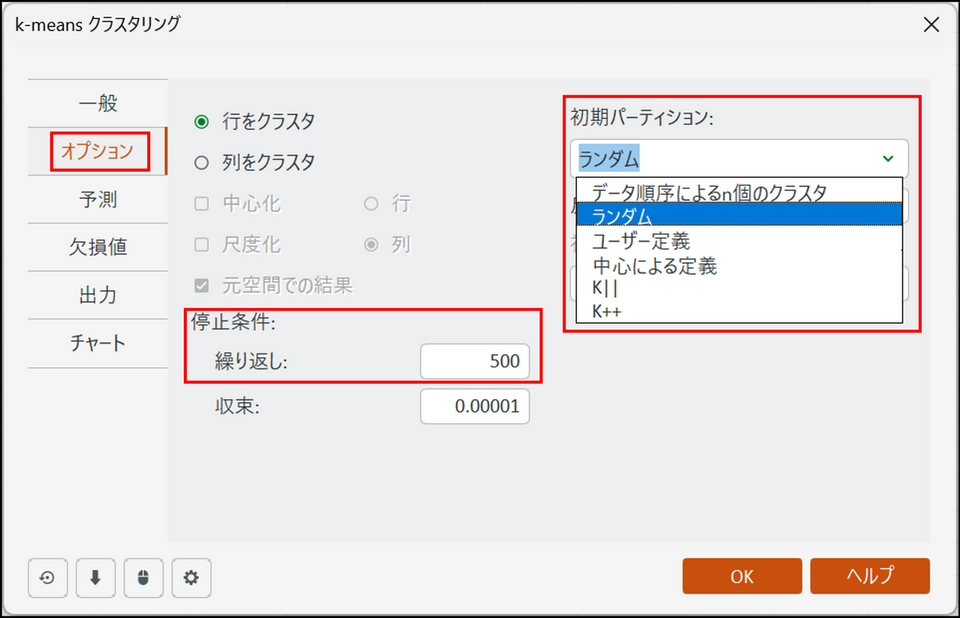
- 初期パーティション:[ランダム] を選択します。
- 停止条件:[500] と入力します。
【補足】初期パーティションについて
k-means クラスタリングを実行する際は、初期クラスターの中心がランダムに設定される点に注意が必要です。不適切な初期値が選ばれると、クラスタリングがうまくいかなかったり、収束に時間がかかってしまうことがあります。この問題の対処法の1つは、結果を慎重に解釈し、必要に応じて複数回クラスタリングを実行することです。もしくはk-means++ を選択することで、初期値を互いに離れた位置に配置し、通常のk-means 法よりも効果的で、一貫性のある結果が得られる可能性があります。k-means++ で実行する場合は、初期パーティションから[K++] を選択します。
-
[出力] タブに切り替え、以下の項目にチェックを入れます。
-
[チャート] タブに切り替え、以下の項目にチェックを入れます。
-
[OK] をクリックすると計算が始まり、結果が別シート(k-means)に出力されます。
k-means クラスタリングの結果の解釈
結果には複数の表やグラフが出力されますが、以下の点に着目して結果を解釈します。
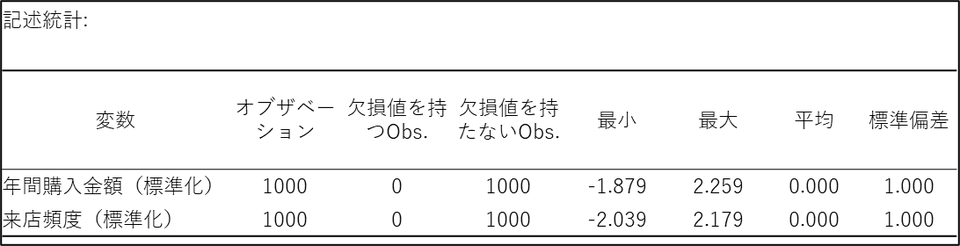
記述統計
記述統計では各変数の最小値、最大値、平均、標準偏差のデータを確認することができます。今回はあらかじめ各変数のデータを標準化しているため、平均は0、標準偏差は1 となっています。
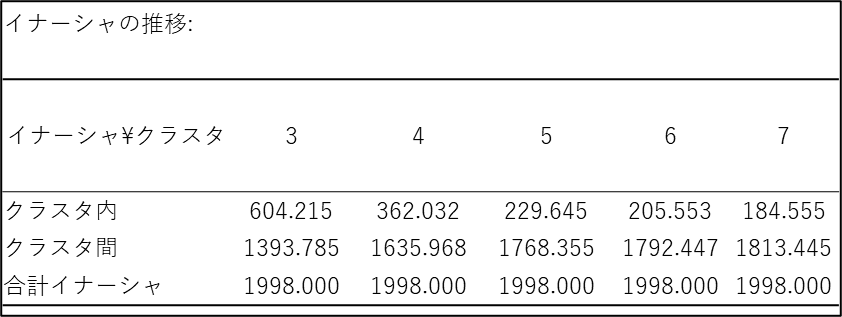
イナーシャの推移
【注意】
k-means のランダム性のため画像と同じ結果を得られるとは限りません。
詳細はk-means クラスタリングの注意点 をご参照ください。
イナーシャとはクラスター内誤差平方和(SSE)とも呼ばれ、各クラスターの重心から、そのクラスターに属する各データ点までの距離の二乗和を計算したものです。言い換えると、各クラスター内のデータのばらつき具合を示す指標となります。この値が小さいほど、クラスター内のデータが中心点に集中しており、クラスターの凝集度が高いことを意味します。上記表ではクラスター数を増やしていったときに、SSE がどのように変化していくのかを確認することができ、最適なクラスター数を判断する上で役立ちます。ただし、通常クラスター数を増やしていくと、クラスター内の分散は減少するため、単純にSSE の値が一番小さいクラスター数が最適とはならないことに注意が必要です。
k-means クラスタリングにおいて最適なクラスター数は、エルボー法と呼ばれる図解により判断することができます。次のグラフでは横軸にクラスター数、縦軸にSSE をプロットしています。
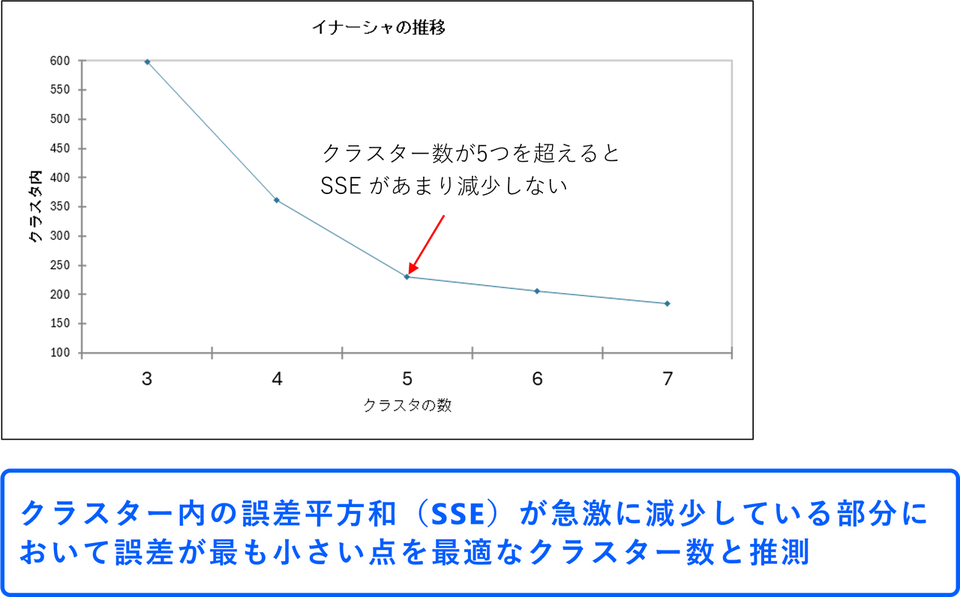
クラスター数を増やしていくと、SSE が減少していきますが、ある時点で減少率が急激に緩やかになります。この減少率が変化する点をグラフにプロットすると、肘(エルボー)のように見えることからエルボー法と呼ばれています。このエルボーに相当するクラスター数が、データにとって最適なクラスター数であると考えられます。今回のデータではクラスターが5つを超えると、SSE があまり減少しないため、クラスター数を5つとするのが良さそうです。
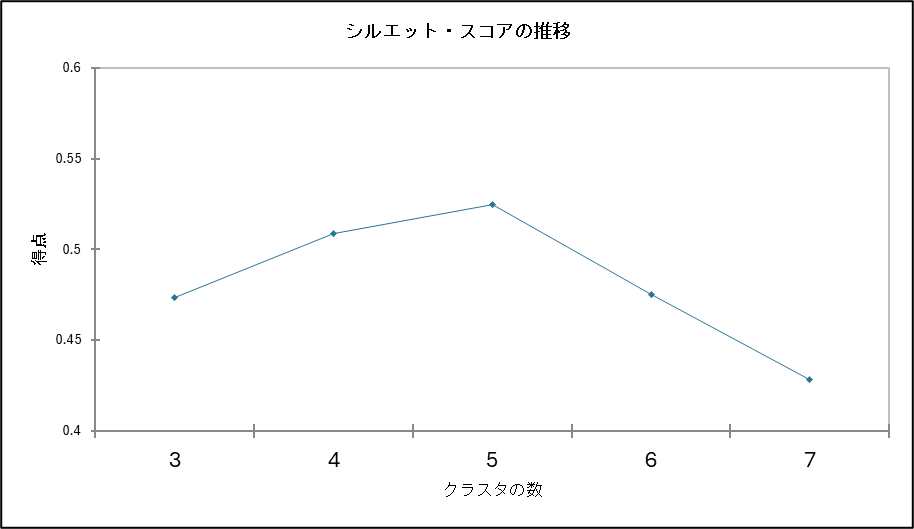
シルエット・スコアの推移
シルエットスコアとは、クラスタリングの結果を評価するための指標です。各データ点がどれくらい適切にクラスターに割り当てられているかを数値で表し、クラスタリングの品質を客観的に判断するのに役立ちます。シルエットスコアは -1 から 1 の範囲の値を取ります。1 に近いほど、クラスタリングが適切に行われていることを示します。0 に近い場合は、データ点がクラスタの境界付近に位置しており、どちらのクラスタに属するか曖昧であることを示します。-1 に近い場合は、クラスタリングが不適切であり、データ点が誤ったクラスタに割り当てられている可能性を示します。
「シルエット・スコアの推移」ではクラスター数を増やしていったときに、このスコアがどのように変化するのかを確認することができます。

今回のデータではクラスター数が5のときのシルエットスコアが最大となるため、やはりクラスター数は5つとするのが最適なようです。
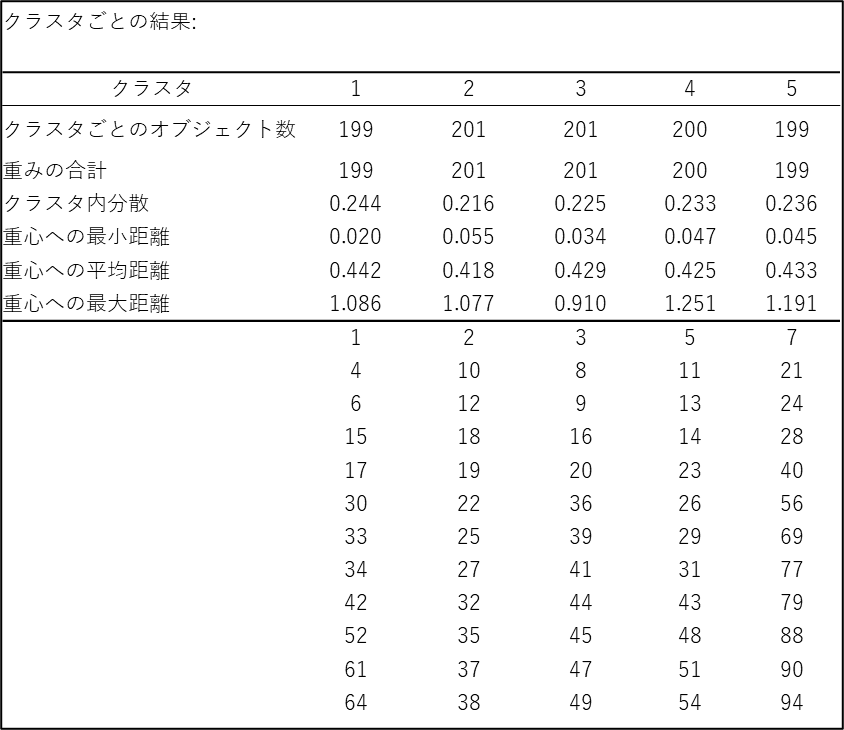
クラスタごとの結果
クラスタごとの結果では、クラスターごとのデータ数や分散などの情報を確認することができます。今回は実行時にクラスターの数を3~7 と指定したため、計5つの結果が出力されています。以下の画面はクラスター数を5つにした場合の結果を示しています。
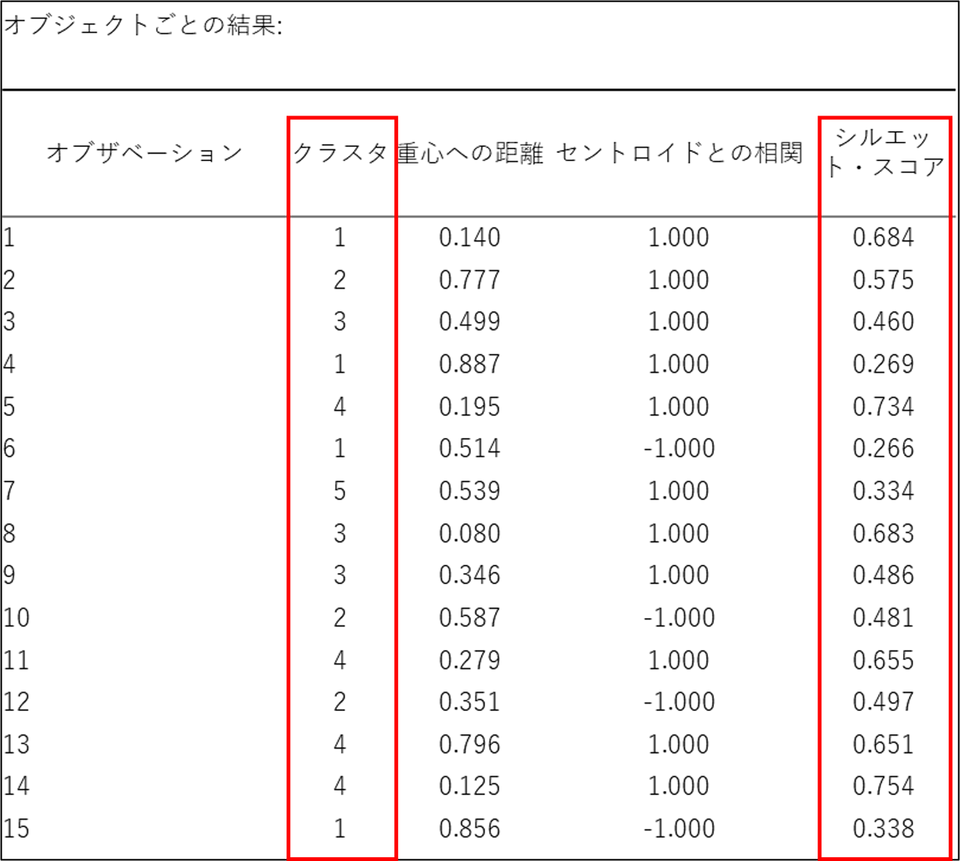
オブジェクトごとの結果
各データごとにクラスターの情報とシルエットスコアが表示されます。
シルエット・スコア
シルエット・スコアではクラスターごとに各データ点のシルエットスコアをソートして棒グラフで表示しています。クラスター全体のシルエットスコアの分布を確認することで、クラスタリングの品質を評価できます。
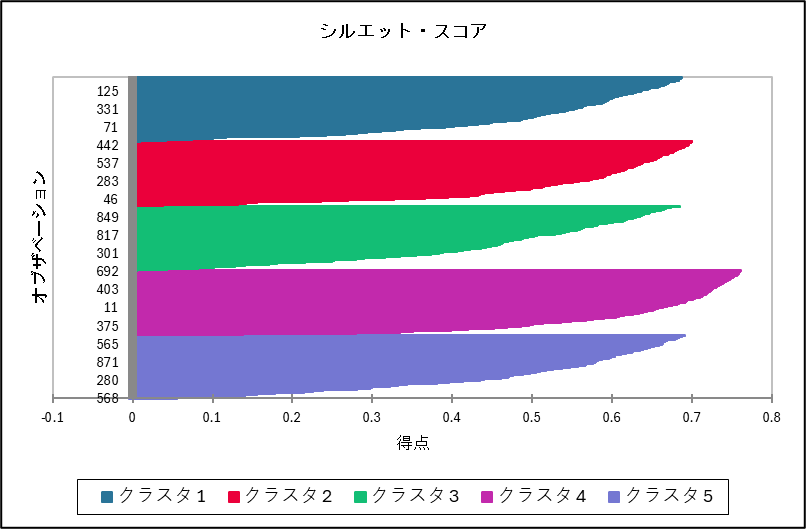
棒グラフの長さが均一で、クラスター内のデータ点のシルエット係数が高いクラスターは、密でまとまりのあるクラスターであることを示しています。
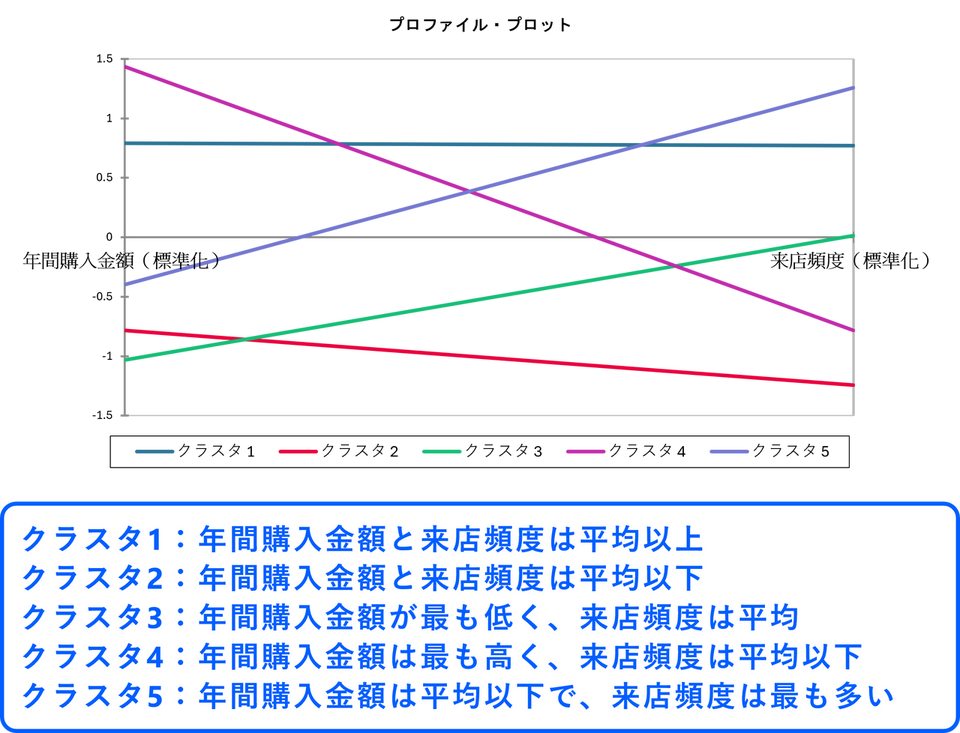
プロファイル・プロット
プロファイルプロットでは、クラスターごとに各変数の平均値をグラフで表示しています。このグラフから各クラスターの特徴を大まかに把握することができます。
クラスタリングの結果を可視化する(応用)
クラスタリングの結果で得られた情報をもとにグラフを作成することで各クラスターの特徴をより深く理解することができます。
散布図
散布図を用いることで、クラスターがどのように分布しているか、どのような形状をしているかを視覚的に確認できます。XLSTAT ではクラスターごとに色分けして散布図を作成することができます。
-
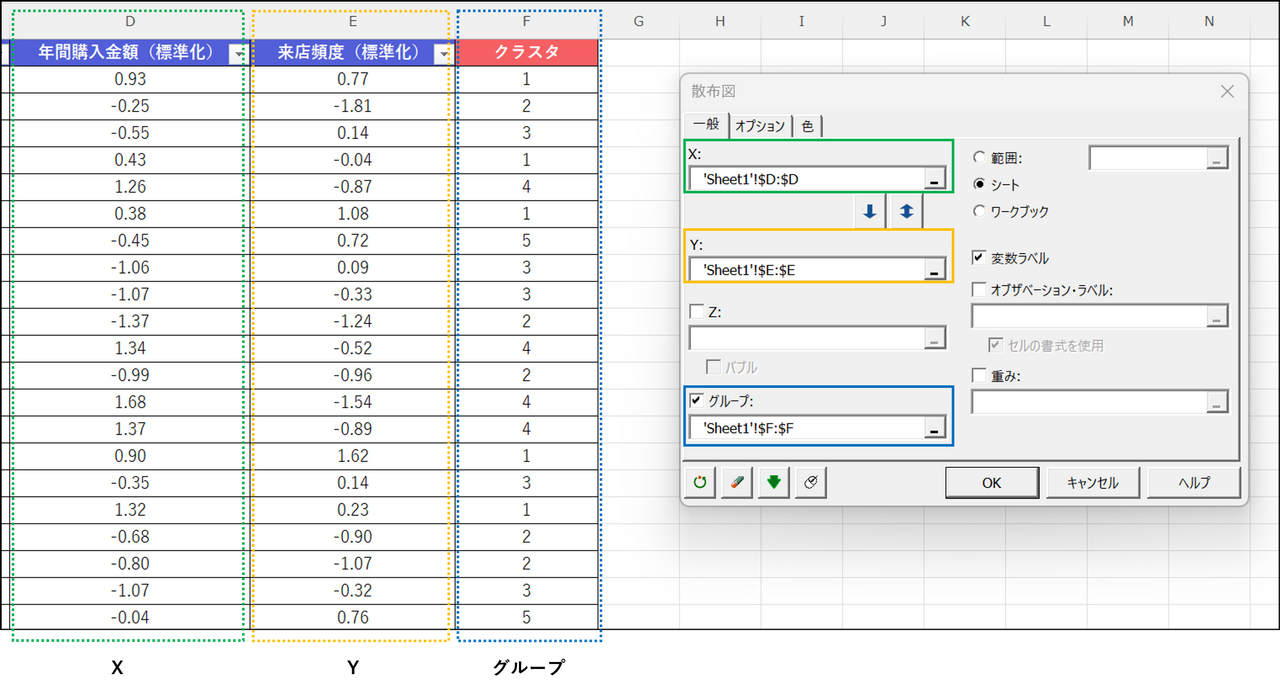
k-means クラスタリング結果の「オブジェクトごとの結果」から各データのクラスター列をコピーします。
※データ数が多い場合、一番上のセルを選択した状態でCtrl + Shift + 下矢印で一番下のセルまで選択することができます(Mac の場合はCommand + Shift + 下矢印)。
-
コピーしたクラスター列の情報を元のデータに貼り付けします。
※わかりやすいように画像ではクラスタ列名の色を変更しています。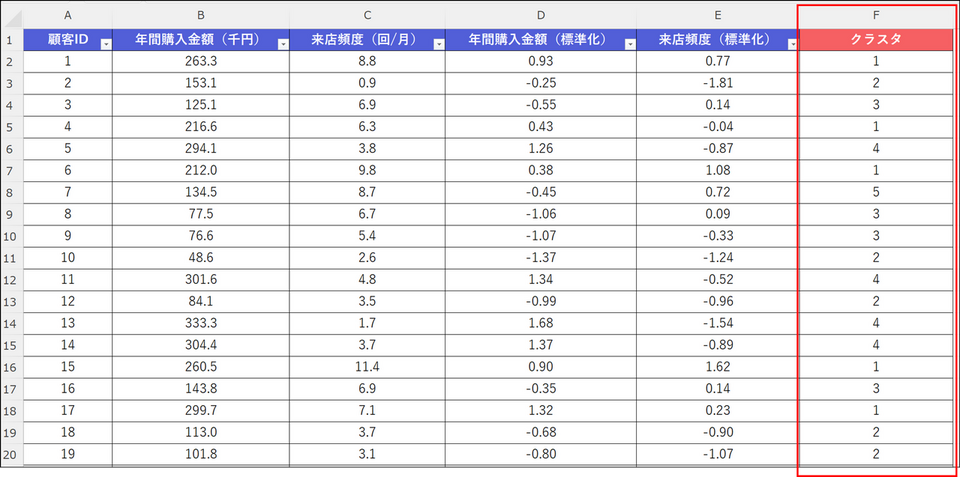
-
XLSTAT を起動し、[発見、説明および予測] > [データを可視化] > [散布図] を選択します。
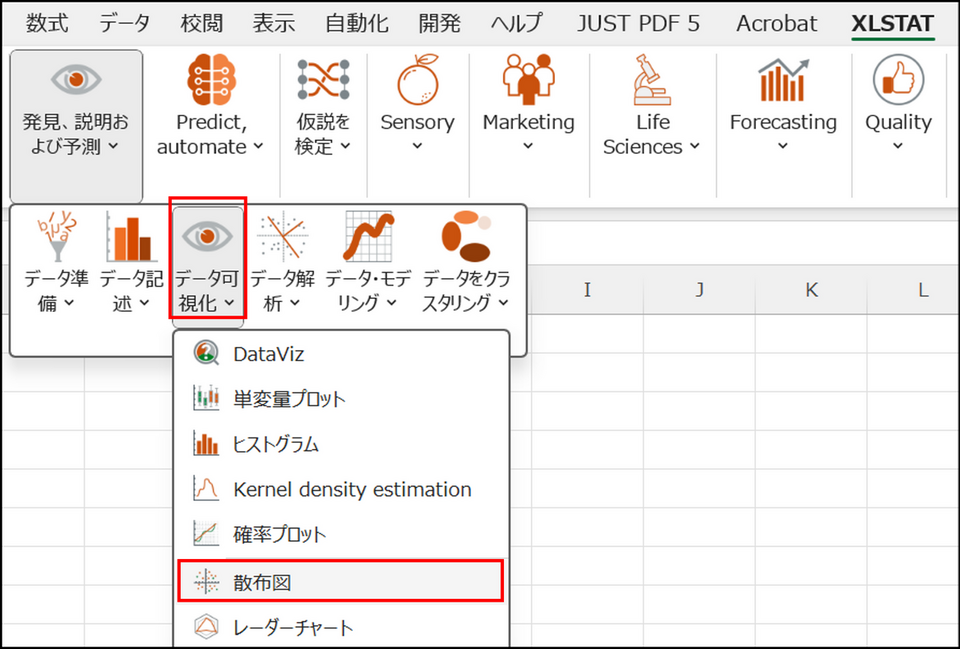
-
ダイアログ画面にて以下のように選択します。
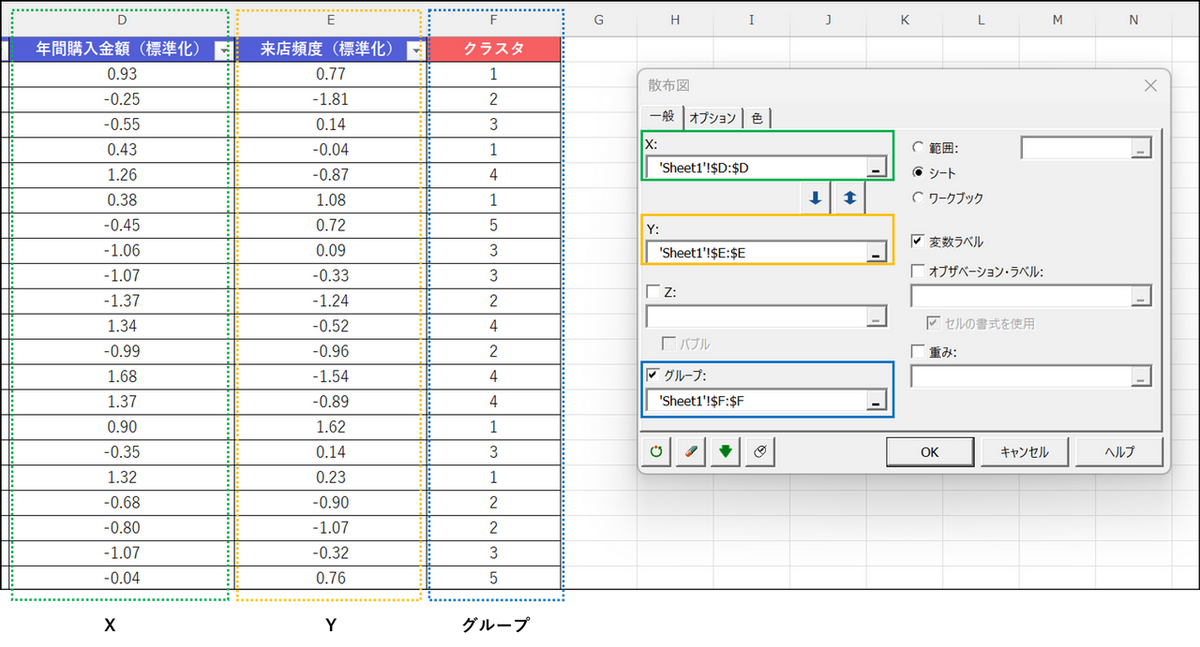
- X:[年間購入金額(標準化)] の列を選択
- Y:[来店頻度(標準化)] の列を選択
- グループ:[クラスタ] の列を選択
-
[色] タブに切り替え、各クラスターのプロットの色を指定します。
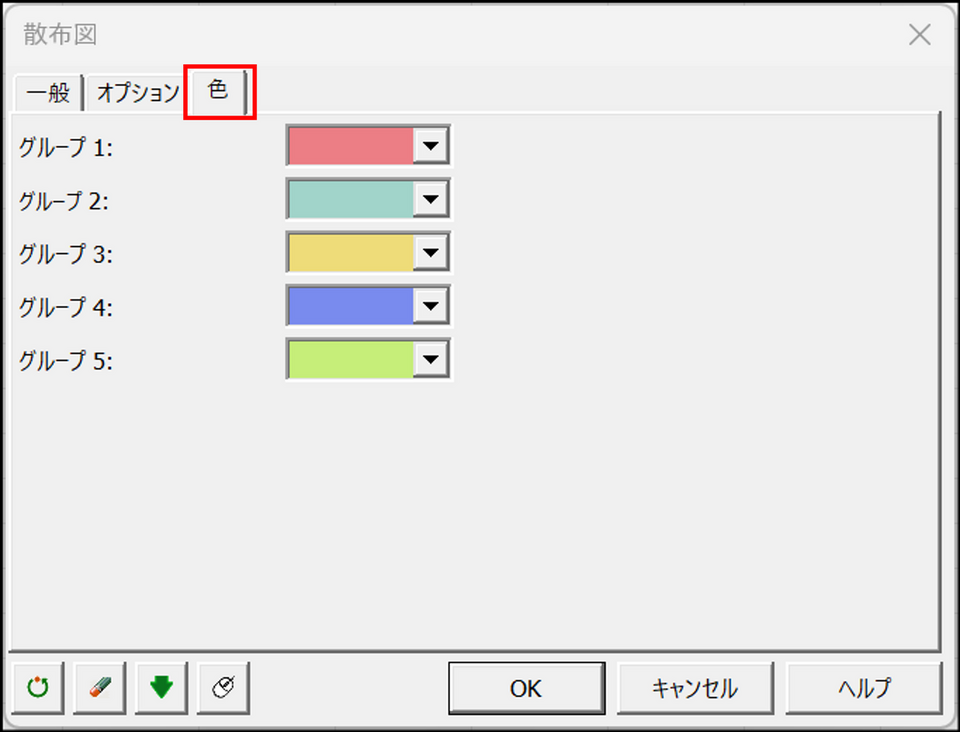
-
[OK] をクリックすると、別シート(SCA)に散布図が出力されます。
※軸を解釈しやすくするため、画像には説明を加えています。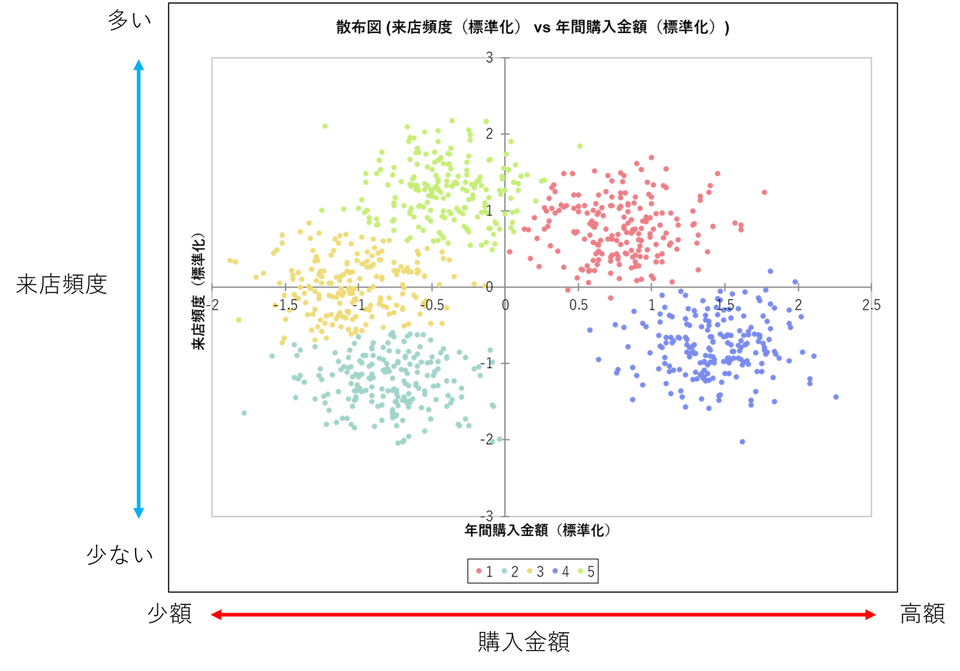
なお、XLSTAT で出力されたグラフはエクセル上で編集することが可能です。
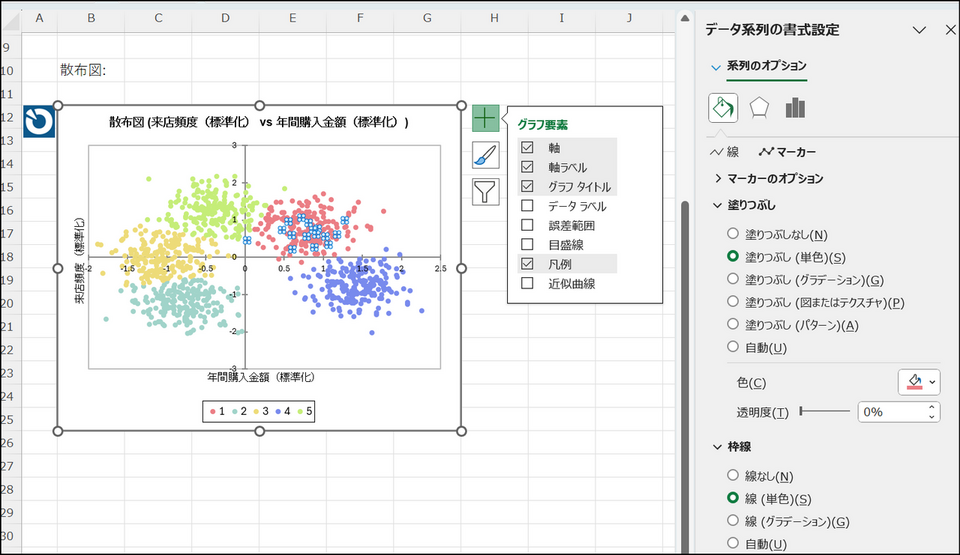
【補足】3変数以上のデータで散布図を作成したい場合
今回のデータでは「年間購入金額」と「来店頻度」の2変数でクラスタリングを実行しましたが、3変数以上のデータでもクラスタリングを実行することは可能です。ただし、3変数以上のデータでクラスタリングした結果を散布図で可視化することはできないため、あらかじめ元のデータを次元削減しておく必要があります。次元削減とは、高次元のデータ(多くの変数を持つデータ)を、できるだけ情報量を保持したまま、より低い次元のデータに変換する手法のことです。次元削減には、さまざまな手法がありますが、例えば主成分分析(PCA)を実行すると、データの中で最も重要な特徴を見つけ出し、より少ない変数にまとめることが可能です。主成分分析については下記ページも合わせてご参照ください。
記述統計
記述統計機能で各クラスターの基本統計量を確認することができます。
-
XLSTAT を起動し、[発見、説明および予測] > [データ記述] > [記述統計] を選択します。
-
ダイアログ画面が表示されるので、以下のようにデータを選択します。
- 量的データ:
チェックを入れ、標準化前の「年間購入金額」と「来店頻度」の列を選択 - 副標本:
クラスターの列を選択
- 量的データ:
-
[OK] をクリックすると、結果が別シート(Desc)に出力されます。
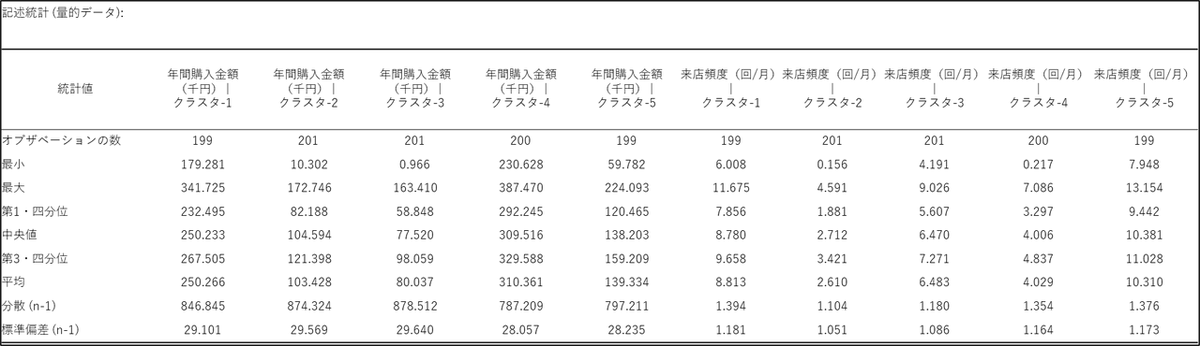
記述統計の出力結果
記述統計の結果にはクラスターごとに「年間購入金額」と「来店頻度」の最小値、最大値、平均、中央値、標準偏差などの情報を確認することができます。
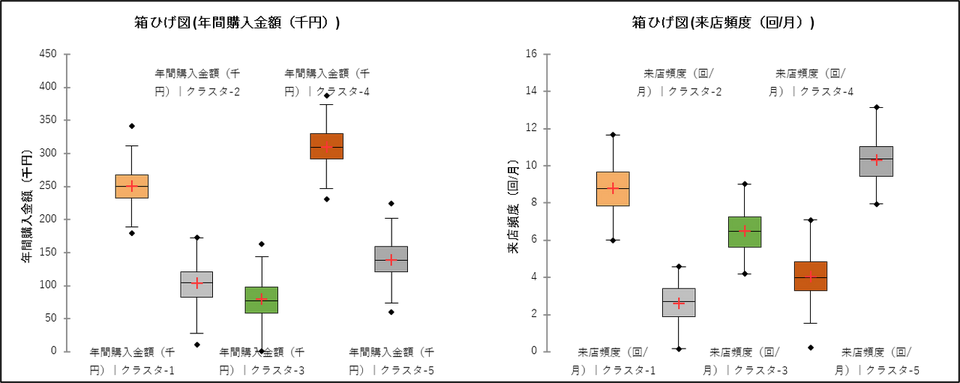
また、箱ひげ図や散布図も一緒に出力され、各クラスターのデータのばらつき具合を確認できます。
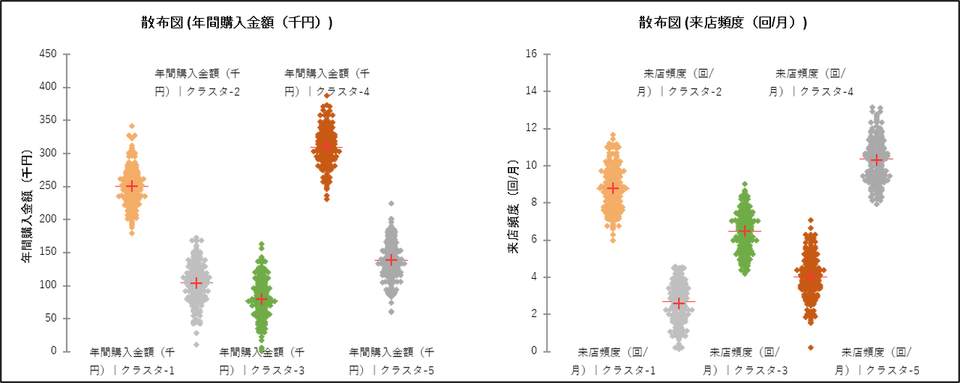
クラスターの解釈
k-means クラスタリングは、データ内の類似性に基づいてグループを自動的に抽出する手法ですが、抽出されたクラスターが何を意味するのか、どのような特徴を持っているのかは、分析者自身がデータと結果を照らし合わせて解釈する必要があります。ここまで出力した情報をもとに各クラスターの特徴を整理してみましょう。
全体平均
- 年間購入金額:176.47千円/年
- 来店頻度:6.4回/月
クラスター1:まとめ買いヘビーユーザー層
- 購入金額の平均:250.2千円/年
- 来店頻度の平均:8.81回/月
年間の購入金額が25万円を超え、月に約9回来店する層です。ほぼ週に2回以上の頻度で来店し、食料品だけでなく、日用品、惣菜、やや高めの嗜好品なども含めて、幅広い商品をまとめて購入するヘビーユーザーと考えられます。家族構成が多い、またはまとめ買いをする習慣があるのかもしれません。
クラスター2:特定ニーズ購入層
- 購入金額の平均:103.42千円/年
- 来店頻度の平均:2.60回/月
年間の購入金額が10万円程度で、月に2~3回来店する層です。2週に1回程度の来店で、週末にまとめて購入する、特定の食材や日用品を買い足すなど、目的を持った利用が多いと考えられます。単身者や二人暮らしで、外食が多い可能性もあります。
クラスター3:日常使い層
- 購入金額の平均:80.037千円/年
- 来店頻度の平均:6.48回/月
年間の購入金額が8万円程度で、来店頻度は月に6~7回と平均的な層です。週に1~2回程度の来店で、日常的な食料品や日用品を必要な時に購入する、標準的な利用層と考えられます。単身者から小規模な家族まで、様々な層が含まれる可能性があります。
クラスター4:高額まとめ買い層
- 購入金額の平均:310.36千円/年
- 来店頻度の平均:4.0288回/月
年間の購入金額が30万円を超え、最も購入金額が高い層ですが、来店頻度は月に4回程度とやや少なめです。月に数回の来店で、高級食材、こだわり商品、まとめ買い、あるいは業務用の食材などを大量に購入する顧客層と考えられます。富裕層や飲食店経営者などが含まれる可能性があります。
クラスター5:こまめ買い層
- 購入金額の平均:139.33千円/年
- 来店頻度の平均:10.31回/月
年間の購入金額が14万円程度で、月に10回以上来店する、非常に来店頻度の高い層です。ほぼ毎日のように来店し、生鮮食品や日配品など、鮮度を重視する商品をこまめに購入する顧客層と考えられます。近隣に住んでおり、毎日のように立ち寄る単身者や高齢者などが考えられます。
上記解釈を散布図に加えることで、よりクラスタリングの結果を理解しやすくなります。
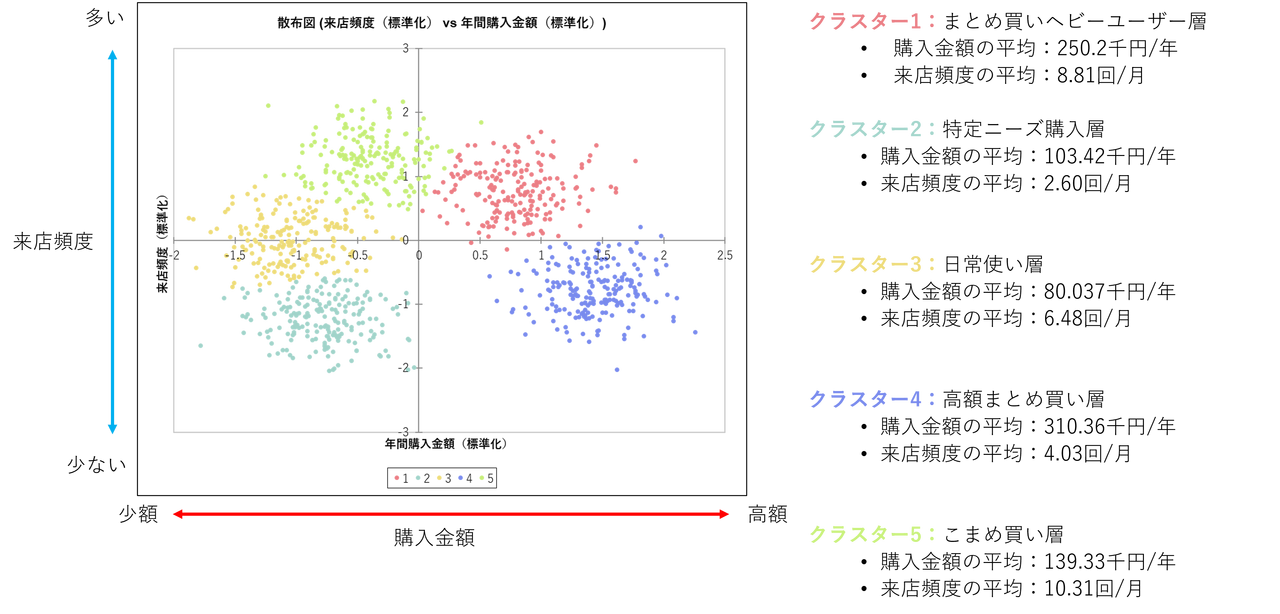
この結果をうまく活用すれば、各ユーザー層に対してどのような販促活動をすれば良いのかといった戦略の方向性を決めることができるかもしれません。
まとめ
k-means クラスタリングは、データ内の類似性に基づいてグループを自動的に抽出する手法です。顧客データのような多変量データを分析し、顧客を購買行動などに基づいてグループ分けする際に非常に役立ちます。クラスタリング結果をもとに、顧客グループごとのニーズや行動パターンを把握することで、より効果的なマーケティング戦略や顧客サービスを展開することが可能になります。
参考資料
- k-means clustering in Excel tutorial
https://help.xlstat.com/6434-k-means-clustering-excel-tutorial - Sebastian Raschka, Vahid Mirjalili (株式会社クイープ 訳 / 福島真太朗 監訳): Python機械学習プログラミング 達人データサイエンティストによる理論と実践, 株式会社インプレス, 2016.
- 非階層型クラスタリング「k-means法」の計算過程
https://analysis-navi.com/?p=618
XLSTAT の無料トライアル
トライアルでは、最上位パッケージ XLSTAT Advanced に加え、3D Plot と LatentClass のオプションもご利用いただけます。本記事で紹介したk-means クラスタリングはすべてのライセンスでご利用いただけます。
無料トライアルを申し込む*トライアルは登録完了日に開始され、有効期間は14日間です。トライアルを更新または延長することはできません。


