Q:XLSTAT でデータを標準化する方法
Answer
このページでは、XLSTAT を用いてデータセットを標準化する手順をご紹介します。
データの標準化とは?
データの標準化とは、異なる尺度を持つ変数間の比較を容易にするために、データの平均を0、標準偏差を1になるように変換する処理です。これにより、元のデータの単位に依存せず、各データが平均からどれだけ離れているかを相対的に評価することができます。
データを標準化する理由
データを標準化する主な理由は以下の通りです。
- 異なる尺度を持つ変数の比較:
例えば、身長(cm)と体重(kg)のように、単位が異なる変数を直接比較することは困難です。標準化することで、これらの変数を同じ尺度で評価できるようになります。 - 多変量解析における影響の均等化:
重回帰分析や主成分分析などの多変量解析では、変数の尺度が結果に影響を与えることがあります。標準化により、各変数が分析に均等に寄与するように調整できます。
XLSTAT でデータを標準化する操作手順
XLSTAT でデータ標準化を実行する手順は以下の通りです。
-
XLSTAT を起動し、[発見、説明および予測] > [データ準備] > [変数変換] を選択します。
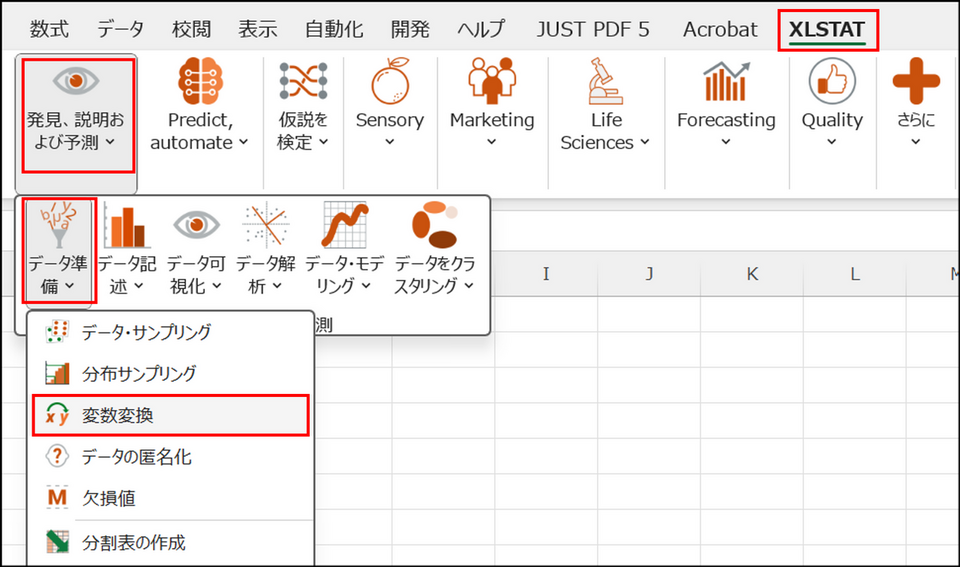
-
ダイアログボックスが表示されるので、[一般] タブで以下のようにデータを選択します。
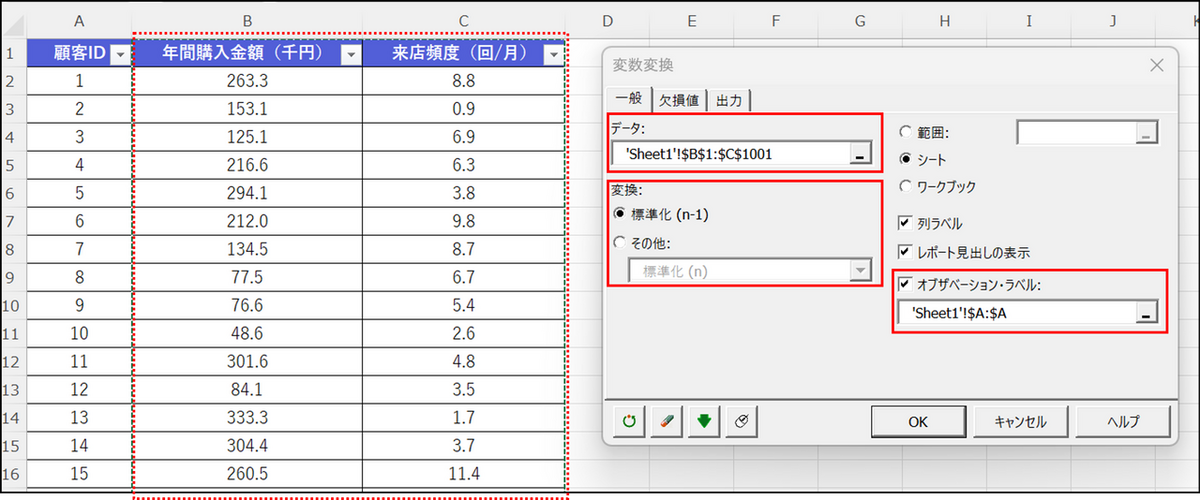
- [データ]:
標準化したいデータ範囲をマウスで選択。列名を含めて選択した場合は、[列ラベル] にもチェックを入れます。 - [変換]:
「標準化 (n-1)」または「標準化 (n)」を選択。- 標準化 (n-1):不偏標準偏差(標本標準偏差)を用いて標準化
- 標準化 (n):標本標準偏差を用いて標準化
その他の変換オプション(中心化、リスケールなど)も選択できます。
- [オブザベーション・ラベル](任意):
データのID 列を選択します。選択しなくても標準化は実行可能です。
- [データ]:
-
[OK] をクリックすると、結果が別シート(変数変換)に出力されます。
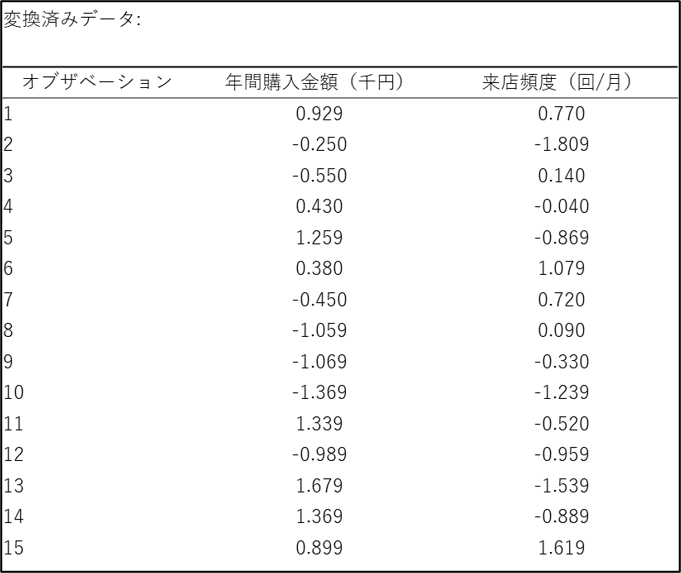
【補足】標準化時の n と (n-1) の違いと使い分け
標準化の際に、標準偏差の計算で分母として n を用いるか、n−1 を用いるかの違いは、母集団の標準偏差を推定するか、標本自身の標準偏差を計算するかという統計学的な考え方に基づいています。
- 標準偏差 (n): (標本標準偏差)
データの個数 n を分母として標準偏差を計算します。これは、標本自身のばらつきを直接的に表す指標となります。 - 標準偏差 (n-1): (不偏標準偏差)
データの個数 n から1を引いた n−1 を分母として標準偏差を計算します。これは、標本から母集団の標準偏差をより正確に推定するための補正を加えたものです。自由度に基づいたより普遍的な推定値とされます。
記述統計として、その標本データの特性をそのまま見たい場合は、「標準化 (n)」を使用します。標本データを用いて、その背後にある母集団の特性を推定したい場合は、「標準化 (n-1)」を使用します。一般的には、統計的推論を行う場合(例:仮説検定、信頼区間)には、不偏標準偏差を用いる「標準化 (n-1)」が推奨されます。
XLSTAT の「変数変換」機能を利用することで、簡単にデータの標準化を行うことができます。データの性質や分析の目的に応じて、適切な標準化の方法を選択してください。
以上


