質的研究ではインタビューの書き起こしやアンケートの自由記述欄など大量のテキストデータを扱います。そこから意味のある情報を見つけ出すには、効率的な分析手法が欠かせません。NVivo の頻出語クエリを利用すると、テキストデータ内で頻繫に出現する単語を検索し、どのような内容のことが記載されているのか傾向を把握することができます。また、結果を単語クラウドという図表で可視化することも可能です。このページでは頻出語クエリの機能概要や操作手順、結果の見方をご紹介します。
※なお、このページではNVivo 15 Windows 版を使ってご説明しております。
- 頻出語クエリとは?
- 頻出語クエリ実行時の注意点
- テキストコンテンツの言語設定
- 頻出語クエリの操作手順
- 頻出語クエリの結果画面の見方
- 結果を絞り込む
- 単語をグループ化する
- 単語の出現箇所を確認する
- 結果をコードとして保存する
- 停止語リストの追加
- 停止語リストの確認
- 頻出語クエリの出力
- 検索条件を保存する
- まとめ
- 参考ページ
頻出語クエリとは?
頻出語クエリとは、テキストデータの中から出現頻度の高い単語を抽出する機能です。例えば、インタビューデータから頻出語を抽出することで、対象者がどのようなテーマについて多く語っているのか、どのようなキーワードを頻繁に使っているのかを把握することができます。

頻出語クエリを使用することで以下のようなことが可能になります。
- テーマの発見
プロジェクトの初期段階で、分析対象となるデータにどのようなテーマが含まれているのかを把握するのに役立ちます。
- 特定グループの分析
特定の属性を持つ人々がどのような言葉を使っているのかを分析することができます。
- 概念の把握
類似語をグループ化することで、データ全体を俯瞰し、主要な概念を捉えることができます。
頻出語クエリ実行時の注意点
頻出語クエリを実行する際には以下の点にご注意ください。
- テキストコンテンツの言語設定
頻出語クエリを実行する前に、プロジェクトのテキストコンテンツの言語が、分析対象のデータの言語と一致しているか確認しましょう。言語が正しく設定されていないと、出力結果が正常に表示されないため、ご注意ください。また、1つのプロジェクトで複数の言語を選択することはできません。
- 日本語の取り扱い
日本語の場合は、動詞の活用形を考慮しないでカウントされます。例えば、頻出語に「諦める」という単語があれば、「諦める」だけでなく、「諦めず」や「諦めない」という単語も含めてカウントされます(頻出語は原形でまとめて表示されます)。そのため、出力結果を解釈する際には必ずどのような文脈で使われているのかも合わせて確認する必要があります。
- 半角全角文字の区別
頻出語クエリでは半角全角を区別せずにカウントします。クエリ結果では半角文字で表記されます。
- 停止語
分析に不要な単語(例:接続詞、前置詞など)は、停止語として設定することで、結果から除外することができます。
- 句読点
単語に含まれる句読点(ハイフン、ピリオドなど)は、単語を分割する際に影響を与える可能性があります。
- アポストロフィ
アポストロフィを含む単語は1つの単語として扱われますが、アポストロフィの後に「s」が続く場合は、s は含まれません。
- データセットのテキスト
データセットでは、コード化可能なフィールド(列)の単語のみがクエリに含まれ、分類フィールドの単語は無視されます。
- 画像内のテキスト
画像内のテキストは検索できません。
テキストコンテンツの言語設定
頻出語クエリを実行する前に分析対象の言語が正しく設定されているかを確認します。
テキストコンテンツの言語はプロジェクト単位で設定可能です。
-
メニューの[ファイル] > [プロジェクトプロパティ] をクリック
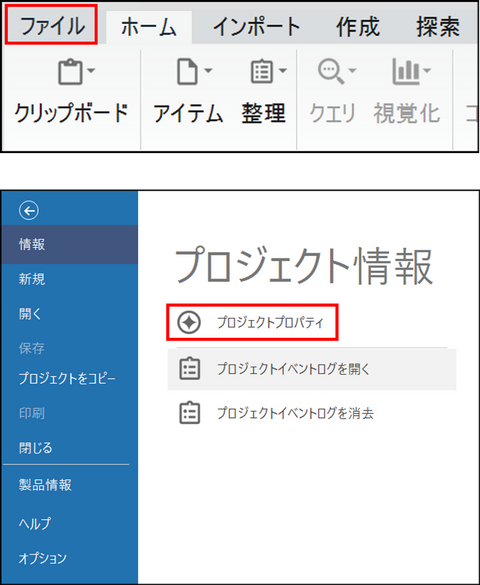
-
[テキスト内容の言語] から分析対象の言語を選択
もし日本語のデータを分析するのであれば、日本語を選択します。ここの言語設定が誤っていると、頻出語クエリの結果が正しく表示されないので、ご注意ください。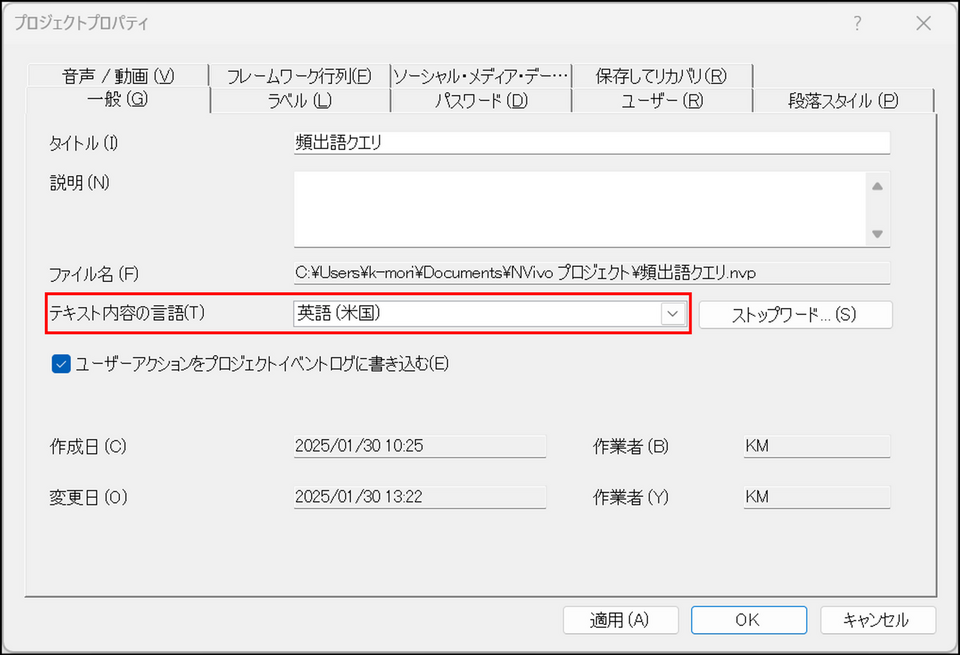
-
[適用] > [OK] の順にクリック
言語設定変更後はプロジェクトファイルを開き直してください。
頻出語クエリの操作手順
頻出語クエリの操作手順は以下の通りです。今回は米国のドナルド・トランプ大統領が2025年1月にワシントンの連邦議会議事堂で行った就任演説のトランスクリプトを使用して、頻出語を確認してみたいと思います。なお、演説の全文は下記ページより確認できます。
The Inaugural Address – The White House
-
メニューの [探索] タブから [頻出語クエリ] をクリック
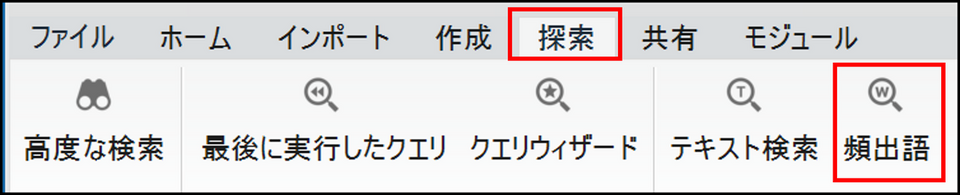
画面サイズにより虫眼鏡アイコンの形で表示されます。
-
表示された画面で[選択したアイテム] をクリック
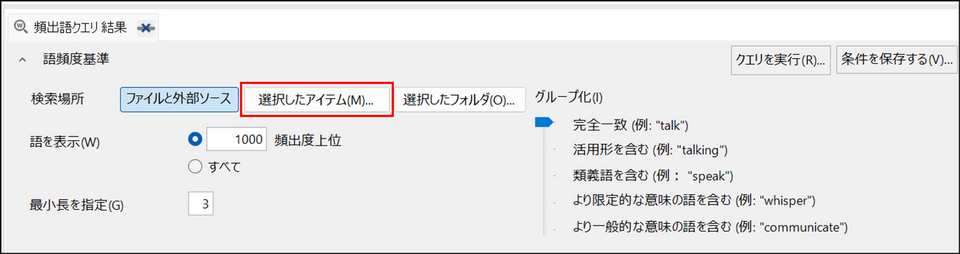
-
対象のアイテムにチェックを入れ、[OK] をクリック
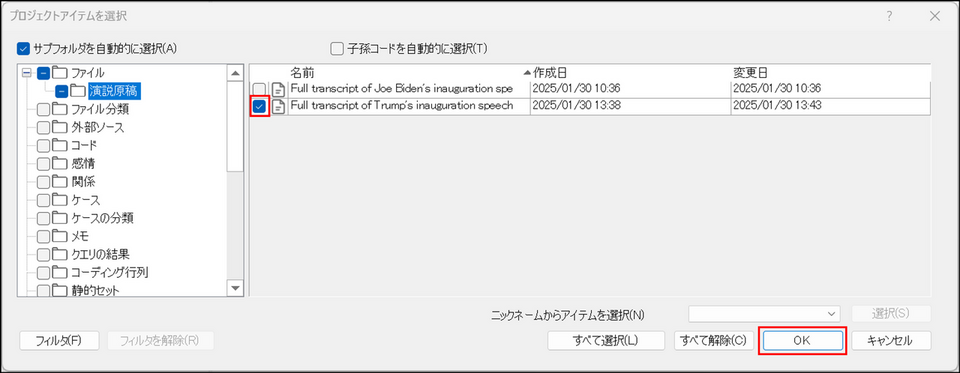
-
[クエリを実行] ボタンをクリック
→ 結果が画面下部に表示されます。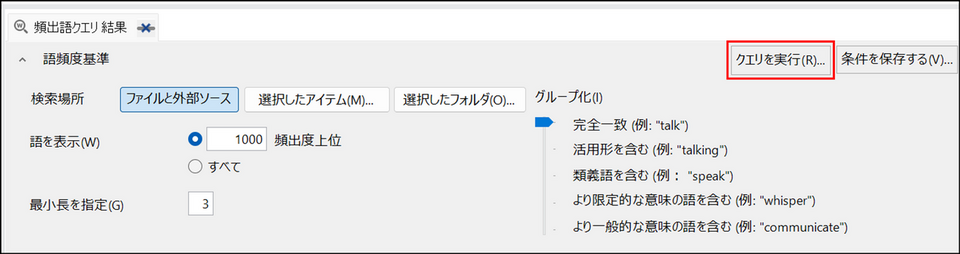
【補足】
対象のアイテムを右クリックし、表示されるメニューから[クエリ] > [このドキュメントの頻出語クエリ] を選択することで頻出語クエリを実行することも可能です。
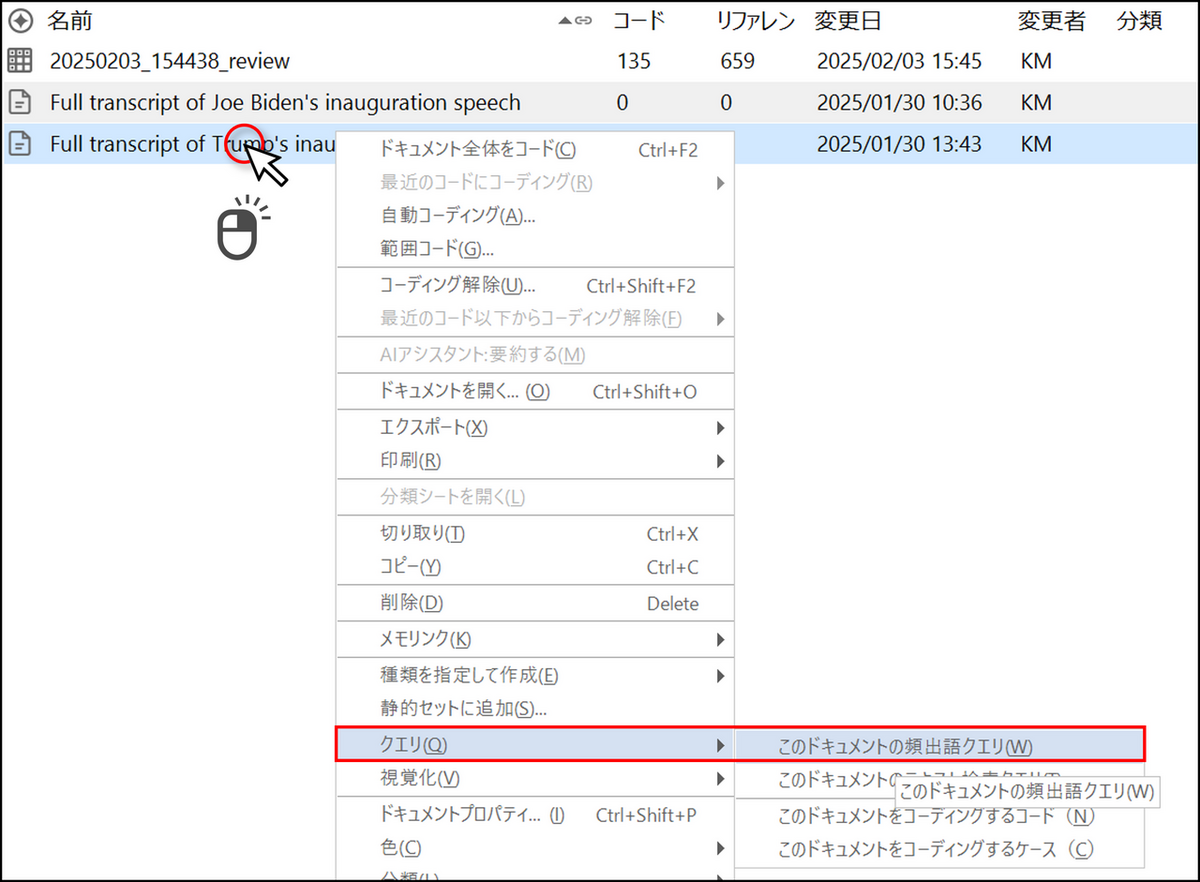
頻出語クエリの結果画面の見方
頻出語クエリの結果画面の右側にはタブが表示され、タブを切り替えることで表示内容が変更されます。
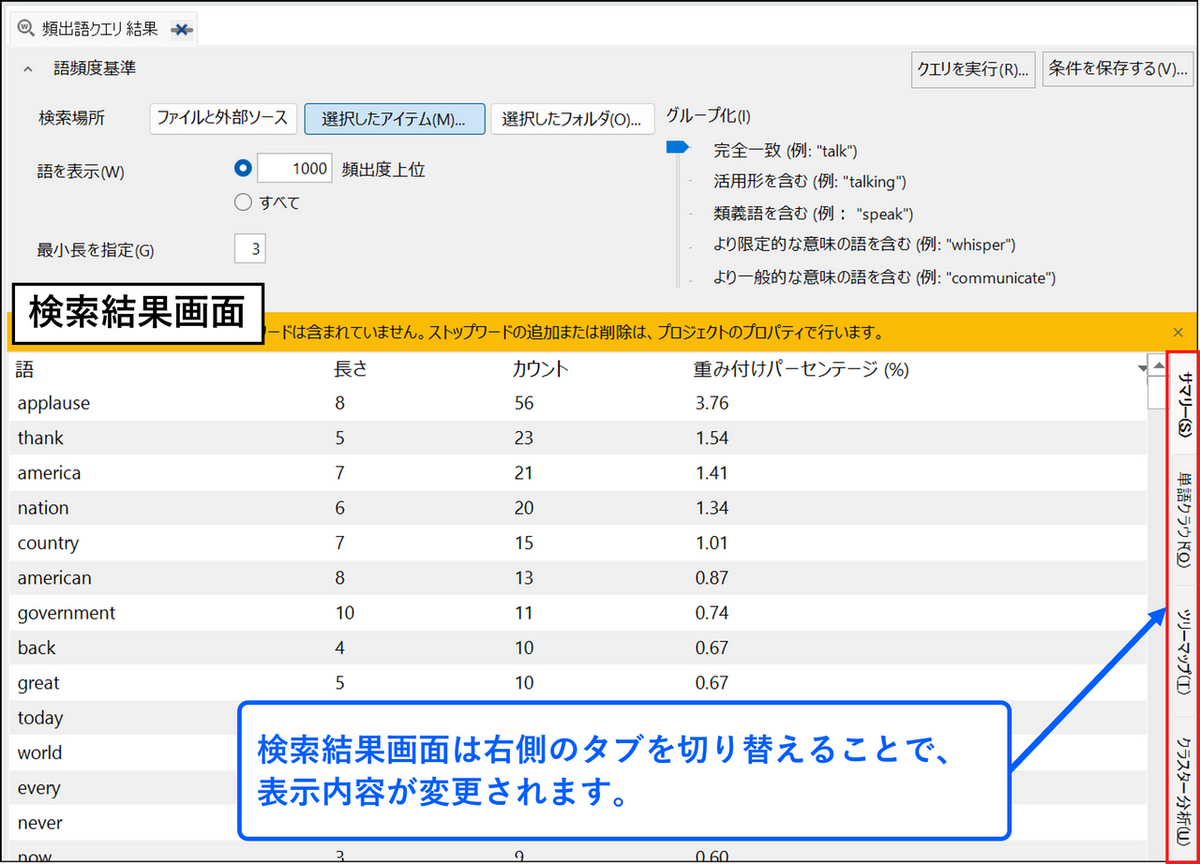
- サマリー:頻出語のリストが表示されます。
- ワードクラウド:頻出語が、出現頻度に応じて異なるフォントサイズで表示されます。
- ツリーマップ:頻出語が、出現頻度に応じて異なるサイズの四角形で表示されます。
- クラスター分析:共起する単語がクラスター化されて表示されます。アイテムが2つ以上選択されている必要があります。
サマリータブ
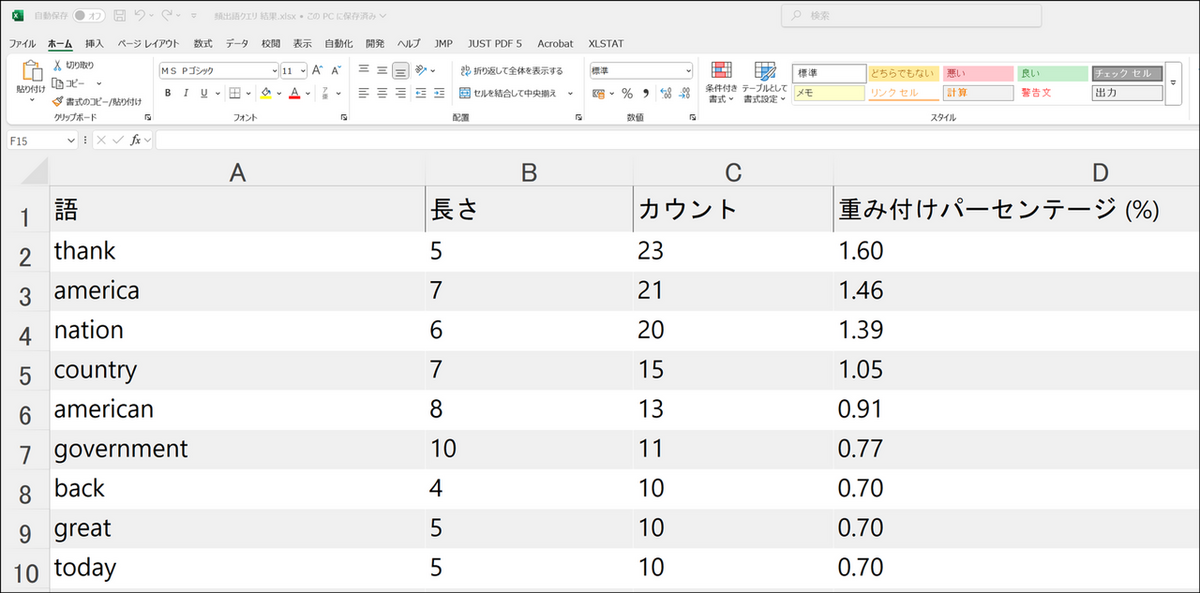
サマリータブでは、データ内で出現回数が多い単語が降順で表示されます。
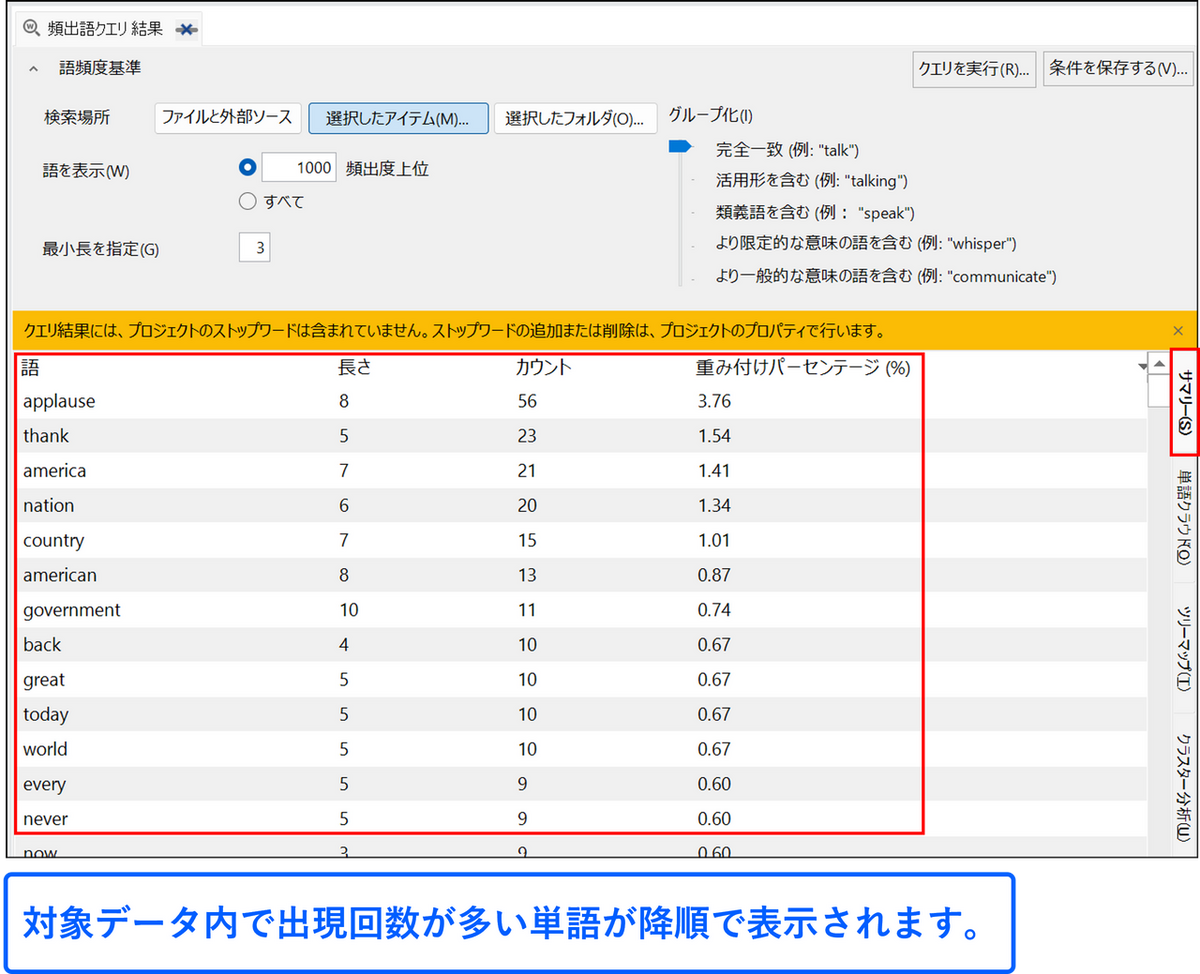
結果内に表示される項目とその意味
- 語:頻出語クエリで特定された単語
- 長さ:単語の文字数
- カウント:データ内でのその単語の出現回数
- 重み付けパーセンテージ(%):
頻出語クエリでカウントされた総単語数に対するその単語の頻度。パーセンテージの数値は各単語を、クエリでカウントされた総単語数で割ることで算出されています。
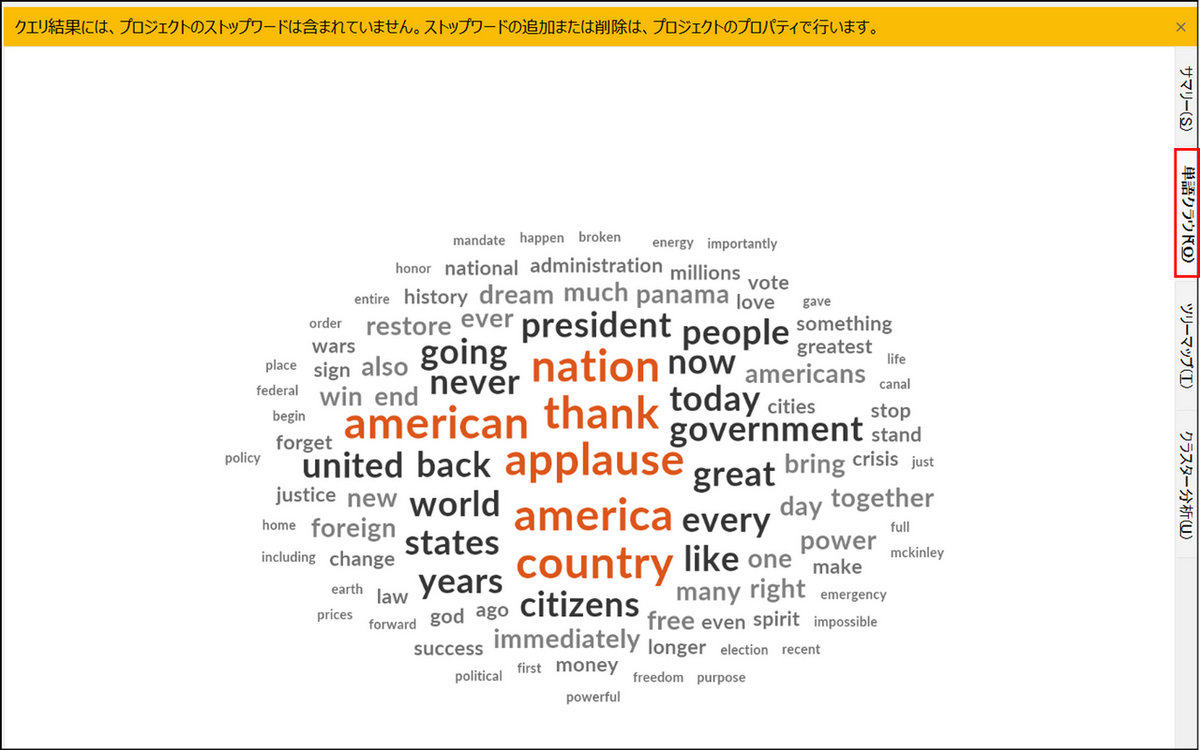
単語クラウドタブ
単語クラウドタブに切り替えると、対象データ内で最も頻繁に使用されているキーワードや用語を視覚的に表現した図が表示されます(最大100の単語)。単語のフォントサイズは、その出現頻度に応じて大きくなります。
メニューの[頻出語クエリ] 内で単語クラウドのレイアウトを変更することも可能です。

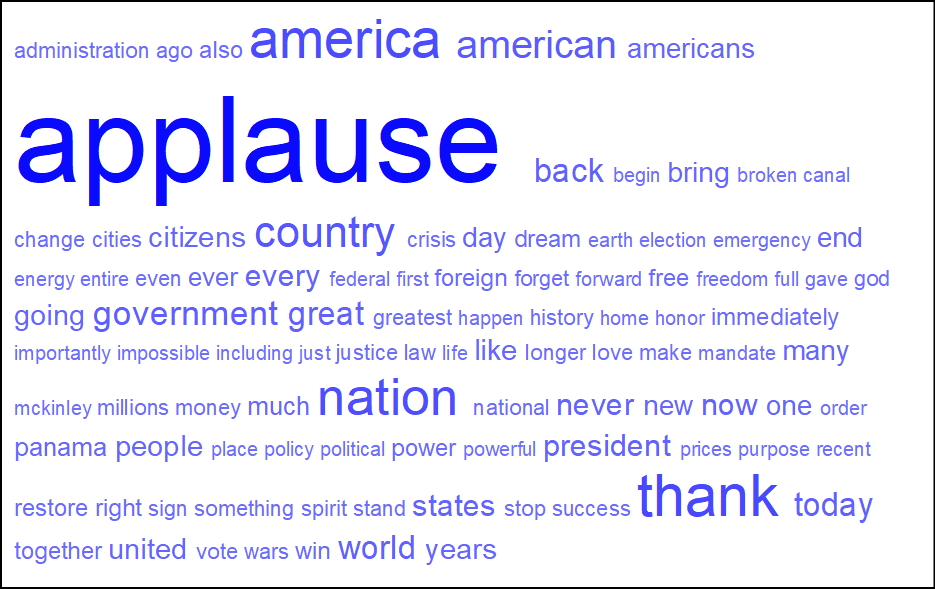
なお、単語クラウド上の文字の配置や色はランダムで出力されるため、同じレイアウトを選択していてもクエリを実行するごとに少しずつ異なる場合があります。
ツリーマップタブ
ツリーマップタブでは、最大100の単語が長方形の列として表示され、頻出単語はより大きな長方形で表示されます。

結果を絞り込む
下記項目の数値を変更することで、結果を絞り込むことができます。
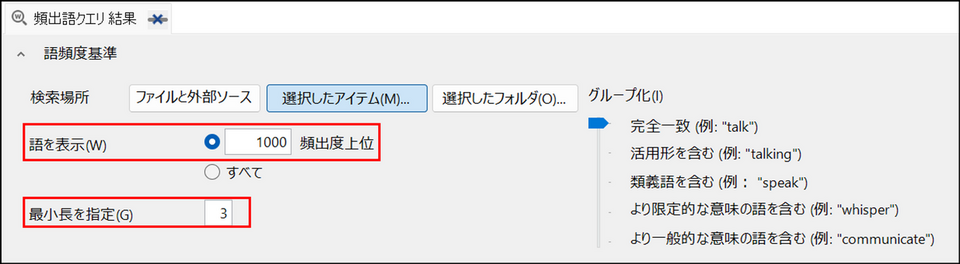
- 頻出度上位
結果に表示する単語数を指定します。初期設定では出現回数上位1,000 の単語が表示されます。
※単語クラウドは上位100 までの単語を表示。
- 最小長を指定
結果に表示する単語の最小文字数を指定します。初期設定では1文字以上の単語が表示されます。
設定を変更した場合は、[クエリを実行] ボタンをクリックすると、再度クエリが実行され、結果が更新されます。
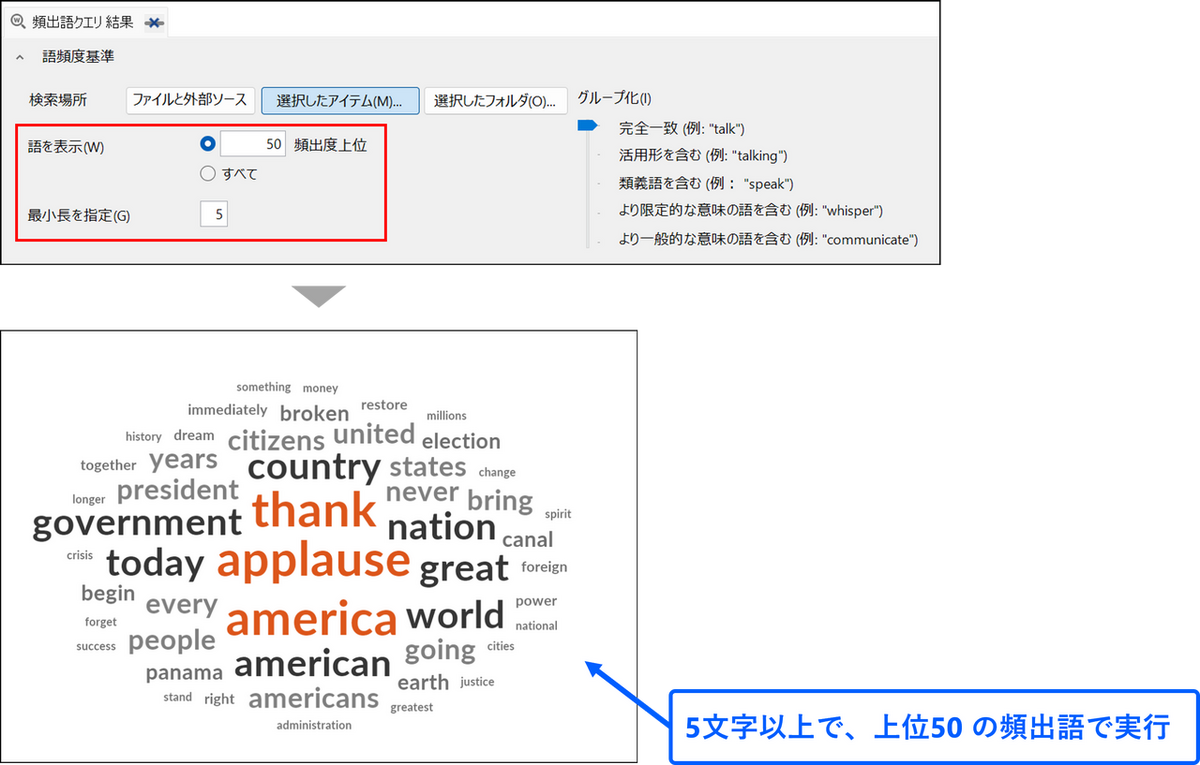
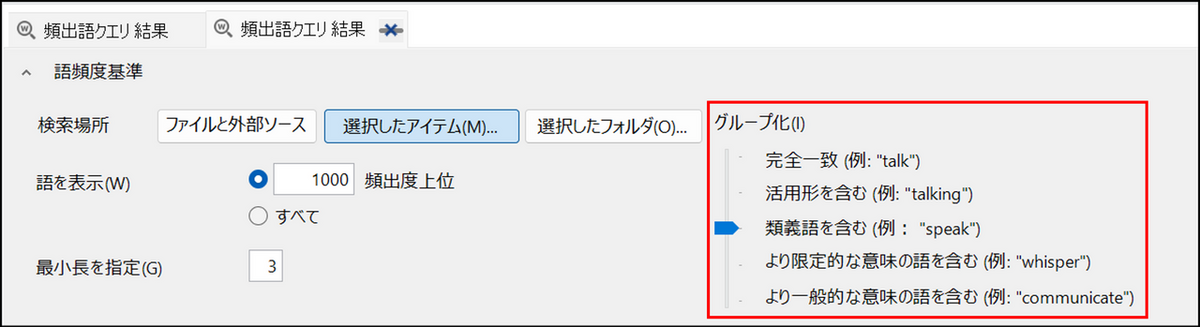
単語をグループ化する
グループ化の項目で類似語などをグループ化して集計することができます。グループ化のレベルは5段階あり、スライダーで調整することができます。レベルが高くなるにつれて、検索範囲が広がります。 なお、日本語の場合は活用形を考慮しないで検索するため、レベル1 (完全一致)とレベル 2(活用形を含む) の違いはありません。
設定変更後、再度クエリを実行をすると、結果が更新されます。

単語の出現箇所を確認する
結果画面[サマリー] タブに表示される単語を右クリックし、[コードプレビューを開く] または[テキスト検索クエリを実行] を選択すると、その単語が出現する箇所を確認することができます。
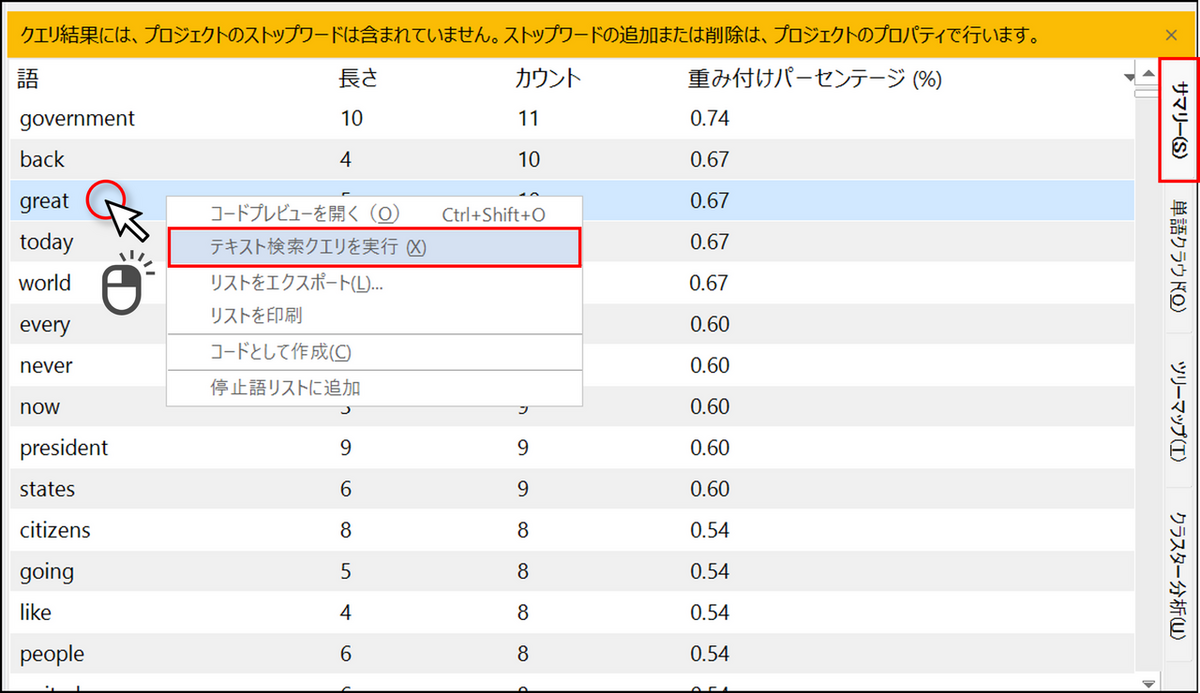
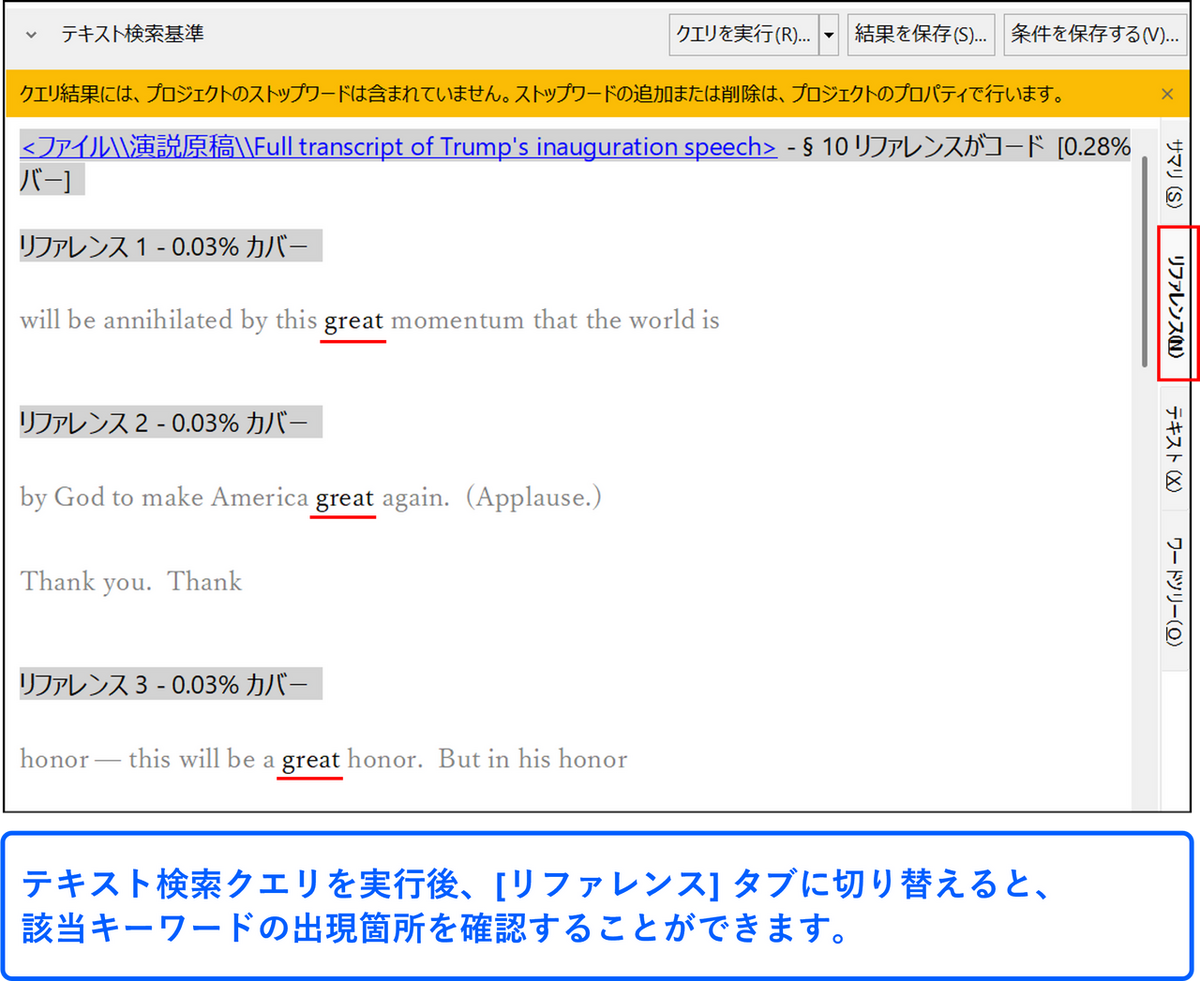
テキスト検索クエリの結果画面の見方についてはこちらのページ もご参照ください。
【注意】
頻出語クエリでは半角全角を区別せずにカウントしますが、頻出語クエリの結果からテキスト検索を実行した場合、半角文字で検索を実行するため、全角文字の単語は表示されません。頻出語クエリ結果のカウントとテキスト検索のカウントが異なる場合は、別途テキスト検索クエリで全角文字を再検索してください。
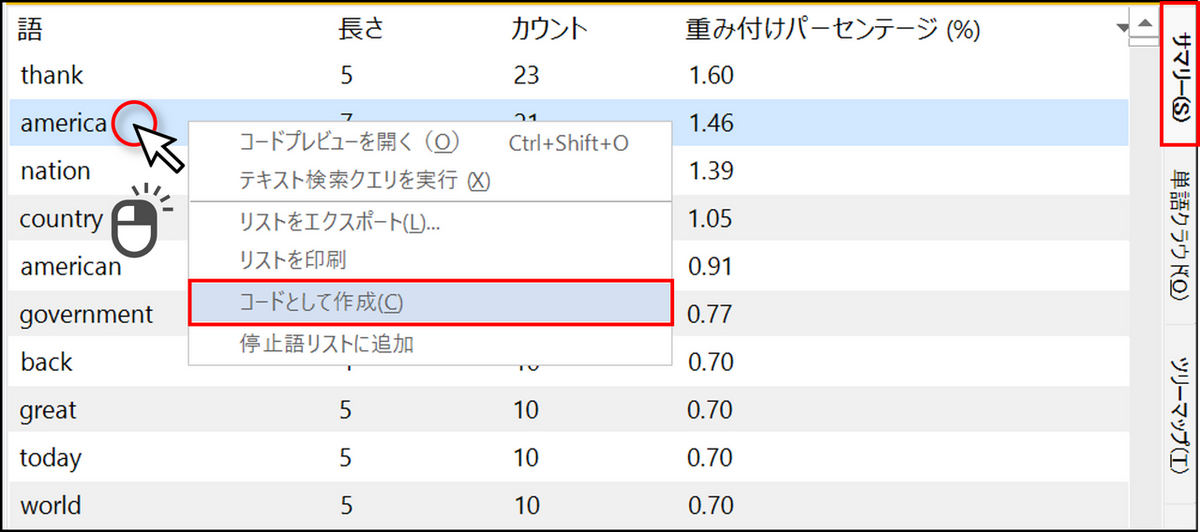
結果をコードとして保存する
頻出語クエリで抽出された単語をコードとして保存することも可能です。
-
[サマリー] タブにてコードとして保存したい単語を右クリックし、[コードとして作成] を選択
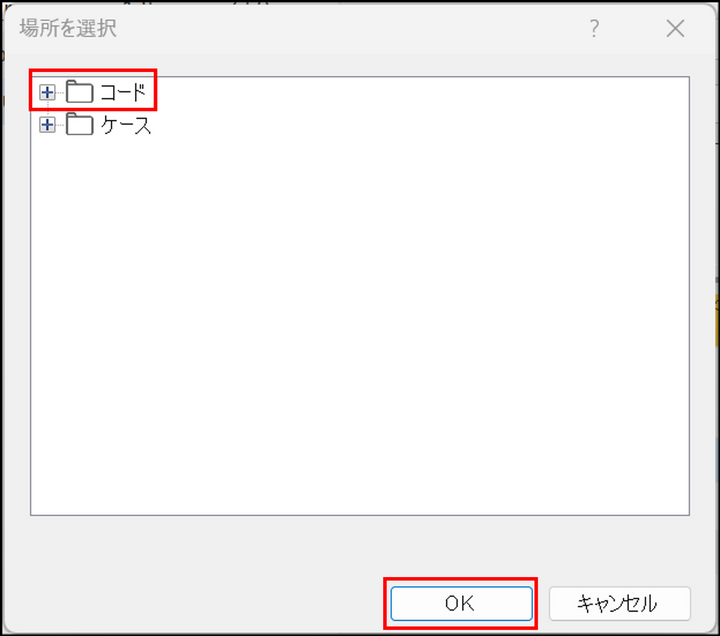
-
コードの保存場所を指定し、[OK] をクリック
-
コード名を入力して、[OK] をクリック
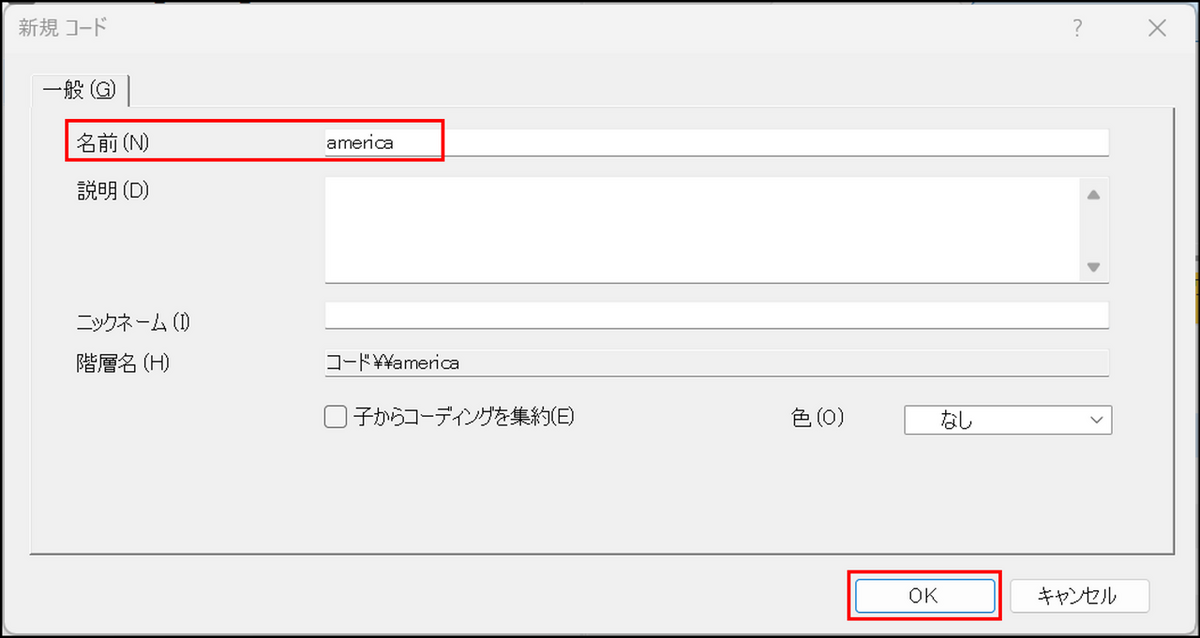
→ 指定した場所にコードが保存されます。
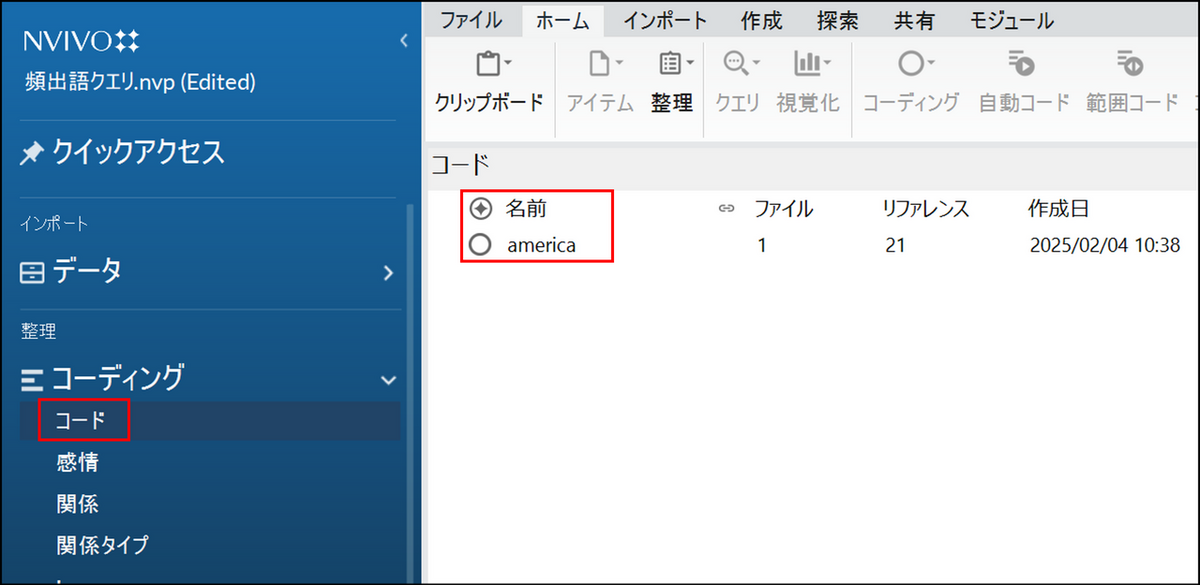
停止語リストの追加
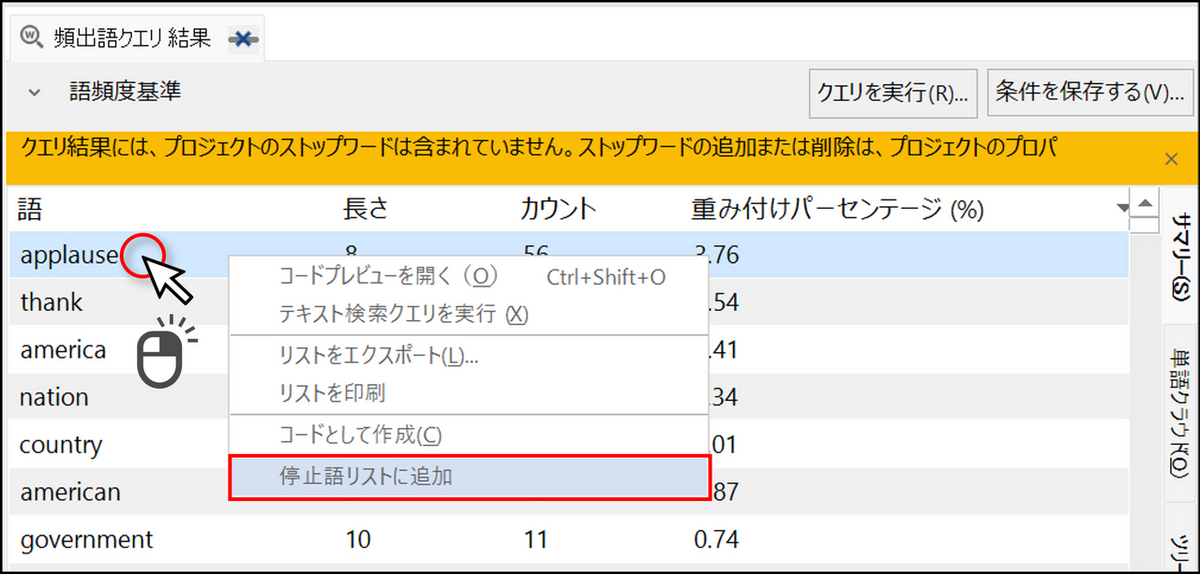
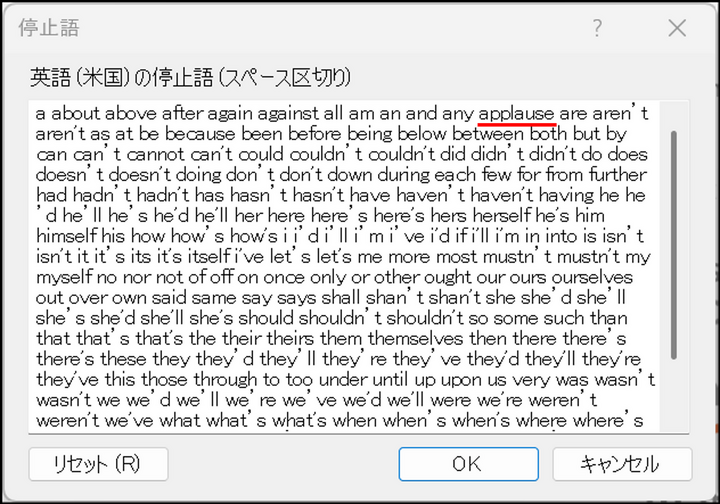
頻出語クエリの結果に表示させたくない単語がある場合は、以下の手順で結果から除外することができます。今回のデータでは”applause(拍手)” が多くカウントされていますが、演説内容ではないので、頻出語から除外しておきます。
-
[サマリー] タブにて表示させたくない単語を右クリックし、[停止語リストに追加] を選択
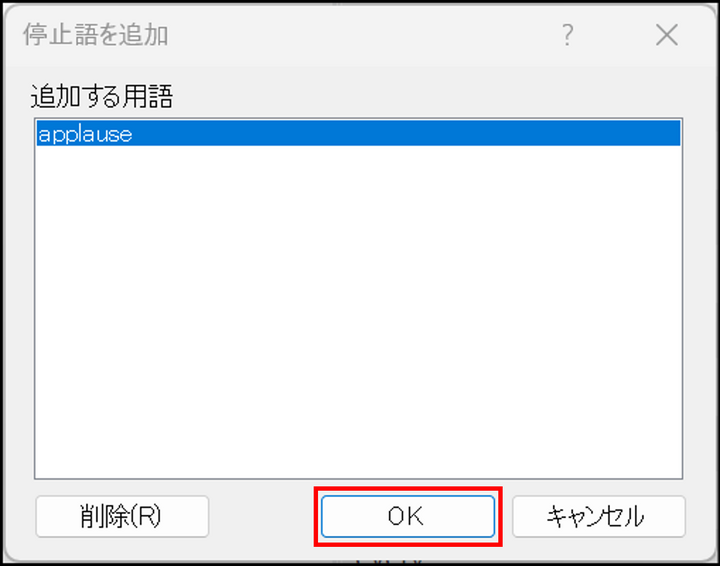
-
確認画面で[OK] をクリック
-
画面右上の[クエリを実行] ボタンをクリック

→ 結果が更新されます。

停止語リストの確認
停止語リストに追加した単語は、プロジェクトプロパティで確認することができます。
-
メニューの [ファイル] を選択し、[プロジェクトプロパティ] をクリック

-
[一般] タブに表示される[ストップワード] をクリック
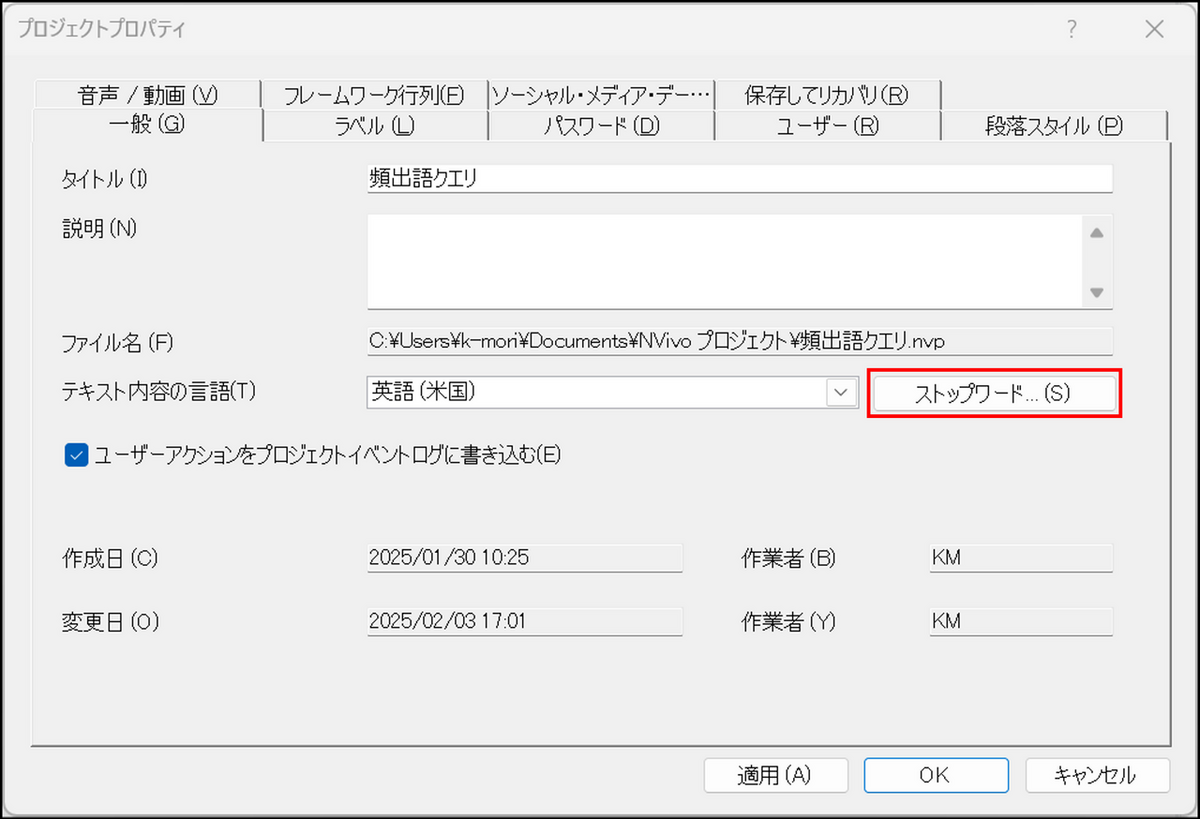
→ 現在停止語に設定されている単語が表示されます。停止語リストに追加した単語を解除したい場合は、この画面上から直接削除してください。
頻出語クエリの出力
頻出語クエリの結果はリストまたは画像で出力することができます。
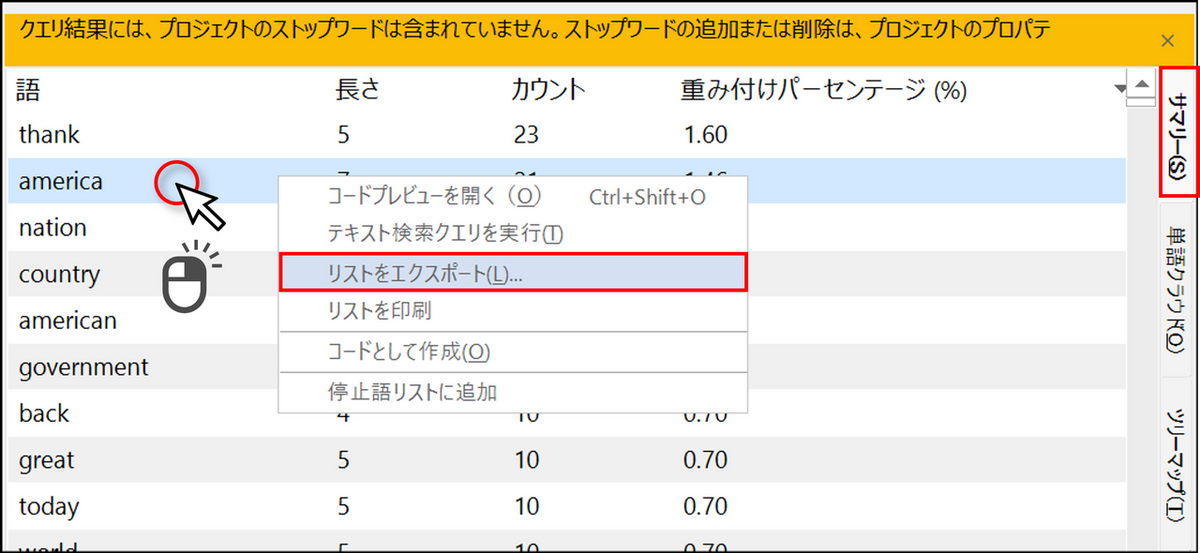
リストを出力
-
サマリータブを選択した状態で、リスト部分を右クリックし、表示されるメニューから [リストをエクスポート] を選択
-
保存場所とファイル名を指定し、[保存] をクリック
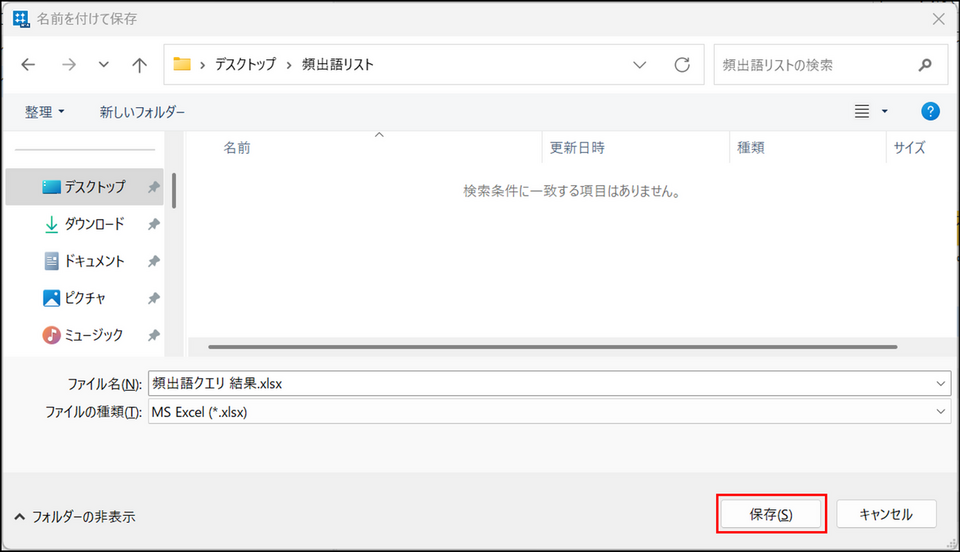
→ エクセル形式で検索結果が出力されます。
単語クラウドを出力
単語クラウドは画像として出力することができます。
-
単語クラウドタブを選択した状態で、空白部分を右クリックし、表示されるメニューから [単語クラウドをエクスポート] を選択

-
保存場所とファイル名を指定し、[保存] をクリック
→ 指定した場所に画像が保存されます。
検索条件を保存する
頻出語クエリを実行後、検索条件を保存しておくことで、あとで同じ条件で頻出語クエリを実行することができます。
-
頻出語クエリ実行後、[条件を保存する] ボタンをクリック
-
クエリの名前を入力して、[保存] をクリック
保存した条件は、ナビゲーションビュー[クエリ] > [クエリ条件] フォルダに保存されます。
まとめ
頻出語クエリは、質的データ分析において、重要なテーマを効率的に抽出するための強力なツールです。NVivo の頻出語クエリを活用することで、大量のテキストデータから隠れたパターンやテーマを見つけ出し、分析に役立てることができます。ぜひ、このページを参考にして、ご自身の研究に頻出語クエリを活用してみてください。

