NVivo上でデータから図表を作成できます。さまざまなカテゴリーやノード、そしてそれら相互の関連性が視覚化されます。
コーディングクエリにより、あなたがお持ちのデータ形式に対する見識が与えられ、さらに詳細な調査に値することがらに関しての理解が始まります。そして、行列コーディングクエリにより比較され、さらに鮮明にデータが対比されます。
質問する
この投稿では、さまざまな質問に対してどのようにNVivoのデータから引き出され、さらに比較的簡単に分析が可能なのかについてお見せします。
研究者として私が知りたかった質問は以下のようなものです。
- インタビュー、調査、フォーカスグループデータを考えた際、私が得た結果は大多数を代表するものなのか、それとも単に回答者の中で最も声高ではっきりしている回答だったのか?
- データのカテゴリー間に意味のある関係はあるのか?
- データのカテゴリー間に有意差はあるのか?
- 時間の経過によって、認識できる事象パターンはあるのか?
ここから、より一般的な3つのポイントが現れます。まず1番目に、何らかの質的(もしくは名義)統計学の記憶がある方にとって、「カイニ乗検定」だけが成果なのではありません!2番目には、統計的なテストすることが、あなたがコンピュータの奴隷になるということではありません。
カテゴリー選択やテスト結果の理解など、あなたの判断は特定の方法で質問を作成・提示するときと同様に不可欠なのです。3番目は、NVivoを使用した質的分析は、量的分析をより安全なものにします。一連の処理のボタンを押す前の根拠の形成に役立ちます!
関連性を探る
例として、NVivoに搭載されているサンプルプロジェクトの「ダウン・イースト地区における環境変化(Environmental Change Down East)」を取り上げましょう

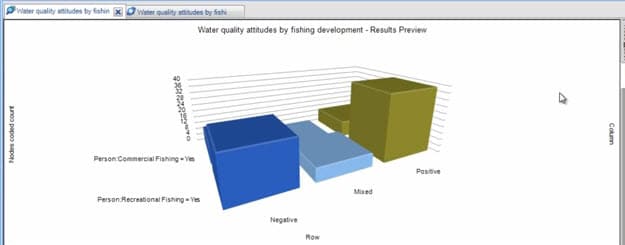
このデータセットは、サンプルプロジェクトで利用されている行列コーディングクエリを実行して取得しています。水質に関するコメント数が、ふたつの要因によりクロス集計されました。
- 人口統計(漁業のタイプ)
- 水質に対するカテゴライズ化された態度(+、-、?)
しかし、コメントの割合は数名の回答者の騒ぎに影響されないのでしょうか?批判さんは、社交家夫人と激情家夫の子供ということで、わずか一家族に影響されるかもしれません。
コメント数のかわりに人数で集計をするよう、NVivoは簡単に切り替え可能です(上記動画をご覧ください)。そこから、これはある集団内のサンプルとなる人たちを研究していることを確認できます。この特定基準を探ってみましょう。

これで(動画で再度示されています)、NVivo内に作成された図表により、関連性について調べることも可能です。
重要な関連性をテストする
私たちはさらに、SPSSやStatsDirectなどのソフトウェアへ自分のデータを移行することができます(SPSSで注意していただきたいのは、元データとは対照的に上記のサマリーデータをインプットする場合、「ウエイトケース」を使用し、数字、頻度、変数などを選択しなければならないことです) 。

左側にある数字をテストしてみましょう。それはカイニ乗検定との関連です。このテストにより、漁業の人口統計と水質に対する態度のふたつの要因の間に関連性があるかどうかが分かります。
その結果は有意ではありません。
証明できる関連性はないという仮説を、私たちは受け入れるべきです。しかし、あなたは「Mixed(入り混じった)」態度は排除すると決断するかもしれません。なぜなら、このテストではその回答数は少なく(いかなるカテゴリーでも最小回答数は5となり、フィッシャー検定は容認していますが、このテストには不適切です)、より端的に言えば、これらの回答を保持することに意味があるとあなたは考えません。
そこで、右側のデータを使って2×2のカイニ乗検定をおこないます。この場合、繰り返しになりますがその結果は有意ではありません。
重要な関連性の例
私の著書から例をあげますが、社会もしくは環境課題に関する推進活動を目にすることと、その課題に対する懸念との関連について関心を持っているとします。
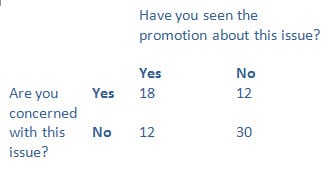
この場合、その関連性は有意です。私たちは「帰無仮説を棄却する」ことが可能で、この結果は偶然や外的要因の影響であると言えます。しかし、私たちは関連性が存在している点にはかなり自信を持っていますが、相互関係は因果関係を証明しません。推進活動は認識を高めているのかもしれませんが、その代わり、心配している人々は自分の懸念を裏付ける資料を探している可能性があります。どちらをあなたの質的分析に反映させますか(そしてその後、どちらで数値化させるか)。
分析に対する可能性は無限です。性別と政策や製品に対する態度の関連、教育的嗜好と能力の関連、化学物質の存在と疫病の発生の関連などがあります。
有意差を決定する
NVivoのサンプルプロジェクトの例に戻りましょう。

私たちは、さらに掘り下げようと決断するかもしれません。
商業的な漁業に従事する人たちは、問題に関して意見が分かれます。私たちは左側の数字をテストしません。これは半々だとはっきり分かるからです。しかし、趣味で釣りをする人たちはかなり肯定的に見えます。しかし、そこには有意差があると言えるのでしょうか。趣味で釣りをする人たちの例で、彼らは明らかに肯定的であることが示されているのでしょうか。
適合度テストのカイニ乗検定を使用することで、回答内の相違を調査することが可能でした。このテストに従うと、その数値は26、8、39となり、かなり有意差が出ます。しかし、このテストは特定の数字が優勢であるということを述べているのではなく、単に関連する数字の間で有意差があるということなのです。つまり、「非選好」仮説の棄却が可能です。
さらに調べるためには、データをもっと切り落としてふたつの数字の選択(二分法)にする必要があります。この点に移る前に、このテストの他の使用法を提案したいと思います。消費されたさまざまな食物に関連したボツリヌス中毒の発生、異なる製品の選択、土壌タイプによって決まる松の木の本数などがあります。それぞれの場合、要因から生じる有意差があるかどうかが分かりますが、それ以上に特定されるものはありません。
質的評価を実行する
ところで、偶然の一致ではありませんが、何が重要で何が重要でないかを知るためだけに、なぜこれら数多くのテストがおこなわれるのでしょうか。各テストの結果がおおまかに述べているのは、このテストでは偶然のチャンスは(例えば)100回のうちたった2回しかないということです(p < .02 は、有名な「確率値」です)。
これは当然です。アルフ・ガーネットはこの際には言わないでしょうが、たくさんのテストがおこなわれると、まぐれ当たりによる結果の出現がかなり増えます。それは実のところ、100回のうち2回の結果のひとつなのです。
そして、ギャンブラーの誤謬を思い出しましょう。驚くべきことですが、事前に起こることは次に起こることに影響しません。だから、まぐれ当たりがいつ出るのか、もしくはどれくらいの頻度で出るのかは絶対に分かりません。しかし、明らかなのは楽しみながらテストをすると、まぐれ当たりのチャンスが増えるということです。
だから、古い結果をただ調べる(「採集する」)代わりに質的評価をおこない、何が重要で、そのために何のテストが必要なのかを知るべきです。数学的な人工物を避けることはあなたの義務です。それはコンピュータの仕事ではありませんよ!
有意差をテストする他の方法

「Mixed(入り混じった)」を取り除いて、二者の考えの間に有意差があるか見てみましょう。つまり、水質に関して肯定的で、趣味で釣りをする人たちは、過半数を大きく上回っているのでしょうか。
ここであなたは、二項検定か符号検定を使います。どちらを使っても、有意ではない結果が現れるでしょう(テスト結果がかろうじて「有意ではない」場合、これは影響がないということではなく、可能性が除外される明らかな証拠がないということなのです)。
他の例には、政策選択や商品の好みがあるでしょう。もしこれらの例の中で(100のサンプルの中から)67と33という数字が対比されたら、明らかに有意差のある結果を得ることになります。
シナリオの「前後」をテストする
前のセクションで使用されたテストで示されたのは、無相関の結果です。ふたつの回答間に関係がある場合、通常は「前後の」シナリオの中で異なるテストであるマクネマー検定が必要となります。
例として挙げれるのは、ドキュメンタリー、プレゼンテーション、イベントの前後で政策に対する回答者の態度、ドラッグを摂取する前後である種の症状が明白かどうか、8歳の子供と18歳の大人の両者に特定の特徴は見られるのかなどです。
一連のイベントを分析する(または生存時間分析)
ここで生存時間分析について少し触れたいと思います。なぜなら、このタイプの分析の最も一般的な名称にもかかわらず、問題になるイベントは必ずしも医療的もしくは否定的なものでないからです。イベントは、推進活動、症状の消失、ハードウェアやソフトウェアの故障、組織の崩壊、結婚や離婚、卒業や中退など、さまざまです。
ここではふたつのことが必要です。そのふたつは、イベントとそれがいつ起きたかです。これには一連のイベントが必要になりますが、インタビューやフォーカスグループからはおそらく引き出されません。しかし、そのようなソースから発見され始める可能性がありますし、NVivoのコーディングクエリから現れるかもしれません。これにあなたは刺激を受けて、健康安全記録ブックや人事記録などのもっと信頼できるソースを見つけるかもしれません。一連のイベントと適切な日付を用意することで、あなたは好調なスタートが切れます。
その分析はイラストで示された研究により、一連のイベントがどれほど速く急激に起きるかについて分かります(そして、ふたつ以上の一連のイベントを比較することが可能です)。これにより、新たな質的および量的研究への判断材料が提供されます。
勘に量的根拠を追加する
ロジスティック回帰などのもっと複雑な分析も可能ですが、今までに述べられてきたテストで、勘や次に何を証明するかについてのひらめきに対して、かなり十分な量的根拠が得られると思います。
著者 コール・デービス(COLE DAVIS)について

Cole Davis’ previous research has included studies in education and training, health, business and community attitudes. With masters degrees in psychology and computer science, his research and writing have always encompassed an integrative approach to qualitative and quantitative work.
元記事 | How to quantify qualitative data: what is the significance of your data? | The NVivo blog
