NVivo でデータ分析する際に、データの全体像を把握して、新たな発見につなげられないかと考えたことはありませんか。NVivo のクラスター分析は、そんなときに役立つ機能です。この機能を活用することで、データの中から類似性を可視化し、新たな視点からデータを読み解くことができます。このページでは、NVivo のクラスター分析がどのような機能なのかと具体的な操作方法をご紹介します。
※クラスター分析はNVivo Windows 版でのみご利用可能です。
クラスター分析とは?
クラスター分析とは、データ内の類似性に基づいて、データを複数のグループ(クラスター)に自動的に分類する統計手法です。NVivo では、テキストデータ内の単語、コーディング、属性値などの特徴に基づいて、類似した項目を1つのクラスターにまとめることができます。
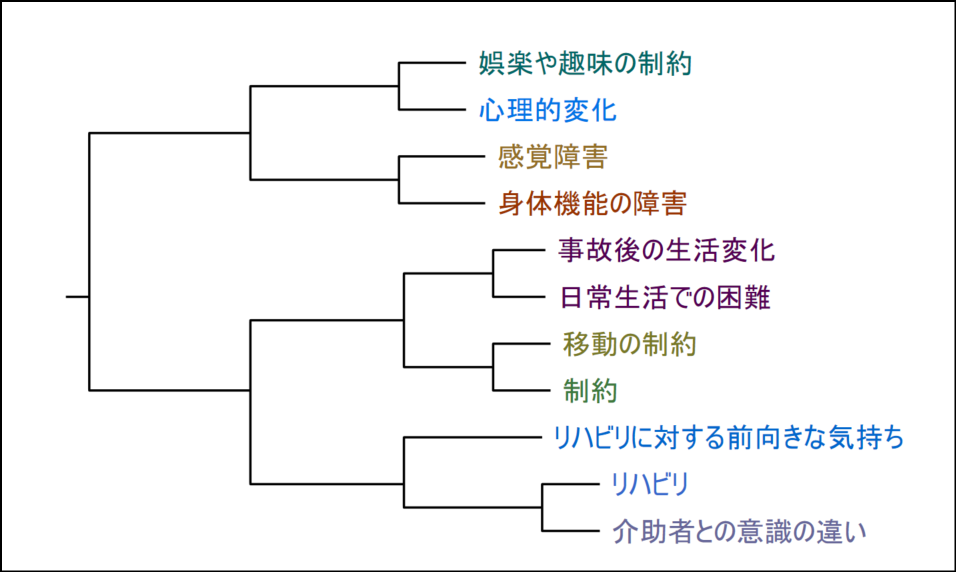
クラスター分析図では以下のようなことを可視化できます。
- ファイル間の類似点と相違点
例:さまざまなコミュニティメンバーからのコメントの類似度はどの程度か。
- コード間の類似点と相違点
例:海面上昇、洪水制御、土壌侵食に関するコーディングの類似度はどの程度か。
- 属性値に基づく調査対象者のデモグラフィック分布
クラスター化の基準
クラスター分析では以下3つの基準でコードまたはファイルをクラスター化することができます。
| 基準 | 説明 |
|
語の類似性 |
選択したファイルまたはコードに含まれる単語が比較されます。単語の出現と頻度に基づいて高い類似度を持つファイルまたはコードは、一緒にクラスター化されて表示されます。単語の出現と頻度に基づいて低い類似度を持つファイルまたはコードは、離れて表示されます。 |
|
コーディングの類似性 |
選択したファイルまたはコードへのコーディングが比較されます。同様にコーディングされたファイルまたはコードは、クラスター分析図で一緒にクラスター化されます。異なってコーディングされたファイルまたはコードは、クラスター分析図で離れて表示されます。 |
| 属性値の類似性 | 選択したファイルまたはコードの属性値が比較されます。類似する属性値を持つファイルまたはコードは、クラスター分析図で一緒にクラスター化されます。異なる属性値を持つファイルまたはコードは、クラスター分析図で離れて表示されます。 |
クラスター分析の操作手順
NVivo でクラスター分析を行う手順は、以下の通りです。
この例では作成したコードの類似性を確認してみたいと思います。
-
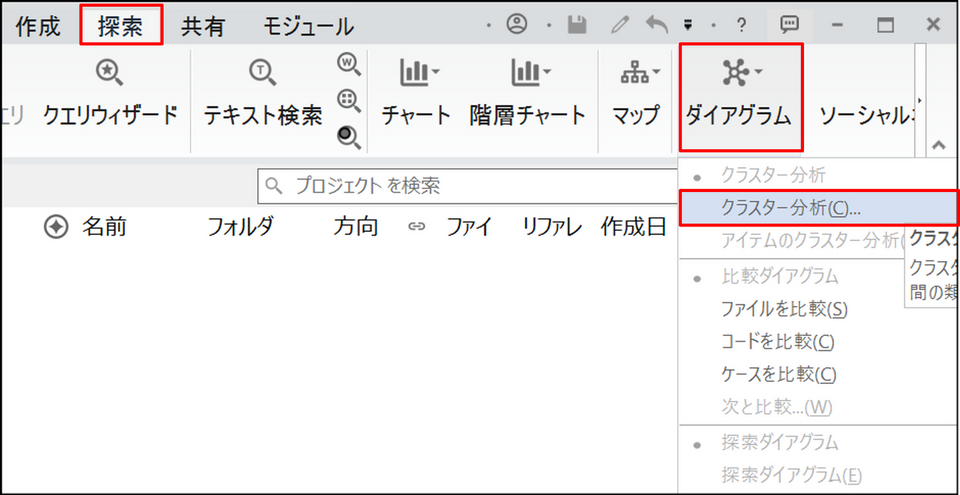
メニューの[探索] から[ダイアグラム] > [クラスター分析] を選択
-
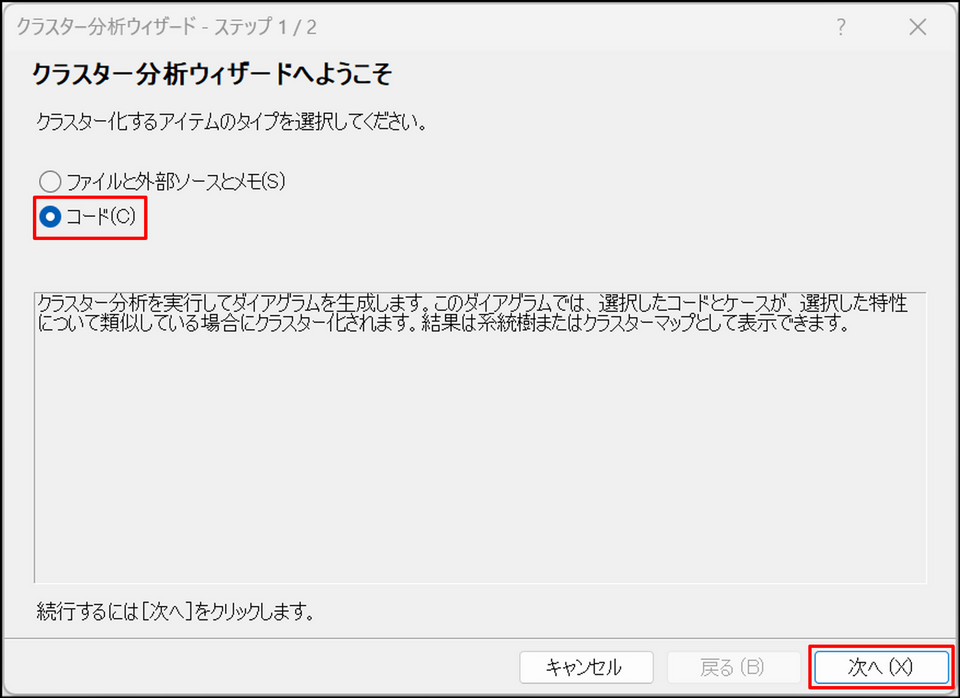
ウィザード画面で[コード] を選択し、[次へ] をクリック
-
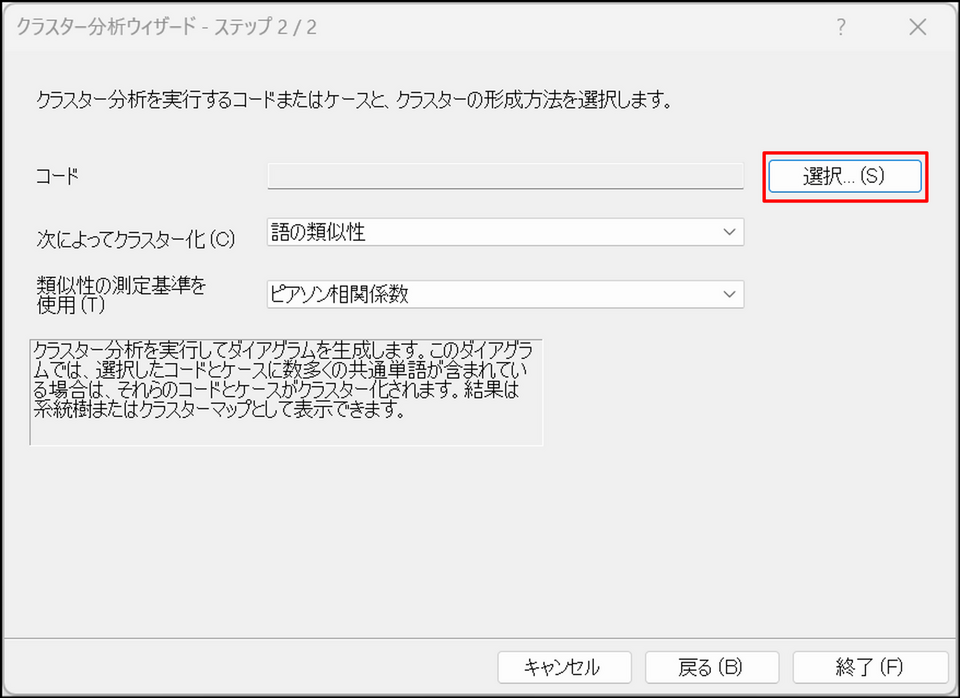
コードの[選択] ボタンをクリック
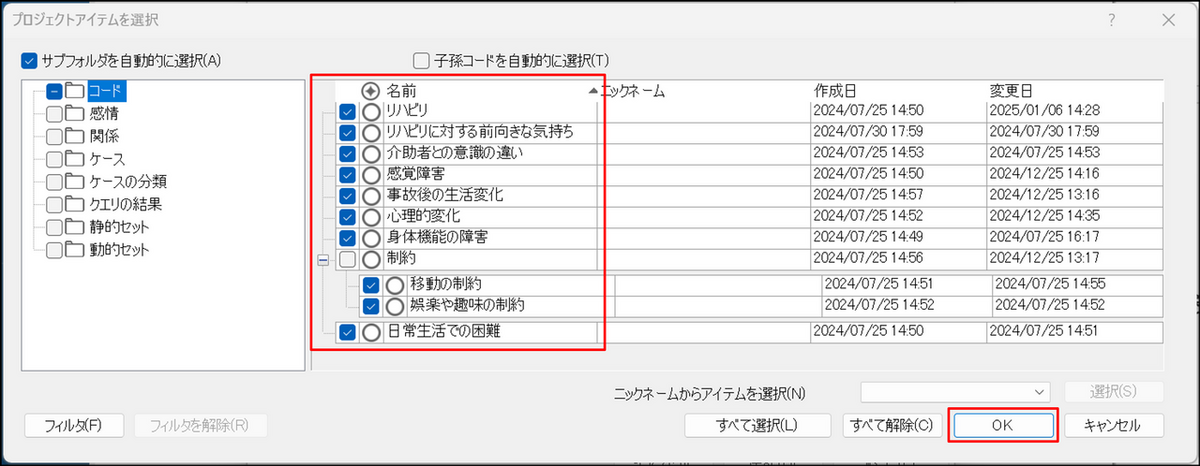
-
比較したいコードにチェックを入れ、[OK] をクリック
-
[次によってクラスター化] で[語の類似性] を選択
※各選択肢の詳細については、「クラスター化の基準」を参照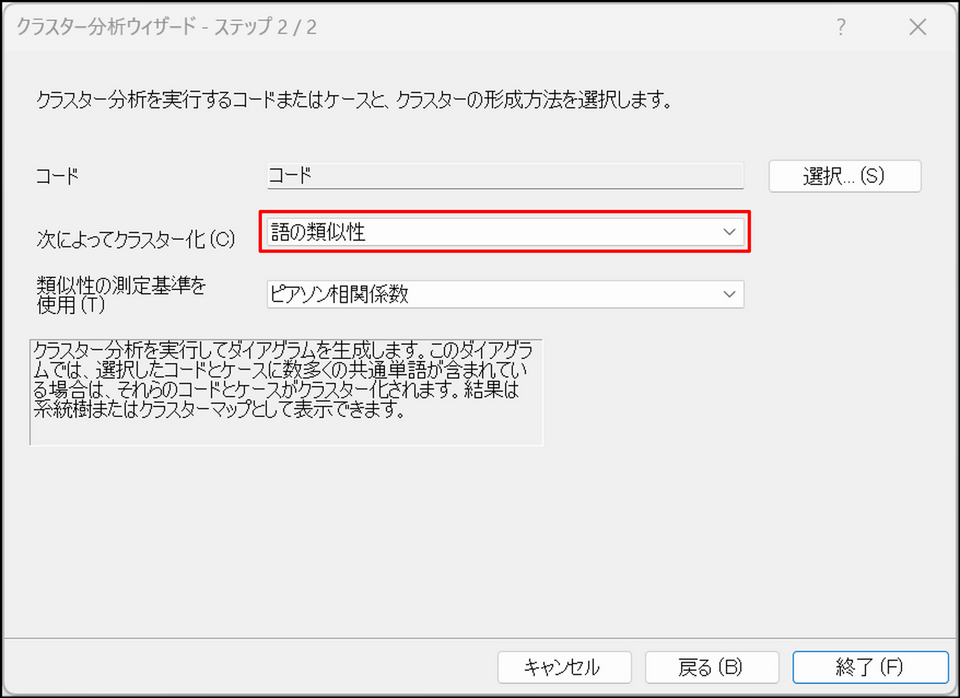
-
測定基準にて[ピアソン相関係数] を選択し、[終了] ボタンをクリック

- ピアソン相関係数:(-1 = 最も類似していない, 1 = 最も類似している)
- ジャカード係数:(0 = 最も類似していない, 1 = 最も類似している)
- ソーレンセン係数:(0 = 最も類似していない, 1 = 最も類似している)
→ 結果が表示されます。
クラスター分析結果画面の見方
結果画面の右側にはタブが表示され、タブを切り替えることで表示内容が変更されます。
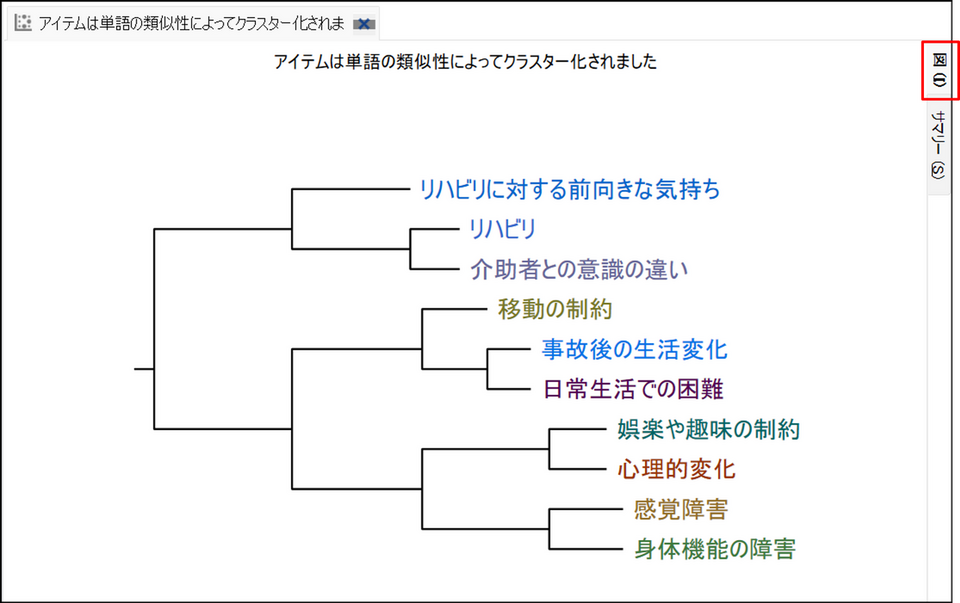
図タブ
クラスター分析の結果は、デンドログラム(樹形図)で表示されます。ツリー構造で、各項目間の階層的な関係を示します。類似性の高いコード同士は近くに配置されます。なお、アイテム色はランダムで特に意味はありません。
メニューの[クラスター分析] 内でレイアウトを変更することもできます。

「クラスターマップ」を選択すると、2次元または3次元の空間上に、各項目を点として配置し、類似する項目同士を近くに表示します。これらの図を見ることで、どの項目がどのクラスターに属しているか、各クラスターの特徴は何かなどを視覚的に把握することができます。

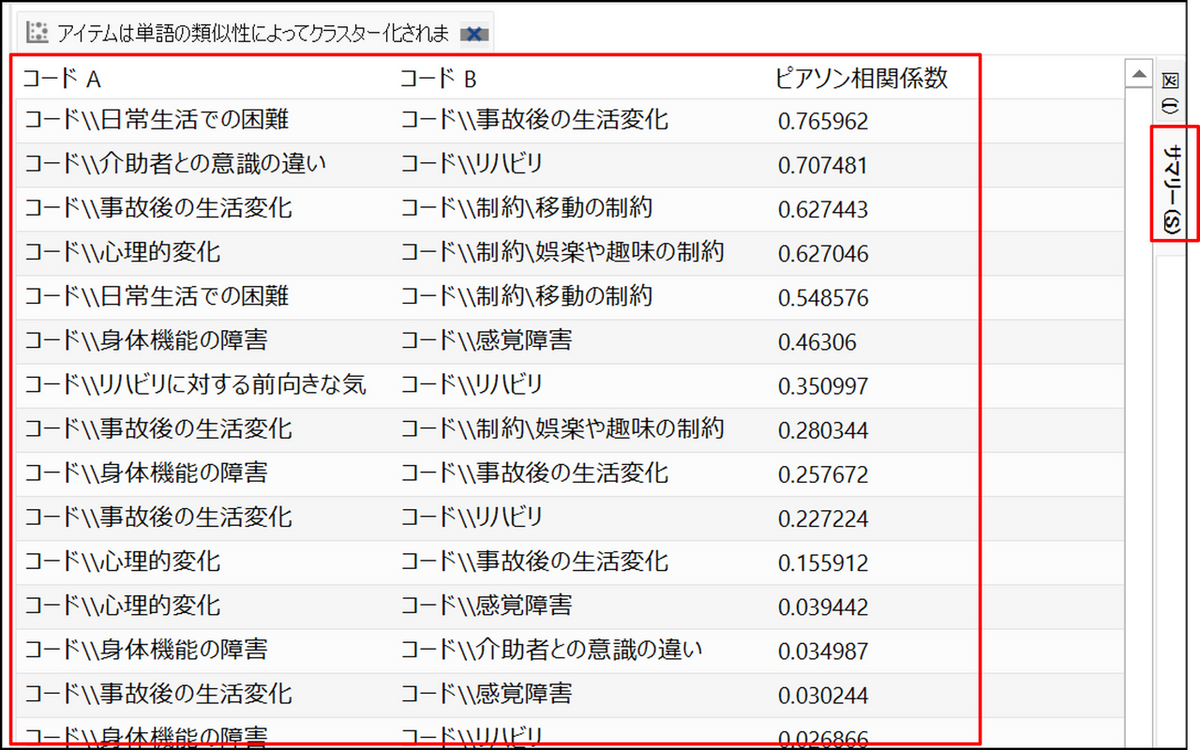
サマリータブ
サマリータブには、各アイテムペアの相関係数が表示され、アイテム同士がどれくらい類似しているのかを判断することができます。
クラスター分析の活用事例
コードの類似性を確認する以外にも以下のような場面でクラスター分析を活用できます。
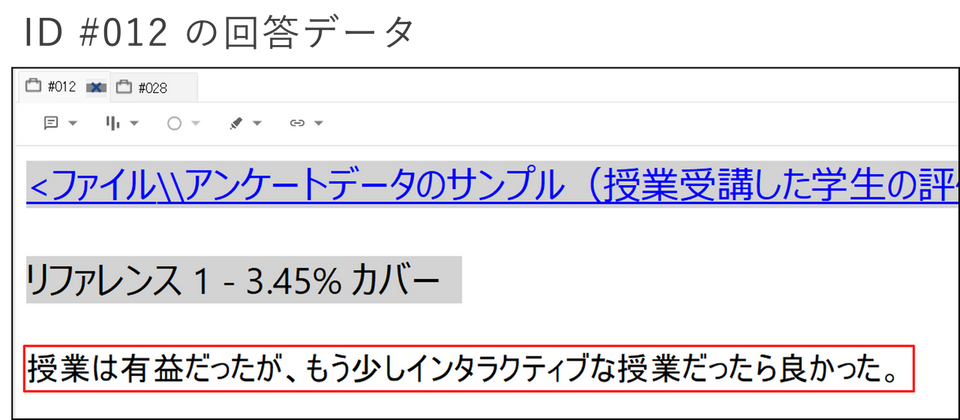
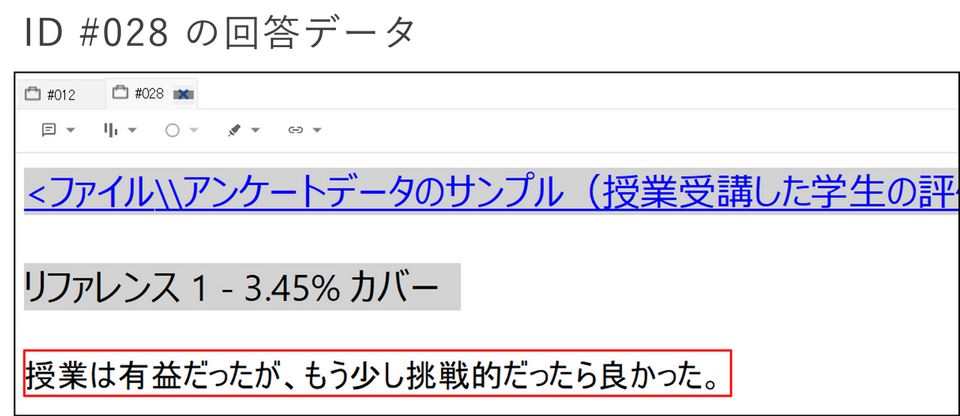
アンケートデータの回答者ケースを比較し、コメントの類似性を確認する
例)ある大学の授業を受講した学生30名に対して行った授業評価のデータ
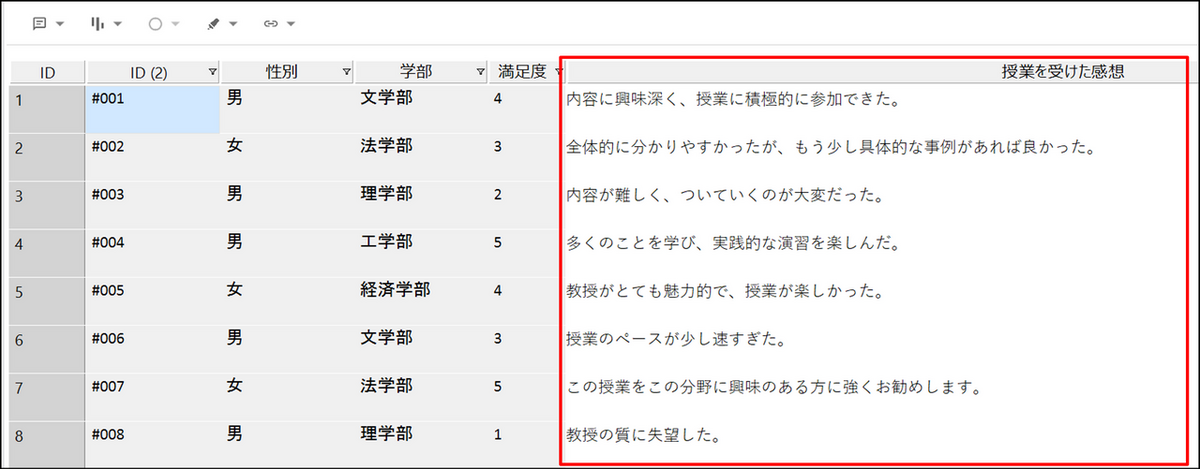
回答者ケースごとに自由記述の回答データをまとめ、クラスター分析を実行した結果
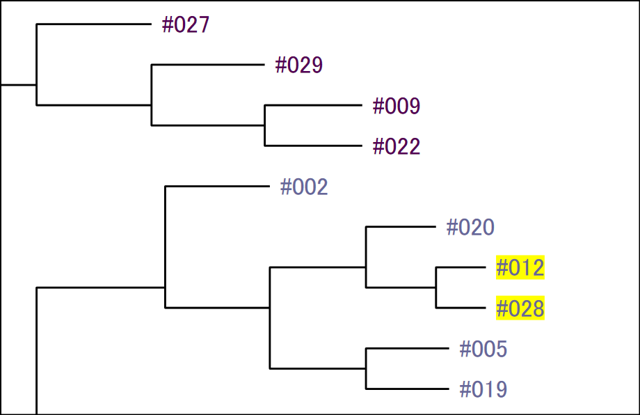
上記アンケートデータでは、ID #012 とID #028 のケースの相関係数が「0.70…」と比較的高く、回答データが類似していると判断できます。

プロジェクト内でインポートした論文PDF の内容を比較
例)緩和ケア関連の論文PDF をインポートして、クラスター分析を実行した結果

同じテーマに関する論文PDF でクラスター分析を実行することで、主張が似通った論文を探すことに役立つ可能性があります。
クラスター分析の注意点
クラスター分析を利用する際には以下の点に留意してください。
- クラスター分析は探索的な手法と理解する
クラスター分析は、データ中に隠されたパターンを発見するためのツールであり、最終的な結論を得るための手法ではありません。得られた結果を解釈する際には、ほかの分析結果や専門知識も合わせて検討する必要があります。
- クラスター数の設定
クラスター数を増やすと、より細かいグループ分けができますが、解釈が難しくなる場合があります。
- 類似性基準の選択
選択する基準によって、クラスターの構成が変わる場合があります。
- ストップワードの設定
単語の類似性を計算する際には、ストップワードを設定(「the」「and」など、意味を持たない単語を除外)することで、より正確な結果を得ることができます。
まとめ
NVivo のクラスター分析は、大量のテキストデータを効率的に分析し、新たな発見につなげるための強力なツールです。この機能を活用することで、データの全体像を把握し、複雑なデータの中から重要な情報を抽出することができます。ぜひ、ご自身の研究や分析に活かしてみてください。
参考ページ
- Cluster analysis diagrams
https://help-nv.qsrinternational.com/15/win/Content/vizualizations/cluster-analysis.htm
- How are cluster analysis diagrams generated?
https://help-nv.qsrinternational.com/15/win/Content/vizualizations/how-cluster-analysis-generated.htm
