インタビューを分析する際に便利な、発言者ごとの自動コーディング機能
NVivoには質的研究で頻繁におこなわれるフォーカスグループ・インタビューなどのインタビューを分析する際に便利な、発言者ごとの自動コーディング機能があります。
フォーカスグループの逐語録を発言者ごとに自動で抜き出すことができるので、コーディングや、分析の効率化が可能です。頻出語クエリなどの、可視化機能と合わせることで、発言者ごとの傾向などをすぐに把握することが可能です。
自動コーディングの実演(自動コーディングからワードクラウドの表示)
インタビューファイルの3名の個々の発言を自動で抽出し、ワードクラウドで各人の頻出語を比較しています。
※動画はNVivo 12のものです。
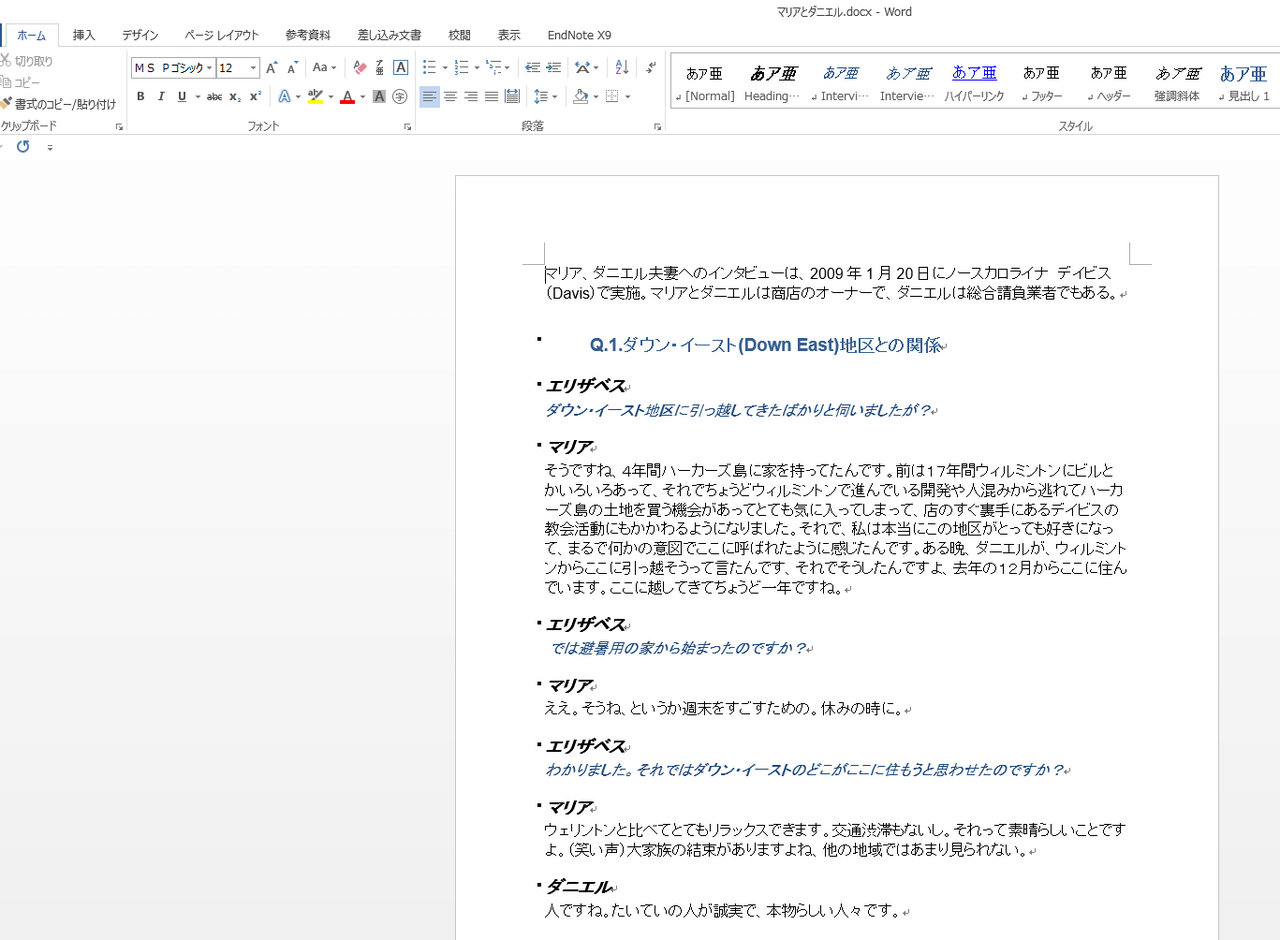
NVivoに取り込むデータファイルを用意する
Word形式で文字起こししたデータファイルを用意します。NVivoは指定した発言者の名前で区切ってコーディングするため、発言者の名前が発言の前に書かれているようにします。
※発言者と発言内容の間は改行や、スペース、コロンなどで区切り、発言内容から離してください
データファイルの取り込み
次に準備したデータファイルをNVivoに取り込みます。
-
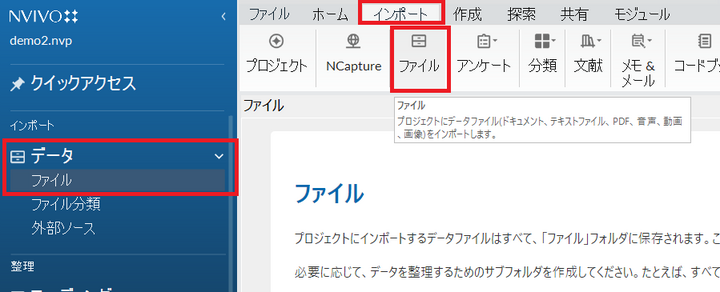
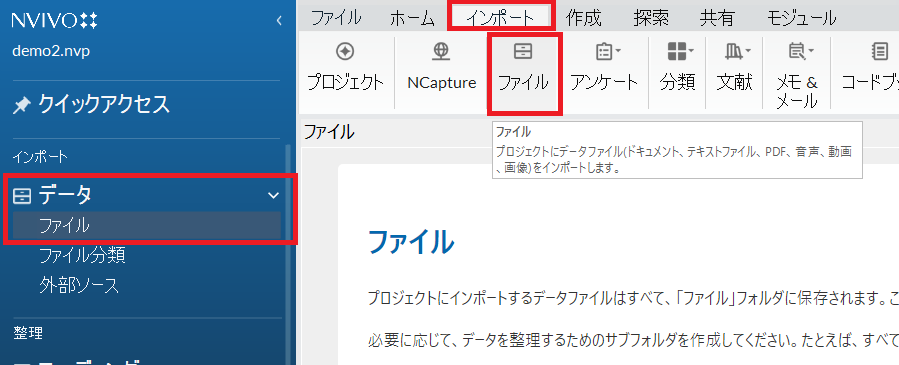
左のナビゲーションビューの「データ」の下の「ファイル」をクリックして、リストビューを「ファイル」にします。
上部のリボンの「インポート」をクリックし、「ファイル」をクリック。
-
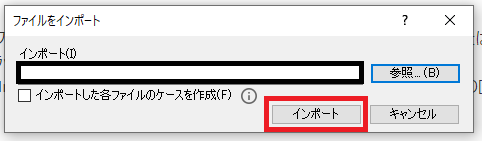
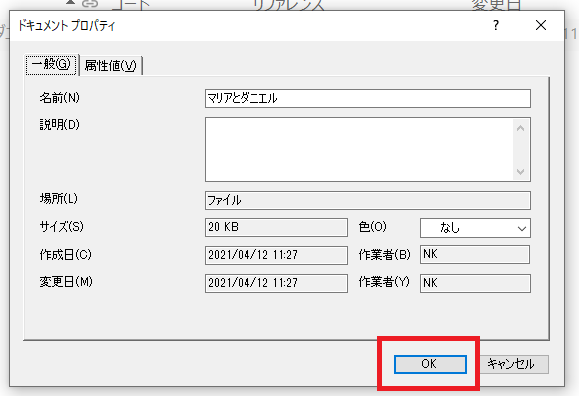
NVivoに取り込むデータファイルを選択します。ドキュメントプロパティも、変更がなければそのままOKをクリックします。
-
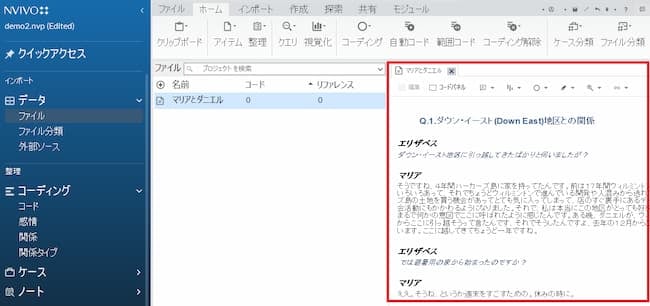
「ファイル」の中に準備したデータファイルが取り込まれました。当該ファイルをダブルクリックすると、ファイルが開かれます。 これを自動コーディングしていきます。
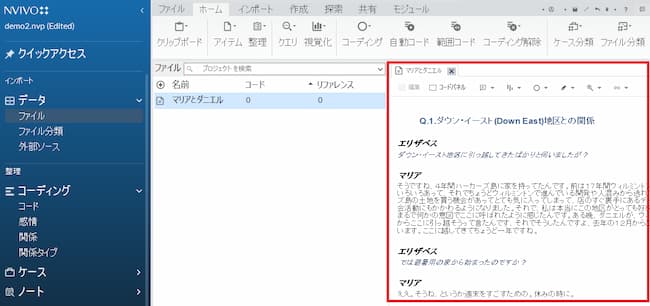
発言者ごとの自動コーディング
-
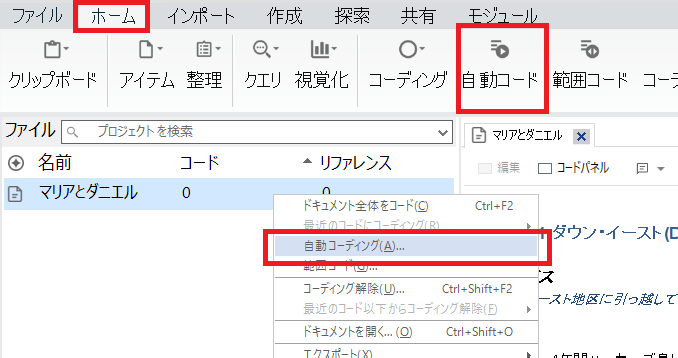
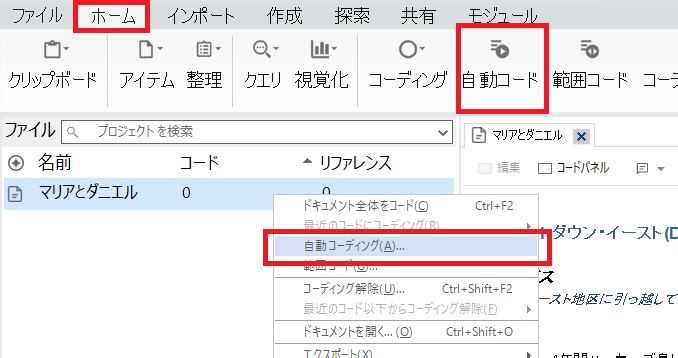
上部のリボンの「ホーム」から「自動コード」をクリック、もしくは当該ファイルに右クリックで「自動コードディング」を選択。
-
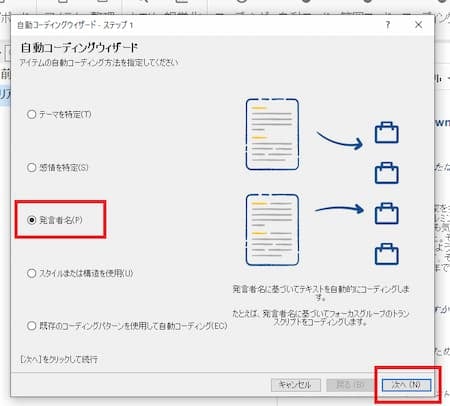
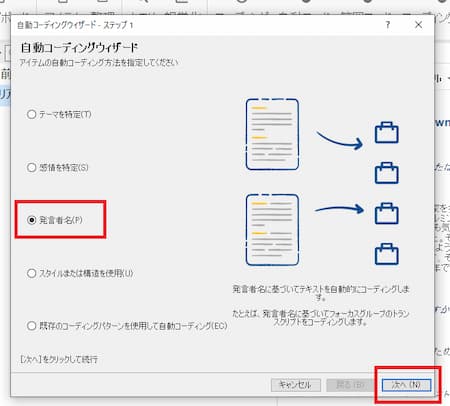
自動コーディングウィザードが表示されるので、「発言者名」を選択して、次へ。
-
データファイル内の発言者を入力します。
入力された発言者から、次の発言者までが各人の発言として振り分けられていきます。下のプレビューで意図したとおりに発言者が振り分けられているか確認できます。
今回は1つのデータファイルを自動コーディングしていますが、複数のデータファイルを選択して、同時に自動コーディングすることも可能です。複数のインタビューのデータファイルがある場合も、一度にまとめて自動コーディングすることができます。
-
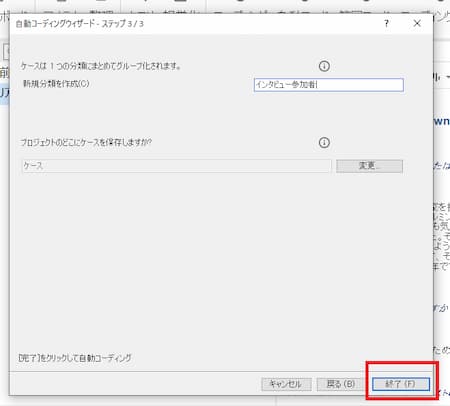
分類を入力して、「終了」をクリック。ここでは分類をインタビュー参加者としました。
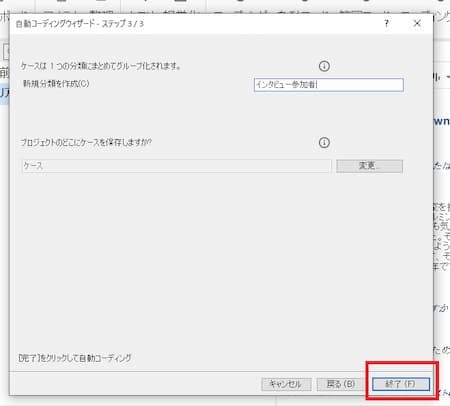
これで自動コーディングが完了しました。
コーディング結果の確認
-
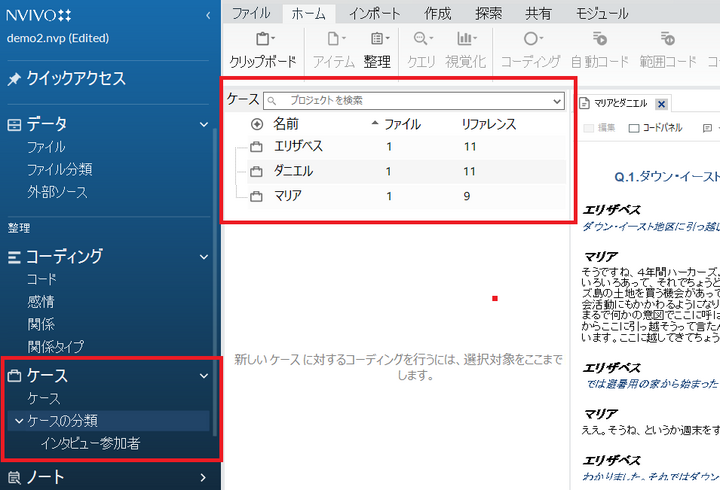
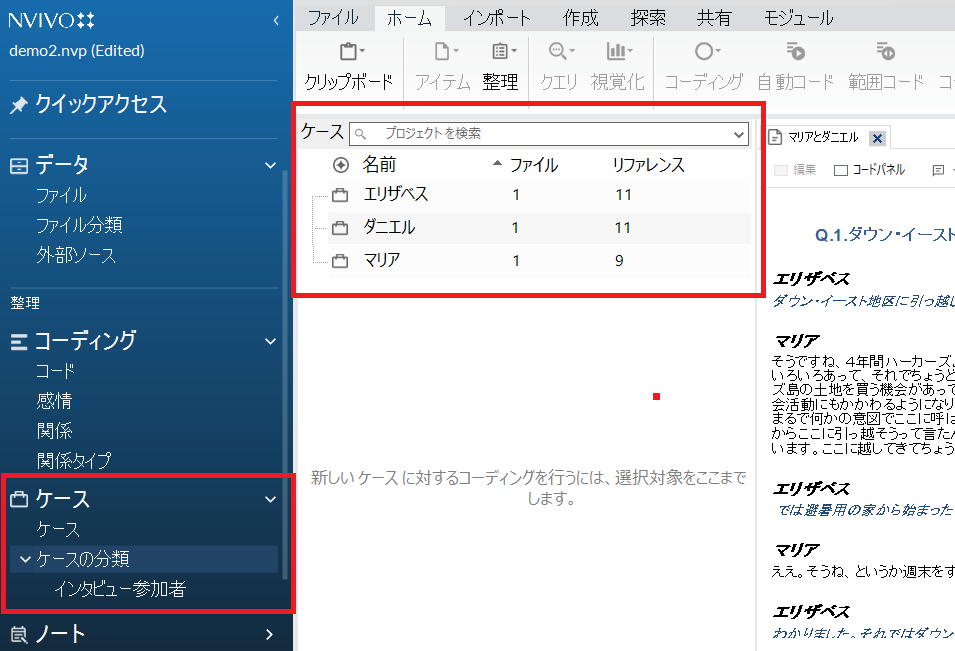
コーディング結果を今回は「ケース」に保存したので、「ケース」を確認します。ナビゲーションビューの「ケース」の下層の「ケース」をクリック。
-
自動コーディングした3名のケースが作成されています。また、先ほど作成した分類「インタビュー参加者」も作成されているのが確認できます。
作成されたケースをクリックして、自動コーディング内容を確認します。今回の例では「ダニエル」の発言だけが抜き出されていることが確認できます。
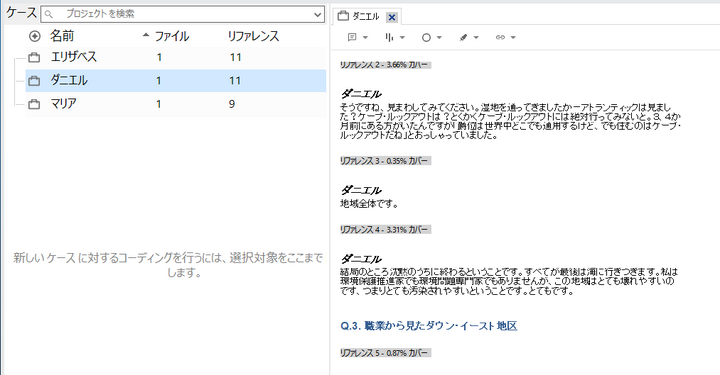
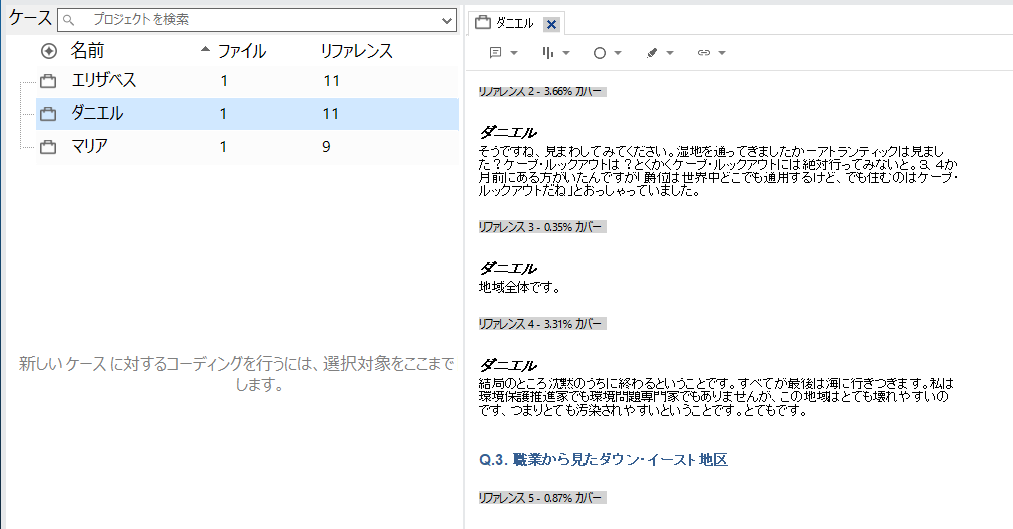
これで、各発言者ごとに逐語録から発言を抜き出すことができました。こうすることで、個々人のコーディングが簡単に出来る環境にすることができます。
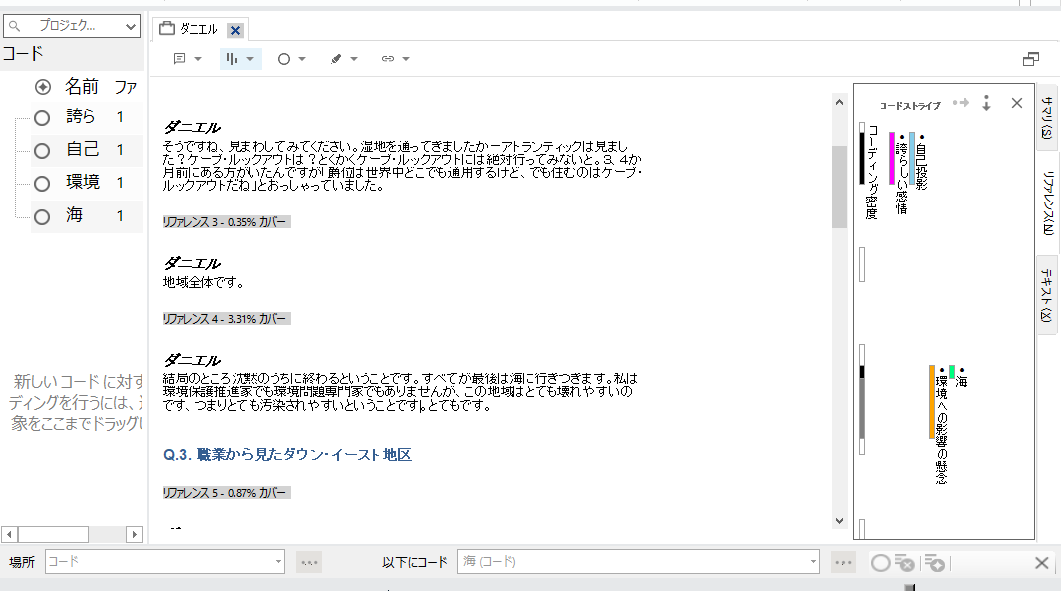
頻出語クエリとワードクラウドでインタビュー内容を俯瞰
また、頻出語クエリとワードクラウドを使って、頻出語を視覚化し、発言者ごとの傾向などを簡単に可視化し俯瞰することが可能です。
-
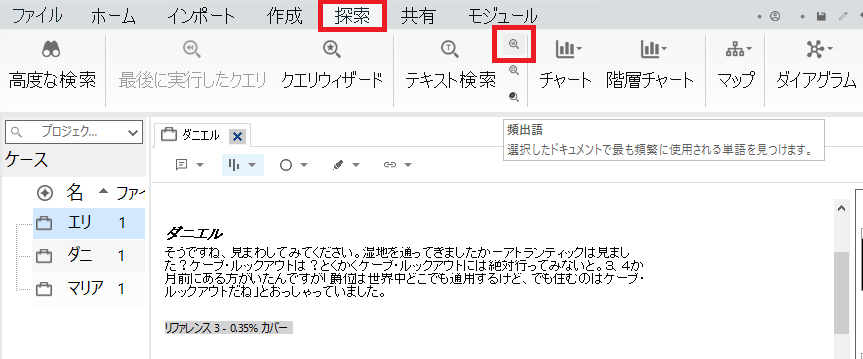
リボンの「探索」から「頻出語クエリ」をクリック。
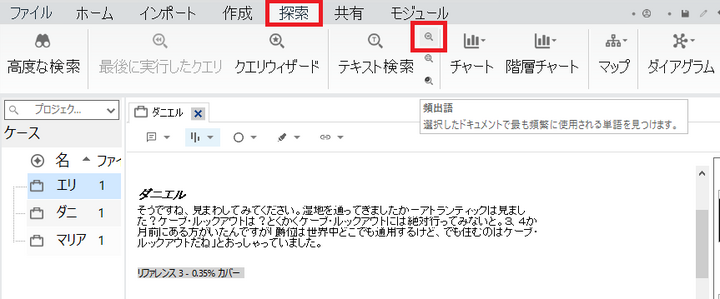
-
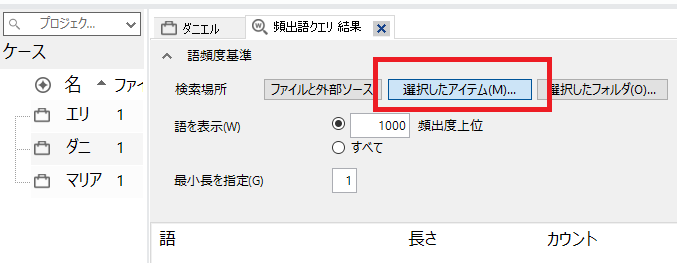
対象を選択します。「選択したアイテム」をクリック。
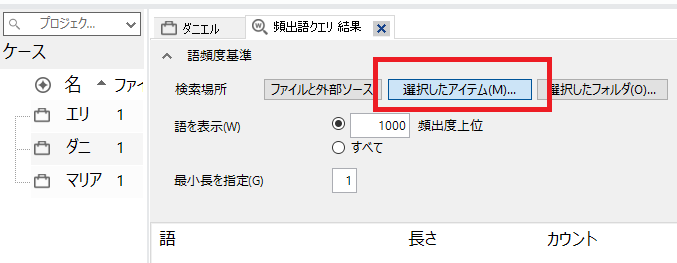
-
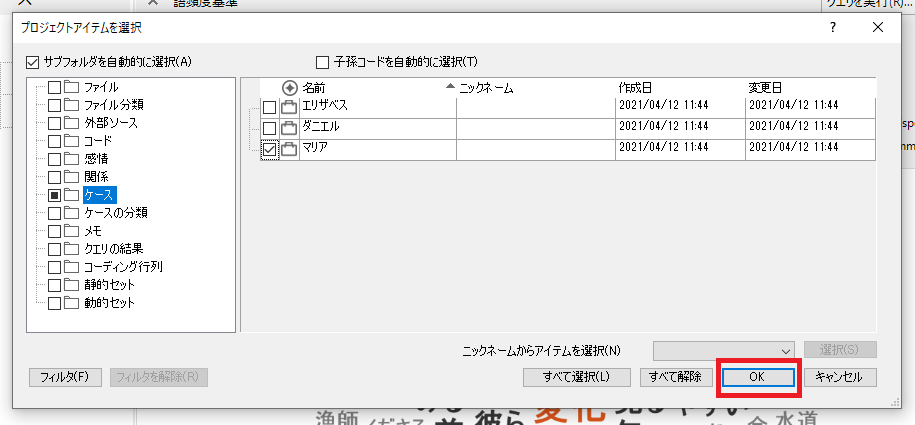
頻出語を確認したいファイルやケースなどを選択して、「OK」をクリック
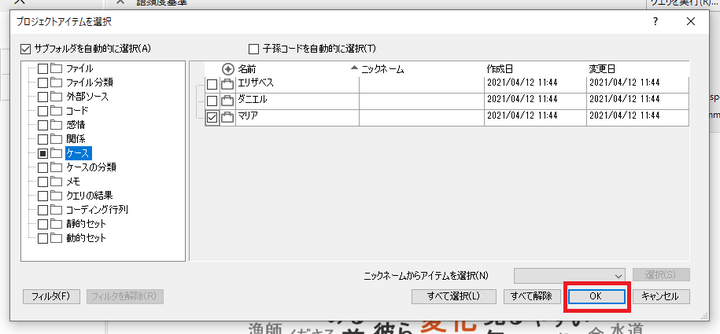
-
「クエリを実行」をクリック。
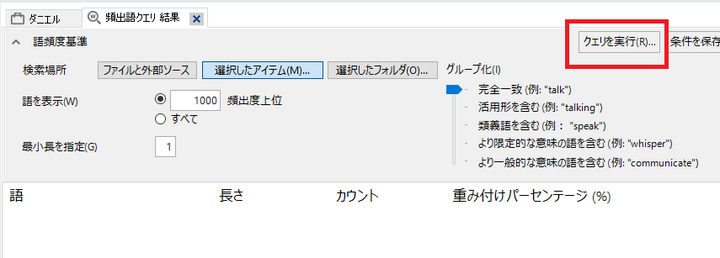
-
画面右のタブ「単語クラウド」をクリックすると、頻出語を可視化する「ワードクラウド」が表示されます。
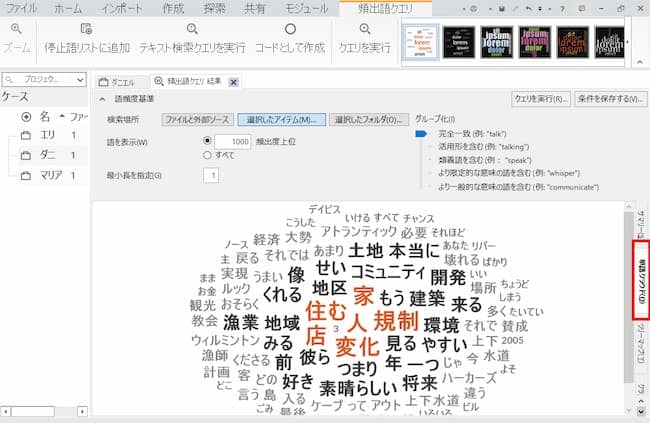
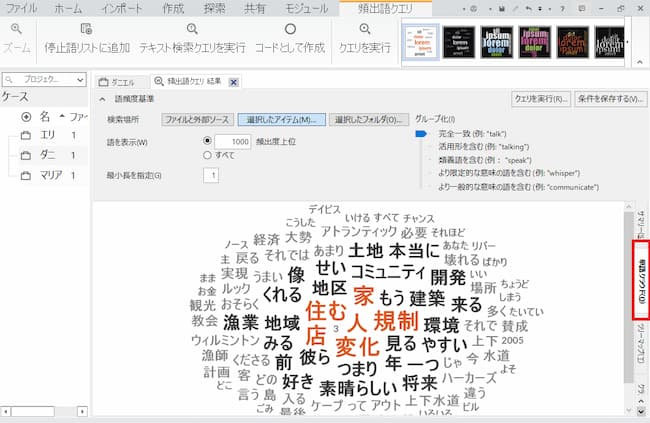
発言者の発言内容の傾向を可視化し、俯瞰できるので、この結果を手がかりにコーディングを進めていったり、新たな洞察を得ることが可能です。
